 夜雨聆风
夜雨聆风





AGENTS.md到底是神器还是坑?
最近是不是特别火“给AI Agent塞一个AGENTS.md文件”?这也是渐进式披露的重要一环。 很多Agent框架(Claude Code、Cursor、Aider、SWE-agent等)都强烈建议你在仓库根目录放一个AGENTS.md,告诉Agent“这个项目该怎么干、不能干啥、用什么工具”。
现在大家都疯狂给Coding Agent塞AGENTS.md,有人手写、有人让LLM生成。迄今为止,尽管上下文文件(Context files)被广泛采用,但它对AI编码智能体解决复杂软件工程任务的能力的影响(即我们所写的AGENTS.md到底起不起作用?起了多大作用?)尚未得到严格研究,也没人认真验证过它到底有没有用!还好,上个月,Anthropic之外的顶尖研究团队(ETH Zürich + 某神秘公司)直接干了一件大事:他们用真实Github中的代码仓库 + 真实Issues,把这个“技能手册”狠狠评估测验了一把!具体研究内容发布在论文《Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?》中。最后的结果有些出人意料,咱们就一起从头来看看吧!
概述
随着编码智能体被更广泛地采用,人们普遍需要为智能体提供有关新颖和鲜为人知的代码库的额外上下文。为了解决这个问题,模型和智能体开发人员建议在代码库中包含上下文文件,如AGENTS.md或CLAUDE.md。许多智能体工具提供内置命令,使用编码智能体本身自动初始化此类上下文文件,例如,通过在智能体接口中提供专用/init命令。在撰写本文时,AGENTS.md报告称,超过60000个公共GitHub存储库包含一个上下文文件。
由Jimenez等人牵头的存储库级评估,在现实世界存储库级任务的自主解决方面评估编码智能体,迅速成为评估其能力的黄金标准。虽然最初的工作侧重于问题解决,但后续工作提出了关于特征添加、单元测试生成、功能生成、代码性能和安全性的基准。工作评估了主动使用上下文文件是否会提高自主问题解决和功能添加能力。
