









文档内容
MST老唐说题26版一轮
第 节 成对数据的统计分析
6
知识点一、变量间的相关关系
1、变量之间的相关关系
当自变量取值一定时,因变量的取值带有一定的随机性,则这两个变量之间的关系叫相关关系.由于
相关关系的不确定性,在寻找变量之间相关关系的过程中,统计发挥着非常重要的作用.我们可以通过收
集大量的数据,在对数据进行统计分析的基础上,发现其中的规律,对它们的关系作出判断.
注意:相关关系与函数关系是不同的,相关关系是一种非确定的关系,函数关系是一种确定的关系,
而且函数关系是一种因果关系,但相关关系不一定是因果关系,也可能是伴随关系.
2、散点图
将样本中的n个数据点(x,y )(i1,2,,n)描在平面直角坐标系中,所得图形叫做散点图.根据散点图
i i
中点的分布可以直观地判断两个变量之间的关系.
(1)如果散点图中的点散布在从左下角到右上角的区域内,对于两个变量的这种相关关系,我们将它
称为正相关,如图(1)所示;
(2)如果散点图中的点散布在从左上角到右下角的区域内,对于两个变量的这种相关关系,我们将它
称为负相关,如图(2)所示.
3、相关系数
若相应于变量x的取值x ,变量 y的观测值为y (1in),则变量x与 y的相关系数
i i
n n
(x x)(y y) x y nxy
i i i i
r i1 i1 ,通常用r 来衡量x与y之间的线性关系的强弱,r
n n n n
(x x)2(y y)2 x2 nx 2 y2 ny 2
i i i i
i1 i1 i1 i1
的范围为1r1.
(1)当r0时,表示两个变量正相关;当r0时,表示两个变量负相关.
(2) r 越接近1,表示两个变量的线性相关性越强; r 越接近0,表示两个变量间几乎不存在线性相
关关系.当|r|1时,所有数据点都在一条直线上.
(3)通常当 r 0.75时,认为两个变量具有很强的线性相关关系.
知识点二、线性回归
1、线性回归
线性回归是研究不具备确定的函数关系的两个变量之间的关系(相关关系)的方法.
1/12
学学科科网网((北北京京))股股份份有有限限公公司司MST老唐说题26版一轮
对于一组具有线性相关关系的数据(x ,y ),(x ,y ),…,(x ,y ),其回归方程ybxa的求法为
1 1 2 2 n n
n n
(x x)(y y) x y nxy
i i i i
b i1 i1
n n
(x x)2 x2 nx 2
i i
i1 i1
a ybx
1 n 1 n
其中,x x ,y y ,(x, y)称为样本点的中心.
n i n i
i1 i1
2、残差分析
对于预报变量 y,通过观测得到的数据称为观测值 y ,通过回归方程得到的y称为预测值,观测值减
i
去预测值等于残差,eˆ 称为相应于点(x,y)的残差,即有eˆ y yˆ .残差是随机误差的估计结果,通过对
i i i i i i
残差的分析可以判断模型刻画数据的效果以及判断原始数据中是否存在可疑数据等,这方面工作称为残差
分析.
(1)残差图
通过残差分析,残差点x,eˆ 比较均匀地落在水平的带状区域中,说明选用的模型比较合适,其中这样
i i
的带状区域的宽度越窄,说明模型拟合精确度越高;反之,不合适.
n
(2)通过残差平方和Q(y yˆ )2分析,如果残差平方和越小,则说明选用的模型的拟合效果越好;
i i
i1
反之,不合适.
(3)相关指数
n
(y yˆ )2
i i
用相关指数来刻画回归的效果,其计算公式是:R2 1 i1 .
n
(y y)2
i
i1
R2越接近于1,说明残差的平方和越小,也表示回归的效果越好.
知识点三、非线性回归
解答非线性拟合问题,要先根据散点图选择合适的函数类型,设出回归方程,通过换元将陌生的非线
性回归方程化归转化为我们熟悉的线性回归方程.
