 夜雨聆风
夜雨聆风MeMo: Memory as a Model
论文: MeMo: Memory as a Model (arXiv:2605.15156)
作者: Ryan Wei Heng Quek, Sanghyuk Lee, Alfred Wei Lun Leong, Arun Verma, Alok Prakash, Nancy F. Chen, Bryan Kian Hsiang Low, Daniela Rus, Armando Solar-Lezama
机构: 新加坡国立大学 (NUS) · MIT CSAIL · A*STAR · Liquid AI · 东京大学 · AI Singapore · SMART
代码: https://github.com/arunv3rma/MeMo (MIT 协议) 发布: 2026年5月
作者导语
当前AI技术里面最重要的两个就是记忆和自进化,虽然大模型现在的能力已经能在很多地方使用,特别是在代码方面。但大模型的记忆短板限制了其在更广泛的地方使用和获得更好的效果。
为了给记忆短板打补丁,现在的手段都有百万上下文这种扩大context窗口大小的手段,还有RAG等技术手段,这些手段始终作用有限,局限较多。虽然今年(26年1月)google的nested learning的论文非常惊艳,但苦于工程实现比较复杂而难于实践推广,也没有在大参数规模上实践验证,也只停留于理论。
今天我们要介绍的MeMo就是一个比较巧妙的思路来解决这个问题的一种方法,虽然也有一定的局限性,比如溯源归因变得困难。
下面就分三部分来介绍一下(后面两个部分太长建议没时间不要看):
快速导览——让你知道是什么,创新点有什么,影响是什么
论文原文全文翻译——真实前面的了解原始论文怎么讲的
官方github仓库实现介绍——怎么工程实现的
一、导览:MeMo 是什么,为什么重要
一句话概括
MeMo 把”新知识”装进一个独立的小型”记忆模型”里,让任何冻结的大语言模型(哪怕是不能改权重的商用 API 模型)都能通过结构化多轮对话向它”查资料”,从而免去重新训练的昂贵代价,也避开 RAG 检索的噪声与长度瓶颈。
它解决了什么问题
大模型预训练后参数就”冻住”了,而现实世界知识每天都在变。现有三种补知识的方法各有硬伤:
RAG受上下文窗口限制且对噪声敏感;
微调计算极贵且会灾难性遗忘;
潜在记忆与产生它的模型死绑,换一个 LLM 就用不了。
MeMo 的出发点是——把三种方法的好处都拿到,同时避开它们的短板。
核心思路:记忆即模型
MeMo 分两步:
训练时用一个 Generator 模型把语料”消化”成反思问答对,再据此微调出一个紧凑的 Memory 模型(1.5B–14B);
推理时主模型(Executive)通过结构化多轮协议向 Memory 模型”查资料”,自身权重一个参数都不动。两个模型只通过标准 API 通信,Executive 完全是黑盒——这就是即插即用能力的根基。
四个技术创新点
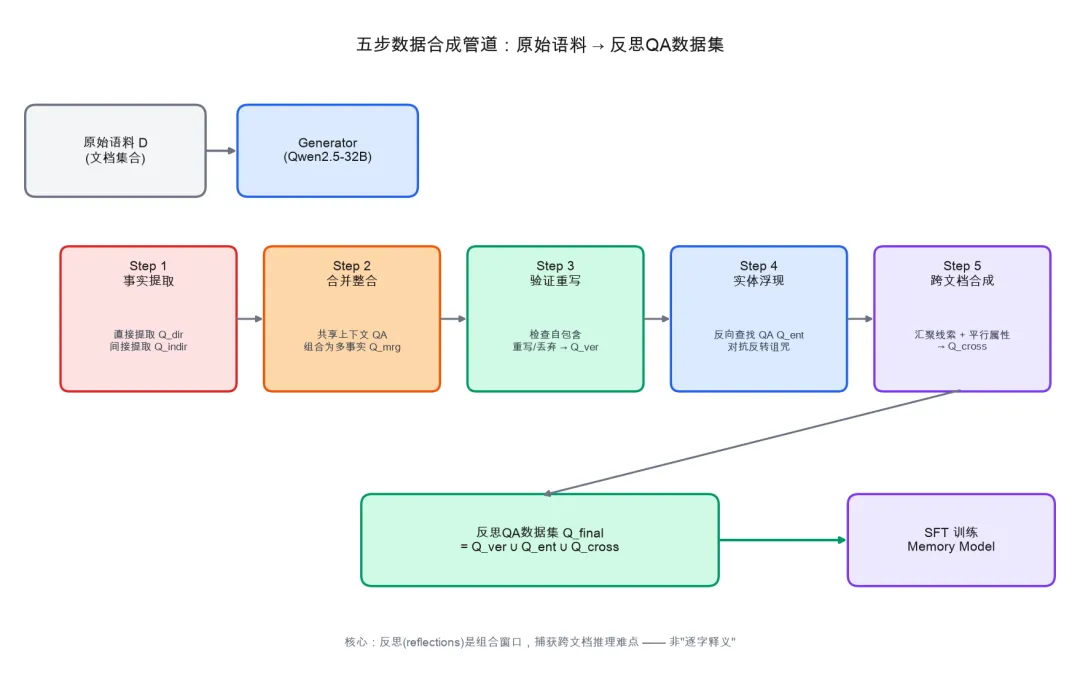
1. 五步数据合成:把文档变成”反思”
这是 MeMo 最核心的贡献。它不直接拿原始文档训练,而是用 Generator 模型把语料”消化”成五类反思问答对:
事实提取(直接 + 间接):既抓明说的,也抓需要推导的
合并整合:把共享上下文的事实组合成多事实问题,形成”组合表示”
验证重写:确保每个问答对都能独立理解(无代词、无文档引用)
实体浮现:为每个实体生成”反向查找”问答对——用属性描述问”这是谁”,直接对抗”反转诅咒”
跨文档合成:识别多文档间的汇聚线索和平行属性,生成真正需要跨文档推理才能回答的问题
关键在于:这种”反思”设计不需要预知未来会问什么问题,却能自然地成为任意查询访问底层语料的精确接口。
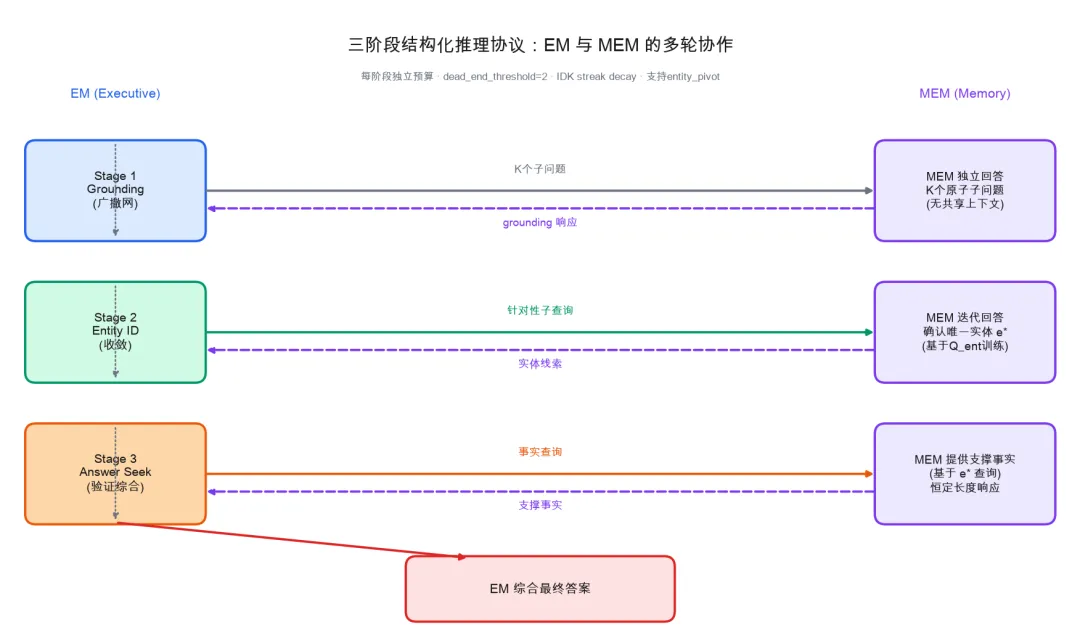
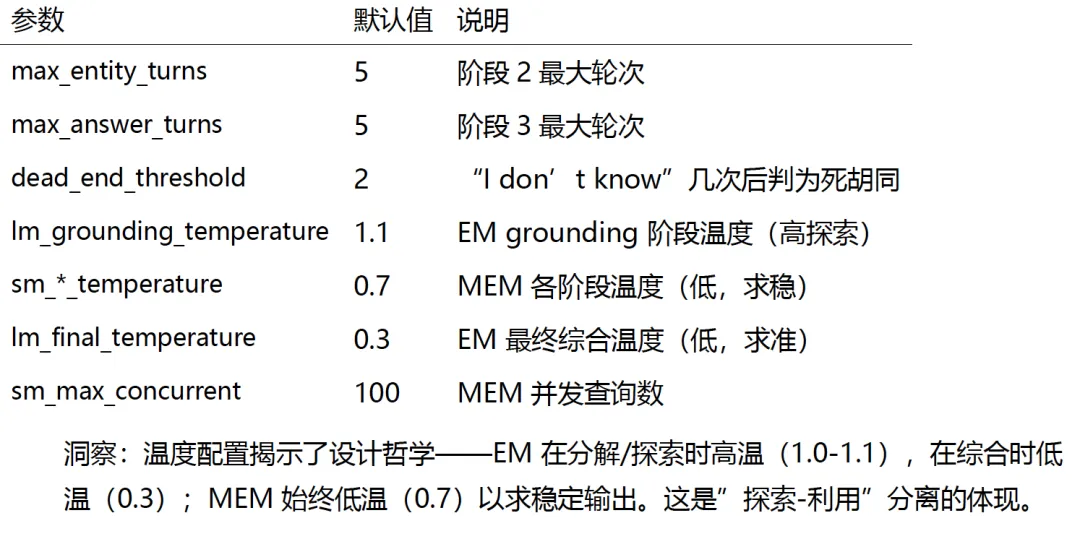
2. 结构化三阶段推理协议
推理时模仿分析师的工作方式分三阶段:
Grounding(把复杂问题拆成原子子问题,Memory 独立回答)
→ Entity ID(基于线索迭代确认具体实体)
→ Answer Seek(围绕实体查支撑事实,综合答案)。
每个阶段有独立预算和温度配置,还有”死胡同检测”和”IDK streak decay”——Memory 连续答”不知道”的问题就不再追问,避免在无效路径上浪费预算。
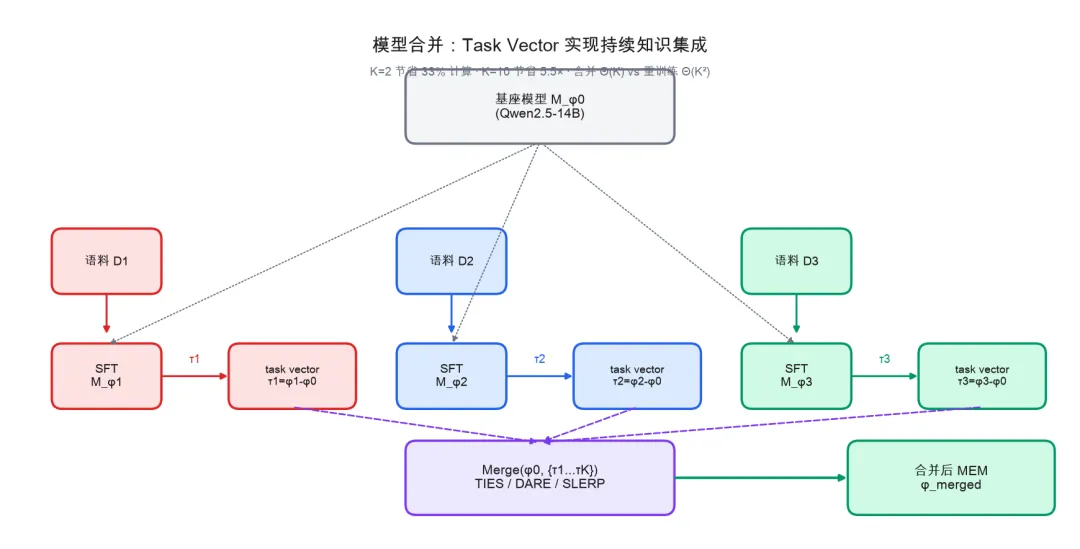
3. Task Vector 模型合并:持续知识集成
新语料到达时无需全量重训练。MeMo 为每个语料单独训练 Memory 模型,再用 Task Vector + TIES 合并融合成一个通用模型。全量重训练按 缩放,模型合并按 缩放, 时节省 5.5 倍计算。
4. 黑盒即插即用
Executive 全程只通过标准 API 与 Memory 通信,不需要权重、梯度或 logits 访问权限。直接红利:用较弱的开源 Generator 训练 Memory,推理时搭配最强的商用 LLM(如 Gemini-3-Flash),性能自动提升,Memory 零重训练。
潜在影响
正向影响:
降低知识密集型 AI 部署门槛:法律、医学、科研等垂直领域,不再需要昂贵的全量重训练,一个小型 Memory 模型 + 任意商用 LLM 即可内化领域知识。
解耦知识与推理:知识库与推理引擎相互独立,模型升级换代时 Memory 模型可复用,避免”换模型就丢知识”的困境。
可扩展的持续学习路径:模型合并让增量纳入成本从 降到 ,为长期演进铺平道路。
