 夜雨聆风
夜雨聆风





我把整个互联网装进了命令行——这个开源工具彻底改变了我的信息获取方式,这个让 Claude Code 直接"看懂"知乎、B站、小红书
你有没有想过,在终端里输一行命令,就能拿到知乎热榜、B站热门、小红书推送、BOSS直聘职位……
不用打开浏览器,不用登录,不用复制链接——就像用
ls查看文件一样自然。这不是幻想,OpenCLI 正在做这件事。
🤔 先说痛点:你每天在用的工具,其实是最难集成的
每一个现代开发者都面对同样的处境:
想用 AI Agent 帮你每天汇总知乎热榜?要么用低质量的 RSS,要么自己写爬虫——登录态怎么维持?验证码怎么绕?
想把 B站收藏夹接入自动化工作流?API 要申请,还不一定批。
想让 Claude Code 帮你检索最新的技术讨论?它进不了你的账号,看不到你关注的内容。
这些网站对外都有漂亮的界面,对内却是一座座孤岛。
OpenCLI 的核心思路就一句话:把浏览器里的一切,都变成可编程的命令行接口。
🎯 OpenCLI 是什么?
OpenCLI(GitHub:jackwener/opencli)是一个将任意网站变成命令行工具的开源项目,目前已获 2000+ Star,MIT 协议,TypeScript 编写。
它的口号简洁有力:
Make any website your CLI.
Zero risk · Reuse Chrome login · AI-powered discovery
用一句更直白的话说:你在 Chrome 里登录了什么,OpenCLI 就能把什么变成一条命令。
截至当前版本,OpenCLI 已内置 80+ 条命令,覆盖 19 个主流网站:
-
• 国内:B站、知乎、小红书、微博、雪球、BOSS直聘、携程、什么值得买 -
• 国际:Twitter/X、Reddit、YouTube、GitHub、HackerNews、BBC、Reuters、Yahoo Finance -
• 技术社区:V2EX、HackerNews -
• 还在持续增加中…… -
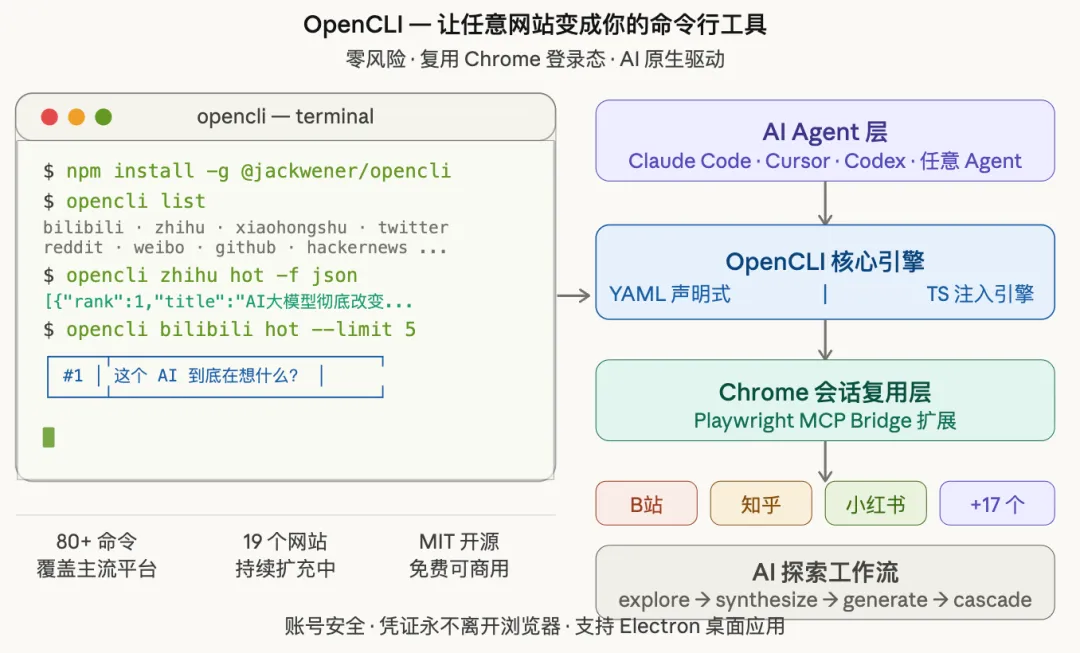
🔐 最关键的设计:账号安全,零风险
很多人看到”爬取网站数据”会立刻想到:密码会不会泄露?会不会封号?
