 夜雨聆风
夜雨聆风
本来想写一个26年上半年AI圈的大事盘点,harness、loop、FDE、DeepSeek融资、Claude Fable5...
但回顾完所有的新闻,我看到了一个趋势:
AI正在进入现实世界,完成真实的工作。
这个趋势将决定和AI有关的钱和机会将会流向哪里。
在正文开始之前,我想要提一下去年我看到的一个反直觉的事情:
2025 年,MIT 的报告《State of AI in Business 2025》说,约 95% 的企业引入生成式 AI,没有产生任何可见的经济回报。
同一时期,2024 年诺贝尔经济学奖得主、MIT 的阿西莫格鲁(Daron Acemoglu)测算,未来十年 AI 对全要素生产率的拉动顶多 0.5% 到 0.7%,对经济的影响小到几乎可以忽略。
一边是「AI 要取代人类」喊得震天响,许多人也开始使用AI提高自己的工作效率,可AI对于经济的影响还不太能看见。
为什么?
01跨越数字世界与现实世界的鸿沟
其实MIT那份报告已经把原因写清楚了:模型和实际工作之间有一道鸿沟。
如果你在网页中用过 AI,你肯定知道AI没有记忆、不会适应场景、也不会随业务一起成长。
对于企业来说,AI对于已有的工作流程、文档、项目背景也一无所知。
而且要改造工作流程,企业内部也会有阻力。
因此,AI只是“纸上谈兵”,根本没法在真实的工作环境里落地。
解决方案就藏在最近很火的两个概念里:Harness 和 FDE。
Harness 补全技术,FDE帮助落地。
harness engineering:驾驭AI
harness 直译挽具,是驾驭马的工具,比如缰绳、马镫。harness engineering 顾名思义,就是一整套驾驭 AI 的方法和框架,目标是让 AI 按照人们预期的要求,稳定交付有价值的工作成果。
具体而言,harness 就是给模型外面装上几样它本来没有的东西:
1.记忆,让模型记得住上次聊到哪、这个项目的来龙去脉。
2.工具调用和权限,让它能去查数据库、改文档、发邮件。
3.上下文管理,保证AI每一步都看到该看的资料。
4.可复用的技能(skill),把「审合同」「写文档」这种活,固化成它随时能调的标准动作。
所有这些合起来形成一套系统,模型才从一个「会聊天的大脑」,成长为一个能在真实流程里干活的系统。

AI 工程的三个阶段
2022 到 2024年,prompt engineering(提示词工程):如何向 AI 提问。 2025年,context engineering(上下文工程):如何管理 AI 该看到的信息。 2026年,harness engineering(挽具工程):如何怎么驾驭 AI,让它真正变成生产力。
前两个阶段的重心都在「怎么跟模型说话」,第三阶段开始关注「模型周围那套系统怎么搭」,才能让AI少出错完成任务。
有一句总结很到位,「Agent = model + harness」。
Claude Code、Codex、WorkBuddy 这些你听过的产品,都是 harness engineering 的具体体现。
FDE:把AI带进生产环境

OpenAI 官网正在招聘的 Forward Deployed Engineer(前沿部署工程师)岗位
FDE(Forward Deployed Engineer),中文叫前沿部署工程师。
如果说 harness 是让 AI 在产品里干活,FDE 就是把这一套能干活的 AI,落实到企业的真实业务场景里。
早在 2000 年,Palantir 就创造了FDE这个岗位。
众所周知,Palantir 的主要业务是用大数据给美国情报机构做咨询服务,他们的产品没法打包交付、装好走人,只能派工程师钻进客户内部,一边搞懂业务,一边在对方的系统里把方案搭出来。
AI的处境和上面说的情况比较类似。每家公司的业务流程都完全不同,想要把AI部署进生产环境,需要为每一家公司提供定制化服务。
于是, Anthropic(5 月 4 日):联手黑石、高盛、Hellman & Friedman,约 15 亿美元,成立 AI 原生的企业服务公司,把工程师 + Claude 嵌进中型企业核心流程,公开说就是来抢麦肯锡这类咨询生意的。
