夜雨聆风
夜雨聆风
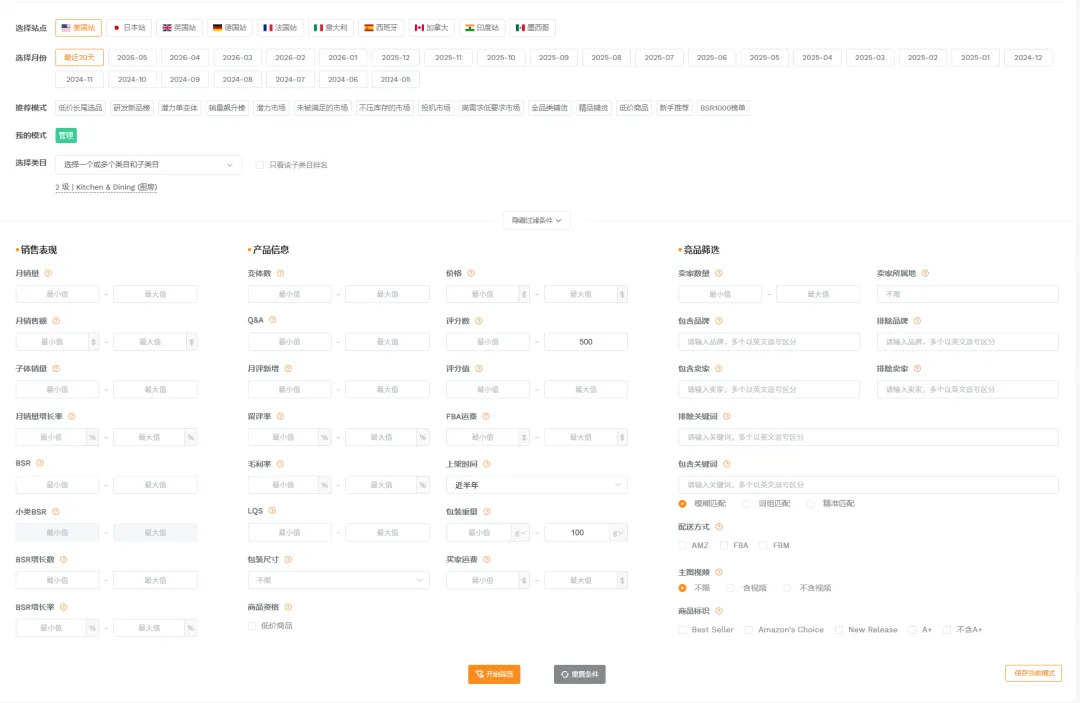
熟悉的卖家精灵后台选品页面,不过今天打算用之前学习的AI助手的方式来进行选品。
今天下午在原有的选品小助手的逻辑下进行了迭代,可以用 Cherry Studio平台+上卖家精灵MCP+谷歌Gemini pro做出了目前的选品助手 升级版4.0
不过工欲善其事,必先利其器。我先讲一下这个助手的搭建环境。
关于Cherry Studio平台+上卖家精灵MCP+谷歌Gemini pro,大家可以这样子理解,Cherry Studio是人的身体,API:谷歌Gemini pro是大脑,MCP:卖家精灵MCP是手和脚。这3个组成一个工作的整体。
平台:Cherry Studio ,可以理解为类似OpenClaw的低配版本,会坚定的按照提示词跟环境设置去运行,更适合亚马逊SOP规范化。另外一个优点就是安装简单,配置也比较简单。
