











文档内容
2011 年计算机学科专业基础综合试题参考答案
一、单项选择题
ADCDAB ADBBB BCDBC DCDDC ADADD BCCCA DBBCC AACB
1. 2. 3. 4. 5. 6. 7. 8.
9. 10. 11. 12. 13. 14. 15. 16.
17. 18. 19. 20. 21. 22. 23. 24.
25. 26. 27. 28. 29. 30. 31. 32.
33. 34. 35. 36. 37. 38. 39. 40.
l. 解析:
在程序中,执行频率最高的语句为 "x=2*x"。设该语句共执行了 T(n)次,则 2兀n)+l~n/2, 故
T(n) = log2(n/2) - 1 = log2n - 2, 得 T(n)= O(log2n)。
2. 解析:
d为第 1 个出栈元素,则d之前的元素必定是进栈后在栈中停留。因而出栈顺序必为d_c_b_a_,
e 的顺序不定,在任一"_"上都有可能,一共有4种可能。
【另解】 d首先出栈,则 abc停留在栈中,此时栈的状态如右图所示。
e - d
飞「
此时可以有如下 4 种操作: (De 进栈后出栈,则出栈序列为 decba; ®c 出
栈, e 进栈后出栈,出栈序列为 dceba; @cb 出栈, e 进栈后出栈,出栈序列为
dcbea; ©cba 出栈, e进栈后出栈,出栈序列为 dcbae。
3. 解析:
根据题意,第一个元素进入队列后存储在 A[O]处,此时 front 和 rear 值都为 0。入队时由于
要执行(rear+ 1)%n操作,所以如果入队后指针指向 o, 则 rear初值为 n-1, 而由千第一个元素在
A[O]中,插入操作只改变rear指针,所以 front为 0 不变。
注意:©循环队列是指顺序存储的队列,而不是指逻辑上的循环,如循环单链表表示的队列
不能称为循环队列。 @front和 rear 的初值并不是固定的。
【排除法】如果 front和 rear 的初值相等,则无法判断队列空和队列满,排除A、 D。第 1 个
进入队列的元素存储在A[O]处,进队操作不会改变 front 的值,由题意可知队列非空时 front指向
队头元素,故 front初值为 o, 只能选 B。
4. 解析:
根据完全二叉树的性质,最后一个分支结点的序号为Ln12」=L16s12」=384, 故叶子结点的个
数为 768- 384 = 384。
【另解 1】由二叉树的性质 n=n社n1+n2和 n。=n2+ 1 可知, n=2n。-I +ni, 2n。-I +n1=768,
显然 n1= 1, 2n。=768, 则 n。=384。
【另解 2】完全二叉树的叶子结点只可能出现在最下两层,由题可计算完全二叉树的高度为