需要警惕的风险:
归因困难:减少对显式检索的依赖后,模型回答背后的知识来源更难追溯,对需要可解释性的场景(法律、医疗)是挑战。
错误信息内化:同样能力可能被用来大规模内化错误信息或未经授权的专有数据,降低知识整合门槛是双刃剑。
二、论文全译
摘要
大型语言模型(LLM)在各类任务上取得了优异表现,但在预训练完成后到下次更新之前会长期处于冻结状态。许多实际应用需要及时、特定领域的知识,这促使人们寻求高效的机制来纳入新知识。本文提出 MeMo(Memory as a Model,记忆即模型),一种模块化框架,将新知识编码进一个专用的 Memory 模型,同时保持 LLM 参数不变。与现有方法相比,MeMo 具有以下优势:(a)能捕获复杂的跨文档关系;(b)对检索噪声鲁棒;(c)避免 LLM 的灾难性遗忘;(d)无需访问 LLM 的权重或输出 logits,可与开源和闭源商用 LLM 即插即用集成;(e)推理时的检索成本与语料库大小无关。在 BrowseComp-Plus、NarrativeQA 和 MuSiQue 三个基准上的实验表明,MeMo 在多种设置下取得了优于现有方法的强劲表现。
1 引言
大型语言模型(LLM)在各类任务上展现出卓越能力。尽管取得了成功,这些模型在预训练后实际上被冻结了相当长的时间,直到后续更新,导致其预训练知识随着世界演进日益过时。对于需要最新知识或领域特定知识的应用,这种对静态知识的依赖构成了根本性的架构限制。重新训练是自然之选,但在现代规模下代价高昂得令人却步,这促使人们寻求一种无需全量重训练即可将新外部知识整合进 LLM 的高效机制。
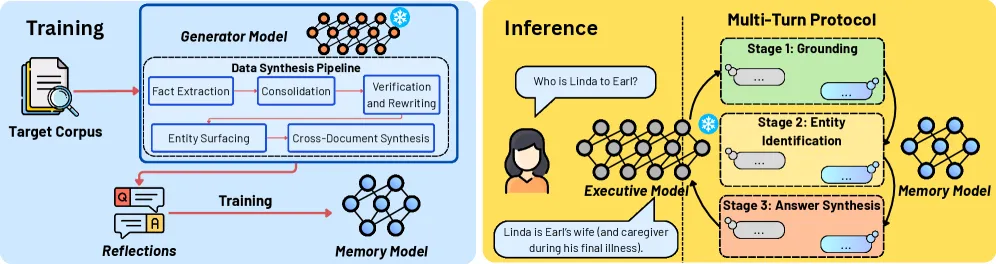
图 1:MeMo 训练与推理管线总览。 在 Memory 模型训练阶段(左),一个冻结的 Generator 模型通过事实提取、合并整合、验证、实体浮现和跨文档合成五个步骤,将目标语料库转化为反思QA数据集,再据此训练专用 Memory 模型。在推理阶段(右),冻结的 Executive 模型通过结构化多轮协议查询 Memory 模型来回答复杂用户查询:将输入分解为更简单、针对性的子查询,从 Memory 模型检索中间响应,并基于推理产出最终答案。
将新知识整合进 LLM 的现有方法可分为三类。① 非参数化方法在推理时通过词法、稠密或基于图的检索器从外部存储检索相关信息,再通过上下文学习纳入。但这些方法受限于有限的上下文窗口,且当相关信息分散在多个文档中时难以综合跨文档关系。② 参数化方法通过持续预训练或微调将知识直接内化到模型参数中。虽然有效,但计算昂贵、易发生灾难性遗忘,且倾向于记忆训练分布而非获取可迁移知识。③ 潜在记忆方法将知识压缩为 soft token 或其他模型特定表示,但存在表示耦合问题:记忆与产生该表示的特定模型紧密绑定,限制了跨 LLM 的可迁移性。
我们提出 MeMo(Memory as a Model),一种模块化框架:在专用 Memory 模型上训练新知识,Executive 模型在推理时通过针对性子查询从 Memory 模型检索相关信息,再对检索到的信息进行推理以响应用户查询。MeMo 结合了上述三种范式的互补优势,同时缓解了它们各自的局限。因此,MeMo 具有以下优势:(a)捕获复杂跨文档关系;(b)对检索噪声鲁棒;(c)保持 Executive 模型参数不变以避免灾难性遗忘;(d)无需访问 Executive 模型权重或输出 logits,实现与开源和闭源 LLM 的即插即用集成;(e)由于 Memory 模型大小固定,推理时检索成本与语料库大小无关。然而,设计 MeMo 使其在训练时全面捕获跨文档关系、在推理时准确回答任意查询,带来了两个关键挑战:
① 训练 Memory 模型。 核心挑战在于确保 Memory 模型能准确回答推理时各种未见查询,包括需要跨文档推理和长上下文理解的查询。自然的方法是直接在原始语料上用标准数据增强技术训练(如改写、额外采样生成的QA对、定向填空)。但这些方法未能将相关事实整合为组合表示,无法稳健泛化到未见查询。为此,我们设计了一个由 Generator 模型驱动的五步数据合成管线(第4.1节),将语料蒸馏为反思(reflections)的问答数据集——这是一种组合表示,能在多种查询变体下暴露底层语料知识。我们通过监督微调在合成的反思QA数据集上训练 Memory 模型(第4.2节)。
② 查询 Memory 模型。 推理时,复杂或组合查询常需要多步推理和跨多文档信息聚合。朴素地通过单轮或非结构化多轮交互查询 Memory 模型,无法可靠检索回答此类查询所需的知识。为此,我们设计了一个三阶段推理管线,Executive 模型通过结构化多轮协议查询并检索 Memory 模型的信息,将复杂用户查询分解为与共享反思接口对齐的针对性子查询(第4.4节)。与基于检索的方法不同,该方法的检索成本与语料库大小无关,且对检索噪声鲁棒。关键在于,由于 MeMo 将 Executive 模型视为黑盒,不访问其权重、梯度或输出 logits,因此支持与任意 LLM(包括开源和闭源商用模型)的即插即用集成。
我们的方法受单一设计原则指导:反思——语料衍生的结构,不需要预知未来查询,却能自然地作为任意查询访问底层语料的精确接口,而无需直接观察语料。训练时 Memory 模型内化这些反思;推理时 Executive 模型通过针对性子查询检索相关知识。本文的主要贡献如下:
新型数据合成管线。 提出五步数据合成管线,使用 Generator 模型(可与 Executive 模型相同或更小的 LLM)将目标语料蒸馏为反思,使专用 Memory 模型能以组合形式内化知识,捕获更复杂的跨文档关系并稳健泛化到推理时各种未见查询变体(第4.1、4.2节)。
