 夜雨聆风
夜雨聆风Codex Workflow Lab
AI Coding / Setup
先跑通模型、工具、项目和验证之间的最小链路
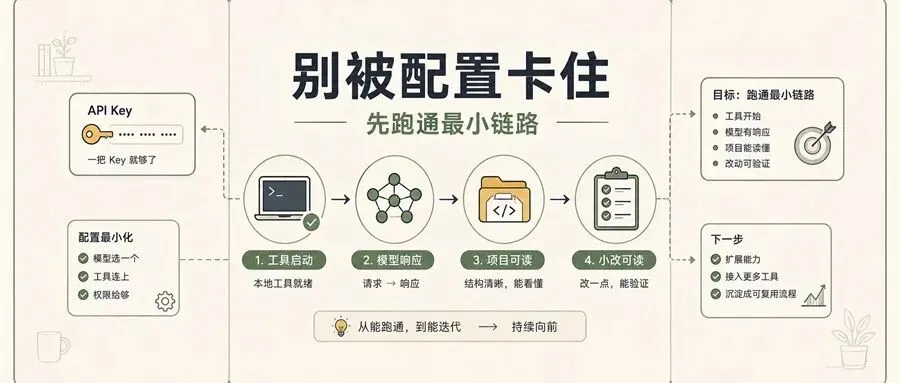
图注:别先追求复杂配置,先让 AI 编程链路稳定跑起来。
很多人想学 AI 编程,第一步不是卡在代码上,而是卡在工具入口上。
想用 Claude Code,发现账号、地区、订阅、额度都要处理;想用 Codex,又听说要配置模型、API Key、路由、环境变量。还没开始写一行代码,先被一堆名词劝退。
这件事挺可惜的。
因为 AI 编程真正该学的,不是“怎么折腾某个工具”,而是怎么把一个任务交给 AI,让它理解项目、生成方案、执行修改、跑出结果,再让你检查和迭代。
工具和模型很重要,但它们不应该成为第一道墙。
很多新手会把 Codex、Claude Code、Cursor、DeepSeek、Qwen 混在一起说。
但它们其实不是同一类东西。
Codex、Claude Code、Cursor 更接近“工作台”或“执行环境”。它们负责读项目、调工具、跑命令、改文件、展示 diff、管理上下文。
DeepSeek、Qwen、GLM、GPT、Claude 更接近“模型”。它们负责理解和生成。
简单说:
工具决定 AI 怎么干活,模型决定 AI 用什么脑子干活。
以前大家经常默认:某个工具只能配某个官方模型。现在情况变复杂了,很多工具开始支持自定义模型供应商,也出现了第三方切换工具,帮你把不同模型接进不同 AI 编程环境。
这带来了自由,也带来了风险。
自由在于:你可以根据成本、速度、上下文长度、模型能力选择不同后端。
风险在于:配置链路变长后,任何一个环节出问题,你都可能不知道是模型问题、协议问题、网络问题,还是工具配置问题。
所以,新手第一件事不是“把所有模型都接一遍”,而是先跑通一条最小可用链路。
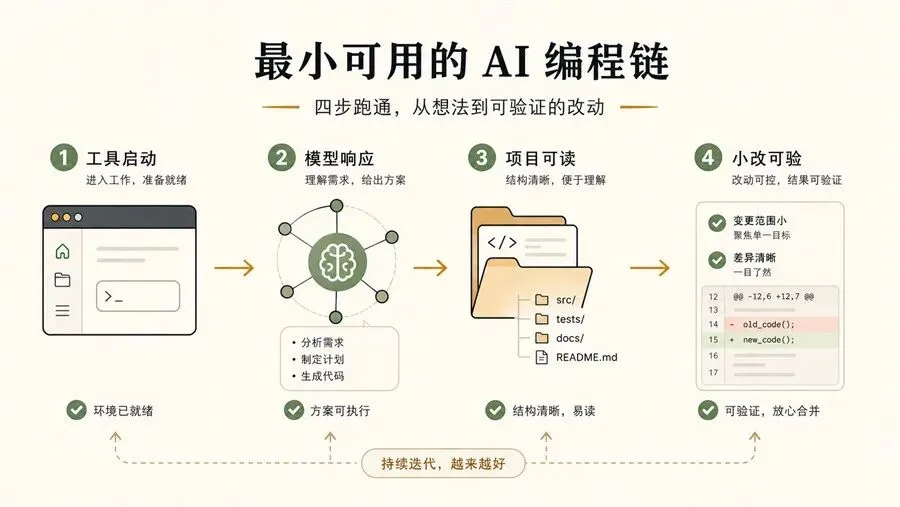
图注:先验证工具、模型、项目和小改动,再进入复杂任务。
所谓最小可用链路,就是让 AI 编程工具完成一个足够小、但完整闭环的任务。
它至少包含四步:
工具能正常启动。 模型能正常响应。 AI 能读到项目文件。 AI 能做出一个可检查的小改动。
比如你可以准备一个最简单的 HTML 页面,然后让 AI 完成一个小任务:
读取当前项目,把页面标题改成“我的第一个 AI 编程测试页”,然后告诉我你改了哪个文件。