10。第 10层的叶子结点数为 768-(29-1)= 257; 第 10层的叶子结点在第 9层共有「257127= 129个
父结点,第 9 层的叶子结点数为(29-1)-129= 127, 则叶子结点的总数为 257+ 127 = 384。
5. 解析:
前序序列为 NLR, 后序序列为 LRN, 由千前序序列和后序序列刚好相反,故不可能存在一
个结点同时存在左右孩子,即二叉树的高度为 4。 1 为根结点,由千根结点只能有左孩子(或右孩子),因此,在中序序列中,l或在序列首或在序列尾,ABCD皆满足要求。仅考虑以1的孩子
结点2为根结点的子树,它也只能有左孩子(或右孩子),因此,在中序序列中,2或在序列首或
序列尾,ABD皆满足要求。
【另解】画出各选项与题干信息所对应的二叉树如下,故ABD均满足。
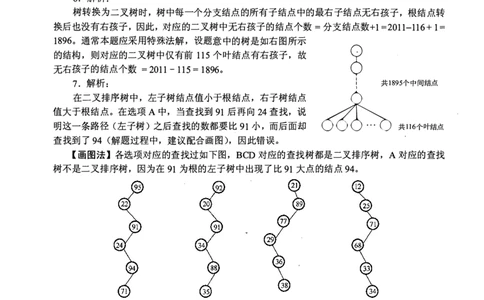
6. 解析:
树转换为二叉树时,树中每一个分支结点的所有子结点中的最右子结点无右孩子,根结点转
换后也没有右孩子,因此,对应的二叉树中无右孩子的结点个数=分支结点数+1=2011-116+ 1=
1896。通常本题应采用特殊法解,设题意中的树是如右图所示 二
的结构,则对应的二叉树中仅有前115个叶结点有右孩子,故
无右孩子的结点个数= 2011 - 115 = 198 6。
7. 解析: 二 5个中间结点
在二叉排序树中,左子树结点值小于根结点,右子树结点
值大于根结点。在选项A中,当查找到91后再向24查找,说
明这一条路径(左子树)之后查找的数都要比91小,而后面却 共ll6个叶结点
查找到了94 C解题过程中,建议配合画图),因此错误。
【画图法】各选项对应的查找过如下图, BCD对应的查找树都是二叉排序树,A对应的查找
树不是二叉排序树,因为在91为根的左子树中出现了比91大点的结点94。
(a)选项A的查找过程 (b)选项B的查找过程 (c)选项C的查找过程 (d)选项D的查找过程
8. 解析:
第一个顶点和最后一个顶点相同的路径称为回路;序列中顶点不重复出现的路径称为简单路
径;回路显然不是简单路径,故I错误;稀疏图是边比较少的情况,此时用邻接矩阵的空间复杂
度为O(n2), 必将浪费大量的空间,而邻接表的空间复杂度为O(n+e), 应该选用邻接表,故II错
误。存在回路的有向图不存在拓扑序列,若拓扑排序输出结束后所余下的顶点都有前驱,则说明
只得到了部分顶点的拓扑有序序列,图中存在回路,故III正确。
9. 解析:
Hash表的查找效率取决于散列函数、处理冲突的方法和装填因子。显然,冲突的产生概率与
装填因子(表中记录数与表长之比)的大小成正比,即装填得越满越容易发生冲突,I错误。II显然正确。采用合适的处理冲突的方式避免产生聚集现象,也将提高查找效率,例如用拉链法解
决冲突时就不存在聚集现象,用线性探测法解决冲突时易引起聚集现象, 正确。