结构化多轮协议。 引入结构化多轮协议,系统地将复杂查询分解为与共享反思接口对齐的针对性子查询。该协议支持与任意 LLM(包括闭源商用 LLM)即插即用集成,且检索成本与语料库大小无关(第4.4节)。
实证验证。 在 BrowseComp-Plus、NarrativeQA 和 MuSiQue 上评估 MeMo,展示了对参数化和非参数化基线的强劲表现,并进一步实证验证了 MeMo 对检索噪声的鲁棒性(第5节)。
2 相关工作
非参数化方法。 非参数化替代方案完全避免参数更新,转而在推理时提供新知识。上下文学习(ICL)将相关知识直接插入提示,避免灾难性遗忘。但 ICL 随上下文长度增加扩展性差:自回归生成的计算成本随知识库增长带来大量 token 开销和推理延迟,即便是长上下文模型也会随上下文长度增加出现显著性能下降。检索增强生成(RAG)通过在推理时选择性地检索相关知识块来解决这一可扩展性瓶颈。但 RAG 系统对检索噪声高度敏感,无关或误导性段落会显著降低生成质量。此外,RAG 系统常难以对复杂的跨文档依赖进行推理,因为缺乏稳健的机制来综合分布在多个块或大型语料中的信息。
参数化方法。 现有训练后方法(如持续预训练或监督微调)试图通过在训练后阶段将新知识纳入 LLM 来解决这一局限。虽然概念上直接,但这些参数化方法常受灾难性遗忘之苦——对新知识的适应会退化先前习得的知识、能力和安全对齐。此外,现代 LLM 的规模使得频繁微调计算昂贵,且对闭源模型通常不可行,实质性地限制了参数化方法在现实大规模应用中的实用性。
潜在记忆方法。 另一种存储知识的方式是通过压缩潜在表示,介于非参数检索和完全参数化方法之间。上下文压缩技术如 AutoCompressor、Gist tokens 和 ICAE 将知识编码为紧凑 soft token,在推理时前置以减少 ICL 的 token 开销。但这些表示与编码器紧密耦合,不能被其他模型族消费。类似地,循环状态模型和最近邻记忆方法(如 Memorizing Transformers、kNN-LM)依赖模型特定的表示或架构,无法与预训练 LLM 事后配合使用。Memory Decoder 虽是即插即用的预训练记忆模块,但仅限于共享通用分词器的架构。这些方法的核心局限是表示耦合:潜在记忆与产生它的模型不可分离。相比之下,MeMo 允许与任意 LLM(包括闭源模型)即插即用集成。
表 1:不同记忆范式在理想属性上的比较,显示 MeMo 通过其模块化记忆构建和记忆增强推理满足了所有属性。
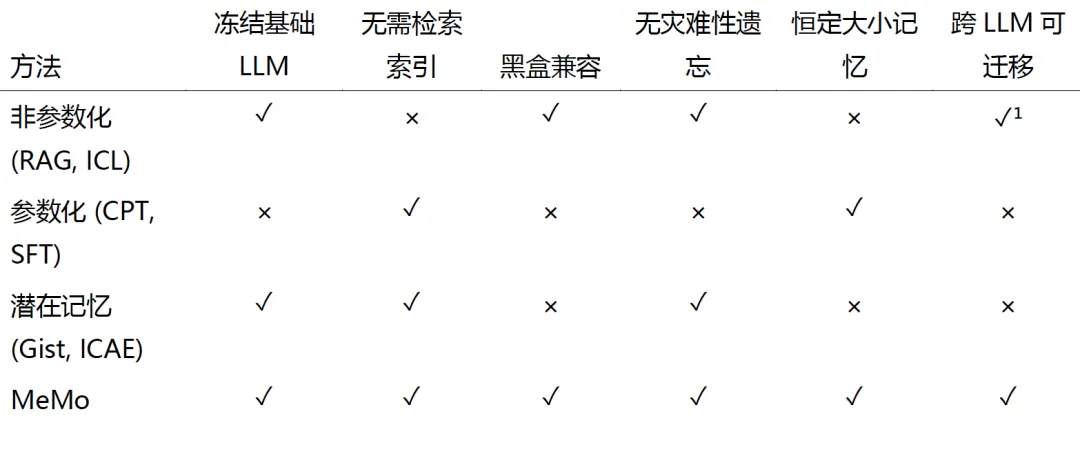
¹ 我们假设 RAG 使用与 Executive 模型解耦的固定、任务无关的嵌入模型,使检索索引可跨模型复用。对 ICL,假设提示是基于原始文本的,不含模型特定格式。
3 预备知识


4 MeMo:记忆即模型
MeMo 通过两个组件解决知识整合问题(定义1):一个冻结的模型 (Executive 模型),负责推理并响应用户查询;一个 Memory 模型 ,经过训练以将目标语料 的知识编码进其参数。我们的管线分两个阶段运行:(i)从 构建 Memory 模型的训练阶段;(ii)Executive 模型查询并检索 Memory 模型信息以回答知识密集型问题的推理阶段(见第4.1、4.2和4.4节)。
4.1 数据合成管线
给定文档语料 ,我们在数据生成过程中的目标是构建一个反思QA数据集 ,既捕获单文档事实也捕获跨文档关系。该过程由 Generator 模型 驱动,分五步进行,如算法1所示并在图1中示意:
(1)从原始文档提取事实;(2)合并冗余或重叠信息;(3)验证并重写以确保正确性和清晰度;(4)实体浮现以显式表示关键实体;(5)跨文档合成以整合语料范围内的证据。重要的是,任何步骤都不在生成的QA对中嵌入文档标识符或水印,防止 Memory 模型在评估时利用捷径信号。
算法 1:从目标语料生成反思QA数据集的管线
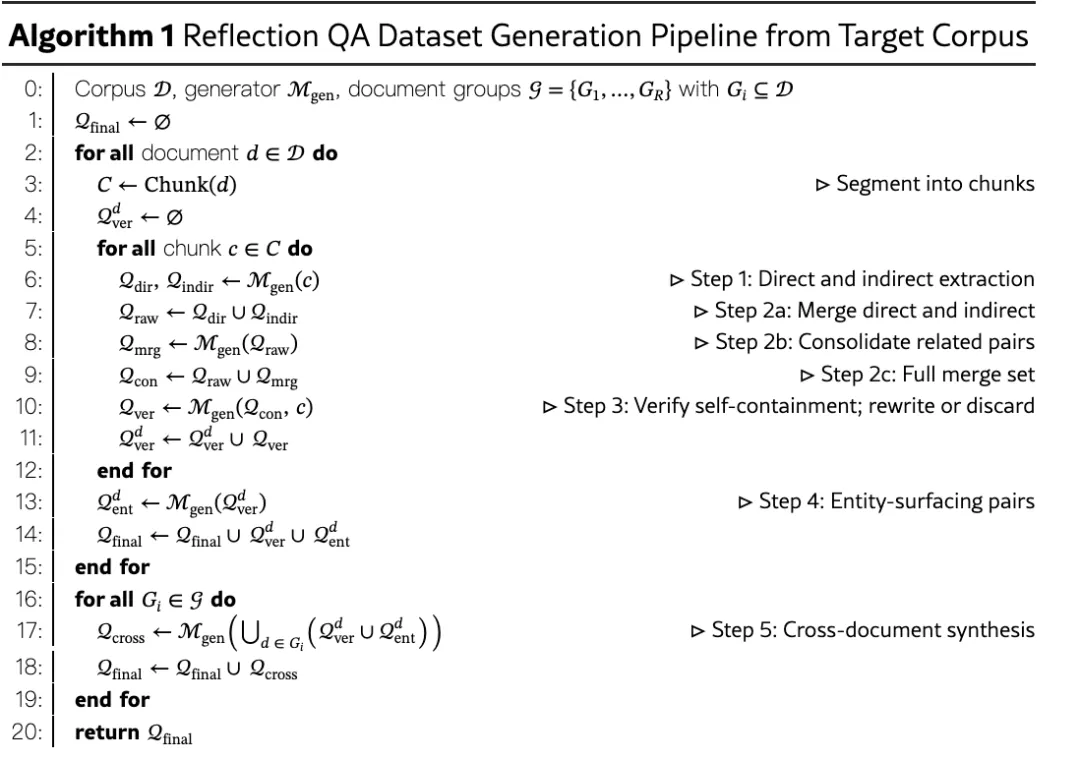
步骤1:事实提取。 每个文档 被分段为块 ,每个块对应整个文档或长文档的连续片段。对每个块, 执行两个并行提取过程:直接提取,捕获显式陈述的事实(产出 );间接提取,针对表面文本之外的推断或合成信息(产出 )。这种双重提取确保 Memory 模型的训练信号既包含事实回忆也包含推理能力。
步骤2:合并整合。 Generator 模型 整合 ,识别共享底层上下文(如实体、时间段或关系类型)的QA对,将它们组合成涵盖多个事实的QA对,记为 。此合并过程产出的训练实例要求在同一上下文块内整合多个事实,超越了单事实问答对。合成的QA对随后与原始集合并形成整合数据集 。
步骤3:验证与重写。 中的每个QA对由 评估自包含性,即在没有源块的情况下能否被完全理解并正确回答。常见失败模式包括未解决的代词(如”他们提出了什么?“)和隐含引用(如”如上表所示……“)。非自包含的QA对由 以源块 为上下文重写;重写后仍含糊的QA对被丢弃。此检查-重写过程产生验证集 ——一组无需访问源块即可用作训练示例的QA对。
步骤4:实体浮现。 对 中的每个命名实体, 生成一组实体浮现QA对,其中问题编码实体的属性和关系(包括与其他命名实体的连接),答案揭示其身份。每个实体的事实跨越块内所有QA对聚合,使能整合和组合来自多个源对的信息。问题以不同复杂度生成,从单事实到多事实查询。这些对(记为 )旨在通过训练 Memory 模型从间接或部分指定描述推断实体来缓解反转诅咒。此能力支持推理时的实体识别轮次(第4.4节)。
