夜雨聆风
夜雨聆风





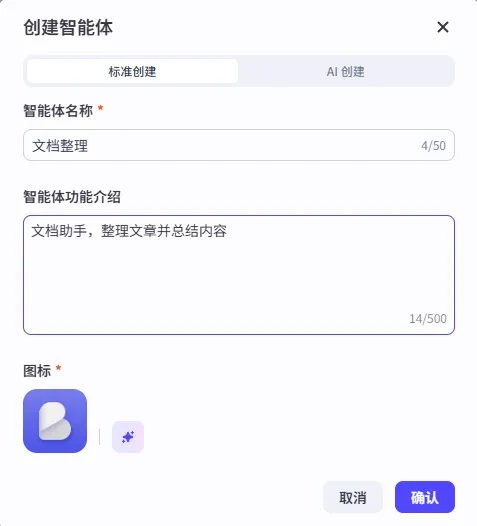
告别文档乱糟糟!用扣子编程5分钟搞定智能整理体,效率翻10倍【实战】
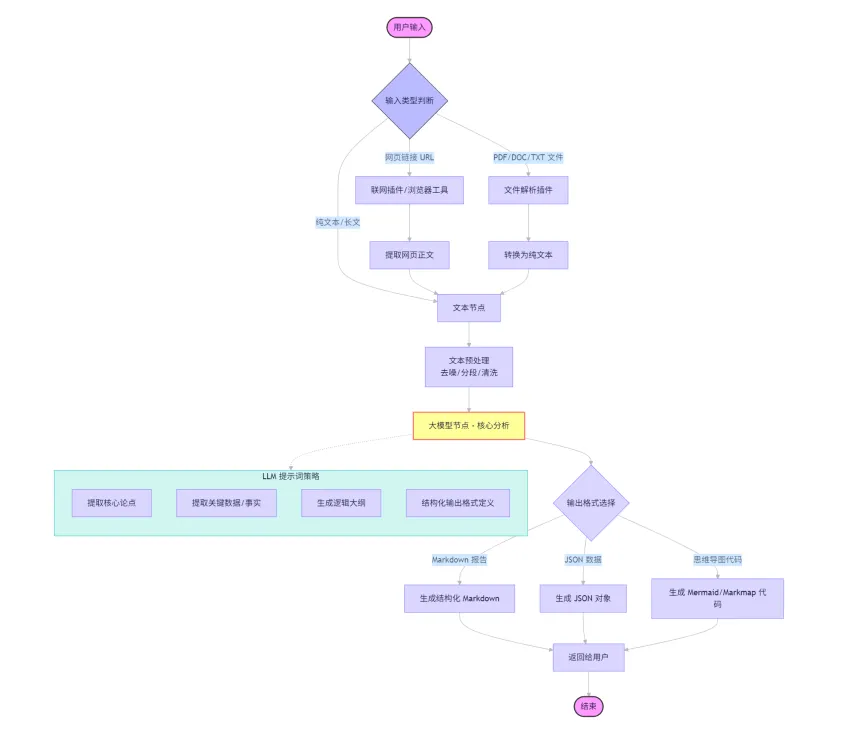
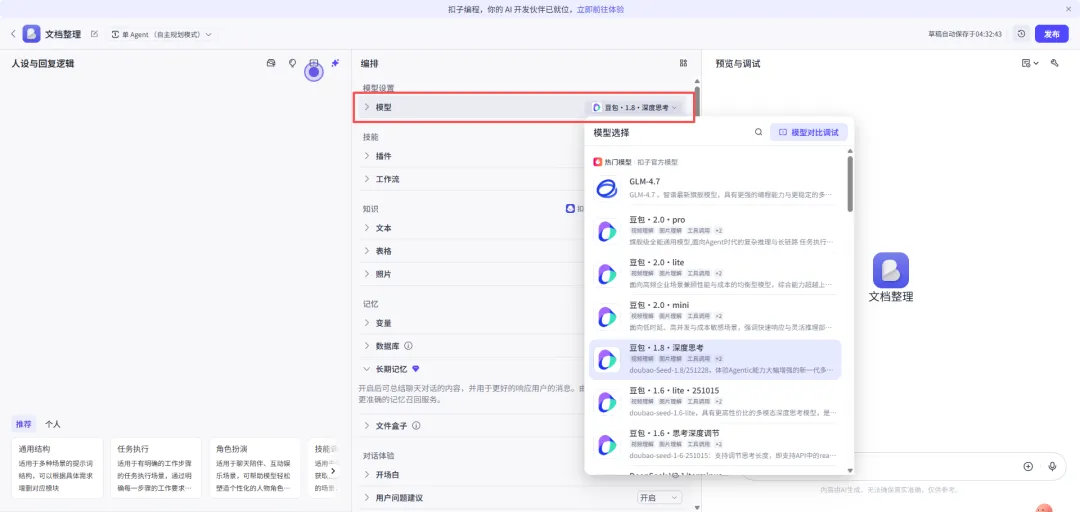
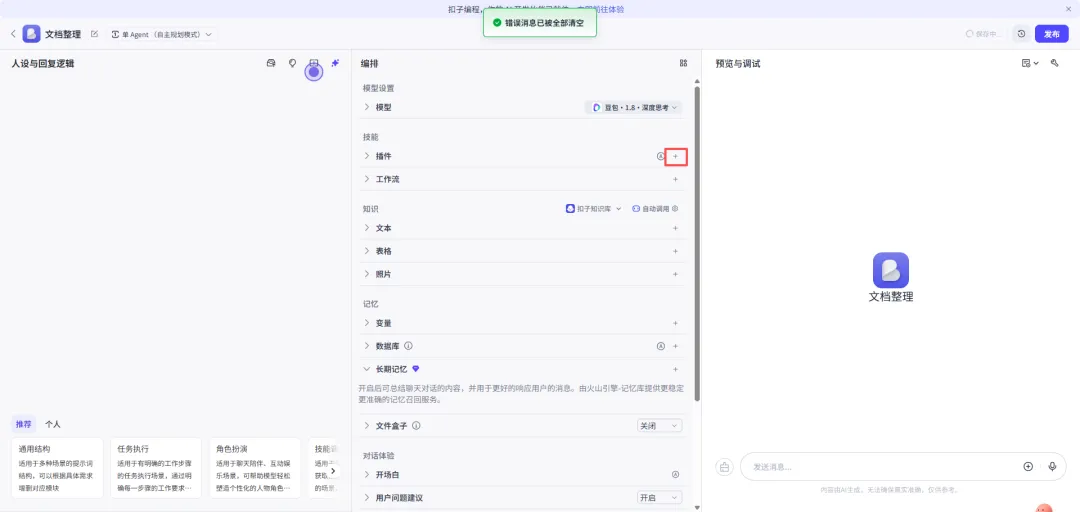
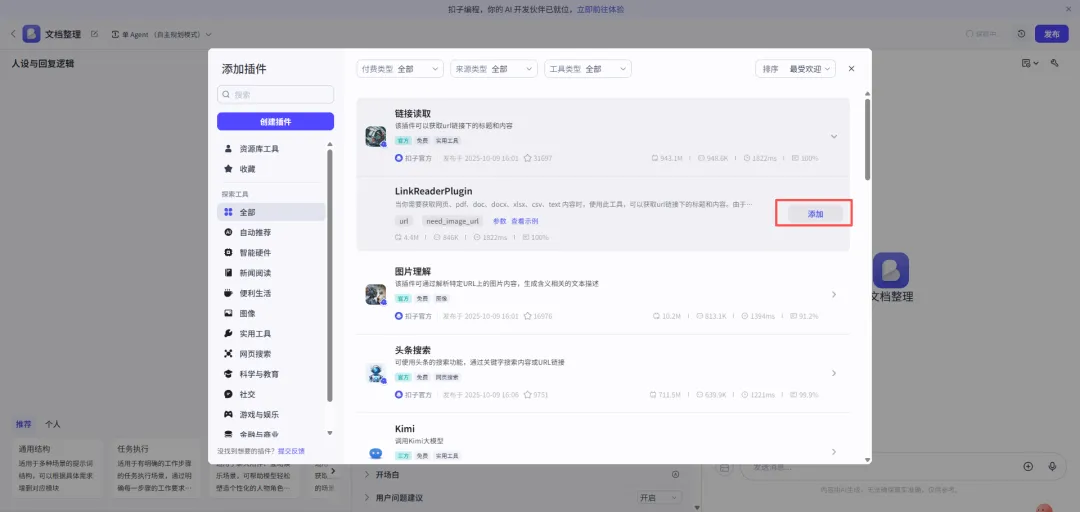
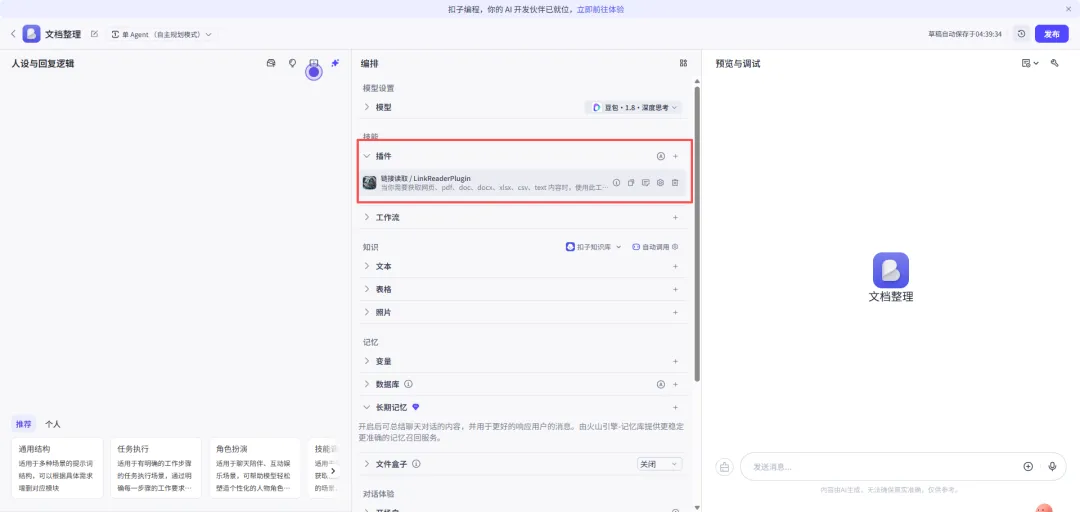
