 夜雨聆风
夜雨聆风





省80%Token!用这个神器给 Claude Code 装上超级记忆大脑
今日分享Claude Code辅助神器
日常用Claude Code写代码,最怕遇到会话中断的情况——前一天刚讲清的项目结构、踩过的坑,第二天重开窗口就全部归零,只能重复输入上下文,既耗Token又费时间。

claude-mem的出现刚好补上这个短板,这个3.6万星的开源项目,不是简单保存聊天记录,而是给Claude Code搭起一层跨会话的工作记忆,让模型能顺着上次的进度继续干活,还能大幅减少无效Token消耗。接下来就一步步讲清楚,怎么给Claude Code装上这个“超级记忆大脑”。
先搞懂:claude-mem到底是个啥?
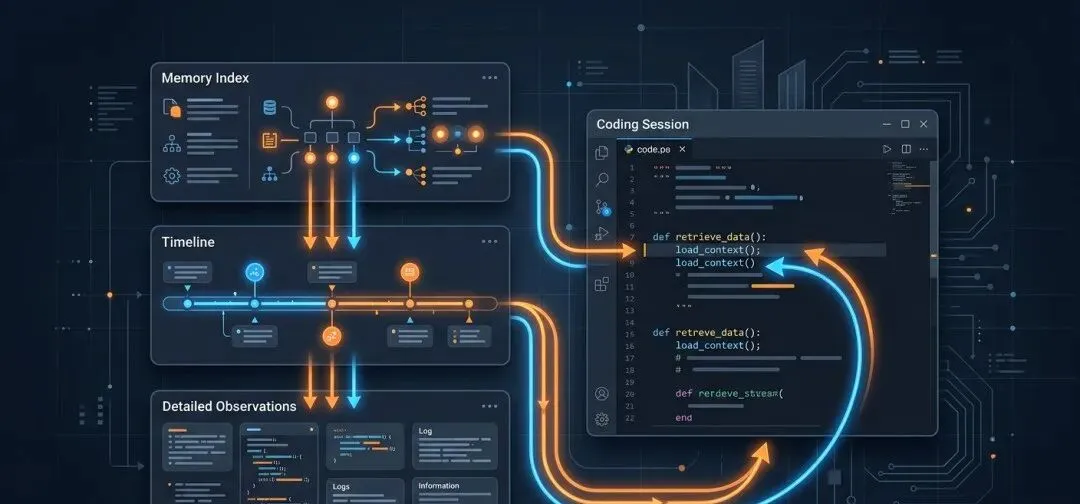
claude-mem不是传统的“聊天记录保存工具”,而是围绕AI编程工作流搭建的记忆基础设施,核心解决Claude Code原生缺乏长期上下文的痛点。它不会把整段旧对话塞回新会话,而是将历史操作、关键信息、阶段总结提炼成可检索的记忆索引,新会话中按需调取细节,从根源上减少Token的无效消耗。

整体架构分为四层,各司其职又相互配合,构成完整的记忆管理体系:
- hooks层:捕捉Claude Code生命周期关键动作,记录会话中的工具调用、指令提交等核心操作
- worker service层:本地常驻服务,默认运行在37777端口,负责整理信息、生成总结、提供查询接口
- 存储检索层:基础信息存入SQLite,开启Chroma后可实现语义检索,让记忆查找更精准
- retrieval层:按“索引→时间线→细节”的逻辑调取历史,而非无差别回放,最大化节省Token
●传统方式vsclaude-mem:Token消耗与工作效率对比
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
避坑安装:选对方式才管用
claude-mem的安装有明确的“正确姿势”,踩错步骤会导致功能无法正常使用,核心记住:优先从Claude Code插件市场安装,而非全局npm安装。
●主流安装方式(推荐新手)
直接在Claude Code内部操作,无需复杂命令行,步骤简单易上手:
-
打开Claude Code,进入插件市场板块 -
搜索“claude-mem”,点击安装并等待配置完成 -
安装成功后,本地会自动启动worker service常驻服务,无需手动操作 -
验证:查看本地37777端口是否处于运行状态,端口正常即安装成功 
●进阶安装方式(适合开发人员)
若需要自定义配置,可通过克隆仓库手动构建,步骤如下:
-
克隆仓库: -
git clone https://github.com/thedotmack/claude-mem.git -
进入目录并安装依赖: cd claude-mem && npm install -
构建项目: npm run build -
本地链接: npm link -
启动服务: claudemem --help查看命令并启动对应服务
●安装核心坑点提醒
-
全局npm安装( npm install -g claude-mem)仅能获取SDK,无法自动配置hooks和worker服务,新手不建议使用 -
安装后若无法启动,检查本地端口是否被占用,37777端口为默认端口,可在配置文件中修改 -
如需开启Chroma语义检索,需单独安装并配置Chroma环境,完成后在claude-mem配置中开启对应功能
基础使用:三步解锁超级记忆
claude-mem安装后会自动运行,无需繁琐的日常配置,核心使用流程分为三步,贴合日常AI编程的操作习惯:
●第一步:正常使用Claude Code,记忆自动记录
在Claude Code中进行写代码、查Bug、重构项目等操作时,claude-mem的hooks层会自动捕捉关键动作,将工具调用、指令提交、阶段结果等信息记录下来,实时生成observation和summary,无需手动触发记录功能。
●第二步:新会话启动,自动加载记忆索引
重开Claude Code会话或切换设备后,无需手动导入任何信息,claude-mem会自动将历史记忆的索引加载到新会话中,Claude Code会先读取索引,明确之前的工作进度和关键信息。
●第三步:按需调取细节,减少Token消耗
当需要用到历史细节时,可通过两种方式调取:
- MCP工具调取:在Claude Code中通过内置MCP工具,直接查询历史记忆的具体内容
- Web Viewer查看:在浏览器中打开本地记忆可视化页面,通过时间线、关键词检索找到需要的信息,按需复制到会话中,避免整段上下文的无效输入
●可视化记忆管理:Web Viewer使用技巧
claude-mem自带本地Web Viewer,可直观查看和管理记忆流,操作简单:
-
打开浏览器,输入本地地址(默认基于37777端口,具体地址见安装后提示) -
页面中可按时间线查看所有历史会话的记忆,支持关键词检索 -
可对记忆内容进行筛选、编辑,隐藏无用信息,让记忆索引更精简 -
支持将选定的记忆内容导出,方便在多设备间同步
功能亮点:不止省Token,更提开发效率
claude-mem能成为热门开源项目,核心在于它不仅解决了记忆问题,更贴合实际的AI编程工作流,多个功能亮点让开发过程更顺畅:
●1. 跨会话连续工作,告别重复讲解
这是最核心的功能,无论是隔天继续开发、中途切换设备,还是临时处理其他任务后回归,Claude Code都能通过claude-mem的记忆层,明确之前的项目结构、修改原因、踩过的坑,无需重复输入上下文,大幅节省时间和Token。