步骤5:跨文档合成。 最后一步在预定义文档组 上操作,其中每组 内的块主题相关。此类组自然产生,例如大文档被分段为块(形成单组)或来自人工标注。对每组 , 接收所有成员文档的验证对 和实体浮现对 ,并识别两种跨文档连接:
汇聚线索(converging clues):多个文档提供同一实体的互补事实,共同使其可被识别。
平行属性(parallel properties):不同文档中的不同实体共享共同属性或角色,使能比较和类比推理。
两种类型均产出支撑大小 的QA对(第3节),直接针对跨文档合成目标。最终数据集为 ,共同捕获自包含、实体中心和跨文档反思以训练 Memory 模型。管线设计的消融见附录E。
4.2 训练 Memory 模型

4.3 通过模型合并实现持续知识集成
任何知识整合系统的一个实际需求是能够增量纳入新语料,而无需在所有先前摄入的源上重训练或重建。对参数化模型,整合新知识通常需要在所有已观察语料的并集上重训练,该成本随源数量增长而变得极其高昂。相比之下,非参数化系统(如知识图谱和向量数据库)支持高效增量更新。我们探索模型合并作为弥合参数化模型这一差距的方法。模型合并旨在通过将 个各自在独立语料上训练的 Memory 模型组合为单一模型,来保留多个来源的知识,而无需在其并集上联合训练。

4.4 推理时集成
推理时,Executive 模型通过结构化多轮协议查询并检索 Memory 模型的信息,Executive 模型将 Memory 模型视为外部知识预言机。该管线有三个顺序阶段,每个阶段旨在逐步提高产生正确最终答案的可能性,如图1(右)所示。每个阶段使用不同的提示、采样温度和独立预算来控制 Executive 模型与 Memory 模型之间的交互次数。

5 实验
数据集。 我们在三个知识密集型基准上评估 MeMo。BrowseComp-Plus 是需要多跳、多文档检索和推理的深度研究基准;我们用 LangDetect 过滤非英语实例,采样300个问题,将每个问题的证据文档与等量负文档配对,共3,541个文档。NarrativeQA 测试对书籍和电影剧本等长文档的话语理解;我们使用10⁴个文档上的293个问题。MuSiQue 需要跨多个维基百科段落组合2-4步推理;我们使用1,000个问题并按与BrowseComp-Plus相同的程序构建目标语料,共5,296个文档。更多细节见附录D。
³ BrowseComp-Plus 和 MuSiQue 提供金标(正确)、证据(支撑)和负(干扰)文档的标注。金标文档是证据文档的子集。
⁴ 我们遵循 HippoRAG2,在 NarrativeQA 验证集的10个此类文档上评估(294个问题);为一致性移除一个重复。
基线。 我们将 MeMo 与四个基线对比:BM25(词法检索)、NV-Embed-V2(稠密检索)、HippoRAG2(基于图的RAG,state-of-the-art)和 Cartridges(推理时加载到 Executive 模型上的训练KV缓存;最接近 MeMo 的现有参数化基线)。更新的方法存在,但通常需要对 Executive 模型的白盒访问,因此不直接可比。我们还纳入 Perfect Retrieval 作为经验上界,其中 Executive 模型在上下文中仅接收证据文档。检索基线使用 top-k=9 并采用自适应回退:逐步减小 k 直到检索到的上下文适合 Executive 模型的上下文窗口。
实现与评估。
数据生成。 我们使用 Qwen2.5-32B-Instruct 作为 Generator 模型,通过 vLLM 服务,配合 YaRN RoPE 缩放以支持131K token的上下文窗口进行长上下文生成。
训练。 我们训练 Memory 模型,从 Qwen2.5-14B-Instruct 初始化,训练3个epoch,使用融合 AdamW 和 DeepSpeed 2,学习率 ;完整超参数见附录F。
评估。 我们用 Qwen2.5-32B-Instruct 或 Gemini-3-Flash 实例化 Executive 模型,以评估同一训练好的 Memory 模型跨不同推理能力模型的表现;两个模型对评估数据集的先验知识极少(附录I)。Executive 模型通过第4.4节描述的多轮协议查询 Memory 模型。我们报告由 Gemini-2.5-Flash-Lite 通过 DeepEval 判定的二元准确率,Qwen2.5-32B-Instruct 为三次运行的均值±标准差,Gemini-3.0-Flash 为单次运行。
持续整合。 对于模型合并实验(第5.5节),我们将 NarrativeQA 划分为两个不相交子集(,每个约640k QA对),在每个上分别SFT一个 Qwen2.5-14B-Instruct Memory 模型,并在三个密度下扫描六种合并方法(共14种配置)。
5.1 实验结果
MeMo 在各基准上取得强劲表现。 如表2所示,MeMo 在两个 Executive 模型上均持续优于 NarrativeQA 和 MuSiQue 的所有基线。在 NarrativeQA(最具挑战性的基准,附录I)上,MeMo 用 Qwen2.5-32B-Instruct 达到26.85%,用 Gemini-3-Flash 达到53.58%,大幅超越所有基线。这值得注意:NarrativeQA 需要对具有复杂连接的长段落推理,基于检索的方法受限于上下文窗口,难以跨长文档综合信息;而 MeMo 通过训练时的反思捕获这些连接,并在推理时通过多轮协议检索。同样的趋势在 MuSiQue 上也成立,MeMo 分别达到48.30%和58.70%,优于那些难以对独立检索的段落进行多跳推理的基线。在 BrowseComp-Plus 上,MeMo 用 Gemini-3-Flash 领先(66.67%),用 Qwen2.5-32B-Instruct 保持竞争力(54.22%,略低于 HippoRAG2 的56.11%)。这一差距反映了 BrowseComp-Plus 的性质:其答案不在 Executive 模型的参数化知识中(附录I),使直接访问证据文档特别有价值,有利于将原始文档传给 Executive 模型的检索方法。
