 夜雨聆风
夜雨聆风4000 个文档
我用 AI 做了个工具把它们管明白了
📅 2026年6月26日 · 🔍 好找 V2.0 · 批量管理 · AI编程实战
先说背景
上一篇讲了我怎么用 ZCode + GLM-5.2 从零造出「好找」V1.0——一个能导入、能搜索、能 AI 整理、能 OCR 的文档管理工具。
那一篇已经讲过了技术栈、三层架构、踩过的坑(async 死锁、sidecar 崩溃、扫描卡死),这里不重复。
只说一句结论:V1.0 解决了「单个文档能不能管理」的问题。
然后我把两个盘的文档全导进去了——4000 多个文件。
V1.0 当场就不够用了。
问题:4000 个文件,V1.0 玩不转了
V1.0 的所有操作都是「针对单个文档」:点一个文档,AI 分析一个;选一个文档,改一次分类。
4000 个文件?你得点 4000 次。
更崩溃的是,我手贱选了「全部」,让 AI 队列一口气跑——从晚上 6 点跑到凌晨 3:40,整整 9 个小时。跑完一看,分类 53 个、标签 2911 个,比没整理还乱。
这就是 V2.0 要解决的问题。不是「让 AI 更聪明」,而是「让几千个文件能被批量管起来」。
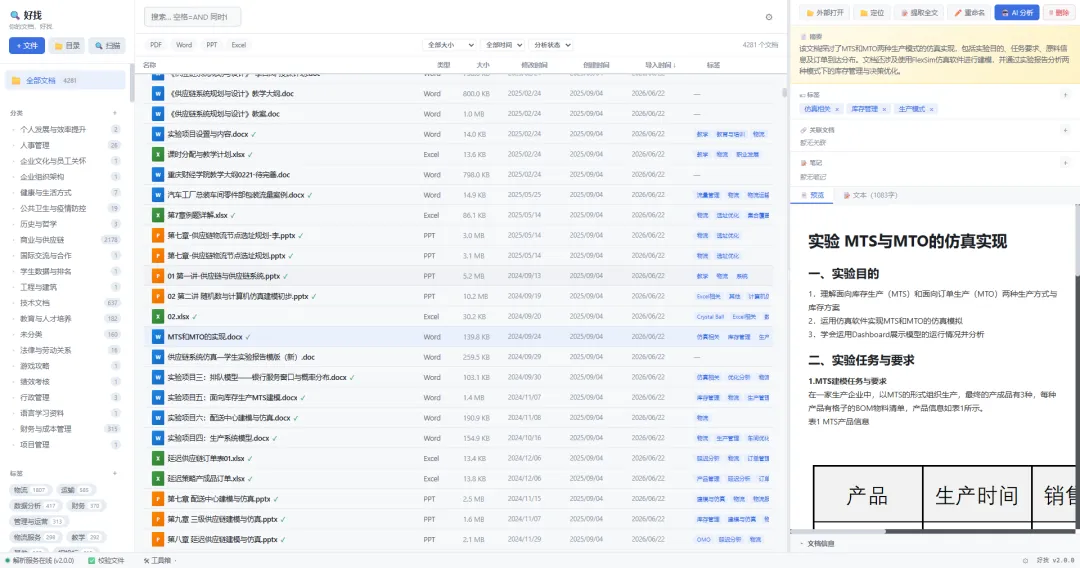
V2.0 做了什么:批量管理流水线
核心洞察是——4000 个文件不该全部交给 AI,而是层层过滤,最小化 AI 成本。
我设计了一条「漏斗式」流水线:
4000 个文件
↓
① 重复检测 — 砍掉冗余副本,0 成本,秒级
↓
② 规则自动分类 — 规则秒杀 80%,0 成本
↓
③ 批量 AI 队列 — 限速保护,处理剩余 20%
↓
④ AI 合并整理 — 标签/分类归并,流式审核
先靠免费的规则砍掉绝大多数,真正烧 AI 的就几百个。既快又省钱。

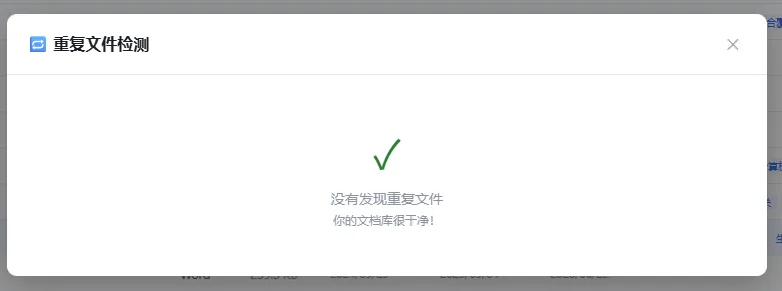
① 重复检测:先瘦身
扫描两个盘导入 4000 个文件,重复的合同、发票、报告大概率有不少——同一份存了多个位置、多个名字。