III
解析:
10.
对绝大部分内部排序而言,只适用于顺序存储结构。快速排序在排序的过程中,既要从后向
前查找,也要从前向后查找,因此宜采用顺序存储。
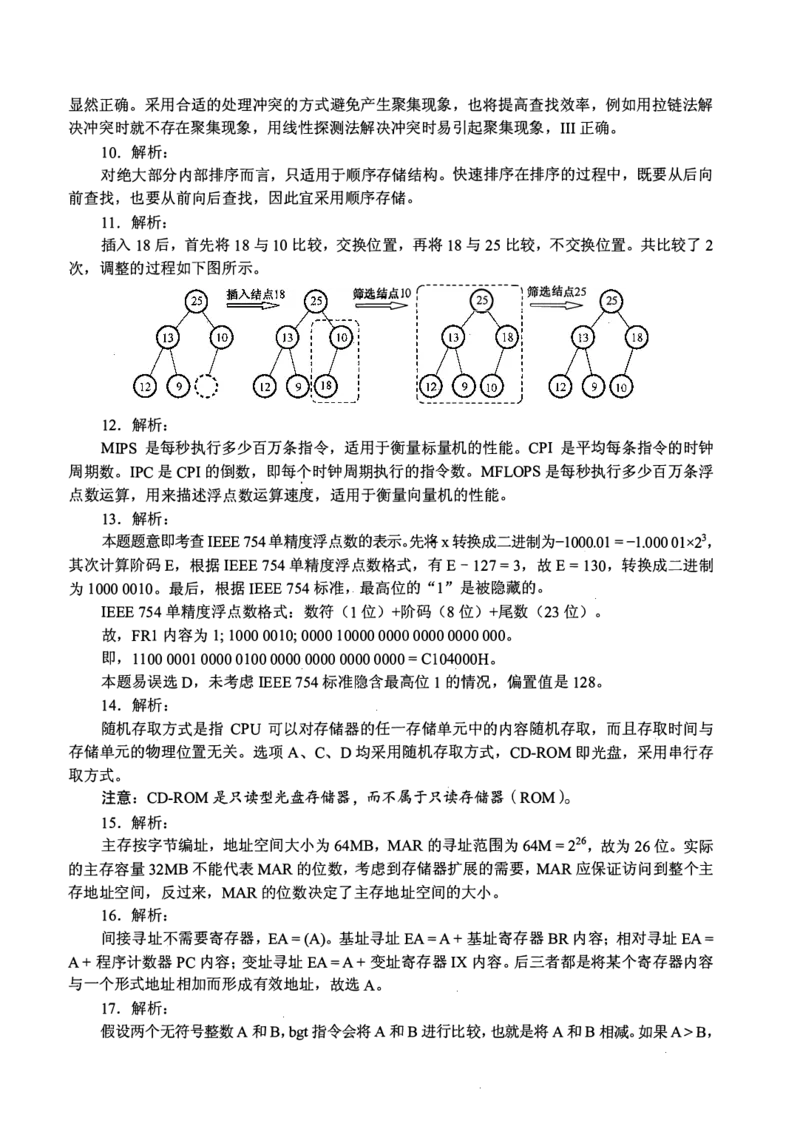
解析:
11.
插入 后,首先将 与 比较,交换位置,再将 与 比较,不交换位置。共比较了
18 18 10 18 25 2
次,调整的过程如下图所示。 r-------------
筛 � 选结点10 ! (is) 飞 ! 筛 � 选结点25 (25
l、--------------
解析:
12.
是每秒执行多少百万条指令,适用千衡量标量机的性能。 是平均每条指令的时钟
MIPS CPI
周期数。 是 的倒数,即每个时钟周期执行的指令数。 是每秒执行多少百万条浮
IPC CPI MFLOPS
点数运算,用来描述浮点数运算速度,适用于衡量向量机的性能。
解析:
13.
本题题意即考查 单精度浮点数的表示。先将 转换成二进制为 3
IEEE754 x -1000.01=-1.000 Olx2 ,
其次计算阶码 根据 单精度浮点数格式,有 故 转换成二进制
E, IEEE754 E-127=3, E=130,
为
10000010
。最后,根据
IEEE754
标准,最高位的
"1"
是被隐藏的。
单精度浮点数格式:数符(1位)+阶码 位)+尾数 位)。
IEEE 754 (8 (23
故, 内容为 。
FRI 1;1000 0010; 0000 10000 0000 0000 0000 000
即, 。
1100000100000100 0000 0000 0000 0000 = C104000H
本题易误选 未考虑 标准隐含最高位 的情况,偏置值是 。
D, IEEE754 1 128
解析:
14.
随机存取方式是指 可以对存储器的任一存储单元中的内容随机存取,而且存取时间与
CPU
存储单元的物理位置无关。选项 A 、 C 、 D 均采用随机存取方式, CD-ROM 即光盘,采用串行存
取方式。
注意:
CD-ROM
是只读型光盘存储器,而不属于只读存储器
(ROM)
。
解析:
15.
主存按字节编址,地址空间大小为 凡\的寻址范围为 26 故为 位。实际
64MB, M 64M=2 , 26
的主存容量 不能代表 凡过勺位数,考虑到存储器扩展的需要八丛 应保证访问到整个主
32MB M R
存地址空间,反过来, 凡辽彴位数决定了主存地址空间的大小。
M
解析:
16.
间接寻址不需要寄存器, 。基址寻址 基址寄存器 内容;相对寻址
EA=(A) EA=A+ BR EA=
程序计数器 内容;变址寻址 变址寄存器 内容。后三者都是将某个寄存器内容
A+ PC EA=A+ IX
与一个形式地址相加而形成有效地址,故选A。
解析:
17.