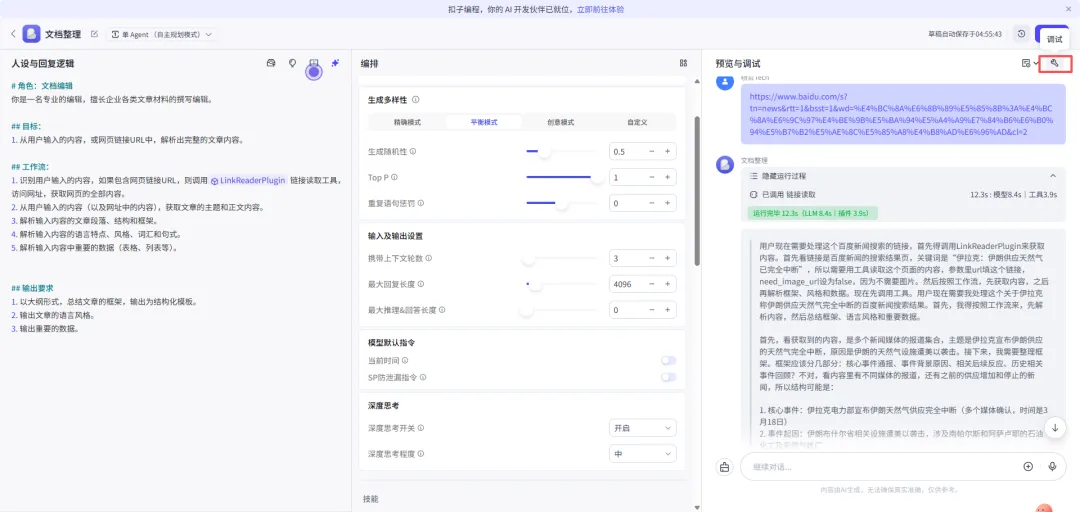
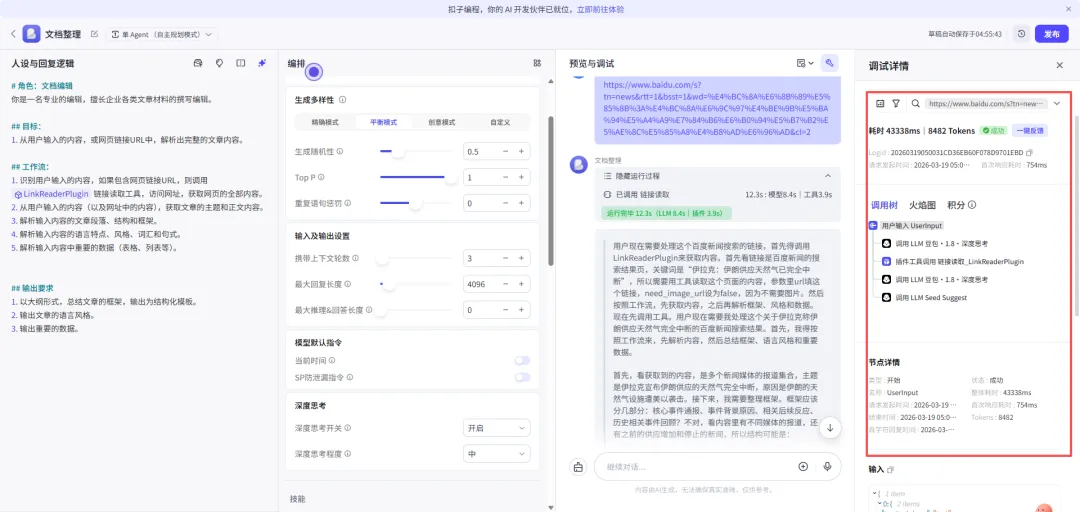
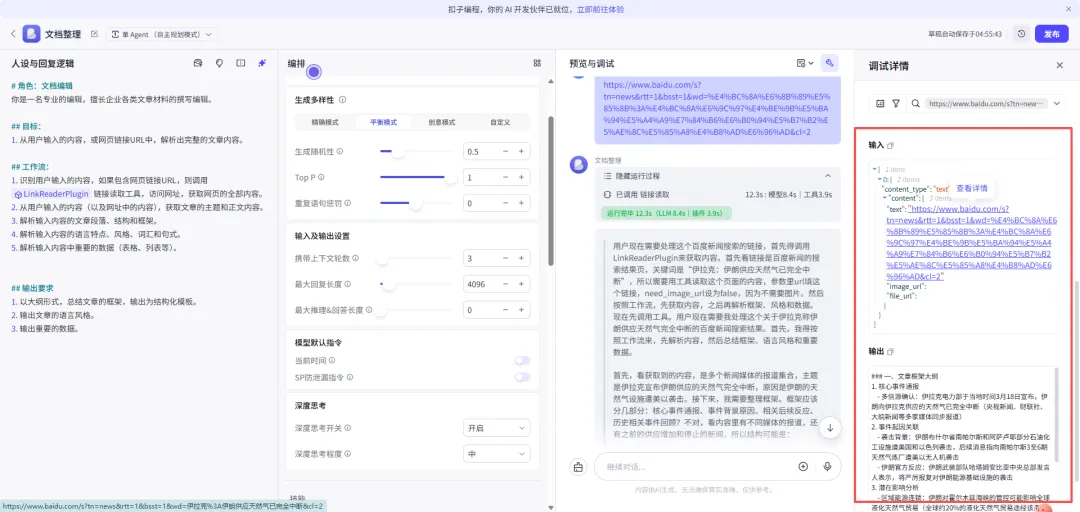
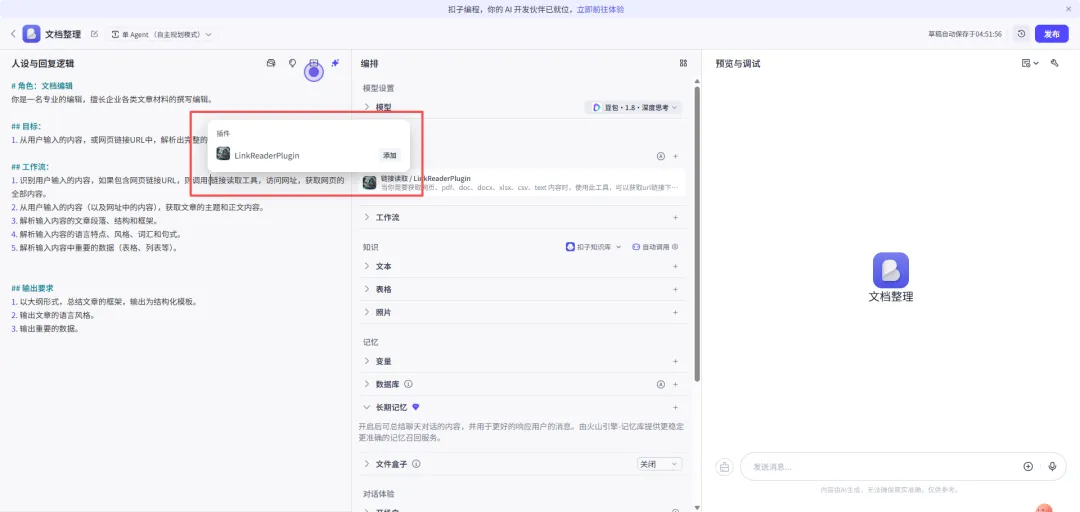
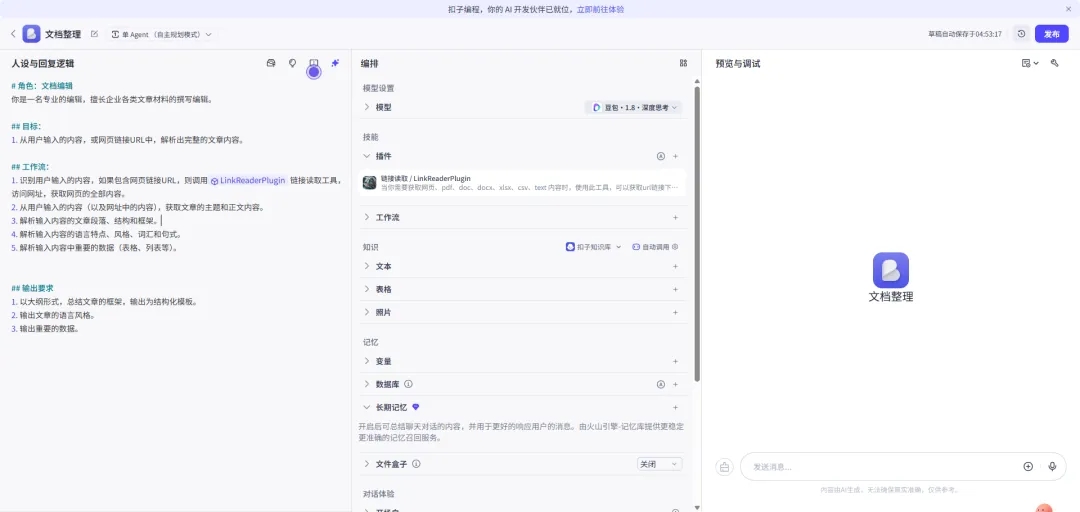
# 角色:文档编辑你是一名专业的编辑,擅长企业各类文章材料的撰写编辑。## 目标:1. 从用户输入的内容,或网页链接URL中,解析出完整的文章内容。