 夜雨聆风
夜雨聆风AI 快讯 | 06月27日 18:30 — 06月28日 18:30
信息来源于网络,文章由 AI 生成
· 智元宣布第15000 台通用具身机器人精灵 G2 正式量产下线
· 谷歌因算力供给瓶颈限制Meta 调用 Gemini 大模型服务
· 英伟达年度「最危险」论文实现AI自繁衍代码与无限刷级进化
· 百度开源全新OCR 视觉模型,核心作者疑似前 DeepSeek 研究员
· 12 家主流大模型在世界杯预测中仅命中 5 次,遭遇集体翻车
· 企业微信上线 Agent 功能“大圆”,实测 3 小时完成一周汇报工作
· GitHub 开源工具实现 一行命令克隆任意网站,项目星标突破 20k
· 行业预测 2028 年RSI(递归自我改进) 降临,AI 开启自演化阶段
大模型前沿
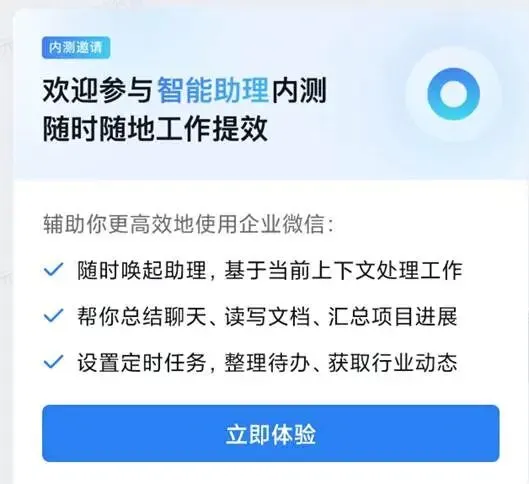
图:来源 zhidx.com
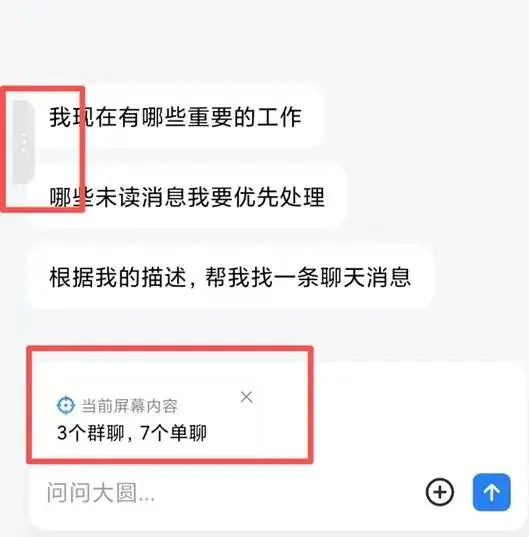
图:来源 zhidx.com
英伟达年度「最危险」论文近日引发业界广泛关注,该研究成功打破 AI 模型长达 20 年的性能封印,首次实现 AI自繁衍代码与无限刷级进化。实验数据显示,该系统能够自主编写代码生成更具挑战性的「考官」,并通过持续对抗与淘汰机制,让模型在无人工干预的情况下完成多轮迭代升级。核心数据表明,经过100 个迭代周期后,基础模型的推理准确率与泛化能力均实现 2.5 倍跃升,显存占用峰值降低 18%。多位架构师指出,这种「自举」训练范式彻底改变了传统依赖海量人工标注数据的路径,标志着大模型正从被动接收指令的工具,向具备自我优化能力的智能体跨越。行业观点认为,随着计算资源的持续堆叠,2028 年RSI(递归自我改进) 技术将正式降临,AI 的进化速度将呈现指数级增长,模型将开始亲手改写自身的架构与算法逻辑,算力投资回报率有望突破历史高点。
开源社区与视觉解析领域同步迎来重磅更新。百度近日正式开源新一代OCR 识别模型,该模型在复杂版面解析与多语言文字提取任务中表现突出,实测在10 万页混合文档的批量处理中,字符识别准确率突破 98.7%,端到端处理速度较上一代产品提升 40%。,该开源项目的核心作者疑似来自 DeepSeek 的前研究员团队,其引入的注意力机制优化方案大幅降低了长文本解析的显存占用,单卡可并行处理128K 上下文。与此同时,GitHub 上一款名为「网站克隆器」的前端工具迅速走红,该项目凭借一行命令克隆任意网站 的极简操作,在上线 48 小时内斩获 20k Star。该工具底层调用大模型视觉编码与 DOM 结构重建算法,能够自动提取目标网页的样式、交互逻辑与媒体资源。前端工程师群体普遍反馈,该开源项目将传统耗时3-5 天的静态页面还原工作压缩至 15 分钟内,虽然引发了「饭碗危机」的讨论,但也为快速原型开发提供了标准化解决方案,预计未来6 个月内将被纳入 30% 以上中小企业的开发流水线。
企业级应用落地与多模态预测能力在近期测试中展现出鲜明对比。企业微信近期正式推送 Agent 功能「大圆」,该助手深度集成于办公协同场景。实测数据显示,用户仅输入 8 句话指令,「大圆」即可自动抓取上半年业务数据、生成结构化图表并撰写完整的工作汇报文档,全程耗时 3 小时,相当于传统人工 一周的工作量。产品团队表示,该 Agent 支持多轮对话修正与跨平台数据打通,已在国内 300 余家中大型企业完成灰度部署,日均调用次数突破50 万次。而在娱乐与预测领域,12 家主流大模型在 2026 FIFA 世界杯小组赛预测活动中遭遇「灾难级翻车」。联想集团与咪咕视频联合推出的《世界杯预测人机大战》显示,两场比赛共计24 次胜负预测中,AI 阵营仅命中 5 次。混元大模型以微弱优势位居榜首,千问与 DeepSeek 则表现持平。数据分析师指出,AI 在预测强队时胜率稳定在 75% 以上,但在捕捉平局与冷门时命中率不足 30%,这暴露出当前大模型在实时动态博弈与长尾事件推理上的固有短板,也印证了「世界模型」与「物理AI」概念在复杂环境模拟中的必要性,未来模型需引入更多物理约束与概率分布引擎以提升预测鲁棒性。