这个任务看起来很小,但它能同时验证很多东西:
工具是否能访问当前目录。 模型是否能听懂需求。 文件写入是否正常。 修改结果是否可追踪。
一旦这条链路跑通,你再去做复杂项目,心里就有底了。
如果第一步就让它开发一个完整系统,最后报错,你根本不知道问题出在哪。
原文提到的 CC Switch,本质上解决的是“配置太碎”的问题。
不同 AI 编程工具的配置文件不一样。有的写 JSON,有的写 TOML,有的要填环境变量,有的要配置 Base URL、API Key、模型名。
如果你手动改,每一个字符都可能出错。
第三方切换工具的价值,是把这些配置集中到一个界面里管理,让你不用每次都翻文档、找路径、改配置文件。
但你要理解:它不是魔法。
它做的事情通常包括:
保存不同模型供应商的 API Key。 写入对应工具的配置文件。 在多个模型之间快速切换。 必要时启动本地代理或路由,把请求转发到目标模型。
这对熟悉工具的人很方便。
但对新手,我建议先把它当成“配置管理器”,而不是“万能加速器”。
凡是涉及 API Key、代理、路由、本地服务的工具,都要注意三件事:
不要把 API Key 发给不可信的人或项目。 不要在重要项目里直接测试未知配置。 出问题时,先回到官方默认配置,确认工具本身没坏。
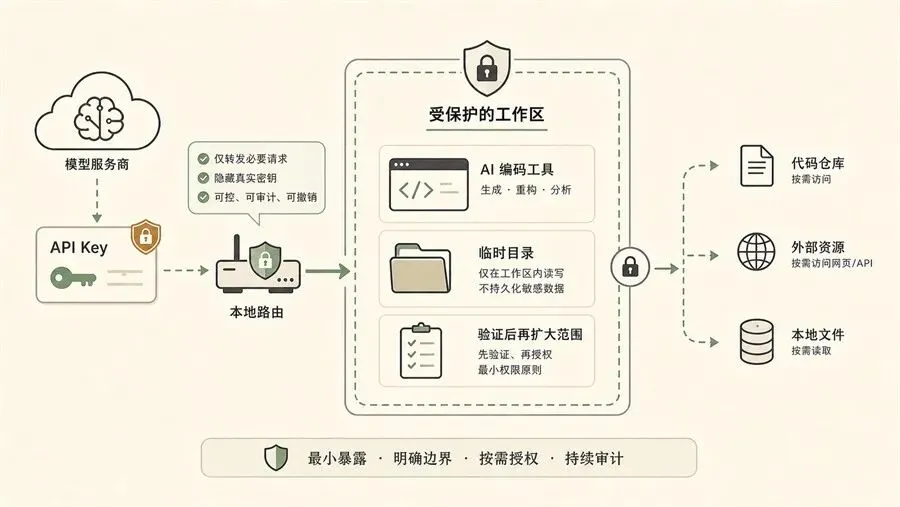
图注:模型接入越灵活,越需要先把密钥、路由和测试目录边界划清楚。
有些工具换模型很简单,填上 API Key 就能跑。
但 Codex 这类工具,可能会涉及协议差异。
你不能只看两个接口都叫“AI 接口”,就以为它们能直接互通。不同模型供应商支持的 API 格式、参数、流式返回、工具调用方式都可能不同。
这就像两个人都在打电话,但一个说中文,一个说法语。电话能接通,不代表能交流。
这时候中间就需要一层“翻译”。
在工具配置里,这层翻译可能表现为:
本地路由。 代理服务。 协议转换。 请求转发。
所以,如果你看到某个教程说“只要改一下 Base URL 就行”,要谨慎。
有些场景确实可以,有些场景会直接报错。
更稳的判断方式是:看这个工具到底使用哪种 API 协议,看目标模型供应商是否兼容,或者是否有成熟的转换层。
把模型接进工具,只是第一步。
真正要看的是:它能不能稳定完成你的任务。
AI 编程不是普通聊天。它需要模型理解项目结构、跟踪多文件修改、执行工具调用、处理错误、根据测试结果修正方案。