表 2:在两个 Executive 模型下 BrowseComp-Plus、NarrativeQA 和 MuSiQue 上的准确率 (%):Qwen2.5-32B-Instruct (Qwen2.5-32B-I) 和 Gemini-3-Flash (Gemini-3-F)。加粗值表示每列最佳结果(不含 Perfect Retrieval)。MeMo 使用 Qwen2.5-14B-Instruct 作为 Memory 模型,结果在最佳训练epoch报告。⋆Perfect Retrieval 代表经验上界。
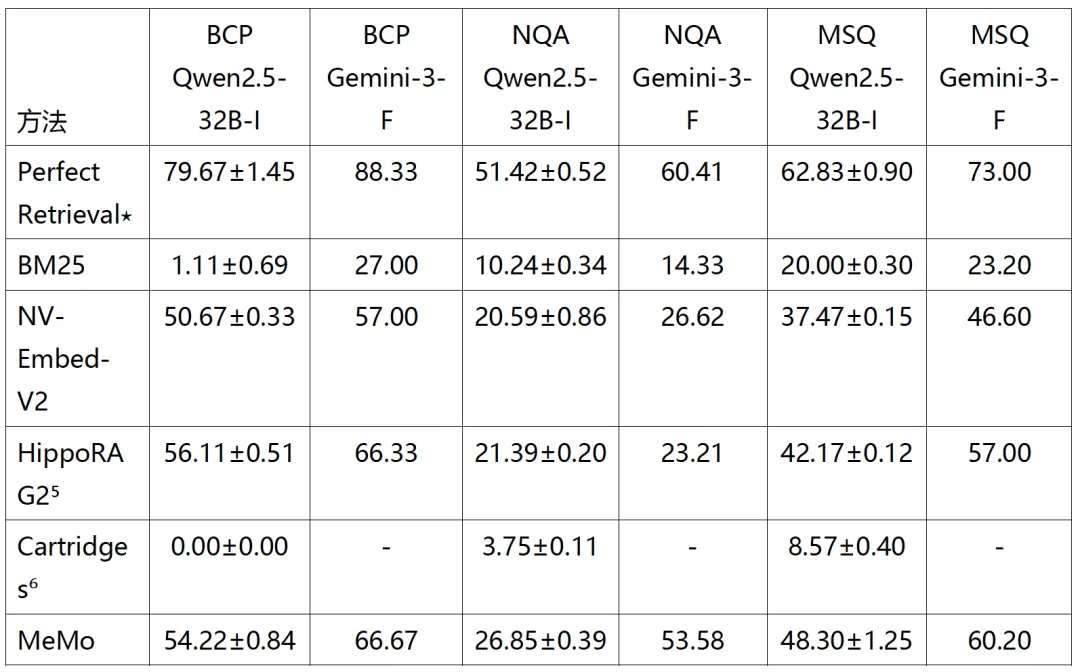
⁵ 这些结果与原始论文不同,原论文使用 Llama3.3-70B-Instruct 而非 Qwen2.5-32B-Instruct。
⁶ Cartridges 也需要对 Executive 模型的白盒访问,因此其 Gemini-3-Flash 结果省略。
MeMo 支持即插即用集成。 在三个基准上,MeMo 搭配更强的 Executive 模型(Gemini-3-Flash)时始终取得更高表现:从 Qwen2.5-32B-Instruct 切换到 Gemini-3-Flash 在 BrowseComp-Plus、NarrativeQA 和 MuSiQue 上分别提升12.45%、26.73%、11.90%。这表明 MeMo 可用较弱的 Generator 模型训练一次,在推理时与任意 LLM 无缝搭配,包括 Gemini-3-Flash 等商用模型。这种即插即用能力使 MeMo 能直接利用最先进模型而无需额外训练或开销。
5.2 数据集噪声量消融
表 3:以 Qwen2.5-32B-Instruct 为 Executive 模型,在 BrowseComp-Plus 和 MuSiQue 上的准确率 (%)。MeMo 结果基于 Qwen2.5-14B-Instruct,在最佳训练epoch报告。 表示语料库中真值证据文档数量;列头表示添加的额外负(干扰)文档数量,为 的倍数。 表示相对于 的准确率差值 (%)。
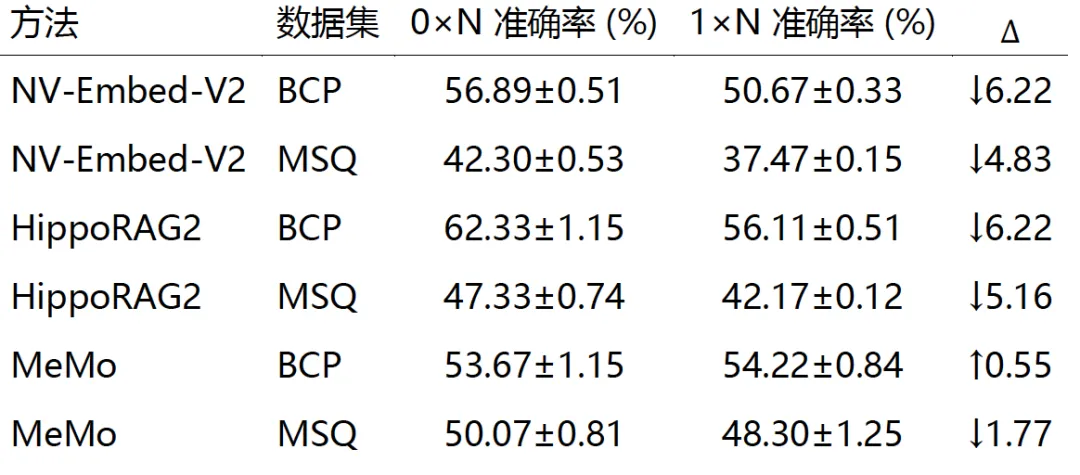
我们研究 MeMo 在递增检索噪声水平下对两个强检索基线(NV-Embed-V2 和 HippoRAG2)的鲁棒性,通过改变添加到目标语料的负(干扰)文档数量(为每个数据集真值证据文档总数的倍数)来控制(BrowseComp-Plus ,MuSiQue )。本文使用的数据集(附录D详述)对应 比率;我们还额外在 (无干扰)比率下评估,作为理想化的无噪声参考以隔离干扰的影响。
表3结果表明基于检索的方法对噪声表现出明显的敏感性。NV-Embed-V2 和 HippoRAG2 在从 到 时,BrowseComp-Plus 上下降高达6.22%,MuSiQue 上下降高达5.16%,证实这些系统在现实语料条件下难以过滤无关文档。相比之下,MeMo 在两个基准上保持稳定表现,BrowseComp-Plus 上微升0.55%,MuSiQue 上仅下降1.77%,均在一个标准差之内,表明 MeMo 对递增检索噪声鲁棒。我们将此鲁棒性归因于 MeMo 的设计:尽管在含负文档的语料上训练,Memory 模型向 Executive 模型的子查询提供的信息比直接文档检索更精准。基于检索方法性能退化的更多分析见附录L。
5.3 Memory 模型大小消融
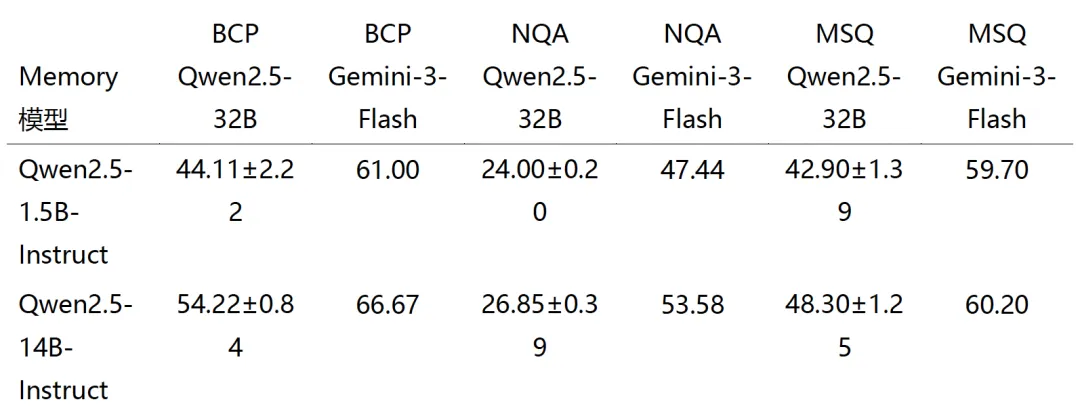
我们通过比较 Qwen2.5 系列中1.5B和14B参数的模型来研究 Memory 模型大小对下游任务表现的影响。实现细节见附录M。
表4结果显示一致的正向缩放趋势:更大的 Memory 模型在所有基准和 Executive 模型上表现更佳。但结果也显示,更强的 Executive 模型推理能力在各任务间非均匀地调节这一差距:Memory 模型大小间的性能差在 NarrativeQA 上扩大,但在 BrowseComp-Plus 和 MuSiQue 上缩小。这表明 Executive 模型推理能力与 Memory 模型大小间的交互是任务依赖的。
表 4:Qwen2.5 系列内 Memory 模型大小消融。加粗结果表示该列最佳。
5.4 Memory 模型族消融
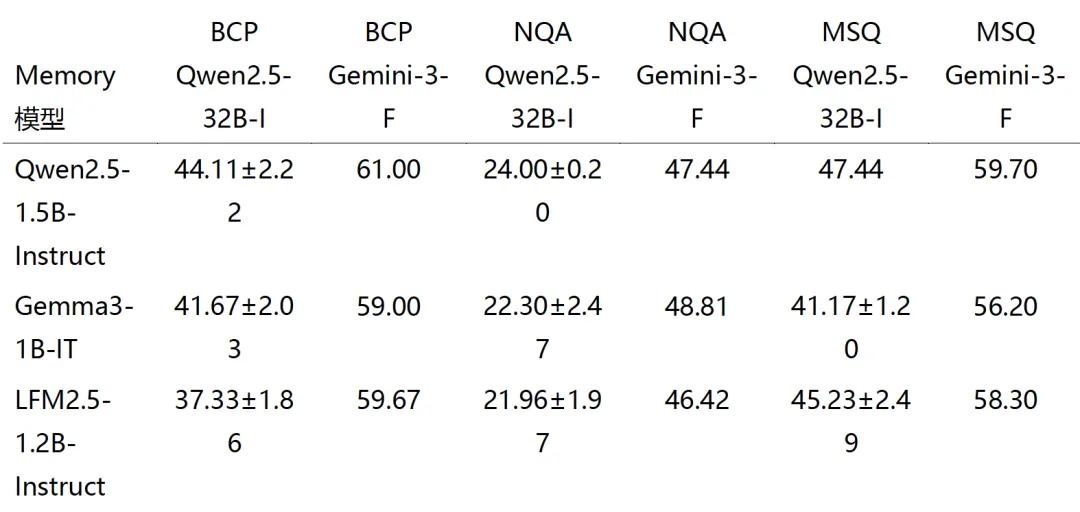
我们通过比较三个参数规模相似(~1–2B)但架构和预训练谱系不同的模型来研究 Memory 模型族选择是否影响表现:Qwen2.5-1.5B-Instruct、Gemma3-1B-IT 和 LFM2.5-1.2B-Instruct。实现细节见附录N。
表5结果表明 MeMo 表现对 Memory 模型架构的选择大体鲁棒,表明该框架在相似参数规模下对 Memory 模型的特定预训练谱系不敏感,且我们的训练过程诱导的参数化知识压缩可跨多样模型族泛化。
表 5:相似参数规模(~1–2B)下跨 Memory 模型的消融。加粗结果表示该列最佳。
5.5 通过模型合并实现持续集成