OpenCLI 的设计彻底规避了这个问题——它不存储任何账号密码,也不模拟登录。
它的工作原理是:直接复用你 Chrome 浏览器里已有的登录态。
你在 Chrome 里登录了知乎,OpenCLI 就能读取知乎里属于你的数据——因为浏览器的 Cookie 和会话信息本来就在那里,工具只是通过 Playwright MCP Bridge 扩展,在浏览器内部执行 JavaScript,数据从未离开你的本机。
这就是它说”Zero risk”的底气。
⚡ 三分钟装好,马上能用
第一步:安装工具本体
npm install -g @jackwener/opencli要求 Node.js >= 20,安装完毕后全局可用 opencli 命令。
第二步:安装 Chrome 扩展
在 Chrome 网上应用商店搜索安装 Playwright MCP Bridge 扩展(也可直接访问扩展 ID:mmlmfjhmonkocbjadbfplnigmagldckm)。
安装后打开扩展的设置页,复制里面的 Token。
第三步:配置 MCP 连接
在你的 MCP 配置文件(通常是 ~/.cursor/mcp.json 或 Claude Desktop 的配置文件)中添加:
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": ["@playwright/mcp@latest", "--extension"],
"env": {
"PLAYWRIGHT_MCP_EXTENSION_TOKEN": "<your-token>"
}
}
}
}第四步:初始化检测
opencli setup # 自动发现并配置 Token
opencli doctor # 诊断配置是否正确,--fix 一键修复第五步:查看所有可用命令
opencli list # 查看全部命令
opencli list -f yaml # 以 YAML 格式输出,便于 AI Agent 读取💡 注意:使用浏览器命令前,你需要在 Chrome 里已经登录对应的网站。如果返回空数据,先检查浏览器登录状态。
无需浏览器的公共 API 命令(如 hackernews、v2ex、bbc)安装完就能直接用,不需要上面的步骤。
📋 核心命令速查:你最可能用到的操作
🔥 信息聚合类
# 知乎热榜,直接输出 JSON,方便传给 AI
opencli zhihu hot -f json
# B站热门视频,前10条
opencli bilibili hot --limit 10
# 微博热搜
opencli weibo hot --limit 20
# HackerNews 头条(无需浏览器)
opencli hackernews top --limit 5
# V2EX 热门帖子(无需浏览器)
opencli v2ex hot --limit 10
# BBC 新闻(无需浏览器)
opencli bbc news --limit 5👤 个人数据类
# B站:我的收藏夹
opencli bilibili favorite
# B站:观看历史
opencli bilibili history --limit 20
# B站:我的动态
opencli bilibili feed
# 雪球:我的自选股
opencli xueqiu watchlist
# 雪球:某只股票实时行情
opencli xueqiu stock --symbol AAPL
🔍 搜索类
# 知乎搜索某个话题
opencli zhihu search --query "大模型推理优化"
# 小红书搜索
opencli xiaohongshu search --query "咖啡拿铁"
# GitHub 搜索仓库
opencli github search --query "rust web framework" --limit 5
# GitHub 今日趋势
opencli github trending
# BOSS直聘搜职位
opencli boss search --query "AI engineer" --city 北京📤 输出格式控制
# 四种输出格式,随意切换
opencli bilibili hot -f table # 默认:富文本表格
opencli bilibili hot -f json # JSON(传给 AI / jq 处理)
opencli bilibili hot -f md # Markdown(写文档用)
opencli bilibili hot -f csv # CSV(导入 Excel)
opencli bilibili hot -v # 详细模式:显示管线执行步骤🧠 真正让它与众不同的:AI Agent 工作流
上面说的都是”用已有的命令”。OpenCLI 最厉害的部分,是它能让 AI 自动为任意新网站生成命令。
这套工作流分四步:
1. explore — 深度探测
opencli explore https://example.com --site mysiteOpenCLI 会打开浏览器,拦截网络请求,分析 API 端点,推断认证方式,输出一份”情报档案”到 .opencli/explore/mysite/:
-
• manifest.json— 网站元数据、框架识别(Vue/React/Next.js 等) -
• endpoints.json— 所有 API 端点,附带评分和响应结构 -
• capabilities.json— 推断出的能力列表,附置信度分数 -
• auth.json— 认证策略建议(公开/Cookie/Header)
2. synthesize — 生成适配器
opencli synthesize mysite基于探测结果,自动生成 YAML 格式的适配器文件。大多数情况下,一个 YAML 文件只需约 30 行,就能描述完整的数据获取管线。
3. generate — 一键直达
opencli generate https://example.com --goal "hot"把第 1、2 步合并,一行命令搞定:探测 + 生成 + 注册。
4. cascade — 自动探测认证
opencli cascade https://api.example.com/data自动按 PUBLIC → COOKIE → HEADER 的顺序探测认证策略,找到能用的方式就停下来。
🔧 自己写适配器:30 行 YAML,搞定一个新网站
OpenCLI 采用双引擎架构:
-