●2. 多工具集成,打造统一记忆层
claude-mem并非只适配Claude Code,还支持Cursor hooks集成、OpenClaw集成,能将AI agent的observation同步到MEMORY.md中。当在Claude Code写代码、Cursor中查看、OpenClaw中运行agent时,所有操作的记忆能统一管理,避免各工具记忆相互独立的问题。
●3. 多provider支持,灵活切换模型
在配置文件中可自由切换Claude、Gemini、OpenRouter等provider,无需为不同模型单独配置记忆功能,一套记忆体系适配多个大模型,提升工具使用的灵活性。
●4. 模式系统切换,适配不同开发场景
内置模式系统,可根据不同的工作模式和开发语言切换对应配置,让记忆管理更贴合具体的开发场景,比如写Python代码和写前端代码时,记忆的提炼和检索逻辑可按需调整。
●5. 本地持久化存储,数据更安全
所有记忆信息均实现本地持久化存储,主要存入SQLite数据库,无需将项目信息、代码内容上传到第三方服务器,避免代码和项目信息泄露,兼顾便利性和安全性。
适用场景:谁最适合用这个工具?
claude-mem虽好用,但并非所有使用Claude Code的场景都需要,贴合以下场景时,能发挥最大价值:
- 长期维护同一代码库:项目复杂度高、上下文信息多,跨会话的连续性需求强,能大幅减少重复工作
- 开发过程易被打断:经常出现“今天修一半Bug,明天继续”“白天写代码,晚上查原因”的情况,需要快速衔接工作进度
- 多工具协同开发:同时使用Claude Code、Cursor、OpenClaw等工具,需要统一的记忆层管理各工具的操作信息
若只是偶尔用Claude Code写一次性脚本,无需跨会话连续工作,使用claude-mem会显得冗余,无需安装。

这款神器的价值
claude-mem的核心价值,不在于让Claude Code“记住更多内容”,而在于让模型的记忆变得“有价值、可利用”。它通过“提炼索引-按需调取”的逻辑,在Token预算有限的前提下,实现了跨会话的工作连续性,让Claude Code从“单次对话的编程工具”,变成能持续推进项目的开发搭子。

对于日常将Claude Code作为主力开发工具的人员来说,按照上述步骤安装使用后,能明显感受到Token消耗的减少和开发效率的提升。当然,它并非完美的“傻瓜工具”,越接受它“先索引、再展开、按需读取”的思路,越能发挥其价值。

日领5500万Token!美团LongCat大模型继续免费薅|AI算力白嫖全攻略
识别财报、试卷、合同绝了!几大开源 OCR 超强工具,你值得拥有
开源免费,牛逼神器!一个人用Codebuddy+开源baoyu-skills玩赚自媒体!
搜索神器!效率提升100%,碾压系统自带工具,碾压Everything
眼花缭乱!国内阿里、腾讯、小米大厂小龙虾”Claw”一网打尽!小白该怎么选?
办公必备!Trae + 这些超强Skill组合!自动下载视频、分析数据、写报表PPT, 效率直接起飞!