假设两个无符号整数 和 指令会将 和 进行比较,也就是将 和 相减。如果
A B,bgt A B A B A>B,o,
则A-B 肯定无进位/借位, 也不为 0 (为 0 时表示两数相同),故而 CF 和 ZF 均为 选 C。其
余选项中用到了符号标志 SF 和溢出标志 OF, 显然应当排除。
18. 解析:
指令定长、 对齐和仅Load/Store指令访存,这3 个都是RISC的特征,指令格式规整且长度
一致能大大简化指令译码的复杂度,有利于实现流水线。指令和数据按边界对齐存放能保证在一
个存取周期内取到需要的数据和指令,不用多余的延迟等待,也有利于实现流水线。只有
Load/Store 指令才能对操作数进行存储访问使取指令、 取操作数操作简化且时间长度固定,能够
有效地简化流水线的复杂度。
19. 解析:
由于不采用指令预取技术,每个指令周期都需要取指令,而不采用 Cache技术,则每次取指
令都至少要访问内存一次(当指令字长与存储字长相等且按边界对齐时),A正确。时钟周期是
CPU 的最小时间单位,每个指令周期一定大于或等于一个 CPU 时钟周期,B正确。即使是空操
作指令,在取指操作后,PC也会自动加1, C错误。由于机器处于 “ 开中断 ” 状态,在每条指令
执行结束时都可能被外部中断而打断。
20. 解析:
在取指令时,指令便是在数据线上传输的。操作数显然在数据线上传输。中断类型号用以指
出中断向量的地址,CPU 响应中断请求后,将中断应答信号-(�TR)发回到数据总线上,CPU
从数据总线上读取中断类型号后,查找中断向量表,找到相应的中断处理程序入口。而握手(应
答)信号属于通信联络控制信号,应在通信总线上传输。
21. 解析:
高优先级置0表示可被中断,比该中断优先级低(或相等)的置 l 表示不可被中断,L1只能
屏蔽L3和其自身,故M3和M置1, 中断屏蔽字汕M 凡M品=01010。
3
22. 解析:
每秒至少查询200次,每次查询至少500个时钟周期,总的时钟周期数为 200x500=1 00000,
因此CPU用于设备A的I/0的时间占CPU时间比为 100000/SOM=0 .20%。
23. 解析:
高响应比优先算法是一种综合考虑任务长度和等待时间的调度算法,响应比=(等待时间+
执行时间)/执行时间。高响应比优先算法在等待时间相同的情况下,作业执行时间越短则响应比
越高,满足短任务优先。随着长任务的等待时间增加,响应比也会变大,执行机会也就增大,
所以不会发生饥饿现象。先来先服务和时间片轮转不符合短任务优先,非抢占式短任务优先会
产生饥饿现象。
24. 解析:
缺页处理和时钟中断都属千中断,在核心态执行;进程调度是操作系统内核进程,无须用户
干预,在核心态执行;命令解释程序属于命令接口,是四个选项中唯一能面对用户的,它在用户
态执行。
25. 解析:
进程是资源分配的基本单位,线程是处理机调度的基本单位。因此,进程的代码段、进程打
开的文件、 进程的全局变量等都是进程的资源,唯有进程中某线程的栈指针是属千线程的,属于
进程的资源可以共享,属于线程的栈是独享的,对其他线程透明。
26. 解析:
输入/输出软件一般从上到下分为四个层次:用户层、与设备无关的软件层、设备驱动程序以及中断处理程序。 与设备无关的软件层也就是系统调用的处理程序。
当用户使用设备时, 首先在用户程序中发起一次系统调用,操作系统的内核接到该调用请求