我们在 NarrativeQA 上测试第4.3节描述的流式更新场景,比较模型合并与在两个子集并集上全量重训练 Memory 模型(当第二个子集到达时)。在14种扫描配置中(见表12,附录H),我们在正文中报告 TIES(),表现最佳。设 和 为每个子集单独的SFT成本(成本随QA对数量近似线性缩放,故并集成本为 ),两次到达的累积计算对合并为 ,对全量重训练为 。
表 6:NarrativeQA 上模型合并 vs 全量重训练。Memory 模型 = Qwen2.5-14B-Instruct。Merge-TIES () 是14种扫描配置中最佳(表12,附录H)。累积计算以8×H100 GPU-小时报告,针对各约640k反思QA对的 子集。 表示相对于全量重训练的准确率差值 (%)。
合并使 时计算减少33%,且随规模收益扩大。 如表6所示,全量重训练基线累积计算约72 GPU-小时,而合并仅累积约48 GPU-小时——减少33%(图2)。差距随 扩大:在相同每语料成本下,合并按 缩放,而全量重训练按 缩放, 时节省5.5倍(240 vs 1,320 GPU-小时)。
图2:随语料数量 K 的计算节省。 全量重训练按 缩放,合并按 缩放,K=10 时节省 5.5×。
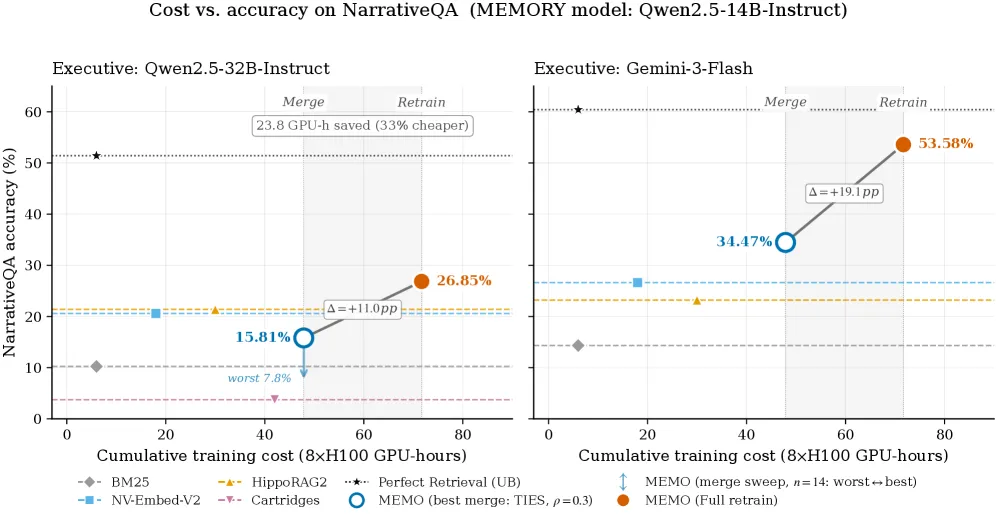
合并以可衡度的准确率差距换取计算节省,但仍优于检索。 Merge-TIES () 在 Qwen2.5-32B-Instruct 下落后全量重训练 Memory 模型11.0%,Gemini-3-Flash 下落后19.1%(表6);在完整的14种配置扫描中,准确率范围从7.85%(SLERP,最差)到15.81%(TIES,最佳),如图2所示。尽管存在此差距,合并的 Memory 模型在 NarrativeQA 上仍优于所有检索基线(BM25、NV-Embed-V2、HippoRAG2、Cartridges;见表2),表明即便激进地更便宜的合并过程仍保留了 MeMo 相对基于检索方法的大部分定性优势。TIES 和 DARE-Linear 在 下主导扫描,表明激进稀疏化配合符号冲突解决是此场景下最可靠的合并配方。
6 结论
我们提出了 MeMo,一种通过在合成反思QA数据集上训练的 Memory 模型将更新或领域特定知识整合进 LLM 的模块化框架。MeMo 解决了现有方法的关键局限:它绕过了基于检索方法的上下文约束和有限的跨文档推理,避免了昂贵且脆弱的参数化更新(包括灾难性遗忘),并消除了潜在记忆方法的表示耦合。其核心组件是捕获显式事实和隐式关系的数据合成管线,以及将复杂查询分解为针对性子查询以从记忆模型检索所需信息的多轮推理协议。虽然 MeMo 展现了强劲表现,但在训练成本、评估范围和 Memory 模型随语料大小缩放的能力方面存在局限(见附录B)。实验上,MeMo 在多样的基准上优于强基线。它还为知识整合提供了可扩展的路径,支持高效更新和与开源及闭源商用 LLM 的即插即用部署。未来工作包括更高效的记忆构建、扩展到动态语料,以及 Executive 模型与 Memory 模型间更紧密的协调循环。我们将 MeMo(记忆即模型)视为构建更灵活、可更新、知识感知 AI 系统的有前景基础。
影响声明
MeMo 提升了 LLM 在大型、领域特定语料上内化知识的能力,无需访问模型权重,降低了在法律、医学和科学研究等知识密集领域部署能力 AI 系统的门槛。通过实现与任意 LLM(包括商用模型)即插即用集成,MeMo 使原本需要大量计算资源或白盒模型访问的强大知识整合能力得以普及。同时,这种可及性引入了双重用途担忧,因为同样的能力可能被用于大规模内化错误信息、未经授权的专有数据或有害内容。此外,由于 MeMo 减少了对显式检索的依赖,可能掩盖检索信息的来源,使归因模型响应背后的来源更困难。我们鼓励未来工作研究基于记忆系统的归因机制和访问控制,并敦促从业者仔细考虑用于训练 Memory 模型的文档性质。
局限性
MeMo 对每个新语料产生前置训练成本,且表现可能因实验覆盖之外的领域、文档类型或 LLM 族而异。此外,MeMo 的表现本质上受 Memory 模型表示能力的限制,无法内化目标语料。尽管我们的实验未显示 Memory 模型已达到容量极限的明显迹象,但我们假设足够大或信息密集的语料将超出固定大小 Memory 模型能正确压缩和表示的范围。
未来工作
我们概述几个未来方向。数据生成管线计算昂贵,算法1的步骤5以 二次缩放,降低此成本仍是开放问题。系统评估分块策略及其权衡(附录D)同样是开放方向。在训练方面,随语料大小缩放 Memory 模型和开发更有效的模型合并策略以降低每语料训练成本(第5.5节)是有前景的方向。其他训练后方法如强化学习也已显示在提升模型任务表现上有效,将此类方法应用于 Memory 模型训练值得未来研究。
三、代码实现讲解
本部分结合官方代码仓库 arunv3rma/MeMo 的实际实现,对 MeMo 的四大管线进行逐层讲解,并配以技术示意图辅助理解。所有讲解均基于实际代码,标注关键文件与函数。
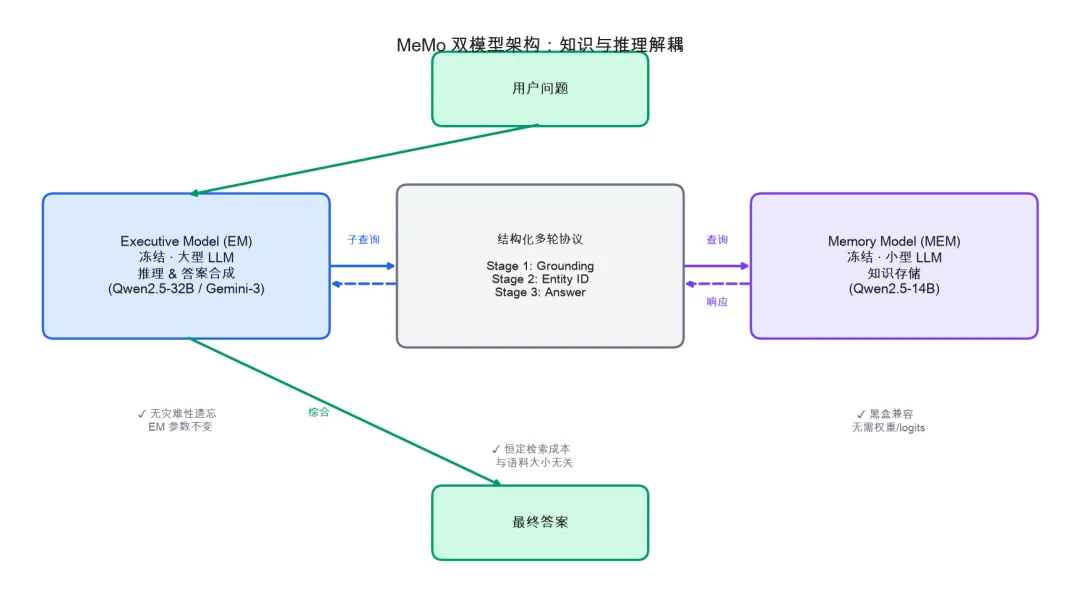
架构总览
MeMo 的核心是将知识存储与推理引擎彻底解耦,形成”双模型协作”架构。
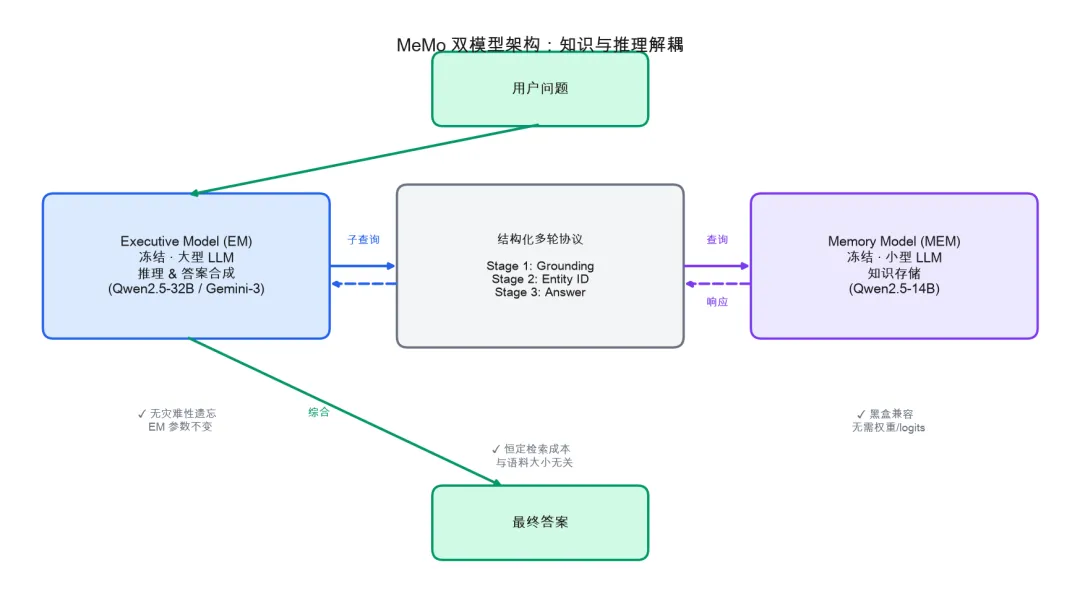
如图所示,MeMo 由两个冻结模型组成:
Executive Model (EM):功能强大的冻结 LLM(Qwen2.5-32B-Instruct 或 Gemini-3-Flash),负责将复杂查询分解为原子子问题,并综合最终答案。