按文件哈希(SHA256)分组,秒级找出所有重复。每组默认保留最早导入的一份,可以切换、可以移除,一键清理(不删原始文件,只从库移除)。
4000 文件可能直接砍掉 30%~50%。
0 成本,纯本地算法。
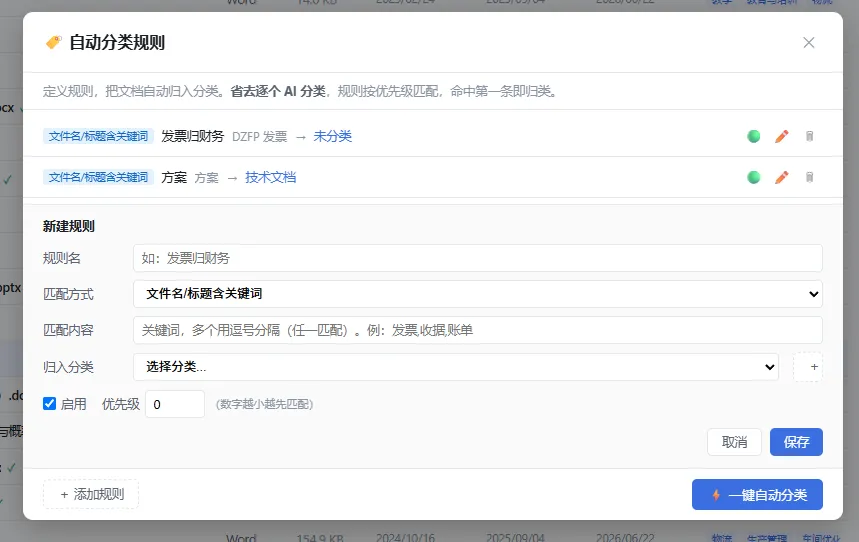
② 规则自动分类:省 90% AI 成本
这是省钱的灵魂。
很多文档根本不用 AI 就能分类——光看文件名/路径就知道归哪类:
▶ 文件名含「发票,收据,账单」→ 财务
▶ 文件名含「合同,协议」→ 合同
▶ 文件类型是 `.ppt` → 演示文稿
▶ 路径里有「财务」目录 → 财务
我在应用里做了一个规则引擎(不是 Python 脚本,是应用内置的图形界面功能):三种规则类型——关键词 / 文件类型 / 路径。新用户首次打开会自动有 7 条默认规则,自己可改可删。
点「一键自动分类」,Rust 直接扫数据库匹配,毫秒级归好几百个。只有文件名模糊、规则搞不定的,才交给 AI。
规则处理 80%,AI 只处理 20%。这一步省掉的钱,是实打实的。
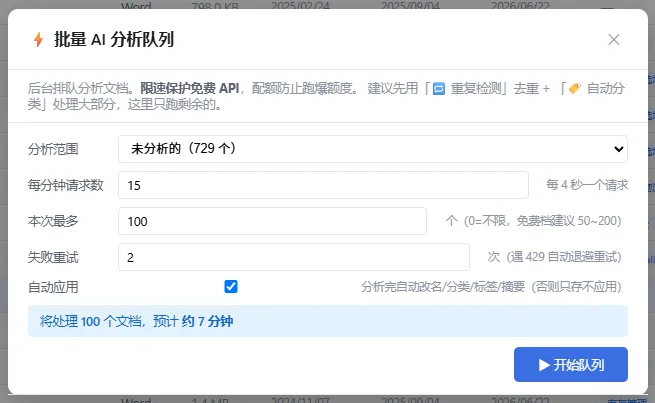
③ 批量 AI 队列:专为免费 API 设计
剩下规则搞不定的,才进 AI 队列。但这里有个真问题——免费 API 有限额,跑着跑着就超了。
所以队列设计了三道保护:
RPM 限速 — 每分钟只调 N 次,防 API 报 429(默认 15,每 4 秒一个)
配额上限 — 本次最多分析 N 个,防一次跑爆免费额度
失败重试 — 遇 429/超时自动退避重试(2s/4s/8s)
还有个教训必须说——UI 不能骗人。
之前预估时间写「几秒」,实际合并标签跑了 18 分钟。我让 AI 队列跑,显示「480 分钟」,我下意识以为是 4 小时,结果跑了 9 小时。
V2.0 改成真实预估:「预计约 8 小时 12 分」,运行中动态显示「剩余 7 小时 30 分」。
用户需要的是准确,不是好看。