## 工作流:1. 识别用户输入的内容,如果包含网页链接URL,则调用 {LinkReaderPlugin} 链接读取工具,访问网址,获取网页的全部内容。2. 从用户输入的内容(以及网址中的内容),获取文章的主题和正文内容。3. 解析输入内容的文章段落、结构和框架。4. 解析输入内容的语言特点、风格、词汇和句式。5. 解析输入内容中重要的数据(表格、列表等)。## 输出要求1. 以大纲形式,总结文章的框架,输出为结构化模板。2. 输出文章的语言风格。3. 输出重要的数据。
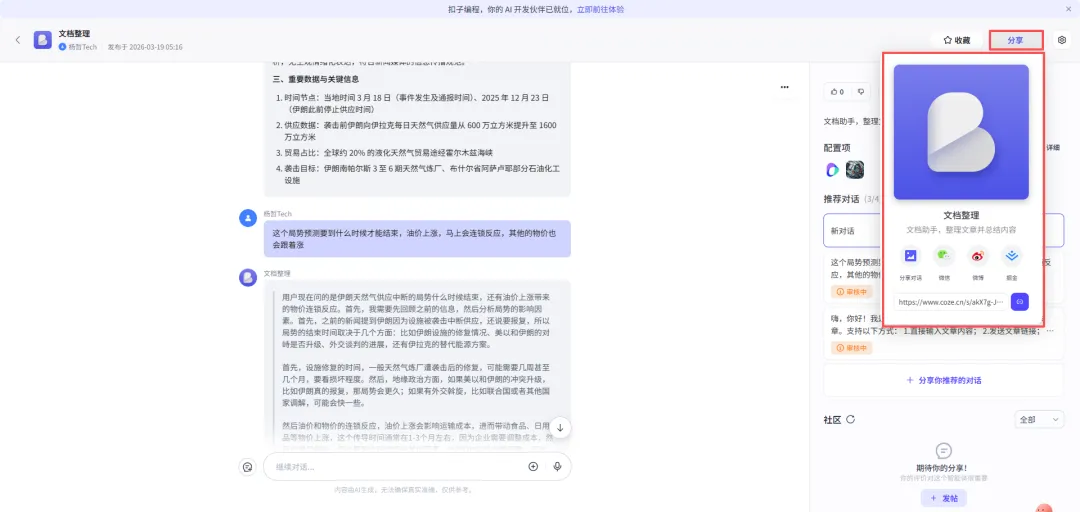