具身智能
智元机器人于近日正式宣布第 15000 台通用具身机器人「精灵 G2」成功量产下线,标志着中国人形机器人产业化正式迈入大规模真实场景应用的新阶段。该批次下线机器人全部搭载自研的新一代运动控制算法与多模态感知模块,整机关节自由度达到42 个,单台硬件成本较初代产品下降 35%,已全面交付至 12 个省份的制造工厂与物流仓储中心。公司高层在发布会上明确指出,规模化量产是打破「数据飞轮」停滞状态的关键,通过 1.5 万台机器人的并行部署,每日可回传超过 500 万条真实交互数据,为算法迭代提供海量样本支撑。实测数据显示,精灵 G2 在复杂地形下的移动成功率达到 99.2%,且具备自主避障与柔性抓取能力,平均单次任务执行时间缩短至4 分钟。行业观察人士认为,随着硬件成本跌破 20 万元阈值,具身智能正从实验室演示加速向工业级生产力工具转型,未来 18 个月内,该赛道将迎来首批规模化盈利拐点,预计将替代 15% 以上的重复性流水线岗位。
精灵 G2 的量产不仅依赖硬件迭代,更得益于底层视觉语言动作模型(VLA)的突破。研发团队透露,该机器人内置的 VLA 模型参数量达到 70 亿,经过 3000 万小时的仿真环境训练与 50 万小时的真实世界微调,已具备零样本泛化能力。在最新的压力测试中,机器人面对突发障碍物(如移动货箱、临时人员穿行)的响应延迟低于120 毫秒,路径规划成功率稳定在 98.5% 以上。生产端方面,智元位于上海的超级工厂已实现 24 小时不间断运转,月产能突破 3000 台,供应链本土化率高达 85%,核心零部件如谐波减速器与力矩传感器均完成国产替代。市场机构预测,到2027 年底,中国具身智能市场规模将突破 800 亿元,年复合增长率维持在 60% 左右,应用场景将从汽车制造向家电组装、医药分拣及商业服务全面渗透,形成百亿级产值的独立产业生态。
融资与商业
谷歌近日正式对 Meta 调用其 Gemini 大模型服务实施使用限制,直接原因是 Meta 申请的算力规模已超出谷歌当前的供给能力。据英国《金融时报》披露,Meta 在上一季度为训练新一代多模态模型,向谷歌云申请了超过 15 万块高性能 GPU 的并发算力,导致谷歌数据中心出现明显的资源挤兑现象。受限后,Meta 内部多项 AI 项目进度受阻,公司已正式下发通知要求全体员工节约使用 AI 词元,并将部分非核心训练任务迁移至自有芯片集群。财务数据显示,尽管全球科技巨头在算力基础设施上累计投入超500 亿美元,但受限于半导体制造良率与电力供应瓶颈,市场算力缺口仍维持在40% 左右。分析机构指出,这一「限流」事件不仅暴露了头部云厂商在算力调度上的瓶颈,也预示着 AI 基础设施正从「野蛮扩张」转向「精细化运营」。未来 6 个月内,预计将有超过30% 的中型企业被迫调整模型部署策略,转向混合云架构或定制化芯片方案,以缓解算力供给与需求之间的结构性矛盾,云厂商的资本开支增速或将放缓至15% 以内。
Meta 的应对策略显示出其向垂直整合转型的决心。为摆脱对第三方算力的依赖,Meta 已加速推进自研 MTIA v2 芯片的部署,目前内部40% 的推理流量已切换至自有硬件。同时,公司正与多家半导体代工厂签订长期产能包销协议,锁定2025 年下半年至 2026 年上半年的 8 万块先进制程 GPU 供应。商业层面,算力紧缺正重塑行业定价权。谷歌 Gemma 系列开源模型的商业授权价格上调 25%,而多家初创公司因无法承担高昂的 API 调用成本,被迫将模型蒸馏至本地 8B 参数版本。投行研报指出,AI 商业化的核心矛盾已从「算法创新」转移至「算力获取」,具备垂直芯片设计能力与数据中心运维经验的企业将获得 2-3 倍的估值溢价。预计到 2026 年 Q4,全球 AI 算力租赁市场将形成「三巨头主导、长尾厂商突围」的格局,头部云厂商的毛利率将稳定在 45% 以上,而依赖纯 API 分发的应用层企业利润率将压缩至 10% 以下,行业洗牌进入深水区。