而且改成了流式——每跑完一个文档就更新进度,可以暂停、可以停止(已完成的不丢),不用对着一个转圈干等。
④ AI 合并整理:治「标签爆炸」
AI 批量跑完 4000 个文档,标签从 0 个爆炸到 2911 个。
为什么?每个文档各跑各的,AI 每次措辞不一样:
▶ 「物流」「物流服务」「物流管理」「物流运输」「物流配送」——其实都是「物流」
▶ 「运输费用」「运输报价」「运输成本」——其实都是「运输费用」
2911 个标签手动合并?搞不死你。
用 AI 合并——把标签名列表喂给 AI,让它把语义相同的归并成标准名。
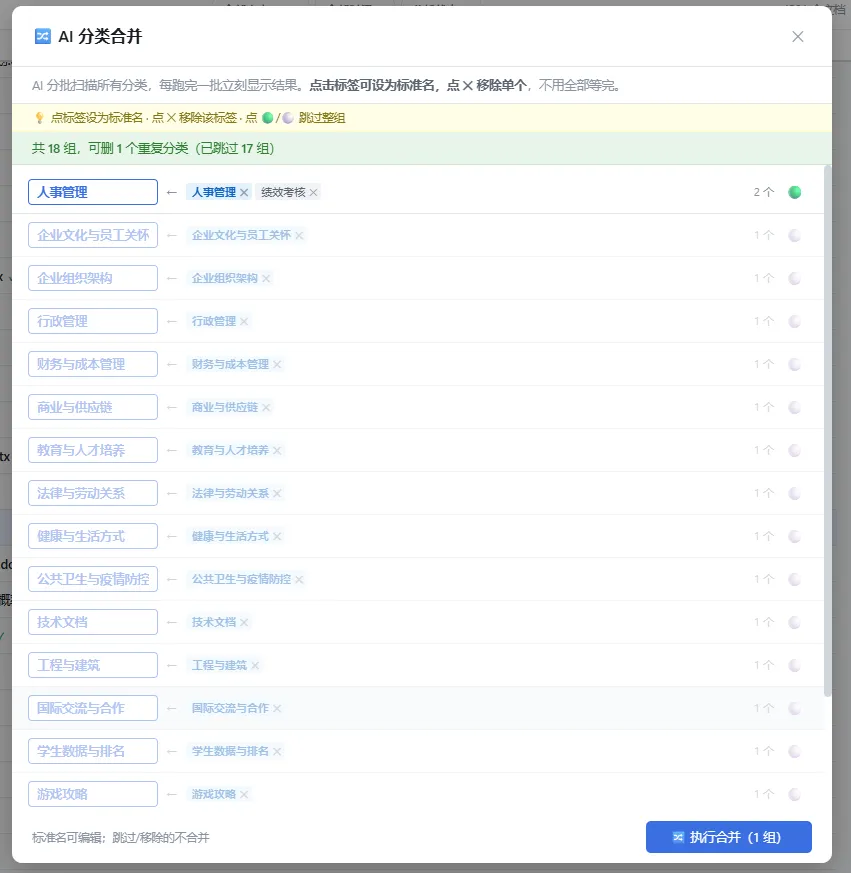
但这里踩了个大坑:2911 个标签一次性喂,AI 输出的 JSON 太大,全部超时失败。
最终方案:流式分批。每批 80 个标签,每跑完一批立刻把结果显示给用户。用户能:
▶ 点标签设为标准名(不用打字)
▶ 点 ✕ 移除不合理的单个标签
▶ 跳过整组
而且这个合并只调几次 AI(喂的是标签名列表,不是文档内容),每批几秒,不像 4000 文档那样要 9 小时。
2911 个标签 → 几百个标准标签。分类也从 53 个碎分类归并到十几个。
取个名字:好找
工具做完,得有个名字。一开始 AI 给我列了一堆——「拾贝」「归档」「DocBox」「文档管家」……都行,但都差点意思。
直到我脑子里冒出两个字:好找。
为什么是这两个字?因为这个工具从头到尾解决的,就是一件事——文件找不到。
▶ 导入,是为了好找
▶ 搜索,是为了好找
▶ AI 整理,是为了好找
▶ 重复检测、规则分类、合并……全都是为了让几千个文件,好找
用户听到这两个字,不用解释就懂它是干嘛的。像「得到」「知乎」一样,简单到反而高级。
slogan 也自然出来了:「你的文档,好找。」
Logo 我让 AI 用 Python 画了一个——深蓝圆角方块(信任感),白色文档卡片带横线(文档),右下角橙色放大镜(找到的意象)。深蓝稳重,橙色是「找到了」的惊喜。