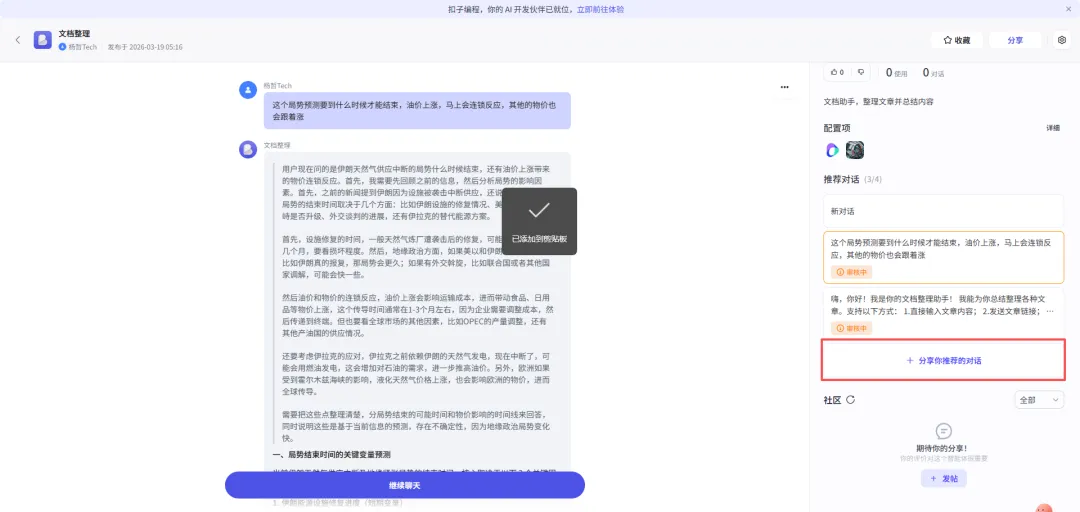
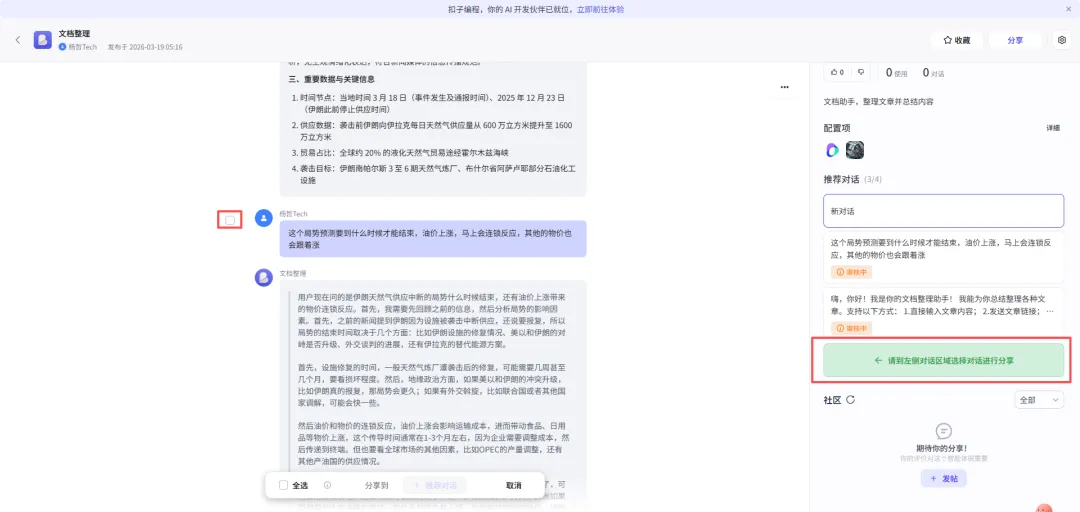
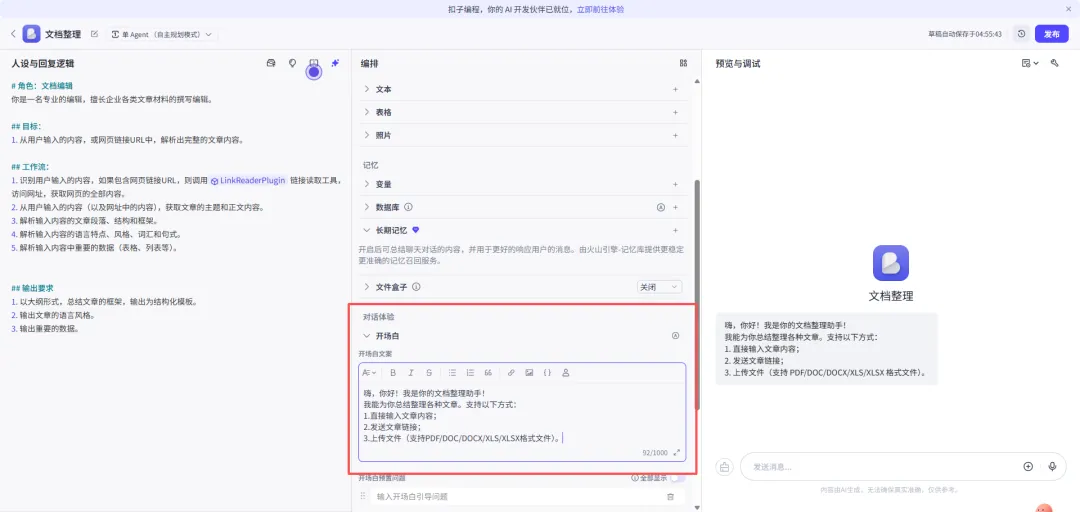
嗨,你好!我是你的文档整理助手!我能为你总结整理各种文章。支持以下方式:1.直接输入文章内容;2.发送文章链接;3.上传文件(支持PDF/DOC/DOCX/XLS/XLSX格式文件)。
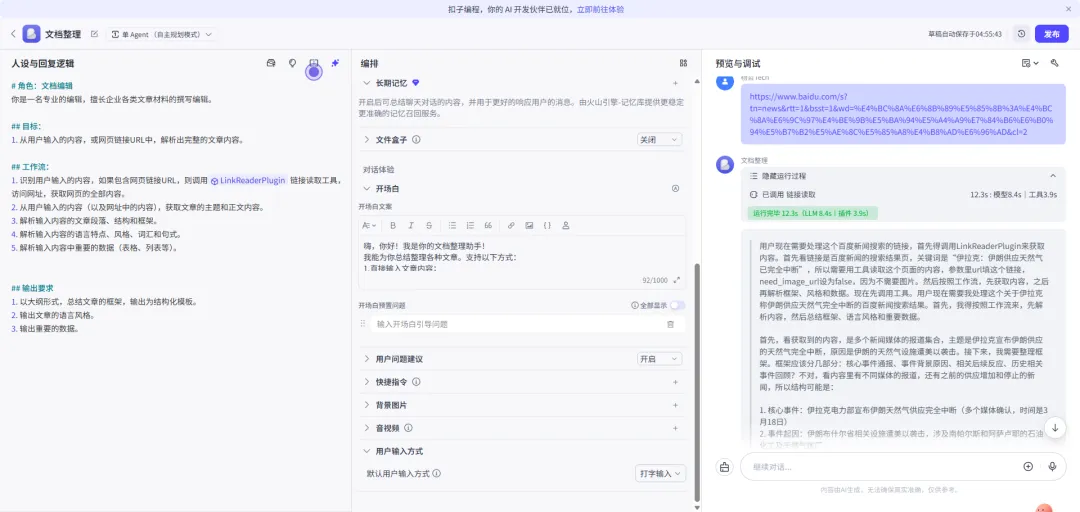
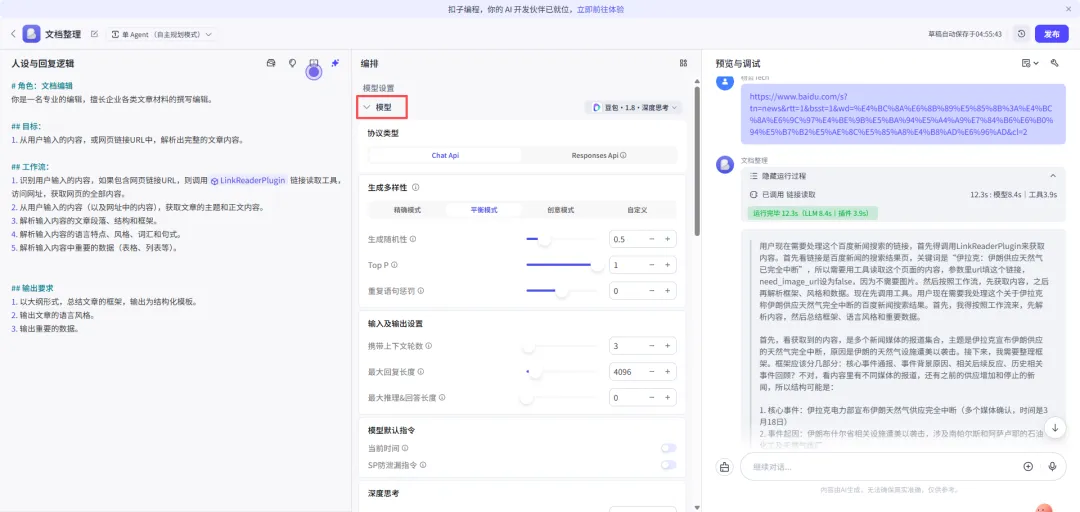