后请求调用处理程序进行处理, 再转到相应的设备驱动程序, 当设备准备好或所需数据到达后设
备硬件发出中断, 将数据按上述调用顺序逆向回传到用户程序中。
27. 解析:
本题应采用排除法,逐个代入分析。当剩余资源分配给Pi, 待P 执行完后,可用资源数为(22, , 1),
1
此时仅能满足凡的需求,排除AB; 接着分配给P , 待凡执行完后, 可用资源数为(2, 2, 2) , 此时已
4
无法满足任何进程的需求, 排除C。 此外,本题还可以使用银行家算法求解(对于选择题来说, 显得
过于复杂)。
28. 解析:
缺页中断产生后,需要在内存中找到空闲页框并分配给需要访问的页(可能涉及页面置换),
之后缺页中断处理程序调用设备驱动程序做磁盘I/0, 将位于 外存上的页面调入内存, 调入后需
要修改页表, 将页表中代表该页是否在内存的标志位(或有效位) 置为1, 并将物理页框号填入
相应位置, 若必要还需修改其他相关表项等。
29 . 解析:
在具有对换功能的操作系统中, 通常把外存分为文件区和对换区。 前者用于存放文件, 后者
用于存放从内存换出的进程。抖动现象是指刚刚被换出的页很快又要被访问, 为此又要换出其他
页,而该页又很快被访问, 如此频繁地置换页面, 以致大部分时间都花在页面置换上, 引起系统
性能下降。 撤销部分进程可以减少所要用到的页面数,防止抖动。 对换区大小和进程优先级都与
抖动无关。
30 . 解析:
编译后的模块需要经过链接才能装载,而链接后形成的地址才是整个程序的完整逻辑地址空
间。 以C语言为例: C语言经过预处理(cpp)-编译(eel)-汇编(as)-链接Cld)产生可执
行文件。 其中链接的前一步, 产生了可重定位的二进制的目标文件。C语言采用源文件独立编译
的方法,如程序main.e,filel.efi, le2.efi , lel.hfi, le2.h, 在链接的前一步生成了main.ofi, lel.ofi, le2.o,
这些目标模块采用的逻辑地址都从 0开始,但只是相对于该模块的逻辑地址。链接器将这三个 文件,
lbi e和其他的库文件链接成一个可执行 文件。 链接阶段主要完成了重定位, 形成整个程序的完整逻
辑地址空间。
例如,filel.o的逻辑地址为o�1023, main.o的逻辑地址为0�1023, 假设链接时将filel.o
链接在main.o之后, 则重定位之后filel.o对应的逻辑地址就应为1024�2047。
这一题有不少同学会对C选项有疑问,认为生产 逻辑地址的阶段是链接,下面引入一个线性
地址的概念来解释为什么链接是不对的。 为了区分各种不同的地址, 下面也把逻辑地址和物理地
址一并介绍。
逻辑地址(Lgo iealAddress)是指在程序各个模块中的偏移地址。 它是相对于当前模块首址
的地址。
线性地址(LinearAddress)是指在分页式存储管理中单个程序所有模块集合在一起构成的
地址。
物理地址(PhysiealAddress)是指出现在CPU外部地址总线上的寻址物理内存的地址信号,
是地址变换的最终结果地址。 它实际上就是物理内存真正的地址。 线性地址的概念在很多操作系
统书中并不涉及,在这里引入只是为了把这题解释清楚。选择C选项的同学应该是把题目所说的
逻辑地址当成了线性地址。 实际上, 很多书中也不会把这线性地址和逻辑地址区分得那么清楚,而统一的称为逻辑地址, 这就导致了这题的错误选择。