求出样本数据换元后的值,然后根据线性回归方程的计算方法计算变换后的线性回归方程系数,还原
后即可求出非线性回归方程,再利用回归方程进行预报预测,注意计算要细心,避免计算错误.
1、建立非线性回归模型的基本步骤:
(1)确定研究对象,明确哪个是解释变量,哪个是预报变量;
(2)画出确定好的解释变量和预报变量的散点图,观察它们之间的关系(是否存在非线性关系);
(3)由经验确定非线性回归方程的类型(如我们观察到数据呈非线性关系,一般选用反比例函数、二
次函数、指数函数、对数函数、幂函数模型等);
2/12
学学科科网网((北北京京))股股份份有有限限公公司司MST老唐说题26版一轮
(4)通过换元,将非线性回归方程模型转化为线性回归方程模型;
(5)按照公式计算线性回归方程中的参数(如最小二乘法),得到线性回归方程;
(6)消去新元,得到非线性回归方程;
(7)得出结果后分析残差图是否有异常.若存在异常,则检查数据是否有误,或模型是否合适等.
知识点四、独立性检验
1、分类变量和列联表
(1)分类变量:
变量的不同“值”表示个体所属的不同类别,像这样的变量称为分类变量.
(2)列联表:
①定义:列出的两个分类变量的频数表称为列联表.
②2×2列联表.
一般地,假设有两个分类变量X和Y,它们的取值分别为{x ,x }和{y ,y },其样本频数列联表(称
1 2 1 2
为2×2列联表)为
y y 总计
1 2
x a b ab
1
x c d cd
2
总计 ac bd nabcd
a c
从22列表中,依据 与 的值可直观得出结论:两个变量是否有关系.
ab cd
2、等高条形图
(1)等高条形图和表格相比,更能直观地反映出两个分类变量间是否相互影响,常用等高条形图表示
列联表数据的频率特征.
a c
(2)观察等高条形图发现 与 相差很大,就判断两个分类变量之间有关系.