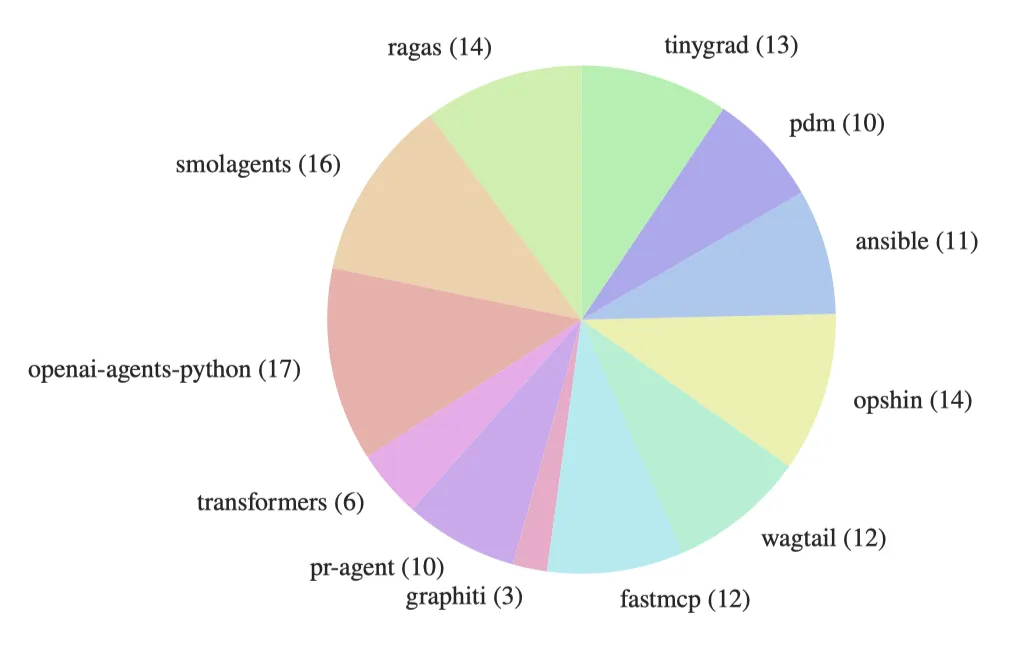
图:AGENT BENCH实例分布在12个开源GitHub存储库中,每个存储库都包含上下文文件
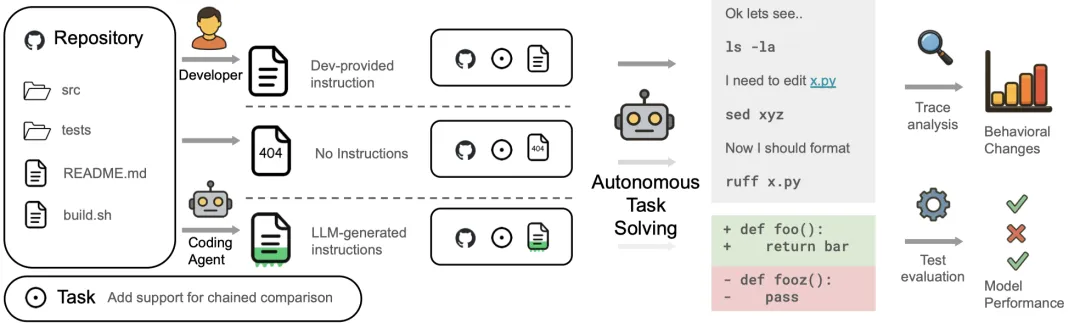
介绍下这次使用的评估管道:从现实世界的Github存储库和从过去的拉取请求中派生的任务开始。对于每个存储库状态,生成三个设置:1) 如果存在开发人员提供的上下文文件(开发人员生成的AGENT.md文件),会将其包含在存储库中。2) 省略了上下文文件(没有AGENT.md文件)。3) 使用编码智能体的推荐设置来生成上下文文件(LLM生成的AGENT.md文件)。然后,将存储库和上下文文件传递给编码智能体,并指示它自主解决任务。最后,分析行为变化的痕迹,并应用生成的补丁来检查任务解决是否成功。
令人惊讶的是,评测实验中观察到,与完全省略相比,开发人员提供的文件仅略微提高了性能(平均提高了4%),而LLM生成的上下文文件对智能体性能有轻微的负面影响(平均降低了3%)。这些观察结果在用于生成上下文文件的不同LLM和提示中都是稳健的。在更详细的分析中,观察到上下文文件导致编码智能体的探索、测试和推理增加,因此成本增加了20%以上。因此,建议暂时省略LLM生成的上下文文件,这与智能体开发人员的建议相反,只包括最低要求(例如,与此存储库一起使用的特定工具)。
这次研究以及评测实验的主要贡献:
-
1. AGENT BENCH,也是研究团队最大的贡献之一,创建了一个新的评估基准,用于评估积极使用的上下文文件对智能体解决现实世界软件工程任务能力的影响。
-
2. 对AGENT BENCH和SWEBENCH LITE上的不同编码智能体和底层模型进行了广泛评估,结果表明,LLM生成的上下文文件往往会降低智能体性能,而开发人员编写的上下文文件则往往会略微提高智能体性能。
-