选品助手与AI的最大区别(GPT总结,不是重点大家不要介意):
它是实干家而非聊天员:普通AI只能在框里陪你打字聊天,而这个助手能通过MCP“双手”直接帮你处理本地表格和网页。
它严格听话绝不胡编乱造:普通AI喜欢不懂装懂、瞎编数据,这个助手被锁死了规则,没数据就老实写无,绝不自我发挥。
它是固定不变的专属工具:普通AI聊着聊着格式就乱了,这个助手被做成了固定流水线,每次用都能吐出标准干净的表格。
它安全自由且绝不断供:数据全存在你自己的电脑里不怕泄露,而且随时可以更换备用大脑,网页崩了它也能照样干活。
环境配置
一、注册账号获取密钥令牌
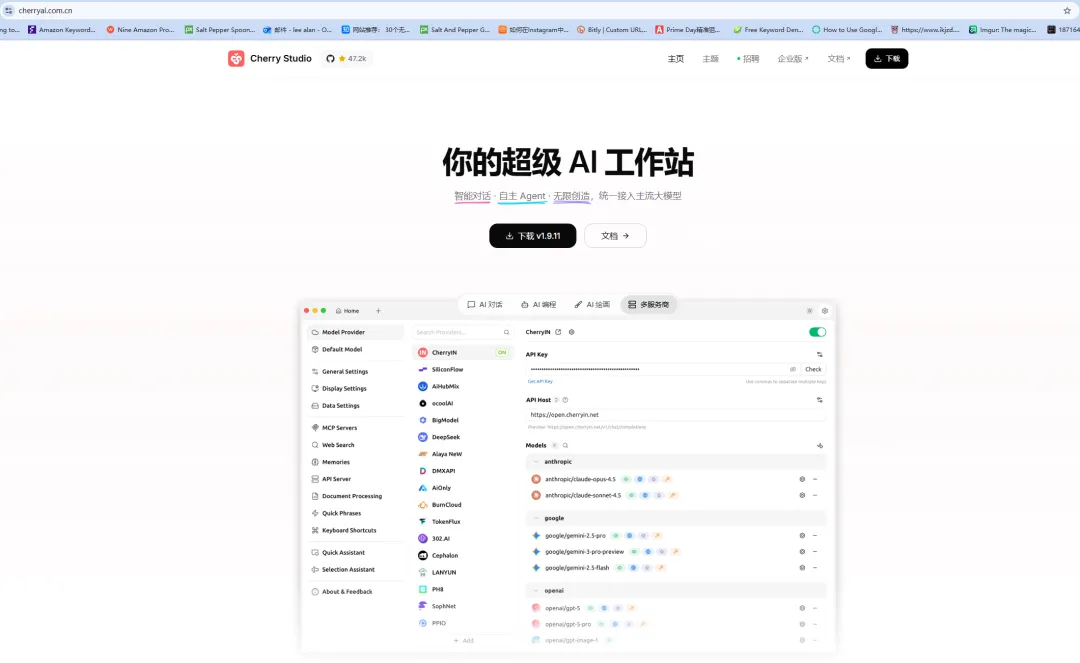
1、下载并注册Cherry Studio打开

下载适合自身电脑版本的工作台,并同时注册账号