Memory Model (MEM):紧凑的参数化知识存储(Qwen2.5-14B-Instruct,1.5B–14B),在反思QA数据集上训练,推理时从不查看源文档,仅从内化的参数化知识回答子查询。
二者通过 结构化多轮协议 通信。关键在于:EM 对 MEM 的所有访问都通过标准 OpenAI 兼容 API(vLLM 服务)进行,因此 EM 可以是任意黑盒 LLM——这正是 MeMo 即插即用的实现基础。
仓库的四大管线对应四个顶级目录:
MeMo/├── data_synthesis_pipeline/ //五步数据合成 → 反思QA数据集
├── sft_training/ // SFT训练 → Memory 模型
├── model_merging_scripts/ // 模型合并 → 持续知识集成
└── evaluation_pipeline/ // 结构化多轮推理 → 评估
1. 数据合成管线实现
核心文件: data_synthesis_pipeline/general_prompt_utils.py (1141行)
数据合成是 MeMo 最核心的创新——它决定了 Memory 模型能学到什么样的知识。五步管线将原始语料转化为”反思”QA数据集,每一步都有精心设计的提示词。
步骤1:事实提取(generate_directfact_qa.py)
对每个文档分块,Generator 模型并行执行两种提取,分别由两个提示词驱动:
直接提取 prepare_prompt_for_direct_fact_extraction_v3():捕获文档中显式陈述的事实。提示词强制要求每个QA对满足”自包含”——无代词、无相对时间表达、无文档引用,使用全名和绝对日期。
间接提取 prepare_prompt_for_indirect_fact_extraction():捕获需要组合、解析或推导才能得到的隐含信息。它系统性地识别六类间接事实:
计算属性(年龄 = 出生年 + 事件年)
所有关系(双向提取:“X的Y” → 正反两个QA对)
代词消解
时间计算(相对时间 → 绝对日期)
动作链(使能者→接受者→结果,从所有方向提取)
跨句推理
设计要点:双信号确保 Memory 模型既有事实回忆能力也有推理能力。代码中每步都强调”THE MOST IMPORTANT RULE”——自包含,这是后续验证步骤的基础。
步骤2:合并整合(generate_consolidation_cache.py)
prepare_prompt_for_consolidation() 提示词驱动 Generator 识别共享上下文(同一实体、时间段、关系类型)的QA对,将它们组合成涵盖多事实的复合QA对 。
提示词要求系统性地穷举所有组合排列: - 对(2个)、三元组(3个)、四元组(4个)……直到无有效添加 - 每个组合必须有”真正可识别的共同性”——不强行组合 - 一个QA对可出现在多个组合中
设计要点:这步产出”组合表示”,是 Memory 模型能泛化到未见查询的关键。论文指出,标准的改写/采样增强”未能将相关事实整合为组合表示”,而这步正是为此设计。
步骤3:验证与重写(check_self_containment_post_combination.py)
prepare_prompt_for_self_containment_check() 检查每个QA对的自包含性,识别六类违规: 1. 未解决的代词 2. 相对时间表达 3. 文档/来源引用 4. 模糊或隐含引用 5. 理解缺失的上下文 6. 不完整的答案
违规的QA对由 prepare_prompt_for_self_containment_fix() 以源块为上下文重写,重写后仍含糊的则丢弃。
设计要点:这步确保 Memory 模型的训练数据可以独立使用——推理时 MEM 回答子查询时不会有源文档上下文,因此训练数据必须自包含。
步骤4:实体浮现(generate_surface_entity_cache.py)
prepare_prompt_for_entity_surfacing() 为每个命名实体生成反向查找QA对 :问题通过属性描述实体(不命名),答案揭示实体身份。
提示词要求生成四级复杂度: - 单事实浮现(一个高区分度属性) - 双事实浮现 - 多事实浮现(3+属性,最具区分性) - 关系遍历(通过已知主实体浮现次级实体)
设计要点:这步直接对抗反转诅咒(reversal curse)——LLM 知道”A→B”但不知道”B→A”。通过训练 MEM 从间接描述推断实体,支持推理时阶段2的”实体识别”。
步骤5:跨文档合成(generate_crossdoc_entity_combination_cache.py)
prepare_prompt_for_crossdoc_anchor_combination() 是最复杂的一步,在预定义文档组上操作,识别两种跨文档连接:
Type A — 汇聚线索(converging clues):多个文档提供同一实体的不同事实,组合后可识别该实体。
Q: "Who [anchor doc fact] and [candidate doc fact]?"A: "[Entity full name]. [confirming facts]."
Type B — 平行属性(parallel property):不同文档中的不同实体共享同一属性/角色,支持比较推理。
Q: "Which [entity type]s [shared property P]?"A: "[Entity X] and [Entity Y]. [confirming sentences]."