OpenAI(5 月 11 日):成立 The Deployment Company(部署公司),连麦肯锡、贝恩、凯捷这类传统咨询公司都成了投资人。
两家AI巨头都明说要把自己的工程师派进客户公司,把AI部署进真实的工作环境。
02 AI的地缘鸿沟
数字世界和现实世界之间的鸿沟相对会比较容易填上,但是另一道鸿沟已经横亘在中国和美国这两个超级AI大国之间。
美国:把最强模型锁进白名单
6 月 9 日,Anthropic 发布迄今最强的 Fable 5;6 月 12 日,美国商务部致函,要求禁止外国公民使用;6 月 13 日全面下架,前后四天,连 Anthropic 自家的外籍员工都被一并切断。6 月 26 日,OpenAI 发布最强的 GPT-5.6,干脆只发给美国政府批准的约 20 家公司。半个月内,普通用户能接触到的两个最强模型,一个被下架,一个进了白名单。最强的前沿闭源模型,正在从商业产品变成战略物资,能不能用上它,越来越是国籍和政治问题。

要把外国人挡在门外,光下架还不够,平台还要知道每个用户是谁。Anthropic 6 月更新隐私政策,7 月 8 日起可要求 Claude 消费版用户(Free / Pro / Max)提交政府证件、实时自拍和人脸扫描,交给 KYC 公司 Persona 处理,4 月中旬已经小范围试过;OpenAI 更早,2025 年 4 月就对 API 上的高级模型上了机构实名。匿名用最先进 AI 的时代即将结束。想用最强的模型,先得证明你是谁、是哪国人。
中国:叫停 Meta 收购 Manus
墙不是只有美国在砌。
2025 年 12 月底,Meta 决定以超过 20 亿美元买下 Manus(原蝴蝶效应 Butterfly Effect),这是 Manus 走红全球后第一次卖身,也是 Meta 史上第三大并购。
Manus 当时已经把总部迁到新加坡,从注册地算,已经是一家「外国公司」。
但中国监管没看它注册在哪。2026 年 1 月商务部启动评估调查,3 月发改委约谈双方高管,4 月 27 日,国家发改委外商投资安全审查办公室正式叫停交易,要求撤销已经完成的收购。
审查关心的是技术从哪来:Manus 的核心团队、研发能力、训练数据和知识产权,是怎么从境内一步步转到境外的。
到 6 月,Meta 开始解除运营、停止和 Manus 共享数据,当初的中国投资人正打算按原价把公司买回来。
这是中国《外商投资安全审查办法》2020 年实施以来,第一次在 AI 领域叫停外资收购。
美国怕最强的模型流出去,中国怕最强的 AI 团队流出去。一个不让模型出境,一个不让公司出境,两个超级大国正在互相关门。
两国在AI领域的竞争趋于白热化。
03 国产大模型正在发力,逐渐跨过可用门槛
DeepSeek 融资完成,harness 团队招兵买马
6 月 DeepSeek 完成了成立以来第一轮外部融资,规模约 500 亿元,投后估值跃升到约 4000 亿元。出钱的阵容很说明问题:创始人梁文锋个人出资约 200 亿,腾讯以 100 亿成为最大外部投资方,宁德时代约 50 亿,网易、京东、IDG、国家大基金等跟投。一家一向对外说「不缺钱、不融资」的公司,这次松了口。
融来的钱主要有两个用途。一是自建算力。为了训练万亿参数级的下一代 V4 模型,DeepSeek 跑到内蒙古乌兰察布建超大规模智算中心,规模从 MW 级一路规划到 GW 级,还专门新设了「IDC 设计规划工程师」,开出月薪 3 万招人去草原「守机房」。二是给员工的期权一个明确的定价,留住核心的研发人员。
6 月 25 日晚,DeepSeek 在官方公众号挂出成立以来规模最大的一次公开招聘。
除了常见的算法和深度学习研究员,这次招人最多的几类是:全栈开发、AI 核心系统研发、运维(含数据中心)、模型数据策略产品经理,外加一个新设的「AI 跨界技术人才」。
再往前数,3 月DS已经放过约 17 个 Agent 岗,工作描述上写明「重度用过 Claude Code、Cursor 优先」;5 月又挂出了过去根本不存在的「Agent Harness 研发工程师」和「Harness 产品经理」。把这些岗位连起来看,DeepSeek 要的已经不止是训练模型的天才,而是能把模型搭成可用产品、能让它稳定跑在自建算力上、能驾驭 agent 干活的全栈队伍。