最终:好找 V2.0 是个什么东西
一句话:本地优先的智能文档管理工具,几千个文件也能批量管明白。
完整能力:
📥 导入搜索 — 全格式 + 全文搜索 + AND/OR 语法 + OCR + 虚拟滚动
🔁 重复检测 — 哈希去重,一键清理
🏷️ 规则分类 — 关键词/类型/路径自动归类,默认规则开箱即用
⚡ AI 队列 — 限速保护 + 真实预估 + 暂停/停止
🔀 AI 合并 — 标签/分类流式合并
🔍 筛选 — 类型/大小/时间/分析状态
🗂️ 批量操作 — 分类/改名/标签/删除
核心是那条流水线:重复检测 → 规则分类 → AI 队列 → 合并整理。
不是 4000 个全交给 AI,而是先用免费的规则砍掉 80%,只让 AI 处理真正需要智能判断的 20%。既快、又省、又准。
这一版教会我的事
第一,UI 不能骗用户。
「几秒」实际 18 分钟,这种文案比 bug 更伤信任。真实预估、流式显示,这些不是「锦上添花」,是「必须做」。
第二,AI 的输出必须人审核。
2911 个标签全信 AI,库就毁了。流式分批 + 边看边改,是让「AI 高效」和「人把关」共存的方法。
第三,工具不需要无限加功能。
V2.0 做完,核心闭环完整了,我反而砍掉了关联图谱(那是 Obsidian 的事,不是文档管理的核心)。少做但做透,比什么都想做强。
隐私
▶ 文件不离开本地,只记录路径和索引
▶ 数据库纯本地,无远程连接
▶ AI 你说了算:云端 API 或本地 Ollama(完全免费)
好找 v2.0 · 你的文档,好找
GitHub:github.com/adams914/DM-tools
下载:github.com/adams914/DM-tools/releases
本文记录好找 V2.0 的开发。工具由作者与 ZCode(GLM-5.2)协作完成——人负责需求、决策、测试、纠偏,AI 负责把想法变成可运行的代码。
创建时间:2026-06-26
文章类型:AI编程实战 · 产品迭代
工具:ZCode(智谱AI)+ GLM-5.2