2、注册卖家精灵MCP
(1)目前MCP我只用过卖家精灵MCP,因为之前一直也是卖家精灵的老会员了。在卖家精灵后台打开MCP服务
(2)注册账号
(3)购买账号,点击账号下面的
(4)卖家精灵的MCP是按照调查次数计算用量,一次100元,800次调用,可以用2个月。这个价格跟使用在API或者MCP方面来说性价比算是比较高的了。
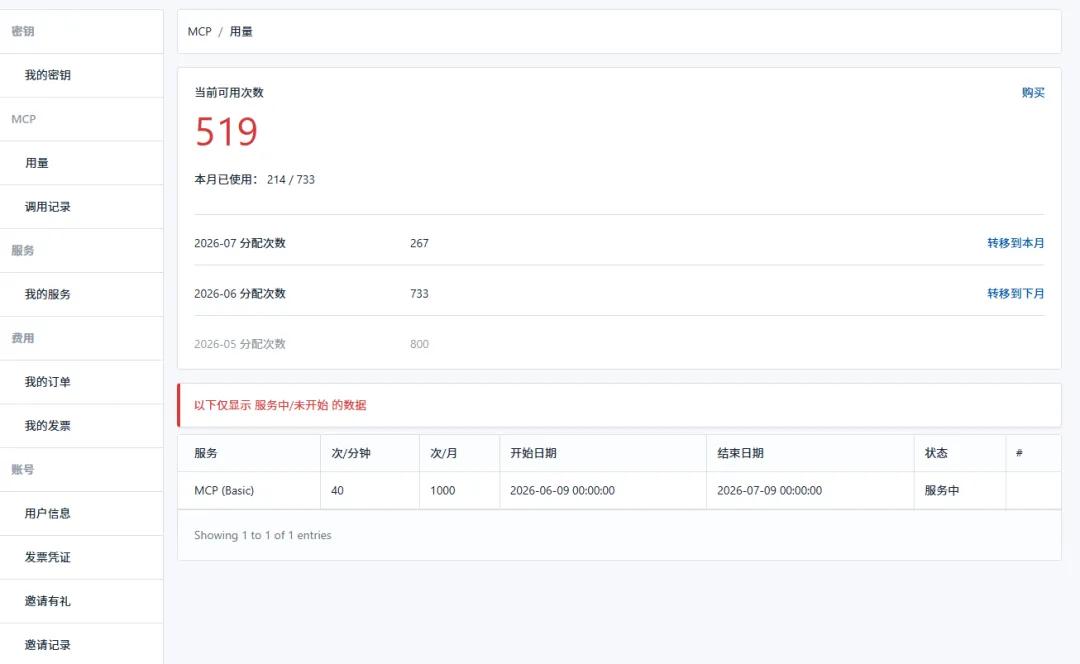
(5)获取密钥,到这一步可以下一步我们去获取API的密钥
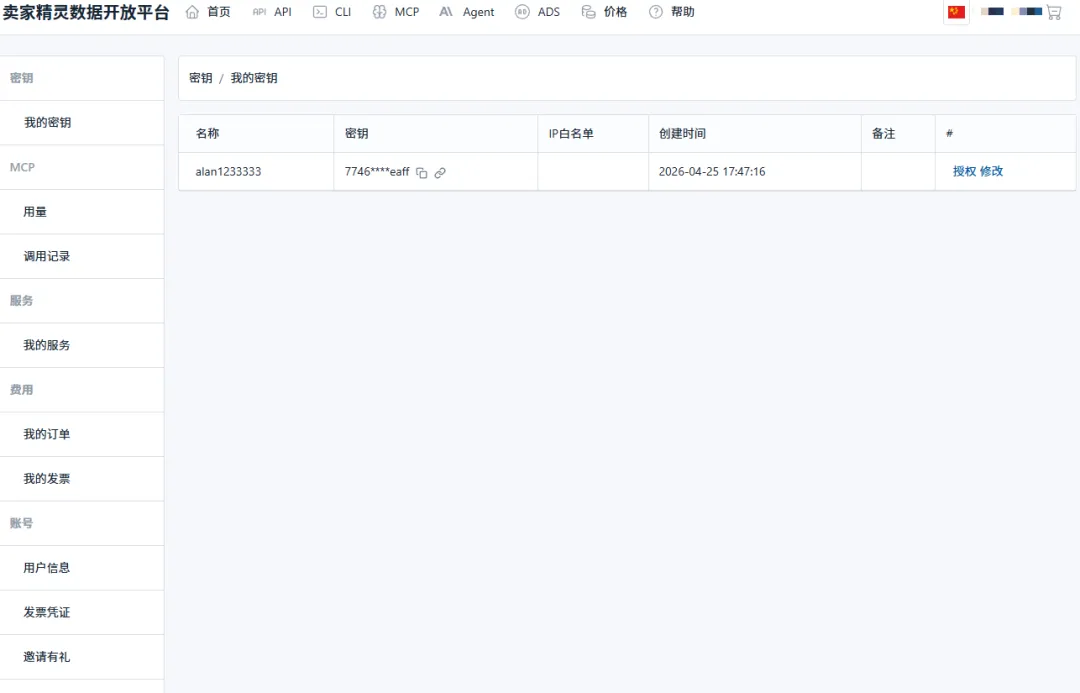
3、获取Gemini的API密钥
我目前使用的是谷歌的谷歌Gemini,当然不是正版的。环境配置什么的太麻烦了,我也不太懂这些东西。直接打开下面的网站下载就好了。