3. 对智能体跟踪的详细调查,表明上下文文件导致编码智能体进行更彻底的测试和探索。
实验评估结果
在SWE-benchLite和自建的AGENTBENCH上,对比了三种设置(1.无上下文2. LLM生成AGENTS.md和3.开发者手写AGENTS.md),如下是4个方面的主要结果和发现:
-
1. LLM生成的上下文文件会增加成本并降低性能
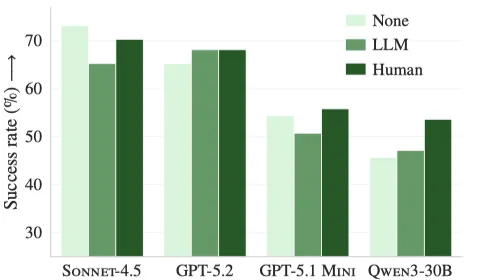
LLM生成的上下文文件会导致SWE-BENCH LITE和AGENT BENCH的8个设置中有5个设置的性能下降(见下图)。
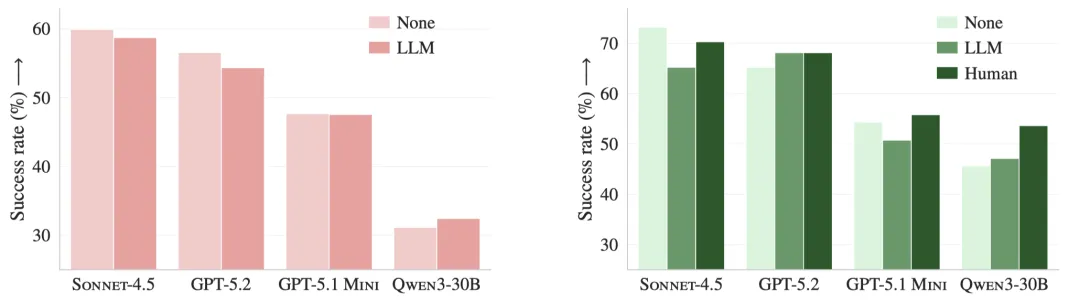
图:SWE-BENCH LITE(左)和AGENTBENCH(右)上,4种不同模型的解决率,包括无上下文文件(None)、LLM生成的上下文文件(LLM)和开发人员编写的上下文文件(Human)
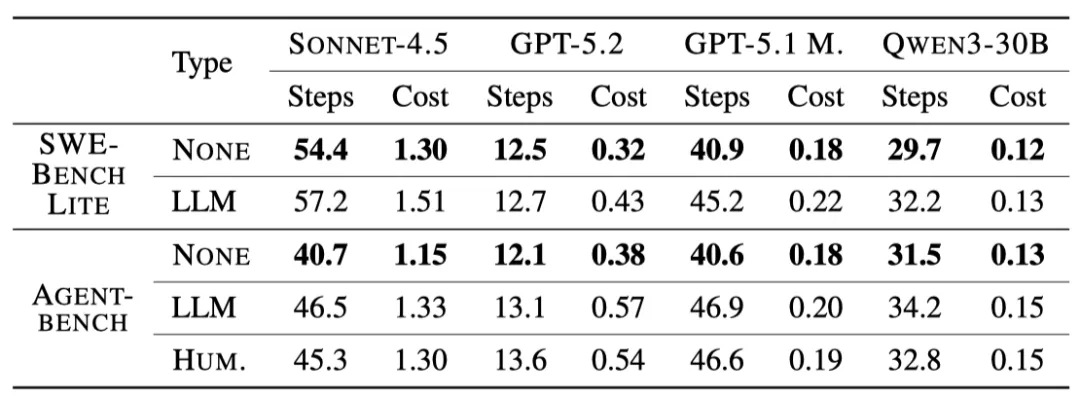
更详细地说,SWE-BENCH LITE和AGENT BENCH的平均解决率分别降低了0.5%和2%。同时,上下文文件分别将每个设置中的#步平均增加2.45和3.92步,这分别导致成本平均增加20%和23%(见下表)。
-
2. 开发人员编写的上下文文件增加了成本和性能
尽管不是特定于智能体的,但开发人员提供的上下文文件在所有四个智能体中(这4个编码智能体分别为:Claude Code with Sonnet-4.5,Codex with GPT-5.2,Codex with GPT-5.1MINI,Qwen Code with Qwen3-30B-Coder)都优于LLM生成的上下文文件,并且与除CLAUDE CODE之外的所有智能体的无上下文文件相比,性能都有所提高(见下图)。然而,开发人员提供的上下文文件也增加了解决任务所需的平均步骤数和成本,平均分别增加了3.34个步骤,最多增加了19%。