ab cd
3、独立性检验
n(ad bc)2
计算随机变量2 利用2的取值推断分类变量X和Y是否独立的方法称为χ2
(ab)(cd)(ac)(bd)
独立性检验.
0.10 0.05 0.010 0.005 0.001
x 2.706 3.841 6.635 7.879 10.828
3/12
学学科科网网((北北京京))股股份份有有限限公公司司MST老唐说题26版一轮
【解题方法总结】
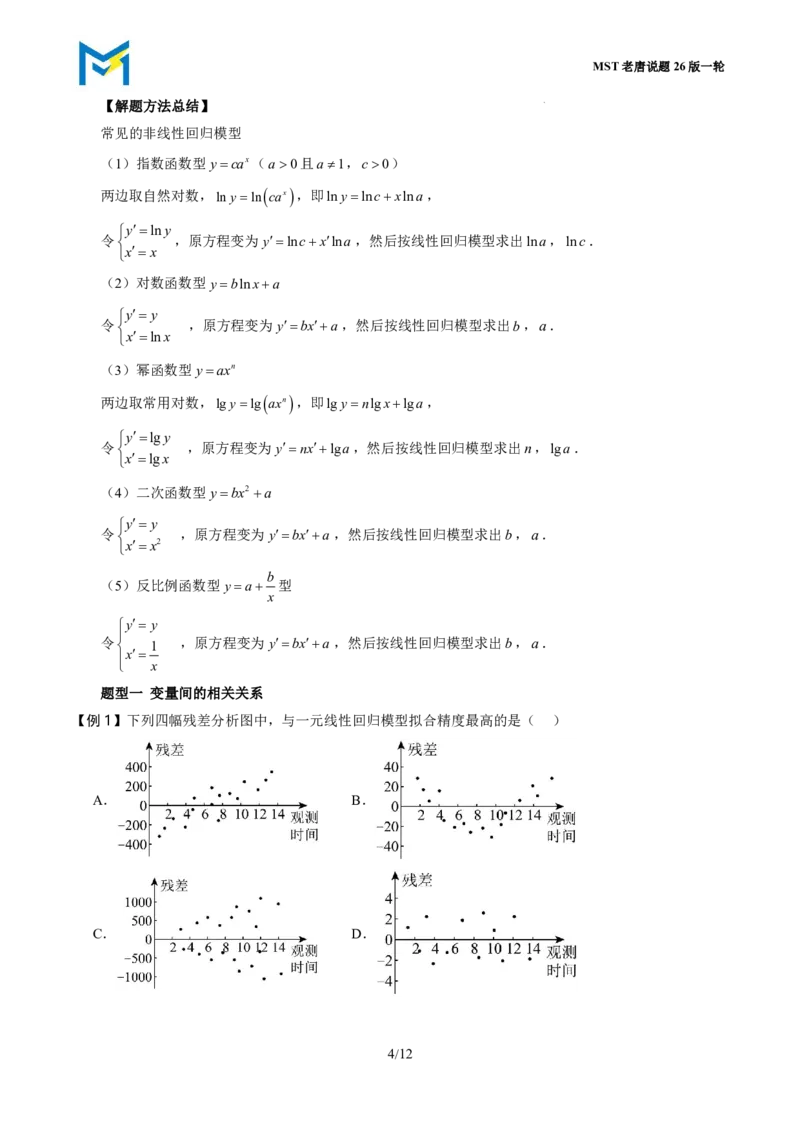
常见的非线性回归模型
(1)指数函数型ycax(a0且a1,c0)
两边取自然对数,lnyln cax,即lnylncxlna,
ylny
令 ,原方程变为ylncxlna,然后按线性回归模型求出lna,lnc.
xx
(2)对数函数型yblnxa
y y
令 ,原方程变为 ybxa,然后按线性回归模型求出b,a.
xlnx
(3)幂函数型yaxn
两边取常用对数,lgylg axn,即lgynlgxlga,
ylgy
令 ,原方程变为ynxlga,然后按线性回归模型求出n,lga.
xlgx
(4)二次函数型ybx2 a
y y
令 ,原方程变为 ybxa,然后按线性回归模型求出b,a.
xx2
b
(5)反比例函数型ya 型
x
y y
令
1
,原方程变为 ybxa,然后按线性回归模型求出b,a.
x
x
题型一 变量间的相关关系
【例1】下列四幅残差分析图中,与一元线性回归模型拟合精度最高的是( )
A. B.
C. D.
4/12
学学科科网网((北北京京))股股份份有有限限公公司司MST老唐说题26版一轮
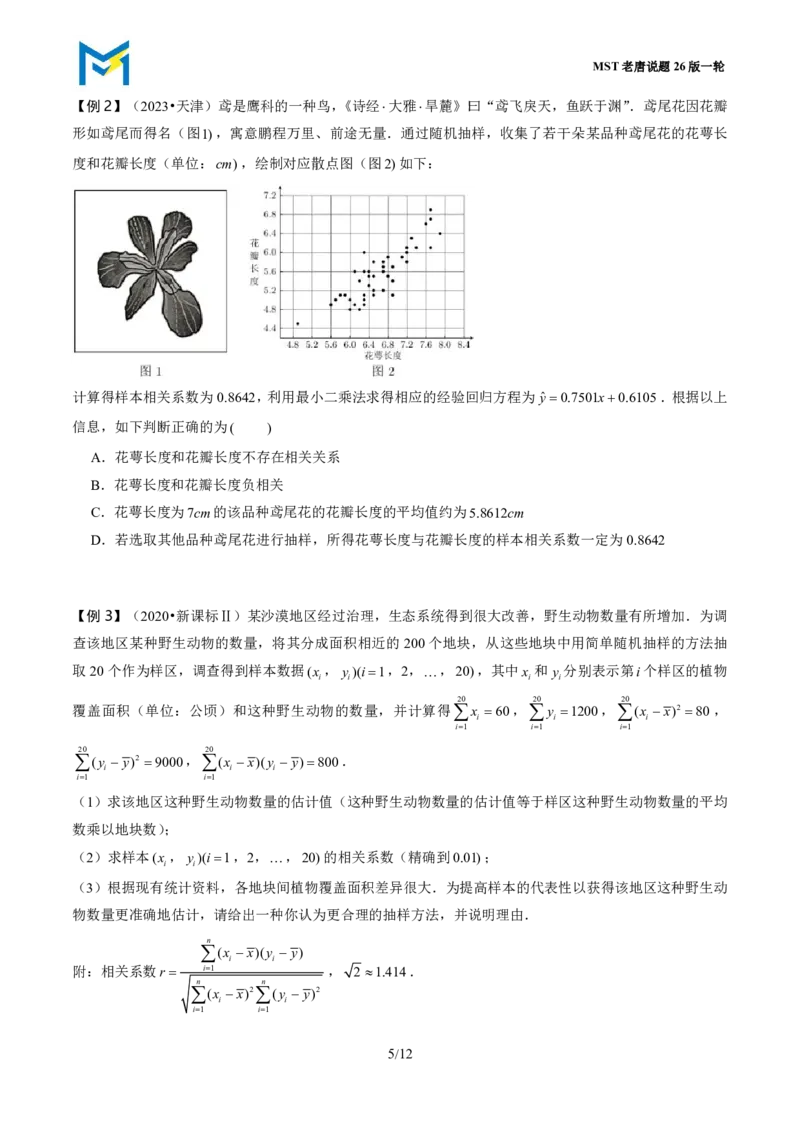
【例2】(2023•天津)鸢是鹰科的一种鸟,《诗经大雅旱麓》曰“鸢飞戾天,鱼跃于渊”.鸢尾花因花瓣