总之,在这题中,逻辑地址指的就是段内的偏移量而不是链接后生成的整个程序全局的逻辑
地址空间, 所以逻辑地址是编译时产生的。编者在查相关资料的过程中看到了关于这个问题的 很
多不一样的 说法, 这也是操作系统这门课的一个 “ 特色”,所以这里综合了各个 说法,并给出了
一个觉得相对合理的解释, 读者不必过多纠结,实际考试碰上这种问题的概率还是很低的。
31. 解析:
在单缓冲区中,当上一个磁盘块从缓冲区读入用户区完成时,下一磁盘块才能开始读入,也
就是当最后一块磁盘块读入用户区完毕时所用时间为150 x10 = 1500µs, 加上处理最后一个磁盘块
的时间50µs,得1550µs。双缓冲区中,不存在等待磁盘块从缓冲区读入用户区的问题,10个磁
盘块可以连续从外存读入主存缓冲区,加上将最后一个磁盘块从缓冲区送到用户区的传输时间
50µs以及处理时间50µs, 也就是lOOxlO+ 50 + 50 = llOOµs。
32. 解析:
将P1中3条语句依次编号为1,2,3: P2 中3条语句依次编号为4,5,6 。依次执行1,2, 3, 4,5 ,
6得结果1 , 依次执行1,2, 4, 5,6 ,3 得结果2 ,执行4,5,1 ,2 ,3 ,6 得结果0。因此结果-1 不可能得出。
33. 解析:
TCP/IP的网络层向上只提供简单灵活的、无连接的、尽最大努力交付的数据报服务。考查PI
首部,如果是面向连接的,那么应有用于建立连接的字段,但是没有;如果提供可靠的服务,那
么至少应有序号和校验 和两个字段,但是IP分组头中也没有(IP首部中只是首部校验和)。通常
有连接、 可靠的应用是由运输层的TCP实现的。
34. 解析:
波特率B与数据传输率C的关系: C=Blog沁N为一个码元所取的离散值个数。采用4种
相位,也即可以表示4种变化,故一个码元可携带log24= 2bit信息, 则该链路的波特率=比特
率2/ = 1200 波特。
35. 解析:
在选择 重传协议中,接收方逐个确认正确接收的分组,不管接收到的分组是否有序 ,只要正
确接收就发送选择ACK分组进行确认。因此选择重传协议中的ACK分组不再具有累积确认的作
用,要特别注意其与GBN协议的区别。本题中只收到1号帧的确认,O、 2号帧超时,由于对于
1号帧的确认不具累积确认的作用,因此发送方认为接收方没有收到0、2号帧,于是重传这两帧。
因为3号帧计时器并无超时,所以暂时不用重传3号帧。
36. 解析:
CSMA/CA是无线局域网标准802.11中的协议,它在CSMA的基础上增加了冲突避免的功能。
ACK帧是CSMA/CA避免冲突的机制之一,也就是说,只有当发送方收到接收方发回的ACK帧
后才确认发出的数据帧已正确到达目的地。
【排除法】首先CDMA即码分多址,是物理层的内容; CSMA/CD即带冲突检测的载波监听
多路访问,接收方并 不需要确认;对于 CSMA, 既然CSMA/CD是其超集,是CSMA/CD没有的
内容, CSMA自然也没有。于是 使用排除法选D。
37. 解析:
要使Rl能够正确将分组路由到所有子网,则Rl中需要有到192.168.2.0/25和192.168.2.128/25
的路由,分别转换成二进制如下:
192.168.2.0: 11000000 10101000 00000010 00000000