一个模型能回答问题,不代表它适合跑 Agent 任务。
你可以用三个小测试判断:
让它先总结项目结构,不要改文件。
看它能不能分清入口文件、配置文件、构建脚本和业务模块。
让它改一个很小的页面文案或配置项。
看它会不会乱动无关文件。
让它修改后运行测试、构建或本地预览。
看它遇到报错时,是认真排查,还是直接编一个“已完成”。
这三个测试通过了,才说明这条模型链路适合继续用。
很多人关注 AI 编程成本,这很正常。
但成本不应该只看单价。
更应该看一次任务的总成本:
模型是不是容易跑偏。 一次任务要重试几次。 上下文够不够用。 工具调用是否稳定。 生成结果是否容易检查。
有些模型单价便宜,但复杂任务反复失败,最后花掉的是时间。
有些模型单价高,但一次就能把项目结构理解清楚,反而更划算。
所以我更建议新手建立一个“模型分工”:
简单问答、文案、轻量代码:用便宜模型。 项目理解、多文件修改、复杂 Agent 任务:用更稳的模型。 重要项目:先备份,再动手,不拿生产文件试验。
省钱没问题,但不要为了省几块钱,把调试成本和数据风险放大。
如果你刚开始学 AI 编程,可以按这个顺序来:
先选一个工具,别同时折腾五个。 先用官方默认配置跑通一个小项目。 再尝试接一个替代模型。 接入后只做小任务测试。 确认读写文件、运行命令、测试反馈都正常,再进入真实项目。
不要一上来就追求“最强配置”。
AI 编程真正重要的是任务拆解、上下文管理、结果验证,而不是工具截图里显示了哪个模型名。
尤其是 Codex、Claude Code 这类能操作文件和命令的工具,你要学会给它边界。
第一次测试时,最好只给它一个临时目录。
不要让它碰你的论文、合同、客户资料、生产代码仓库。
账号、模型、订阅、API Key,这些问题确实会让 AI 编程的第一步显得有点麻烦。
但它们不是核心问题。
核心问题是:你能不能跑通一条稳定的 AI 工作链路。
工具能打开,模型能响应,项目能读懂,修改能追踪,结果能验证。只要这条链路跑通,你就已经跨过了 AI 编程最关键的一步。
后面换模型、换工具、换供应商,本质上都是优化。
别一开始就被配置吓住。
也别因为某个教程说“几分钟搞定”,就把自己的 API Key、项目文件和重要数据一股脑交出去。
真正稳的做法,是先小范围试,先看清楚每一步发生了什么,再把它放进你的日常工作流。
AI 编程不是比谁接的模型多。
而是比谁能把任务稳定交给 AI,并且知道怎么验收它的结果。
如果这篇内容对你有帮助,欢迎继续关注后续更新。