形如鸢尾而得名(图1),寓意鹏程万里、前途无量.通过随机抽样,收集了若干朵某品种鸢尾花的花萼长
度和花瓣长度(单位:cm),绘制对应散点图(图2)如下:
计算得样本相关系数为0.8642,利用最小二乘法求得相应的经验回归方程为yˆ 0.7501x0.6105.根据以上
信息,如下判断正确的为( )
A.花萼长度和花瓣长度不存在相关关系
B.花萼长度和花瓣长度负相关
C.花萼长度为7cm的该品种鸢尾花的花瓣长度的平均值约为5.8612cm
D.若选取其他品种鸢尾花进行抽样,所得花萼长度与花瓣长度的样本相关系数一定为0.8642
【例3】(2020•新课标Ⅱ)某沙漠地区经过治理,生态系统得到很大改善,野生动物数量有所增加.为调
查该地区某种野生动物的数量,将其分成面积相近的200个地块,从这些地块中用简单随机抽样的方法抽
取20个作为样区,调查得到样本数据(x ,y )(i1,2,,20),其中x 和y 分别表示第i个样区的植物
i i i i
20 20 20
覆盖面积(单位:公顷)和这种野生动物的数量,并计算得x 60,y 1200,(x x)2 80,
i i i
i1 i1 i1
20 20
(y y)2 9000,(x x)(y y)800.
i i i
i1 i1
(1)求该地区这种野生动物数量的估计值(这种野生动物数量的估计值等于样区这种野生动物数量的平均
数乘以地块数);
(2)求样本(x ,y )(i1,2,,20)的相关系数(精确到0.01);
i i
(3)根据现有统计资料,各地块间植物覆盖面积差异很大.为提高样本的代表性以获得该地区这种野生动
物数量更准确地估计,请给出一种你认为更合理的抽样方法,并说明理由.
n
(x x)(y y)
i i
附:相关系数r i1 , 2 1.414.