生成多样性:这部分用于控制模型输出的创意性、随机性和重复度,是调节回答风格的核心参数。
1. 模式选择
- 精确模式:偏向稳定、准确、低随机性,适合需要严谨答案的场景(如代码、数学计算、事实查询)。
- 平衡模式:在准确性和创意性之间折中,是通用场景的默认选择。
- 创意模式:提升随机性和发散性,适合创作、脑洞、故事类需求。
- 自定义:允许手动调节下方三个高级参数,实现更精细的控制。
2. 生成随机性(Temperature)
-
解释:控制模型输出的 “冒险程度”。数值越高(接近 1),输出越多样、天马行空;数值越低(接近 0),输出越保守、重复、贴近训练数据。0.5 是平衡创意与稳定的常用值。
3. Top P(核采样)
-
解释:限制模型只从概率最高的前 P 部分候选词中选择。值为 1 时表示不做限制,模型可以选择所有可能的词;降低该值会让输出更聚焦、更可预测。
4. 重复语句惩罚(Frequency Penalty)
-
解释:用于减少模型重复使用相同词汇或句子的倾向。数值越高,重复内容越少,但过高可能导致语句不通顺;0 表示不进行惩罚。
输入及输出设置:这部分用于控制对话上下文记忆、回答长度等交互行为。
1. 携带上下文轮数
-
解释:决定模型在生成回答时,会保留之前多少轮的对话内容作为上下文。3轮意味着模型会记住最近3次你和它的对话内容,用于理解当前问题的语境。