192.168.2.128: 11000000 10101000 00000010 10000000前24 位都是相同的,于是可以聚合成超网192.168.2.0/24, 子网掩码为前24位,即
255.255.255.0。下 一跳是与Rl直接 相连的R2的地址,因此是192.168.1.2。
38. 解析:
首先分析192.168.4.0/30这个网络,主机号只占2位,地址范围为192.168.4.0-192.168.4.3,
主机号全l时,即192.168.4.3是广播地址, 主机号全0表示本网络本身,不作为主机地址使用,
因此可容纳4- 2=2个 主机。
【注意】有些题(特别是综合题)可能采用逆向思维模拟考查,给出最大容量的主机数,要
求进行适当的子网划分,也必须依照上述规律而灵活应用。
39. 解析:
在确认报文段中,同步位SYN和确认位ACK必须都是1; 返回的确认号seq是甲发送的初
始序号seq=11220加1, 即ack=11221; 同时乙也要选择并消耗一个初始序号seq, seq值由乙的
TCP进程任意给出,它与确认号、请求报文段的序号没有任何关系。
40. 解析:
TCP首部的序号字段是指本报文段数据部分的第一个字节的序号,而确认号是期待收到对方
下 一个报文段的第一个字节的序号。第三个段的序号为900, 则第二个段的序号为900-400= 500,
现在主机乙期待收到第二个段,故发给甲的确认号是500。
二、综合应用题
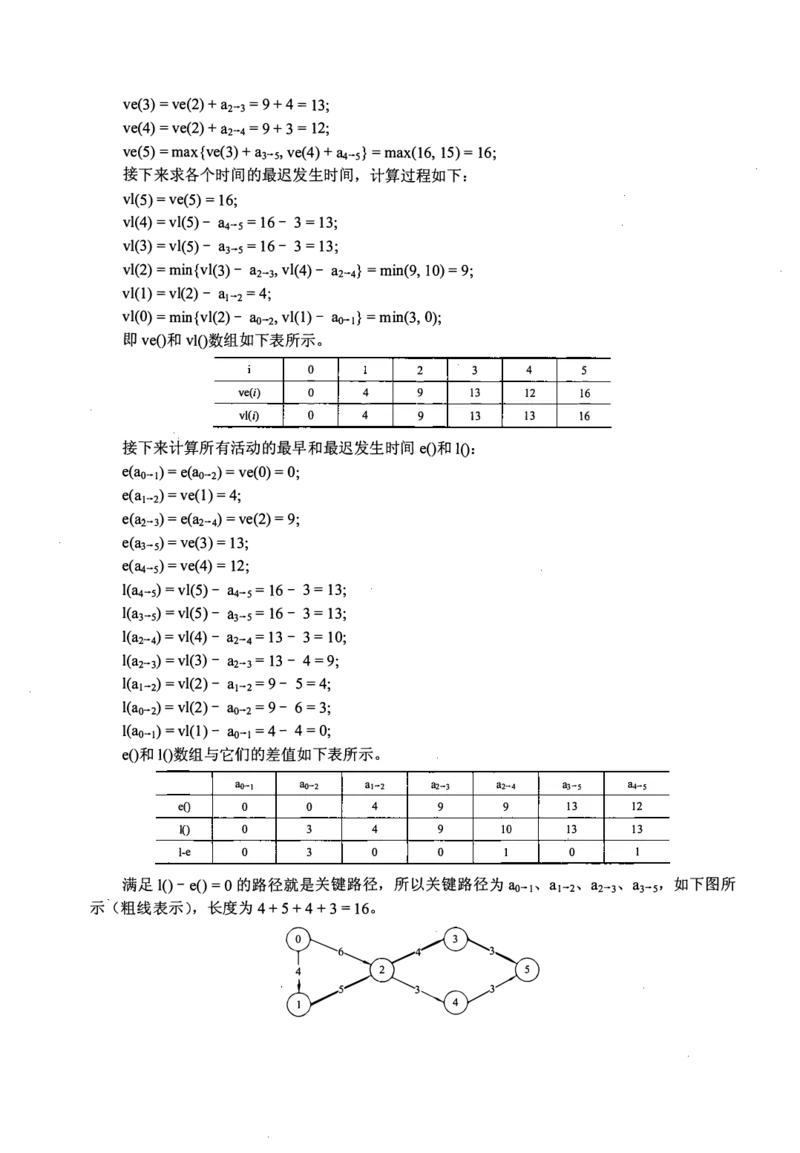
41. 解答:
I)在上三角矩阵A[6][6]中,第1行至第5行主对角线上方的元素个数分别为5, 4, 3, 2, I,
由此可以画出压缩存储数组中的元素所属行的情况,如下图所示。
I I I I I I I I I I I I I I I
4 6 《:,0 《:0 = 5 C日:;, = = 14 3 《:,, 《,, 3 3
�'-v----J'----己
第1行 第2行 第3行 第4行 第5行
用 “ 平移 ” 的思想,将前5个、后4个、后3个、后2个、后1个元素,分别移动到矩阵对
角线C"O")右边的行上。图G的邻接矩阵A如下所示。
= =
0 4 6 00
8 8 8 =
0 5
8 8
A=I:
00
0
8
4
0
3
8 3
= = 8
00 0 3
=
00 00 00 00 0
2)根据上面的邻接矩阵,画出有向带权图G, 如下图所示。
7"6二 4�3
3 3�
歹
3)按照算法,先计算各个事件的最早发生时间,计算过程如下:
ve(O) = O;
ve(l) =v e(O) +彻-1=4;
ve(2) =m ax { ve(O) +彻-1,ve(l)+ a
尸2
}=m ax(6, 4 + 5) = 9;ve(3) =ve (2) + a
2
-3 =9 +4 = 13;
ve(4) =ve (2) +a -4 = 9+ 3 = 12;
2
ve(5) =m ax{ve(3)+ a3-5, ve(4) +a 4-5} =m ax(16, 15) = 16;
接下来求各个时间的最迟发生时间,计算过程如下:
vl(5) = ve(5) =1 6;
vl(4) =vl (5)一 知-s=1 6 -3 = 13;
vl(3) =vl (5)- a
3
-5 = 16- 3 = 13;