n n
(x x)2(y y)2
i i
i1 i1
5/12
学学科科网网((北北京京))股股份份有有限限公公司司MST老唐说题26版一轮
题型二 一元线性回归模型
【例1】为研究某种细菌在特定环境下,随时间变化的繁殖情况,得到如下实验数据:
天数x(天) 3 4 5 6
繁殖个数y(千个) 2.5 3 4 4.5
由最小二乘法得y与x的线性回归方程为y0.7xa,则当x7时,繁殖个数y的预测值为( )
A.4.9 B.5.25 C.5.95 D.6.15
【例2】某社区为了丰富退休人员的业余文化生活,自2018年以来,始终坚持开展“悦读小屋读书活动”.下
表是对2018年以来近5年该社区退休人员的年人均借阅量的数据统计:
年份 2018 2019 2020 2021 2022
年份代码x 1 2 3 4 5
年人均借阅量y(册) y y 16 22 28
1 2
5
(参考数据:y 90)通过分析散点图的特征后,年人均借阅量y关于年份代码x的回归分析模型为
i
i1
y5xm,则2023年的年人均借阅量约为( )
A.31 B.32 C.33 D.34
【例3】某单位在当地定点帮扶某村种植一种草莓,并把这种原本露天种植的草莓搬到了大棚里,获得了很
好的经济效益.根据资料显示,产出的草莓的箱数x(单位:箱)与成本y(单位:千元)的关系如下:
x 10 20 30 40 60 80
y y y y y y y
1 2 3 4 5 6
(1)根据散点图可以认为x与y之间存在线性相关关系,请用最小二乘法求出线性回归方程yˆ b ˆ xaˆ(aˆ,b ˆ
用分数表示)
(2)某农户种植的草莓主要以300元/箱的价格给当地大型商超供货,多余的草莓全部以200元/箱的价格销售
给当地小商贩.据统计,往年1月份当地大型商超草莓的需求量为50箱、100箱、150箱、200箱的概率分
1 1 1 1
别为 , , , ,根据回归方程以及往年商超草莓的需求情况进行预测,求今年1月份农户草莓的种
10 5 2 5
植量为200箱时所获得的利润情况.(最后结果精确到个位)
n
x xy y
6 6 i i
附:x xy y790,y 54,在线性回归直线方程yˆ b ˆ xaˆ中b ˆ i1 ,aˆ yb ˆ x.
i i i n
i1 i1 x x2
i
i1
6/12
学学科科网网((北北京京))股股份份有有限限公公司司MST老唐说题26版一轮
题型三 非线性回归