设计要点:这步产生的QA对支撑大小 ,直接针对跨文档合成目标。代码中显式要求”不要生成所有事实都来自单一文档的QA对”,确保真正的跨文档性。
2. SFT 训练实现
核心文件: sft_training/sft_pipeline.py (585行)
训练目标是让 Memory 模型将问题直接映射到答案,不依赖源文档。这精确对应论文公式 ——仅对答案token计算下一token预测损失。
关键实现:CompletionOnlyCollator
这是训练的精髓所在。标准 SFTTrainer 会对整个序列计算损失,但 MeMo 需要只对 assistant 回答部分计算损失:


原理:通过找到 <|im_start|>assistant\n 标记的位置,将其之前的所有token(用户问题)的标签设为 -100(PyTorch 的忽略标记),使损失仅在答案token上累积。这迫使模型从问题直接生成答案,而非复制问题文本。
对应论文:这正是 的实现——条件仅为问题和先前答案token,从不以源文档为条件。
训练配置

支持的基座模型:Qwen2.5、Gemma3(sft_gemma_pipeline.py)、LFM(独立环境 lfm_requirements.txt)。LoRA 变体见 sft_lora_pipeline.py。分布式训练使用 DeepSpeed ZeRO-2(accelerate_config.yaml)。
数据流

extract_qa_pairs() 将其展平为 [{question, answer, doc_id, type}] 列表,再经 format_as_chat() 用模型 chat 模板格式化为训练文本。
3. 推理协议实现
核心文件: - evaluation_pipeline/structured_multi_turn/eval_bcp_trng_structured_multi_step.py (848行) - evaluation_pipeline/general_eval_prompt_utils.py (685行) - data_synthesis_pipeline/model_utils.py (Memory 查询提示词)
推理时,EM 和 MEM 分别由两个独立的 vLLM 服务器承载,通过 OpenAI 兼容 API 通信。三阶段协议是该文件的核心。
双服务器架构

两个模型完全独立——这正是”黑盒兼容”的实现基础。EM 可以是 OpenRouter 上的任意商用模型(--lm_model_name 参数),也可以是本地 vLLM。
Memory 查询的简洁性
MEM 接收的提示词极其简洁(model_utils.py):

阶段1:Grounding(generate_grounding_subquestions())
EM 将用户问题分解为原子、线索探针式子问题。这是整个协议中最复杂的提示词(~120行),包含五个步骤:
线索提取:列出问题中每个独立的原子线索
线索分类:区分 (A) 实体缩小型(用于识别”是谁”)和 (B) 答案携带型(直接是答案本身)
线索评估:HIGH(高区分度,生成3个标准问题)/ LOW(低区分度,1个)
问题生成:每个标准问题配3个改写变体,用于独立查询 + 多数投票
验证:检查占位符、代词、跨线索借用等8类问题
每个子问题独立由 MEM 回答(无共享上下文),产出 grounding 响应。
对应论文:这正是 Stage 1 中”EM 将查询 分解为原子子问题 , 自适应确定”的实现。
阶段2:Entity Pinning(generate_entity_pinning_prompt())
以 grounding 响应为上下文,EM 迭代确认实体。该提示词实现了几个精巧的机制:
候选排名系统:candidate_entities 列表,每个带 rank、supporting_clues、disqualifying_clues
跨时间一致性检查:同一实体在不同线索下可能属性不同(如不同年龄),需判断是否为自然演进而非矛盾
IDK streak decay:候选若被连续2次”I don’t know”,降2个排名位;3次则完全淘汰
dead_end_threshold:被问2次以上”I don’t know”的问题不再重复
终止条件:确认唯一实体 / 预算耗尽(max_entity_turns=5)

对应论文:这是 Stage 2 “迭代缩小候选实体集合直到收敛于单一实体 或预算耗尽”的实现。它利用了步骤4的实体浮现训练——MEM 学过从属性描述推断实体。
阶段3:Answer Seeking(generate_answer_seeking_prompt())
以确认实体 为条件,EM 查询 MEM 获取支撑事实。关键设计:
实体角色分类(Step 0):判断 是 subject(直接答案)、object(被作用对象)还是 intermediate(跳板)
每个子问题必须嵌入实体名:"What [attribute] did {confirmed_entity} [action]?"
entity_pivot 机制:若当前实体连续”I don’t know”,可切换到替代候选
终止决策:decision == "answer" 时综合最终答案
复杂度降级:multi-fact → two-fact → single-fact,不降至 single-fact 以下
最终综合(format_LM_final_answer())
收集所有 MEM 响应后,EM 综合最终答案。提示词强调约束覆盖推理:
3. Select the candidate that satisfies the greatest number of constraints from the original question — not the one that appears most frequently. Frequency of mention is not a reliable signal; constraint coverage is.
最终用 DeepEval(Gemini-2.5-Flash-Lite 判官)评估二元准确率。
超参数全景
4. 模型合并实现
核心文件: model_merging_scripts/model_merge/merge.py (465行)
模型合并实现持续知识集成——新语料到达时无需全量重训练。
合并方法实现
merge.py 实现了四种合并器,对应论文中的不同方法:

3. TaskArithmetic — 任务向量合并(核心方法,TIES/DARE 基于此)

扫描配置
run_sweep.py 在3个密度()下扫描6种方法,共14种配置:
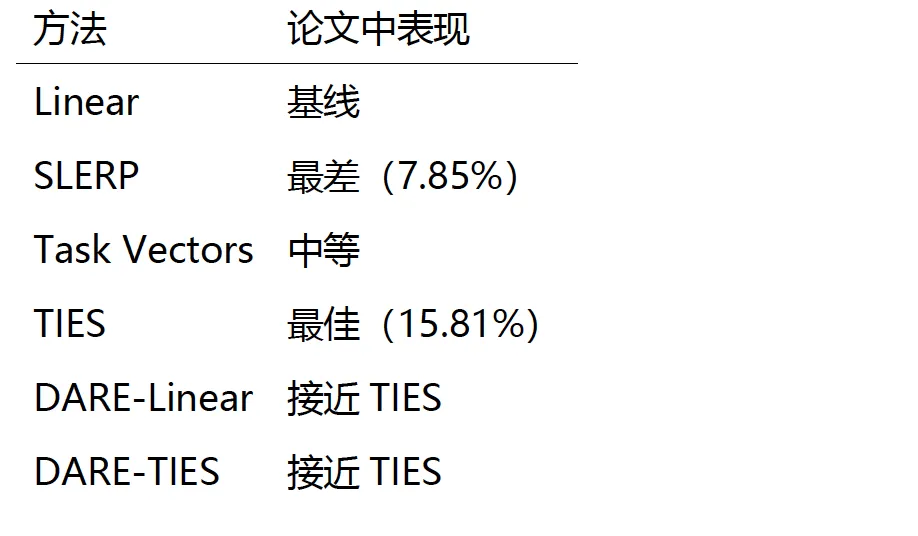
洞察:TIES 和 DARE-Linear 在 下主导扫描,表明激进稀疏化 + 符号冲突解决是此场景下最可靠的配方。这与 TIES 原论文的发现一致——大量参数是噪声,需要修剪。
关键设计洞察
1. 反思(Reflections)是组合窗口,非逐字释义
MeMo 的数据合成不生成”文档的改写”,而是生成组合表示——整合多块事实、强制自包含、双向编码实体关系。这是 Memory 模型能泛化到未见查询的根本原因。代码中每步提示词都反复强调”THE MOST IMPORTANT RULE: self-containment”,这不是装饰——它是参数化学习的必要条件。
2. 黑盒兼容的实现基础
MeMo 的即插即用能力来自一个简单的架构决策:EM 和 MEM 通过标准 HTTP API 通信。代码中 lm_client 和 sm_client 都是 AsyncOpenAI 实例,EM 可以指向 OpenRouter(任意商用模型),MEM 指向本地 vLLM。没有任何地方需要 EM 的权重、梯度或 logits。
3. 探索-利用温度分离
推理协议的温度配置揭示了”分析师”隐喻: - EM 分解问题(探索):1.0–1.1(高温) - MEM 回答(利用):0.7(低温,稳定) - EM 综合答案(利用):0.3(最低温,最准)
4. “I don’t know” 作为信号
MEM 被要求在高置信时才回答,否则说”I don’t know”。这不是缺陷——它是信号机制: - dead_end_threshold:问2次IDK的问题不再重复 - candidate_idk_streaks:候选被连续IDK则降级/淘汰 - filter_sm_responses:IDK响应在综合前被过滤
这让 EM 能自适应地转向,而非在无效路径上浪费预算。
5. 训练-推理的对称性
MeMo 的训练和推理在设计上对称: - 训练时的实体浮现QA()→ 推理时阶段2的实体识别 - 训练时的跨文档合成QA()→ 推理时阶段1的多线索grounding - 训练时的自包含验证()→ 推理时 MEM 的无上下文回答
这种对称性确保了”训练学到的”与”推理查询的”对齐。
6. 知识与推理的解耦红利
MeMo 反转了传统依赖关系:知识库(MEM)和推理引擎(EM)相互独立。这意味着: - EM 升级(Qwen → Gemini)自动带来性能提升,零 MEM 重训练 - MEM 可用较弱的开源 Generator 训练,与前沿商用 LLM 搭配 - 推理成本恒定——MEM 参数不随语料增长
实验数据印证了这一点:从 Qwen2.5-32B 切换到 Gemini-3-Flash,NarrativeQA 上提升 +26.73%,而 MEM 完全不变。
