 夜雨聆风
夜雨聆风





这个开源 PDF 解析黑马项目,最近突然爆火了!
* 戳上方蓝字“开源先锋”关注我
大家好,我是开源君!
如果你做过 RAG(检索增强生成)或者大模型文档清洗,一定被 PDF 这种格式折磨过:多栏排版识别乱序、表格内容支离破碎、复杂的数学公式提取出来全是乱码。
尤其在企业场景中,大量PDF文档结构复杂、格式不统一,传统工具很难兼顾准确性与稳定性。
这两天在 Github 热榜上看到一个霸榜的项目 – opendataloader-pdf,似乎有点新的东西。
项目简介
opendataloader-pdf是一个面向 AI 应用的 PDF 解析工具,可以将 PDF 转换为结构化数据(Markdown、JSON、HTML),并支持复杂文档解析、OCR识别、表格提取、公式解析等能力。
与传统PDF工具不同,它不仅关注“能不能提取文本”,更关注“提取后的数据是否适合大模型使用”。
例如:
-
保留正确阅读顺序 -
输出语义结构(标题、段落、表格等) -
提供元素级坐标信息(Bounding Box) -
支持复杂布局(多列、论文、报告)
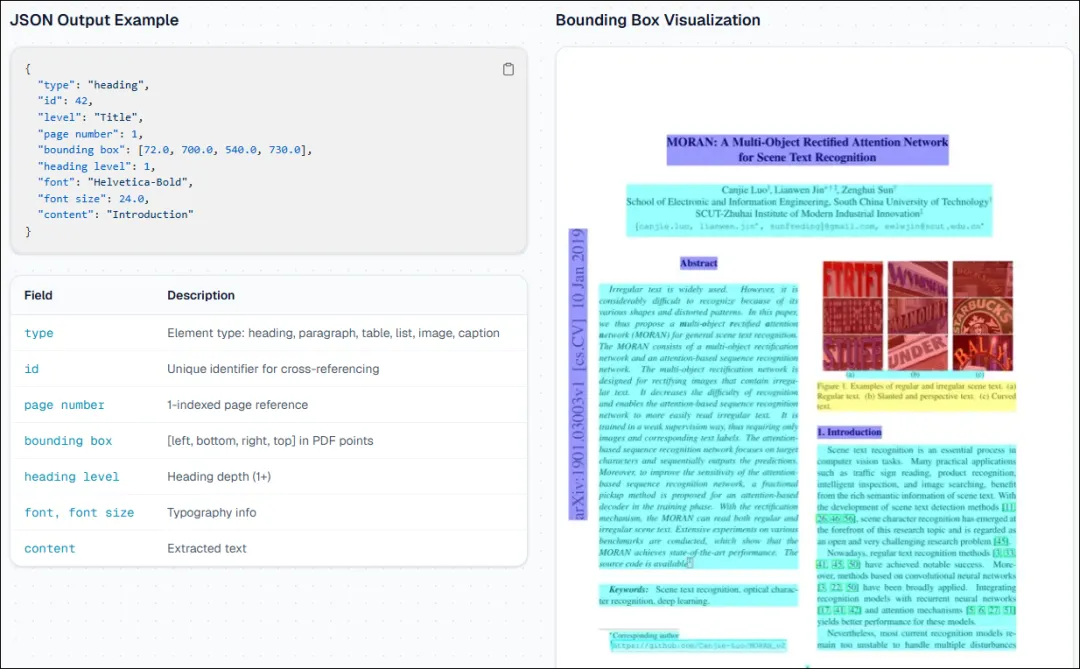
在官方基准测试中,其整体解析准确率达到0.90,排名第一,表格解析能力尤为突出。
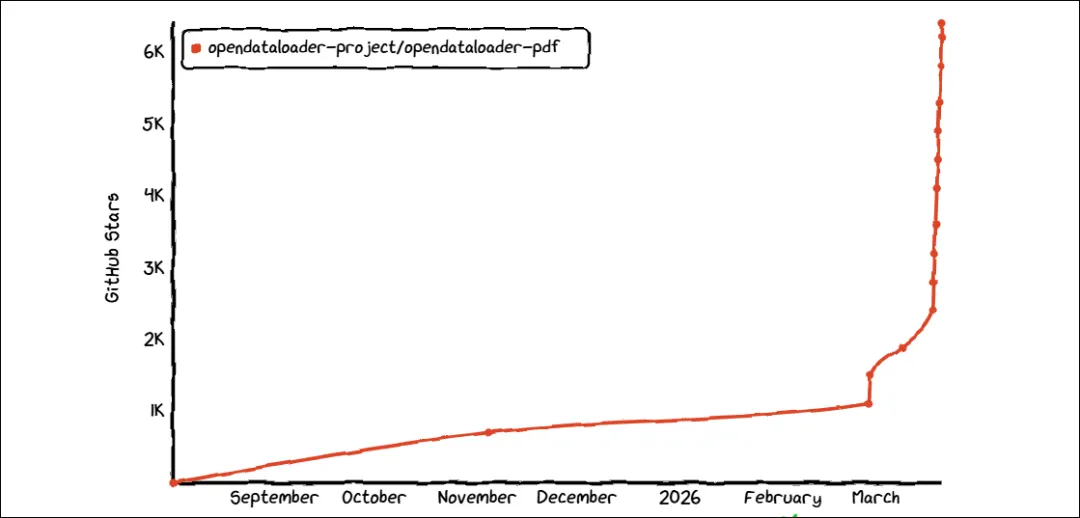
目前该项目在 GitHub 上已经获得 6.4k+ Star,最近社区关注度持续增长。
核心优势
在 PDF 解析界,大家熟悉的可能还有 docling、marker 或者 pymupdf4llm。
为了让大家看清 opendataloader-pdf 的独特优势,我们直接看下表:
|
|
|
|
|
|
|---|---|---|---|---|
| 综合准确率 | 0.90 (排名第1) |
|
|
|
| 表格准确率 | 0.93 |
|
|
|
| 全元素坐标 | 支持 (每个段落/表格都有BB) |
|
|
|
| 阅读顺序算法 | XY-Cut++ (极准) |
|
|
|
| AI 安全过滤 | 内置提示词注入防御 |
|
|
|
| 无障碍打标 | 支持自动化 Tagged PDF |
|
|
|