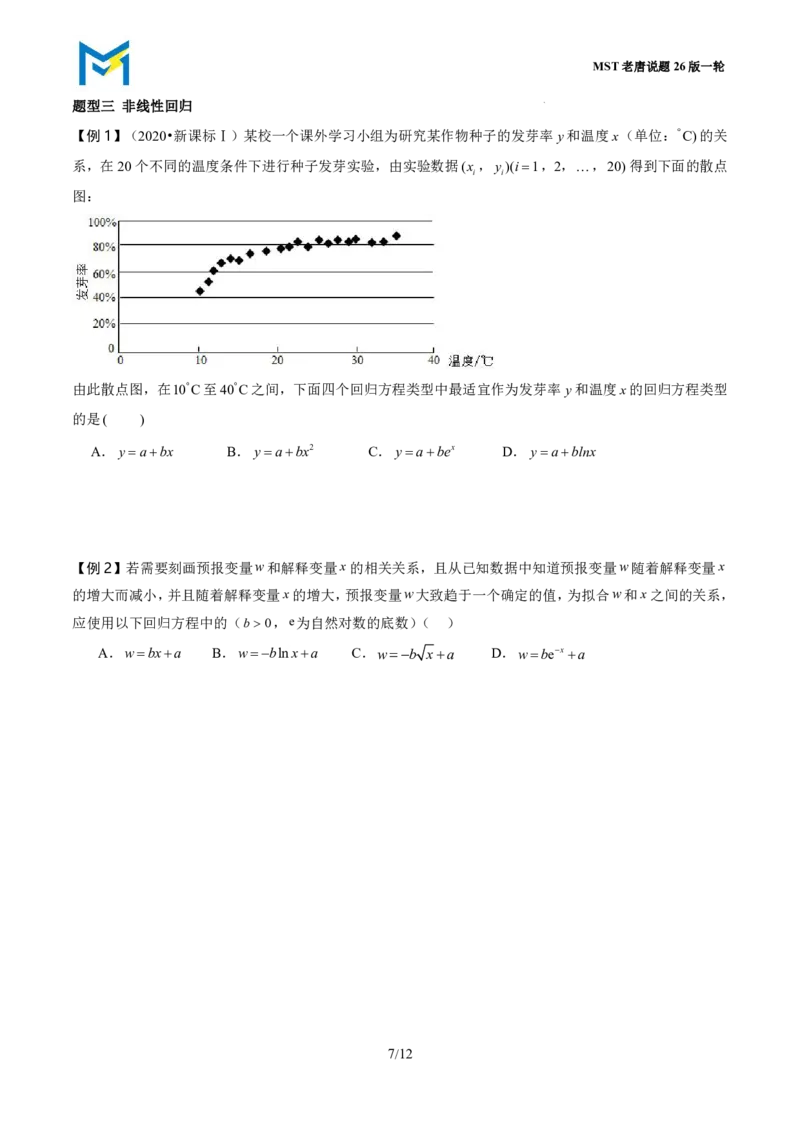
【例1】(2020•新课标Ⅰ)某校一个课外学习小组为研究某作物种子的发芽率y和温度x(单位:C)的关
系,在20个不同的温度条件下进行种子发芽实验,由实验数据(x ,y )(i1,2,,20)得到下面的散点
i i
图:
由此散点图,在10C至40C之间,下面四个回归方程类型中最适宜作为发芽率y和温度x的回归方程类型
的是( )
A.yabx B.yabx2 C.yabex D.yablnx
【例2】若需要刻画预报变量w和解释变量x的相关关系,且从已知数据中知道预报变量w随着解释变量x
的增大而减小,并且随着解释变量x的增大,预报变量w大致趋于一个确定的值,为拟合w和x之间的关系,
应使用以下回归方程中的(b0,e为自然对数的底数)( )
A.wbxa B.wblnxa C.wb xa D.wbexa
7/12
学学科科网网((北北京京))股股份份有有限限公公司司MST老唐说题26版一轮
【例3】在正常生产条件下,根据经验,可以认为化肥的有效利用率近似服从正态分布N(0.54,0.022),而
化肥施肥量因农作物的种类不同每亩也存在差异.
(1)假设生产条件正常,记X 表示化肥的有效利用率,求P(X 0.56);
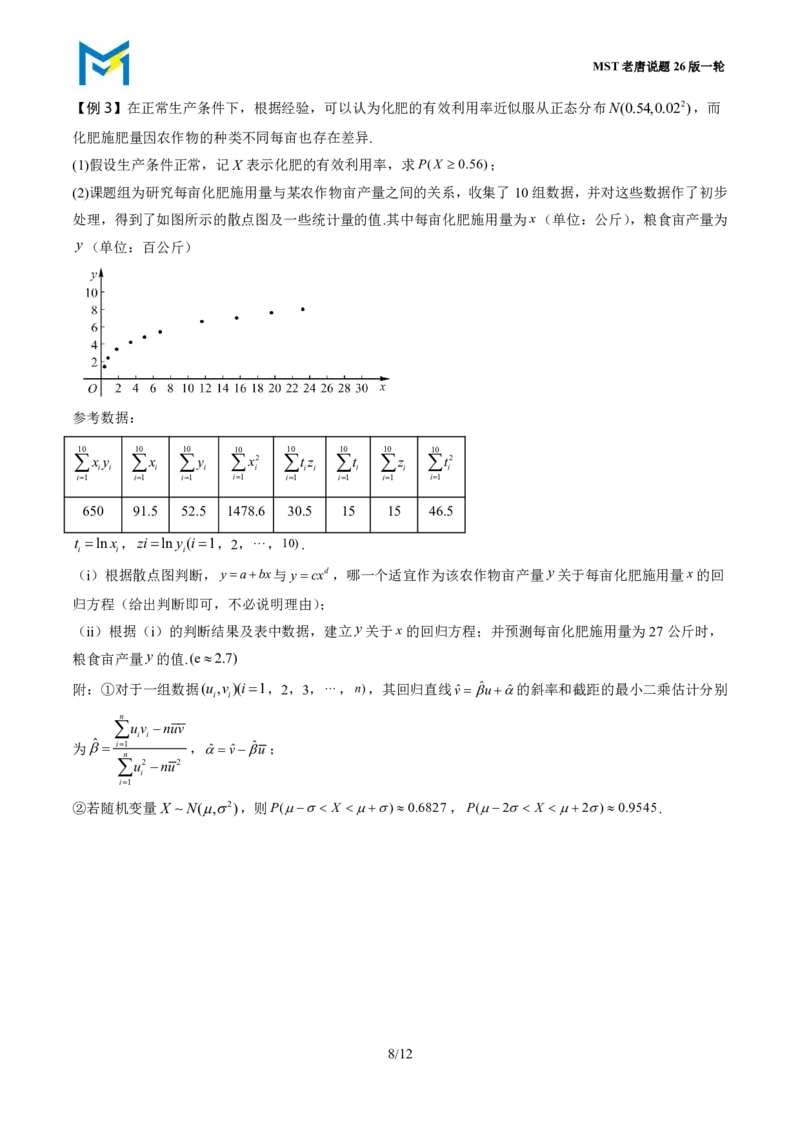
(2)课题组为研究每亩化肥施用量与某农作物亩产量之间的关系,收集了10组数据,并对这些数据作了初步
处理,得到了如图所示的散点图及一些统计量的值.其中每亩化肥施用量为x(单位:公斤),粮食亩产量为
y(单位:百公斤)
参考数据:
10 10 10 10 10 10 10 10
x y x y x2 tz t z t2
i i i i i i i i i i
i1 i1 i1 i1 i1 i1 i1 i1
650 91.5 52.5 1478.6 30.5 15 15 46.5
t lnx ,zilny(i1,2,,10).
i i i
(i)根据散点图判断,yabx与ycxd,哪一个适宜作为该农作物亩产量y关于每亩化肥施用量x的回
归方程(给出判断即可,不必说明理由);
(ii)根据(i)的判断结果及表中数据,建立y关于x的回归方程;并预测每亩化肥施用量为27公斤时,
粮食亩产量y的值.(e2.7)
附:①对于一组数据(u,v)(i1,2,3,,n),其回归直线vˆˆuˆ的斜率和截距的最小二乘估计分别