vl(2) =m in{vl(3) -a 2 - 3 , vl(4) -a 2 -4} = min(9, 10) = 9;
vl(l) =vl (2) -a
1
-
2
= 4;
vl(O) =m in{vl(2)-砌一
2
,vl(l)一 彻一1 } =m in(3, O);
即ve()和vl()数组如下表所示。
o 2 3 4 5
- - - -
ve(i) O 4 9 13 12 16
- - - - -
vl(i) 0 4 9 13 13 16
接下来计算所有活动的最早和最迟发生时间e()和1():
e(ao- 1 ) =e (砌- 2)=ve (O) = O;
e(a 1-
2
) =ve (l) = 4;
e(a - ) =e (a -4) =ve (2) = 9;
2 3 2
e(a 一5)=ve (3) =1 3;
3
e(a4-s) =ve (4) = 12;
l(�-5) = vl(5) -�一 s=1 6-3 = 13;
l(a3-s) = vl(5) -a3-s =1 6- 3 = 13;
l(a2-4) =vl (4) -a 一4=1 3 -3 =1 0;
2
l(a2-3) =vl (3) -a - = 13- 4 =9 ;
2 3
l(a 1 一2)= vl(2) -a 1 -2 =9 -5 = 4;
I(ao-
2
) =vl (2)一 的-
2
=9 - 6 = 3;
I(ao- 1) = vl(l) -砌一
1
=4-4 =0;
e()和1()数组与它们的差值如下表所示。
砌。-1 的 。一2 a 尸 2 a2一3 a2-4 a3一5 缸 -5
e() 。 4 9 9 13 12
I() 。 3 4 。 9。 10 1 。 3 13
1-e 3 I I
满足l()-e() = 0的路径就是关键路径,所以关键路径为a 忙l、a 尸2 、a 壬3 、a 3 一5'如下图所
示(粗线表示),长度为4+5+4+3=16。
�:::x 4
�3
又 叉
4 3歹3
产42. 解答:
I)求两个序列A和B的中位数最简单的办法就是将两个升序序列进行归并排序,然后求其
中位数。这种解法虽可求解,但在时间和空间两方面都不大符合高效的要求,但也能获得部分
分值。
根据题目分析,分别求两个升序序列A和B的中位数,设为a和b。
@若a= b, 则a或b即为所求的中位数。
原因:容易验证,如果将两个序列归并排序,则最终序列中,排在子序列ab前边的元素为
先前两个序列中排在a和b前边的元素;排在子序列ab后边的元素为先前两个序列中排在a和b
后边的元素。所以子序列ab一定位于最终序列的中间,又因为a= b, 显然a就是中位数。
@否则(假设ab, 则舍弃序列A中较大的一半,同时舍弃序列 B中较小的一半,要求舍弃的长度
相等。
在保留的两个升序序列中,重复过程@、@、@,直到两个序列中只含一个元素时为止,较
小者即为所求的中位数。
2)算法的实现如下:
int. M Seai::-ch (工11.t A[J,int B[l,int n) {
...:.
int. s 1=0, dl=n-1, ml, s2=1,,d2=n一 1,m2;
II分别表示序列A和B的首位数、末位数和中位数
while(sl!=dll ls2!=d2) (
ml=(sl+dl)l2;
m2=(s2+d2)12;
if(A[ml]==B[m2])
return -P.,[ml]; //满足条件1)
if(A[ml]