| 运行效率 | 0.05s/页 (本地模式) |
|
|
|
核心杀手锏:
-
RAG 溯源神器:它是市面上极少数能为每一个提取出的元素(标题、段落、图片、表格)都提供精确 Bounding Box(边界框坐标)的工具。这对于金融、法律场景是刚需。 -
混合动力引擎:它不迷信 AI。简单的页面用 Java 引擎秒级处理,遇到复杂的无线表格、公式或扫描件,才会启动 AI 模型(如 SmolVLM)进行增强。这种设计既保证了隐私和速度,又拿到了最高的准确度。
快速安装、使用
项目核心解析逻辑由 Java 驱动,请确保已安装 Java 11+。
1. 安装 Python 库
pip install -U opendataloader-pdf2. 极简代码转换示例
import opendataloader_pdf# 一行代码,批量转换opendataloader_pdf.convert( input_path=["report_2024.pdf", "research_papers/"], output_dir="output/", format="markdown,json"# 输出 Markdown 给 RAG,JSON 用于定位)3. 开启“满血”混合模式(复杂文档必用)
如果你需要解析没有边框的复杂表格或扫描图片:
# 安装增强包pip install -U "opendataloader-pdf[hybrid]"# 启动本地 AI 后端服务opendataloader-pdf-hybrid --port 5002# Python 调用时指定混合模式opendataloader_pdf.convert( input_path="complex_doc.pdf", output_dir="out/", hybrid="docling-fast")更多使用方式、参数设置可以到项目文档查看。
小结
如果你的需求只是简单提取文本,传统工具已经足够。
但如果你需要:高质量结构化数据、可溯源信息、复杂文档解析能力、可直接接入大模型, 那么opendataloader-pdf这个项目值得重点关注。
更多细节功能,感兴趣的可以到项目地址查看:
https://github.com/opendataloader-project/opendataloader-pdf