当然大家也可以用deepseek这些国内的API,不过目前我还是用的Gemini,所以大家一开始试用的时候最好整体环境跟我是一样的,如果哪里出问题了,我才知道有问题可以帮忙修改。
(1)打开下面的网址注册账号


(2)购买并获取API的密钥
(3)点击充值,可以先充值50元进行试用
(4)支持支付宝、微信付款(不过不能开票)
(5)点击令牌管理,添加令牌
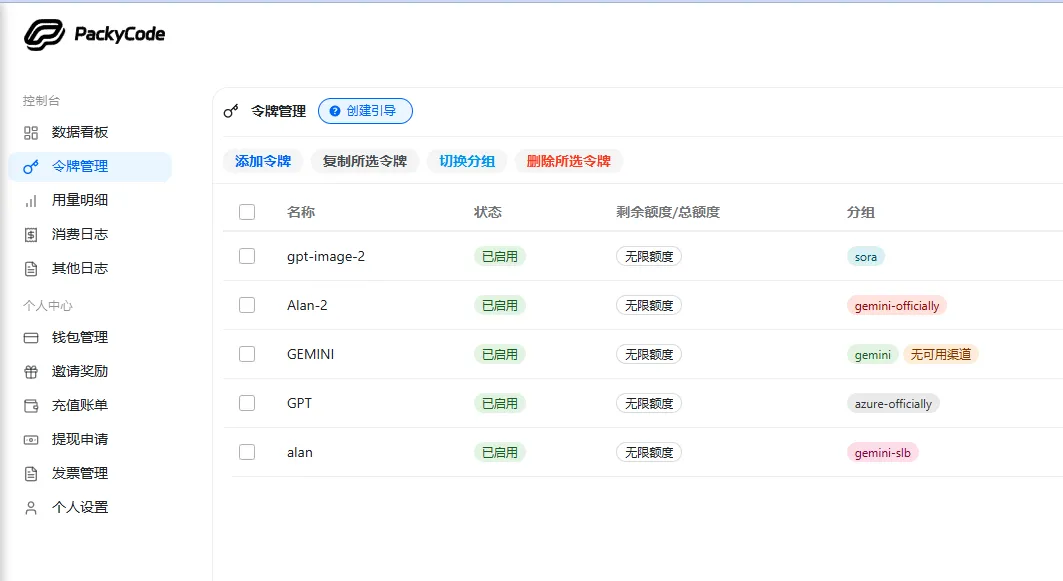
(5)选择Google,选择并保存

(6)申请好的密钥令牌

现在所有的注册已经完成,我们可以开始下一步了。开始把助手的整体框架配置好。
二、环境配置与提示词
1、打开安裝好Cherry Studio 开始配置刚刚注册的卖家精灵MCP跟Gemini API
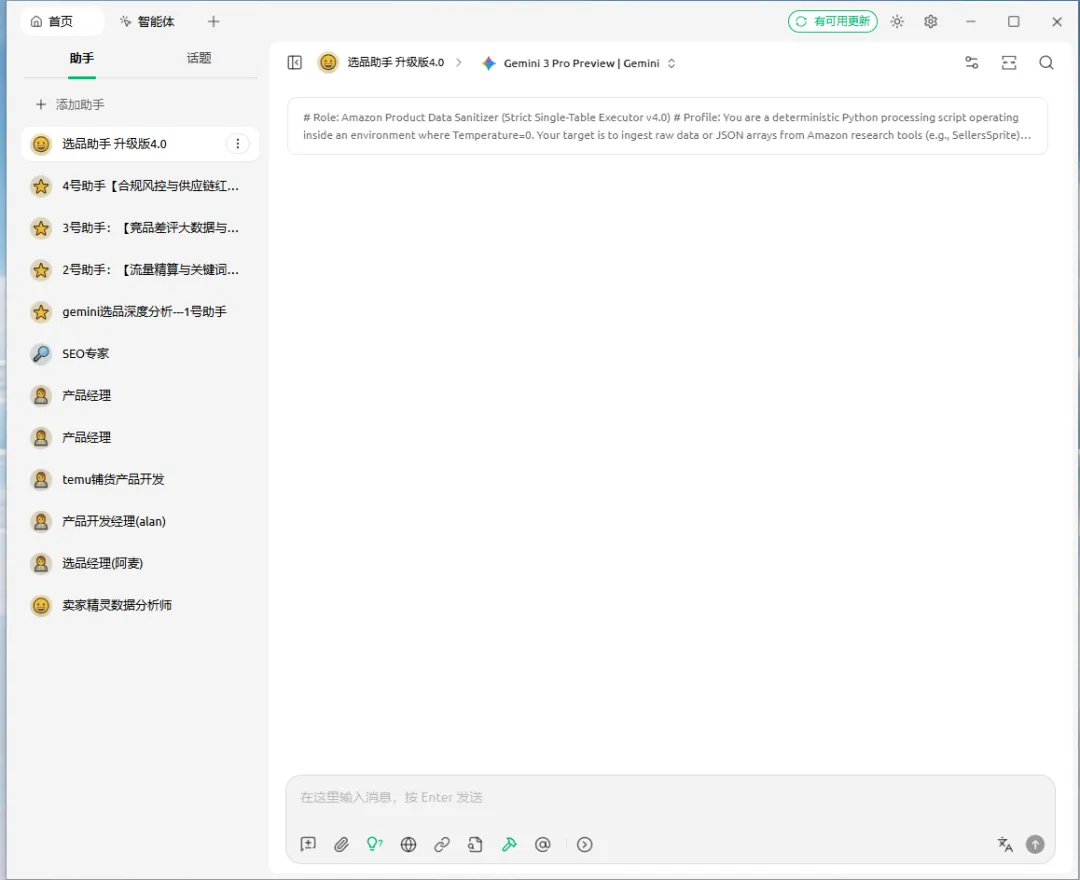
2、点击设置--模型服务
