 夜雨聆风
夜雨聆风老板发你一个PDF报告,让你「用AI总结一下」。你打开ChatGPT,把PDF传上去,有时候AI会告诉你文件太大没法读,有时候读出来全是乱码。你又试了Word版,表格全乱了。又试了PPT,图片识别不全。
折腾半小时,最后你只能手动复制粘贴,把文档内容一段段喂给AI。
这个痛点,微软替你解决了。
2026年6月,GitHub上有一个项目一个月涨了3.4万星,飙星榜第一。161k总星。微软官方出品。名字叫MarkItDown

它就干一件事,把所有格式的文档,一行命令转成Markdown。而Markdown是所有AI大模型最喜欢、读得最准的格式。
总星161k 月增+34k 协议MIT 团队微软AutoGen |
支持的输入格式(20+种)
PDFWord (.docx)PowerPoint (.pptx)Excel (.xlsx)图片 (jpg/png,含OCR和EXIF)音频 (mp3/wav,含语音转写)HTML网页CSVJSONXMLZIP压缩包YouTube链接EPUB电子书

YouTube链接直接能转。你丢一个YouTube视频地址进去,它把字幕扒出来转成Markdown。做内容的人研究竞品视频,这个太好用了。
音频能转。mp3文件丢进去,它帮你语音转写成文字。开会录的音,直接变会议纪要。
ZIP压缩包能转。不用解压,直接丢进去,它自动遍历里面的所有文件逐个转换。批量处理的时候省事。
图片能OCR。截图、扫描件、带图表的页面,它能识别成文字。
如果接了GPT-4o,还能做图片描述。
怎么用?真的就一行命令。
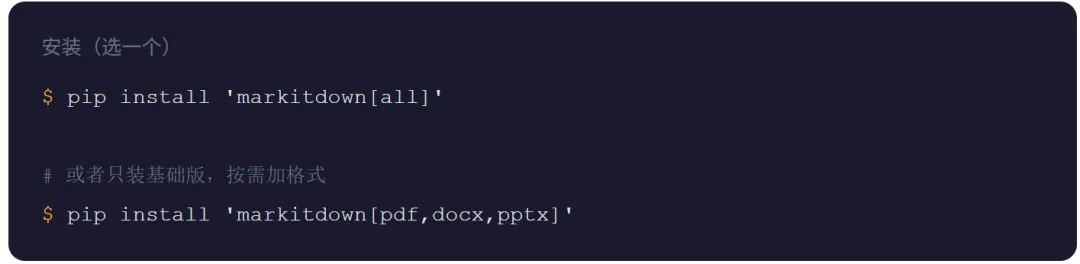
先安装。
然后就能用了。


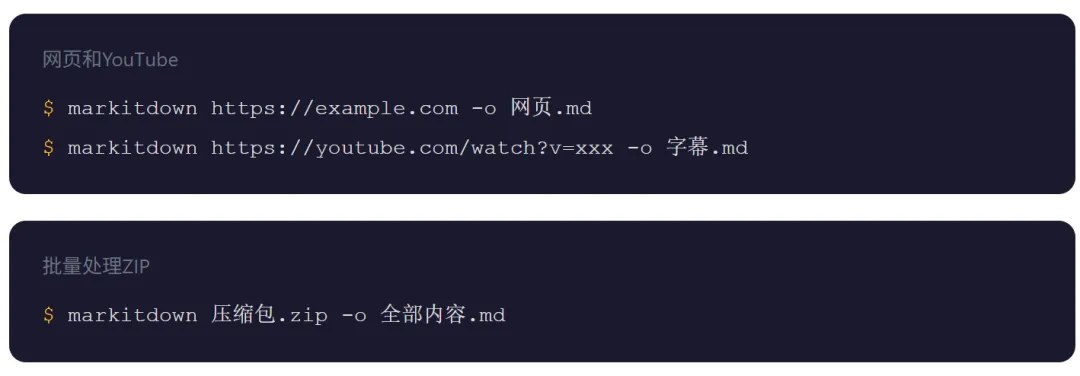
你看到了吧。不管什么格式,都是同一个命令,换个文件名就行。这就是它最厉害的地方,统一的入口,统一的输出。
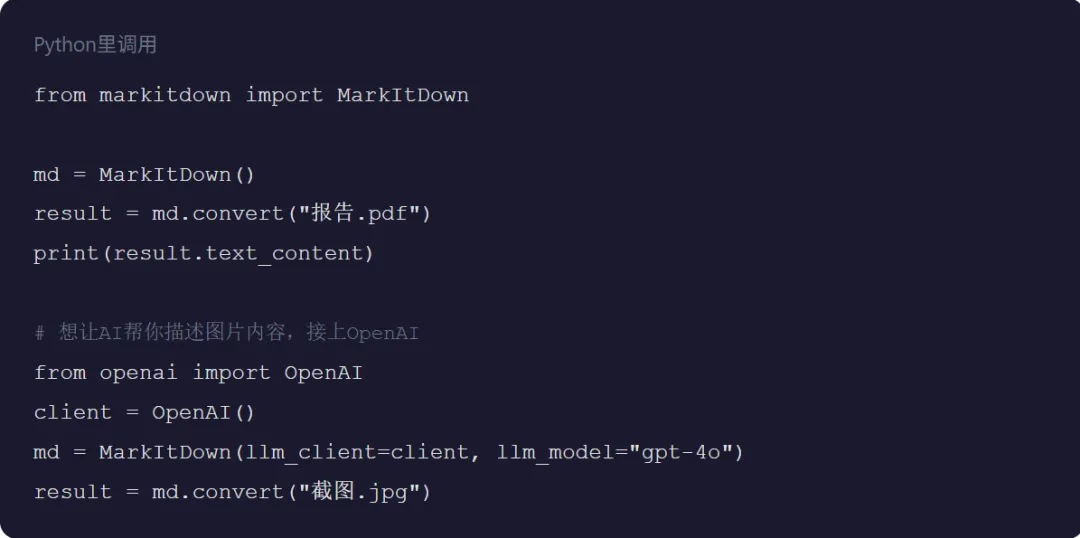
如果你会Python,还能当库用,塞进自己的脚本里。
工具好用,但有几个坑你要知道。
⚠️ 第一,复杂PDF的阅读顺序不一定对。多栏排版、脚注特别多、页眉页脚复杂的PDF,转出来的顺序可能会乱。建议转完抽查一下,别全信。⚠️ 第二,OCR和图片描述要额外配置。想让它识别图片里的文字,要么装OCR组件,要么接GPT-4o。接GPT-4o是要花钱的,处理一批图片几个美元很正常。⚠️ 第三,Markdown不保留排版。它不是高保真转换器,表格能保留但样式会丢,图片会变成文字描述。如果你的目的是「让AI读懂」,这些不重要。如果你的目的是「完美还原文档」,这个工具不适合你。
微软这次做的工具,没花架子,没噱头,就是踏踏实实解决一个问题。161k星不是白涨的。
你装一个试试。下次老板再发你PDF说「AI总结一下」,你5分钟就能交差。
我是Neil,感谢你的阅读
希望你永远对世界保持好奇
如果这份文档对你有帮助,欢迎点赞、转发、推荐!
点赞 · 转发 · 推荐
THANKS FOR READING