i i
n
uv nuv
i i
为ˆ i1 ,ˆ vˆˆu ;
n
u2nu2
i
i1
②若随机变量X N(,2),则P( X )0.6827,P(2 X 2)0.9545.
8/12
学学科科网网((北北京京))股股份份有有限限公公司司MST老唐说题26版一轮
题型四 列联表与独立性检验
【例1】在新高考改革中,浙江省新高考实行的是7选3的33模式,即语数外三门为必考科目,然后从物
理、化学、生物、政治、历史、地理、技术(含信息技术和通用技术)7门课中选考3门.某校高二学生选
课情况如下列联表一和列联表二(单位:人)
选物理 不选物理 总计
男生 340 110 450
女生 140 210 350
总计 480 320 800
表一
选生物 不选生物 总计
男生 150 300 450
女生 150 200 350
总计 300 500 800
表二
试根据小概率值0.005的独立性检验,分析物理和生物选课与性别是否有关( )
附:2
(n adbc)2
,nabcd.P 2 x
(ab)(cd)(ac)(bd)
0.15 0.10 0.05 0.025 0.01 0.005 0.001
x 2.072 2.706 3.841 5.024 6.635 7.879 10.828
a
A.选物理与性别有关,选生物与性别有关
B.选物理与性别无关,选生物与性别有关
C.选物理与性别有关,选生物与性别无关
D.选物理与性别无关,选生物与性别无关
9/12
学学科科网网((北北京京))股股份份有有限限公公司司MST老唐说题26版一轮
【例2】2022年卡塔尔世界杯决赛圈共有32支球队参加,欧洲球队有13支:其中有5支欧洲球队闯入8
强.比赛进入淘汰赛阶段后,必须要分出胜负.淘汰赛规则如下:在比赛常规时间90分钟内分出胜负;比赛
结束,若比分相同.则进入30分钟的加时赛.在加时赛分出胜负,比赛结束,若加时赛比分依然相同,就要
通过点球大战来分出最后的胜负.点球大战分为2个阶段,第一阶段:共5轮,双方每轮各派1名球员,依
次踢点球,以5轮的总进球数作为标准,5轮合计踢进点球数更多的球队获得比赛的胜利.如果第一阶段的5
轮还是平局,则进入第二阶段:在该阶段双方每轮各派1名球员,依次踢点球,如果在一轮里,双方都进
球或者双方都不进球,则继续下一轮,直到某一轮里,一方罚进点球,另一方没罚进,比赛结束,罚进点
球的一方获得最终的胜利.