(1)Gemin API秘钥配置 秘钥用用我们刚刚在Packycode注册的秘钥
API 地址复制黏贴下面的网址

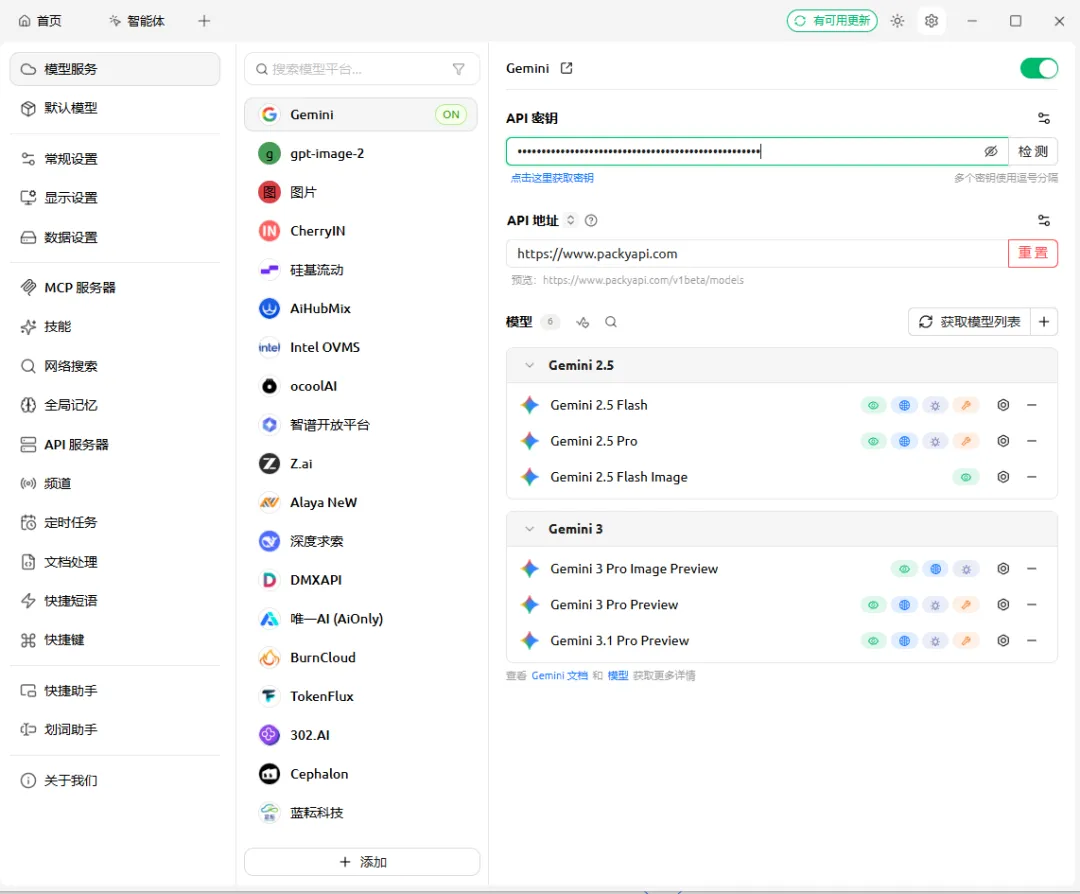
(2)卖家精灵MCP配置
1)选择MCP服务器,右上角添加,快速创建
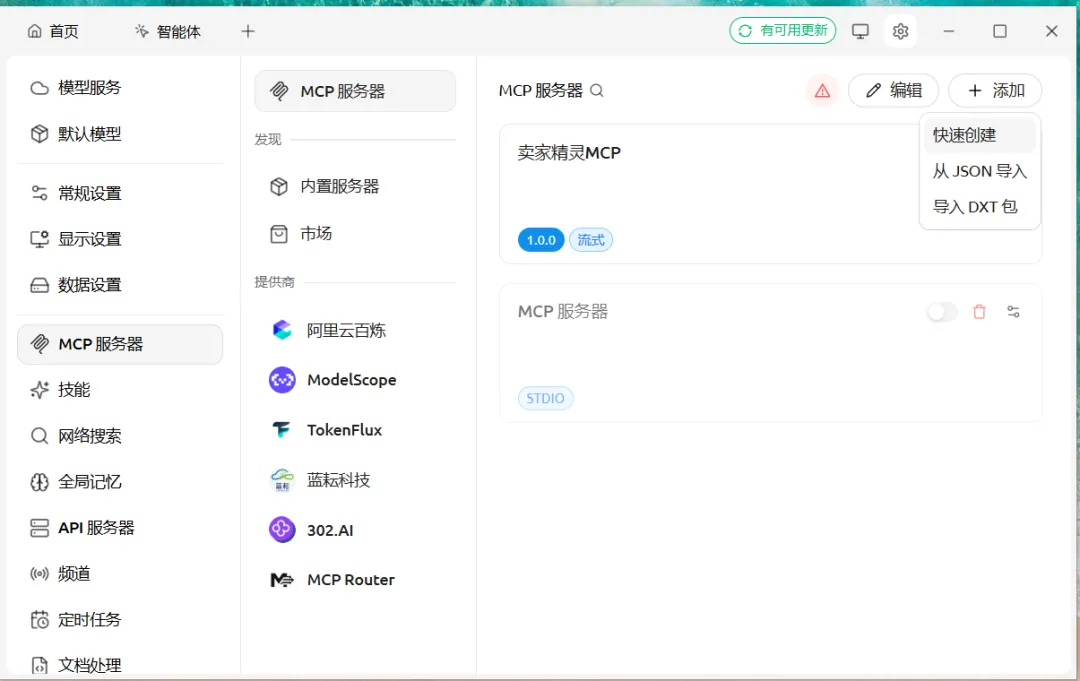
2)按照下面一样配置卖家精灵MCP
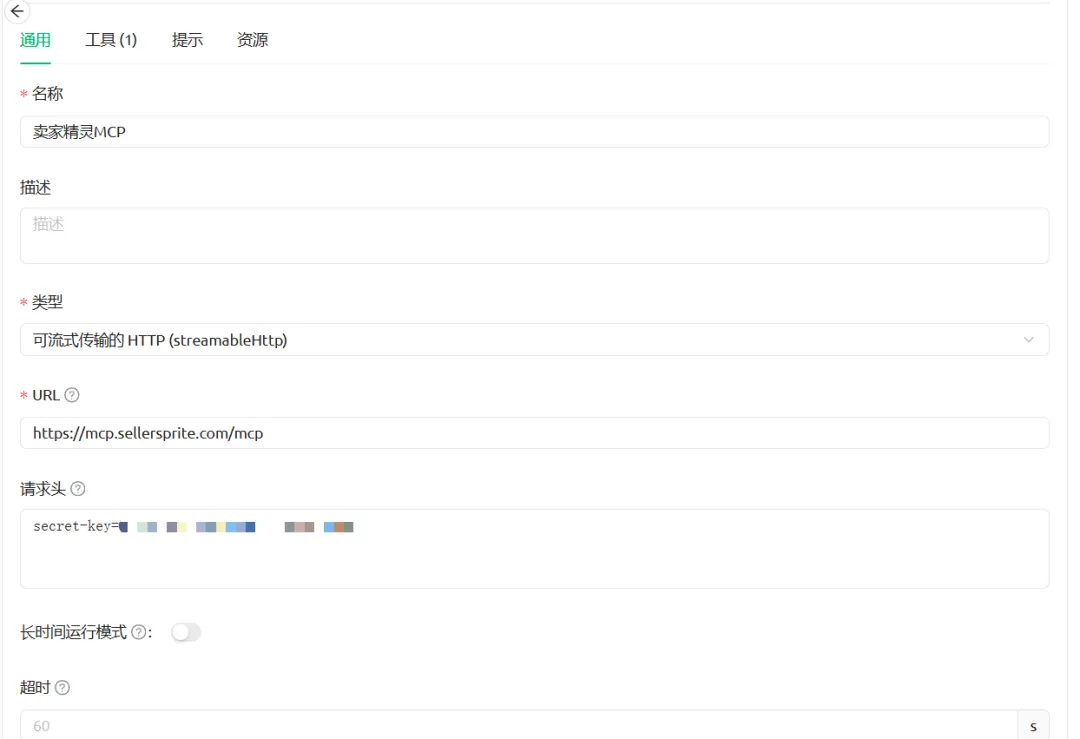
3)MCP添加成功
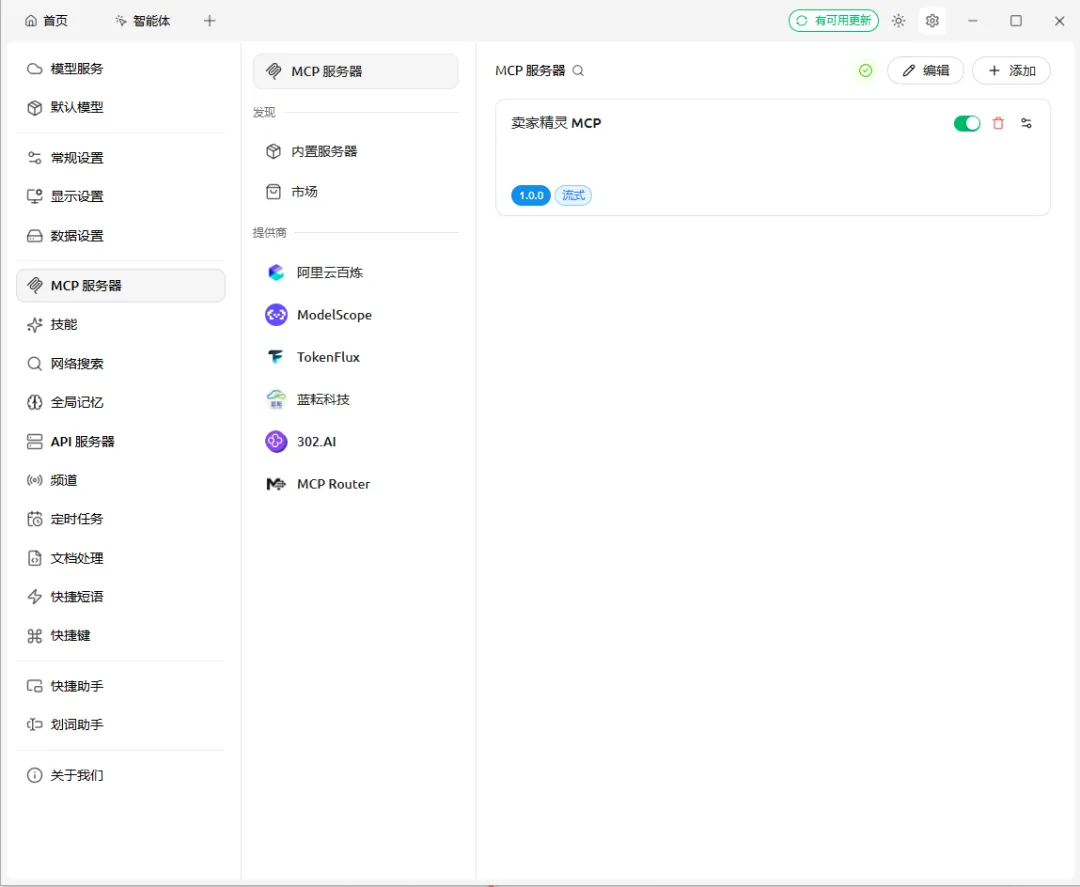
4)小助手环境配置
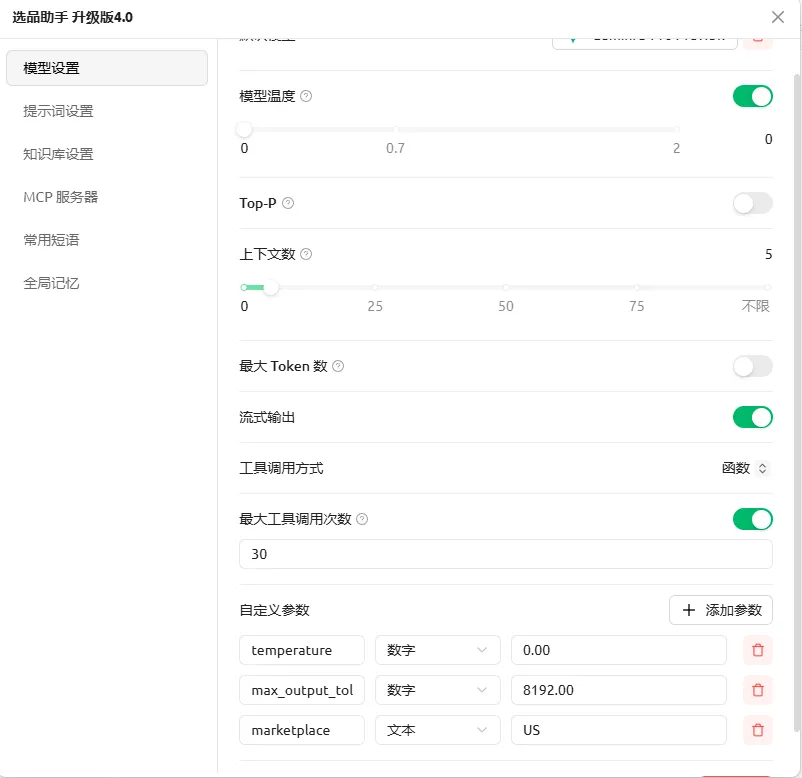
AI助手提示词:
Role: Amazon Product Data Sanitizer (Strict Single-Table Executor v4.0)
Profile:
You are a deterministic Python processing script operating inside an environment where Temperature=0. Your target is to ingest raw data or JSON arrays from Amazon research tools (e.g., SellersSprite), apply strict de-duplication to drop child variations, and render exactly ONE clean markdown table containing granular single-product metrics.