模型本身已经不再是钱和人的唯一去处。真金白银和最好的工程师,正一起推动「让AI进入现实世界,完成真实的工作」。
GLM-5.2 发布,能力直逼最强闭源模型 Claude
6 月 13 日,智谱发布 GLM-5.2,6 月 16 到 17 日以 MIT 协议开源。这是个 7440 亿参数的模型,开源、可免费商用,价格只有 Opus 的五分之一左右。
跑分上它直接冲进前排:在第三方评测机构 Artificial Analysis 的智能指数(Intelligence Index)上拿到 51 分,是目前分数最高的开源模型,全球总榜排第四,只落后 Claude Fable 5、Claude Opus 和 GPT-5.5 这三个闭源模型。
按实验室算,智谱已经是仅次于 Anthropic 和 OpenAI 的世界第三。单项里它也很硬,Terminal-Bench 拿下 81.0,是第一个突破 80 的开源模型,前端设计的 Design Arena 一度反超 Fable 5。
在实际使用中,GLM展现出来较好的审美,以及较强的Coding能力。
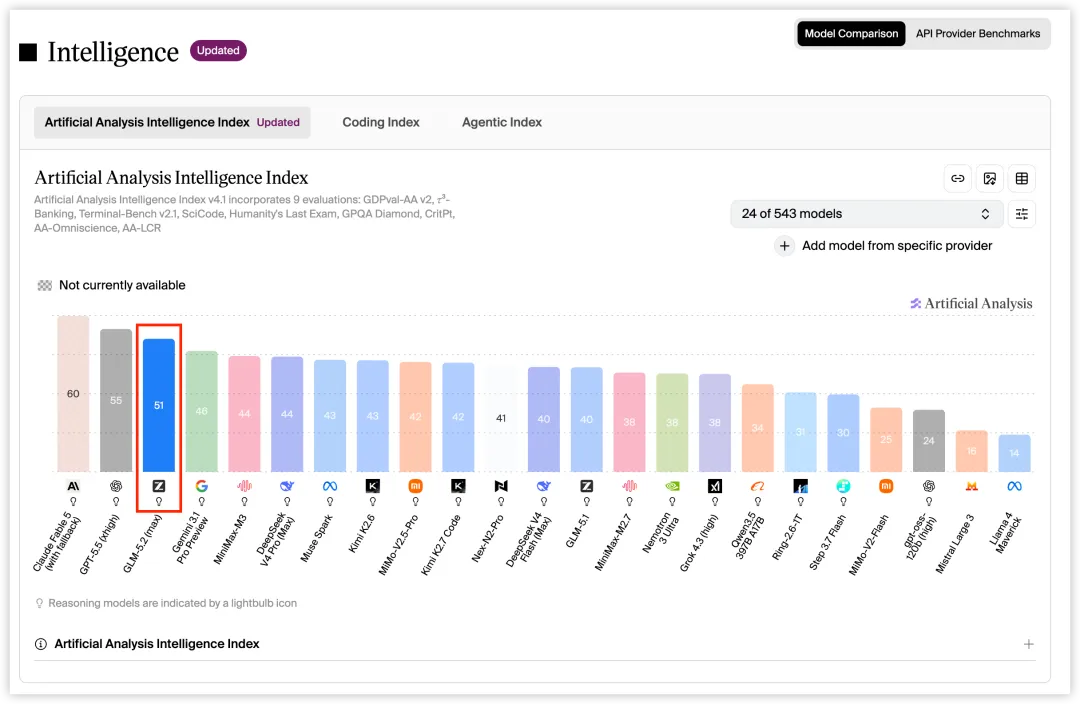
Artificial Analysis 智能指数:GLM-5.2 是分数最高的开源模型,全球总榜第四
这波跑分还引出一场隔空交锋。6 月 18 日,有人在 X 上问马斯克,中国什么时候能拿出对标 Fable 5 的模型,马斯克说「大概要到 2027 年第一季度」。
智谱联合创始人、首席科学家唐杰当场回了一句「用不了那么久」,底气正是刚开源的 GLM-5.2。这条回复让智谱港股当天盘中一度涨了 42%。
然而马斯克回复也令人深思:中国模型在跑分上追上来不难,难的是让模型完成真实的工作,并真正转化成商业收入。
四、几点总结
1. AI 落地会是今年的主题
回头看这半年,最确定的一件事,是行业的重心正从「把模型做得更强」,转移到到「让模型真正干活」。harness 给模型补上记忆、工具和权限,FDE 把它送进一家家公司的真实流程,OpenAI 和 Anthropic 在同一个月先后成立专做落地的公司,把工程师连同模型一起派进客户的业务里。模型还会继续变强,但今年真正的战场,在落地这一侧。MIT 那份报告里 95% 没见到回报的企业,模型早就够强了,差的只是有人把它接进现实。
2. 国产模型值得关注
国产模型这半年真的跨过了「可用」这条线。GLM-5.2 开源、免费商用、价格只有 Opus 的五分之一,跑分冲到全球第四;DeepSeek 第一次对外融资 500 亿,转身就去内蒙古自建算力、成倍扩招。结合上一节看,这一点格外要紧:当最强的闭源模型被锁进白名单、按国籍发放,一个够用、开源、用得起的国产模型,就成了普通人和中小公司实实在在的退路。你不一定用得上全世界最强的那个,但你大概率能用上一个「够干活」的。
3. AI 对人提出了更高的要求
最近很火的loop engineering本来不想写,因为这个概念炒作远远大于实质,但这个概念对人提出了更高的要求。
loop engineering 实质上就是1.设定清晰的目标。2.设定明确的验收的标准。3.利用Claude Code、Codex这样的Agent平台的一些功能,比如loop、goal、定时任务、skill、记忆等 4.让AI自检、优化逐步达成最初设定的目标。
其中没有任何东西是新的。
但与此同时,loop engineering 实际上暴露了于AI协作最重要的要求:
1.能够针对你的工作任务设定清晰的目标。
2.能够知道做成什么样才算是好的。
这两个要求反映出来的是,要想最有效的使用AI,必须成为你所在领域的专家。
只有你足够了解你的专业领域,你才能设定清晰的标准和明确的验收标准,否则只会浪费token。
把这半年发生的事放到一起看,结论其实很简单。
在整个 AI 链条上,训练基础模型的门槛高的可怕,而且正在成为国家竞争的主战场,绝大多数人无法染指。
但模型以外的每一层都是敞开的:怎么驾驭 AI,怎么把它搭进自己的工作流,怎么让它真正落到生产里干活。
这些才是大多数人都能抓住的机会。
🌟感谢你看我的文章。
👏欢迎点赞关注。