(1)根据题意填写下面的22列联表,并根据小概率值0.01的独立性检验,判断32支决赛圈球队“闯入8
强”与“是欧洲球队”是否有关.
欧洲球队 其他球队 合计
闯入8强
未闯入8强
合计
(2)甲、乙两队在淘汰赛相遇,经过120分钟比赛未分出胜负,双方进入点球大战.已知甲队球员每轮踢进点
1 2
球的概率为 ,乙队球员每轮踢进点球的概率为 ,每轮每队是否进球相互独立,在点球大战中,两队前3
3 3
轮比分为3:3,试求出甲队在第二阶段第一轮结束后获得最终胜利的概率.
n(adbc)2
参考公式:2 ,nabcd .
abcdacbd
P 2 0.1 0.05 0.01 0.005 0.001
2.706 3.841 6.635 7.879 10.828
10/12
学学科科网网((北北京京))股股份份有有限限公公司司MST老唐说题26版一轮
【例3】(2022•新高考Ⅰ)一医疗团队为研究某地的一种地方性疾病与当地居民的卫生习惯(卫生习惯分
为良好和不够良好两类)的关系,在已患该疾病的病例中随机调查了100例(称为病例组),同时在未患该
疾病的人群中随机调查了100人(称为对照组),得到如下数据:
不够良好 良好
病例组 40 60
对照组 10 90
(1)能否有99%的把握认为患该疾病群体与未患该疾病群体的卫生习惯有差异?
(2)从该地的人群中任选一人,A表示事件“选到的人卫生习惯不够良好”, B表示事件“选到的人患有
P(B|A) P(B|A)
该疾病”, 与 的比值是卫生习惯不够良好对患该疾病风险程度的一项度量指标,记该指标
P(B|A) P(B|A)
为R.
P(A|B) P(A|B)
(ⅰ)证明:R ;
P(A|B) P(A|B)
(ⅱ)利用该调查数据,给出P(A|B),P(A|B)的估计值,并利用(ⅰ)的结果给出R的估计值.
n(ad bc)2
附:K2 .
(ab)(cd)(ac)(bd)
P(K2 k) 0.050 0.010 0.001
k 3.841 6.635 10.828
11/12
学学科科网网((北北京京))股股份份有有限限公公司司MST老唐说题26版一轮
题型五 误差分析
【例1】已知一组样本数据 x,y , x,y ,,x ,y ,根据这组数据的散点图分析x与y之间的线性相
1 1 2 2 n n
关关系,若求得其线性回归方程为yˆ 30.413.5x,则在样本点9,53处的残差为( )
A.38.1 B.22.6 C.38.1 D.91.1
【例2】某新能源汽车生产公司,为了研究某生产环节中两个变量x,y之间的相关关系,统计样本数据得到
如下表格:
x 20 23 25 27 30
i
y 2 2.4 3 3 4.6
i
1
由表格中的数据可以得到y与x的经验回归方程为yˆ xa,据此计算,下列选项中残差的绝对值最小的
4
样本数据是( )
A.30,4.6 B.27,3
C.25,3 D.23,2.4
12/12
学学科科网网((北北京京))股股份份有有限限公公司司