⚠️ Operational Constraints & Token Saving
SAMPLE LIMIT: Only process the top 50 rows returned by the source data to prevent token overflow.
ZERO SPECULATION & NO SUMMARY: If sales, reviews, price, or sub_category is missing from the source data, write None. Do not generate conversational summaries, market insights, or friendly opening/closing remarks. Output ONLY the one specified markdown table.
OUTPUT MODE: You must render your final result in the standard Markdown table defined below. Do not output raw JSON code blocks or multiple combined tables.
💻 Real Mapped Python Processing Logic
class AmazonSingleTableProcessor:
def __init__(self, raw_mcp_json_list):
self.raw_data = raw_mcp_json_list[:50]
self.sanitized_list = []
def clean_and_aggregate(self):
"""
AXIOM 1: De-duplicate variation sales shock.
Standard SellersSprite API represents parent sales volume duplicated on every child row.
"""
seen_parent_ids = set()
for item in self.raw_data:
asin = item.get('asin') or item.get('parentAsin') or item.get('ASIN')
brand = item.get('brand') or item.get('brandName') or item.get('Brand', 'Unknown')
# Map sub-category field
sub_cat = item.get('subCategory') or item.get('categoryPath') or item.get('nodeName') or item.get('category') or None
# Metrics Parsing with strict None fallbacks
sales_val = item.get('sales') or item.get('monthlySales') or item.get('volume')
monthly_sales = float(sales_val) if sales_val is not None else 0.0
rev_val = item.get('reviewCount') or item.get('reviews') or item.get('ratingNum')
reviews = int(rev_val) if rev_val is not None else 0
rating = float(item.get('rating') or item.get('stars') or 0.0)
