 夜雨聆风
夜雨聆风





OpenRAG 下一代智能文档搜索与问答平台

OpenRAG
在AI浪潮下,如何让企业或个人快速建立属于自己的智能知识库,一直是信息管理的核心问题。传统搜索系统受限于关键字匹配,而大语言模型(LLM)的出现又让语义搜索与知识问答成为可能。今天要介绍的开源项目——OpenRAG,正是将这一理念推向极致的综合平台。
OpenRAG 是一个基于 Langflow、Docling 和 OpenSearch 构建的开源 Retrieval-Augmented Generation(RAG,检索增强生成) 平台。它将文档管理、智能检索与AI对话无缝结合,让你可以将任意文档转化为可问答的“智能知识助手”。
🔍 什么是 OpenRAG?
简单来说,OpenRAG = 文档搜索引擎 + 大语言模型 + 智能对话系统。
用户可以在一个交互式界面中:
-
上传自己的资料(比如PDF、网页、Word文档等); -
系统自动解析内容,建立语义检索索引; -
之后,你就可以像与ChatGPT聊天一样,通过提问来搜索内部知识。
平台亮点功能 ✨
-
即装即用的全功能套件OpenRAG已经将所有核心工具预配置好,安装后即可运行,无需繁琐配置。
-
Agent智能RAG工作流内置的多智能体协调机制支持重新排序结果、动态选择检索路径,让系统更“聪明”。
-
多格式文档处理无论是杂乱的企业文档、扫描件还是网页数据,OpenRAG都能通过Docling进行智能解析与提取。
-
可视化工作流构建借助Langflow的拖拽式界面,用户可以快速定制自己的AI问答流。
-
企业级扩展性体系基于OpenSearch设计,可轻松扩展至大规模数据应用,满足企业生产环境需求。
🔄 工作原理解析
OpenRAG的核心工作逻辑可以概括为三个阶段:

-
文档导入(Ingestion):使用Langflow与Docling解析不同格式的数据; -
向量化与索引(Indexing):通过OpenSearch进行语义索引建立; -
检索增强生成(RAG):检索到的相关文档被传递至语言模型,由模型生成自然语言回答。
这一流程让OpenRAG能够结合检索的准确性与LLM的语言灵活性,从而在知识问答场景中表现出色。
🚀 快速上手指南
官方提供了详细的安装方式与启动流程:
-
[Quickstart快速入门] (https://docs.openr.ag/quickstart) -
[Python安装包说明] (https://docs.openr.ag/install-options) -
[Docker/Podman自部署指南] (https://docs.openr.ag/docker)
启动流程图
 1. 启动 OpenRAG
1. 启动 OpenRAG
↓
 2. 添加知识文件
2. 添加知识文件
↓
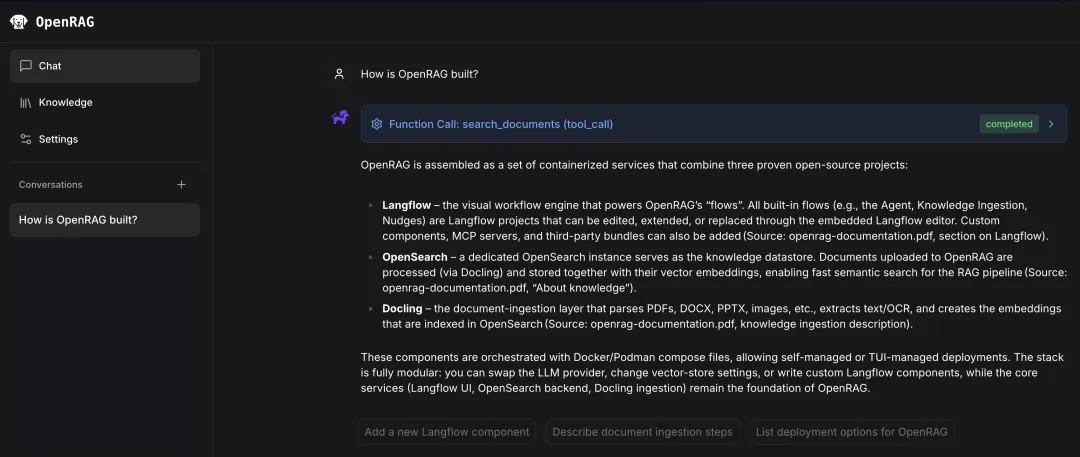 3. 开始智能问答
3. 开始智能问答
短短几步,你就能拥有一个针对私有数据的“企业版ChatGPT”。
💻 官方 SDK 支持
OpenRAG 不仅可以独立运行,还能通过SDK集成至你的应用中。
🐍 Python SDK
pip install openrag-sdk快速示例:
import asynciofrom openrag_sdk import OpenRAGClientasyncdefmain():asyncwith OpenRAGClient() as client: response = await client.chat.create(message="What is RAG?") print(response.response)if __name__ == "__main__": asyncio.run(main())🧩 TypeScript / JavaScript SDK
npm install openrag-sdk快速示例:
import { OpenRAGClient } from"openrag-sdk";const client = new OpenRAGClient();const response = await client.chat.create({ message: "What is RAG?" });console.log(response.response);🔌 Model Context Protocol (MCP)
OpenRAG还支持Model Context Protocol (MCP),可直接与 AI 助手(例如 Cursor 或 Claude Desktop)连接,让你的知识库可被多模型使用。
pip install openrag-mcp配置示例(以Cursor或Claude Desktop为例):
{"mcpServers": {"openrag": {"command": "uvx","args": ["openrag-mcp"],"env": {"OPENRAG_URL": "http://localhost:3000","OPENRAG_API_KEY": "your_api_key_here" } } }}这一模块提供了包括RAG聊天、语义检索与偏好设置管理等功能。
🧠 应用场景
-
企业内部知识管理:将企业手册、文档系统整合为AI助理; -
科研项目知识问答:用科研论文快速生成答案; -
法律/教育行业:让案例文档、教材内容可被语义搜索; -
开发者API集成:为自有产品添加“智能问答层”。
OpenRAG的模块化架构和Langflow兼容性,使得无论是个人开发者还是企业团队,都可以快速搭建属于自己的RAG系统。
🧰 技术栈与架构优势
OpenRAG 架构基于 FastAPI + Next.js,前后端分离,性能高且易扩展。其核心依赖:
-
Langflow:提供可交互的AI工作流构建; -
Docling:智能文档解析; -
OpenSearch:开源搜索引擎,支持大规模检索。
三者的组合让OpenRAG既具创新性又具实用性,完美平衡了AI与传统信息检索的优点。
💡 同类项目推荐
在RAG领域中,除了OpenRAG,还有一些值得关注的类似项目:
-
LlamaIndex专注于通过文档索引与LLM结合,为开发者提供灵活的RAG工具库,适合Python生态。
-
Haystack(deepset.ai)功能全面的开源RAG框架,拥有丰富的组件生态,可搭建定制化问答系统。
-
LangChain + Chroma更偏向组件式开发,适合灵活集成与轻量实验。
与这些相比,OpenRAG的突出优势在于“开箱即用”和“可视化工作流”,让RAG不再是复杂的代码堆叠,而是直观高效的智能平台。
OpenRAG代表了RAG系统的工程化落地方向:即让AI真正理解并应用你的知识。它让每位开发者都能轻松拥有一个“基于自己知识的ChatGPT”,这正是AI赋能知识管理的未来。
参考地址:
-
• https://github.com/langflow-ai/openrag