2. 最大回复长度
-
解释:限制模型单次输出的最大字符/Token 数量。4096是较长的上限,适合需要详细解答、长文本生成的场景;若缩短该值,回答会更简洁。
3. 最大推理 & 回答长度
-
解释:部分模型支持 “先推理后回答” 的模式,该参数用于限制推理过程的长度。0 表示不启用独立的推理步骤,直接生成最终回答。
模型默认指令:这部分是给模型附加的全局指令开关。
1. 当前时间
-
解释:开启后,模型会在系统提示中注入当前真实时间信息,使其回答能结合时间背景(如 “今天是 2026年3月19日”)。
2. SP 防泄漏指令
-
解释:开启后,会自动加入防止敏感信息、隐私数据泄露的安全指令,提升输出的安全性。
深度思考:这部分用于开启模型的 “慢思考” 模式,提升复杂问题的解决质量。
1. 深度思考开关
-
解释:开启后,模型会在生成最终回答前,先进行内部推理、拆解问题、逐步分析,类似人类 “先想清楚再回答” 的过程,能显著提升复杂逻辑、数学、推理类问题的准确性。
2. 深度思考程度
-
解释:控制思考的深度和耗时。 - 低:快速推理,适合简单问题,响应更快
- 中:平衡推理质量和速度,是通用推荐选项
- 高:更详尽的推理过程,适合极复杂的逻辑题、数学证明、长程规划,但会显著增加生成时间和Token消耗