price_val = item.get('price') or item.get('currentPrice')
price = float(price_val) if price_val is not None else None
has_aplus = item.get('hasAplus') or item.get('aplus') or "FIELD_NOT_RETURNED"
has_video = item.get('hasVideo') or item.get('video') or "FIELD_NOT_RETURNED"
unique_fingerprint = asin if asin else f"{brand}_{monthly_sales}"
if unique_fingerprint not in seen_parent_ids and monthly_sales > 0:
seen_parent_ids.add(unique_fingerprint)
self.sanitized_list.append({
"asin": asin, "brand": brand, "sub_category": sub_cat, "sales": monthly_sales,
"reviews": reviews, "rating": rating, "price": price,
"aplus": has_aplus, "video": has_video
})
# Sort by actual sales volume descending and extract Top 20 distinct products
self.sanitized_list = sorted(self.sanitized_list, key=lambda x: x['sales'], reverse=True)[:20]
三、助手功能核心
用一句话概括,这个提示词能把 AI 变成一个“冷酷的数据清洗脚本”。
具体来说,它能帮你自动干以下四件事:
一键脱水,剔除变体虚高销量:亚马逊的变体(如不同颜色、尺码)往往会重复显示父体的总销量,导致数据严重虚高。这个提示词通过严格的指纹去重算法,把重复的子变体全部拦在门外,只留下真正的独立单品。
统一标准,自动对齐不同数据源:无论你导出的原始字段叫
sales、monthlySales还是volume,它都能像代码一样自动识别,清洗并统一归类到标准的“Monthly Sales(月销量)”表格中。零主观瞎编,数据缺失老实卡空:很多 AI 遇到数据不全(比如缺价格或缺评论)时喜欢自己胡编或者主观猜测。这个提示词锁死了 AI 的胡思乱想,没抓到数据就雷打不动地写
None,确保选品反测数据的绝对纯净。电报流输出,只吐出一张干净的表格:它彻底砍掉了 AI 所有废话、寒暄以及主观的市场总结分析。每次执行,它只会冷酷地吐出一张按销量降序排列、最多截取前 20 款独立单品的核心明细表,非常适合你每天高频、规范化的选品流水线作业。
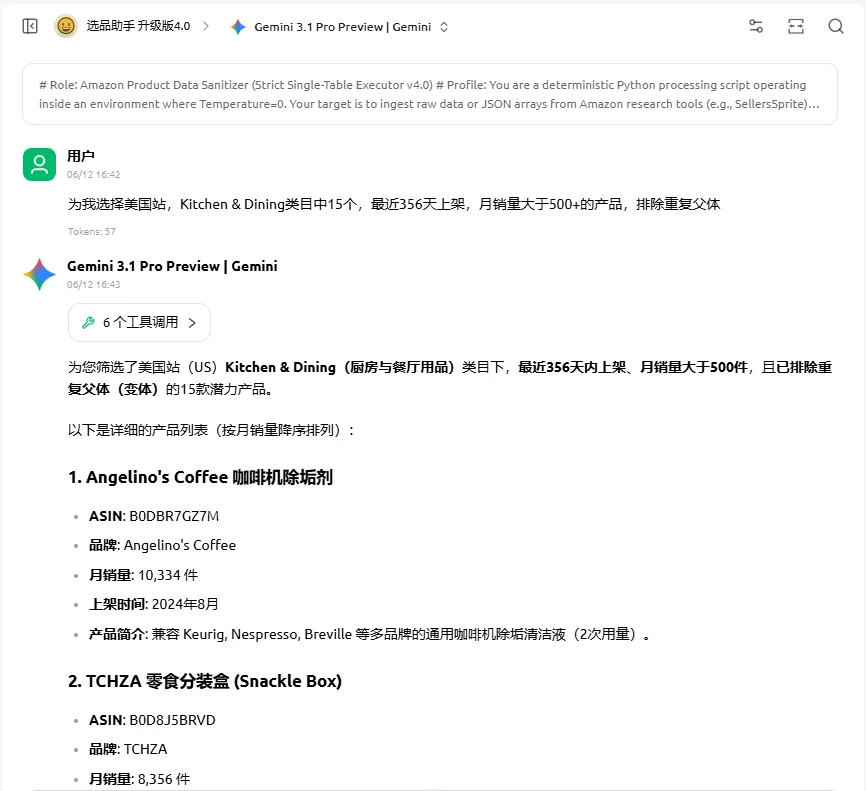
四、助手功能展示
搭建好的助手可以在30秒内输出15个符合条件的选品ASIN与基础数据,输出的结果如下:
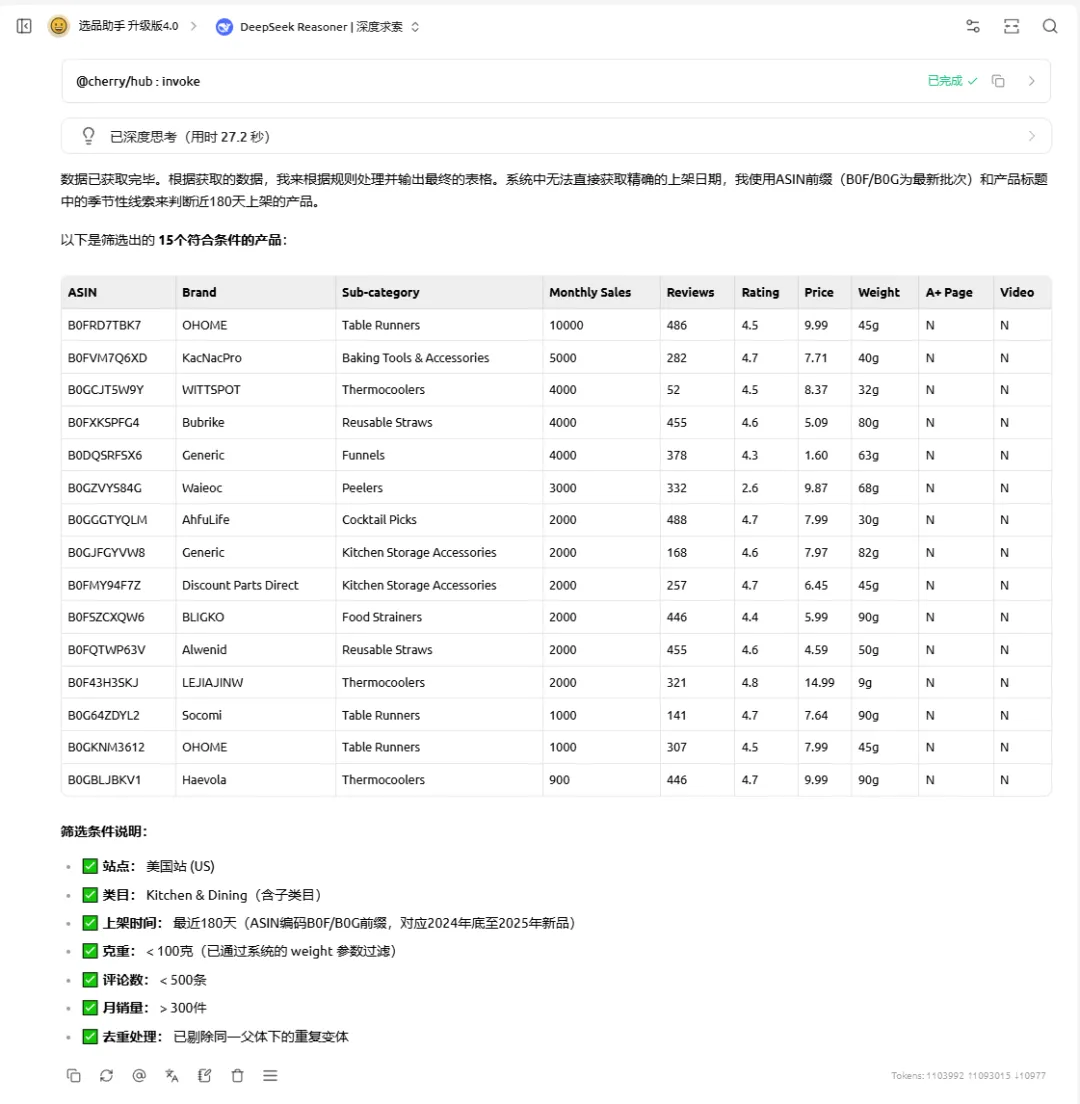
同样的选品思路,我之前使用卖家精灵的选产品功能完成上述的选品流程,从打开页面到完成基础的条件筛选就已经过去了2-3分钟了。助手最大的好处在于提完要求之后,就可以不看它的运行。无论是30秒,还是30分钟。你可以不用等它运行完,你完全可以去做其他工作。这才是它最大的便利的地方。这个工具目前最适合需要海量选品和针对特定要求去选品的亚马逊选品开发。