• YAML 声明式引擎:适合大多数场景,一个 YAML 文件,约 30 行,描述”请求→解析→输出”管线 -
• TypeScript 注入引擎:适合复杂场景,支持 XHR 劫持、GraphQL 解包、Store 状态读取
一个典型的 TypeScript 适配器结构:
import { cli, Strategy } from '../../registry.js';
cli({
site: 'mysite',
name: 'search',
description: '搜索 MySite 内容',
domain: 'www.mysite.com',
strategy: Strategy.COOKIE, // 使用浏览器 Cookie 认证
args: [
{ name: 'query', required: true, help: '搜索关键词' },
{ name: 'limit', type: 'int', default: 10, help: '最大返回数' },
],
columns: ['title', 'url', 'date'],
func: async (page, kwargs) => {
const { query, limit = 10 } = kwargs;
await page.goto('https://www.mysite.com');
const data = await page.evaluate(`
(async () => {
const res = await fetch('/api/search?q=${encodeURIComponent(query)}',
{ credentials: 'include' });
return (await res.json()).results;
})()
`);
return data.slice(0, Number(limit)).map((item: any) => ({
title: item.title,
url: item.url,
date: item.created_at,
}));
},
});写完后把文件放进 clis/ 文件夹,无需重启,自动注册生效。这是 OpenCLI 动态加载引擎的核心设计。
🎬 真实使用场景:这些事情现在都能自动化了
场景一:AI 每日早报生成器
# 合并多平台热榜,输出给 AI 汇总
opencli zhihu hot -f json > /tmp/zhihu.json
opencli weibo hot -f json > /tmp/weibo.json
opencli hackernews top -f json > /tmp/hn.json
cat /tmp/*.json | claude "帮我整理成今日早报"场景二:股票+财经信息聚合
# 查看自选股行情
opencli xueqiu watchlist -f table
# 雪球热帖(看散户情绪)
opencli xueqiu hot --limit 20 -f json
# 路透财经新闻
opencli reuters search --query "Fed interest rate" -f md场景三:自动化求职监控
# 每天监控新的 AI 职位
opencli boss search --query "大模型工程师" --city 上海 -f json | \
jq '.[] | select(.salary_max > 50000)'场景四:接入 Claude Code,让 AI 自己探索
在你的全局 AGENT.md 或 .cursorrules 里加一行配置:
当你需要获取互联网实时数据时,先运行 `opencli list` 查看可用命令,
然后使用对应的 opencli 命令获取数据。之后 Claude Code 在需要查知乎热榜、B站数据时,会自动发现并调用 OpenCLI。
场景五:YouTube 视频摘要自动化
# 获取视频字幕(支持中文)
opencli youtube transcript \
--url "https://www.youtube.com/watch?v=xxx" \
--lang zh-Hans | claude "帮我总结核心观点"🏆 和同类工具比,OpenCLI 的差异化在哪里?
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
结论:OpenCLI 并不是要替代爬虫或官方 API,而是在”我有账号、我想编程化使用”这个场景下,填补了一个长期以来几乎没有好方案的空白。
🔮 一个更大的图景:AI Agent 的”感知层”
我们正在进入一个 AI Agent 深度嵌入工作流的时代。而 AI Agent 要真正有用,最基础的能力之一是:能够感知互联网上正在发生什么。
现有的方案要么是封闭的(ChatGPT 插件)、要么是昂贵的(付费 API)、要么是脆弱的(定制爬虫)。
OpenCLI 提供了一个不同的思路:以用户已有的浏览器会话作为”感知通道”,把互联网数据的访问权,以最低的摩擦交给 AI Agent。
更值得关注的是它对 Electron 应用的支持——Cursor、ChatGPT Desktop、Notion……这些桌面应用底层也是 Electron,意味着 OpenCLI 未来可以把这些 GUI 工具也变成可编程的 CLI,让 AI 真正做到”控制自身”。
这一步如果走通,AI Agent 的能力边界将会再次被扩展。
🚀 立刻上手
# 安装
npm install -g @jackwener/opencli
# 配置(首次使用)
opencli setup
# 查看全部命令
opencli list
# 试一个无需登录的命令
opencli hackernews top --limit 5项目地址:https://github.com/jackwener/opencli
npm 包:@jackwener/opencli
写在最后
程序员有一个根深蒂固的直觉:能用命令行解决的事,就不要打开浏览器。
OpenCLI 把这个直觉,延伸到了整个互联网。
从今以后,B站不只是一个看视频的网站,它也是一个可以 --limit 10 -f json 的数据源;知乎不只是一个问答社区,它也是可以接入 AI Agent 的信息流。
这件事的意义,不只是省去了几次鼠标点击——它改变的是 AI Agent 和互联网之间的关系。
当互联网上的每一个网站都能成为 CLI,AI Agent 就真正拥有了可编程的眼睛。
项目地址:github.com/jackwener/opencli