-
3. 上下文文件不能提供有效的概述
上下文文件没有帮助Agent更快找到关键修复文件(甚至让GPT-5.1 mini多次重复读取已有的上下文文件)。虽然大部分生成文件都包含“仓库概览-Codebase overview即AGENTS.md”,但实际并未缩短发现相关文件的步骤。得出结论是:上下文文件,即使是开发人员提供的文件,在提供存储库概述方面也不是有效的。
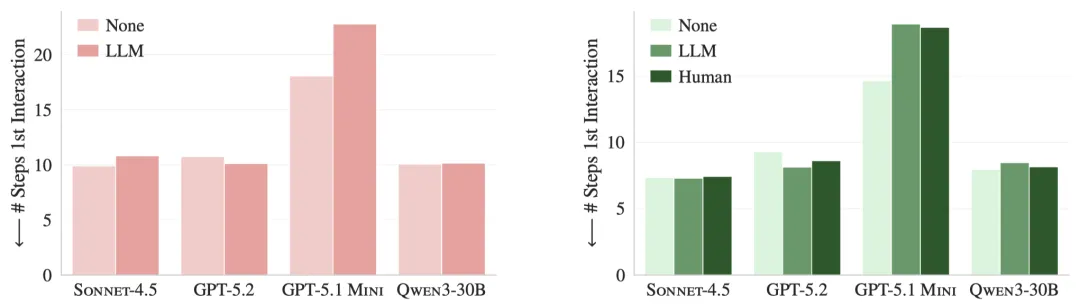
图:在SWE-BENCH L ITE(左)和agent BENCH(右)上,在没有上下文文件的情况下,智能体与PR补丁中包含的文件之间的第一次交互之前的步骤数(越低越好)通常比使用LLM生成的上下文文件或开发人员编写的上下文文件(人)低
-
4. 上下文文件是冗余文档
LLM生成的文件与仓库现有文档高度冗余;在移除所有.md、docs/和示例代码后,LLM文件反而提升2.7%成功率并超过人类开发人员编写的文件
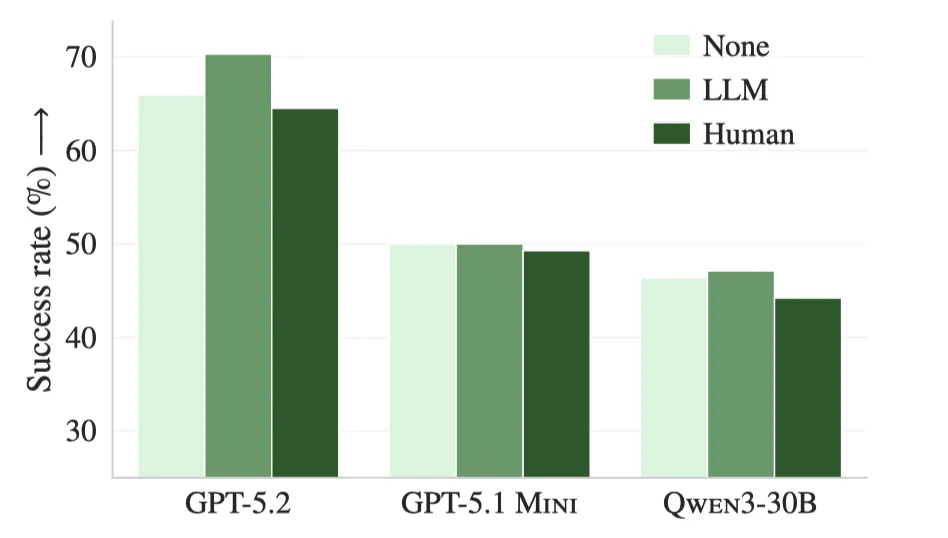
图5:当从代码库中删除所有与文档相关的文件时,LLM生成的上下文文件往往优于AGENTENCH上开发人员提供的(人类)上下文文件
跟踪分析:通过分析智能体工具调用的频率和推理痕迹的长度,更详细地分析上下文文件对智能体行为的影响。有如下3个方面的发现:
-
1. 上下文文件导致更多的测试和探索
工具使用大幅增加:更多测试(pytest、python)、更多仓库导航(grep、find、ls、read、write),以及更多仓库特定工具(如uv、repo_tool、pip等)
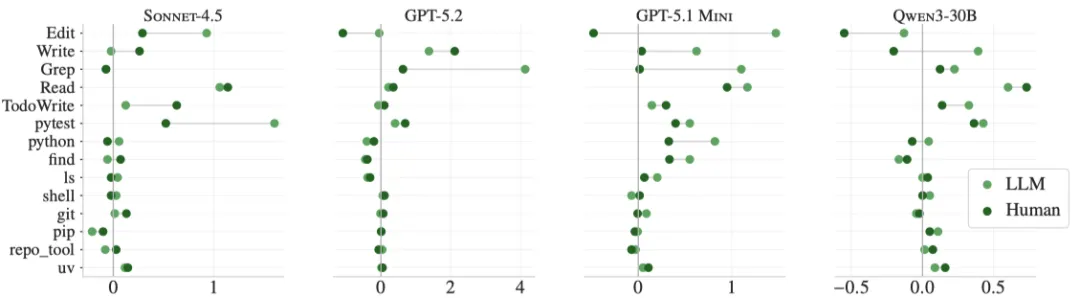
图:与没有上下文文件的平均工具使用相比,包括LLM生成的(亮绿色)或开发人员提供的(深绿色)上下文文件时,平均工具使用增加。对于工具名称,我们将CODEX和QWEN CODE工具映射到CLAUDE CODE等效工具
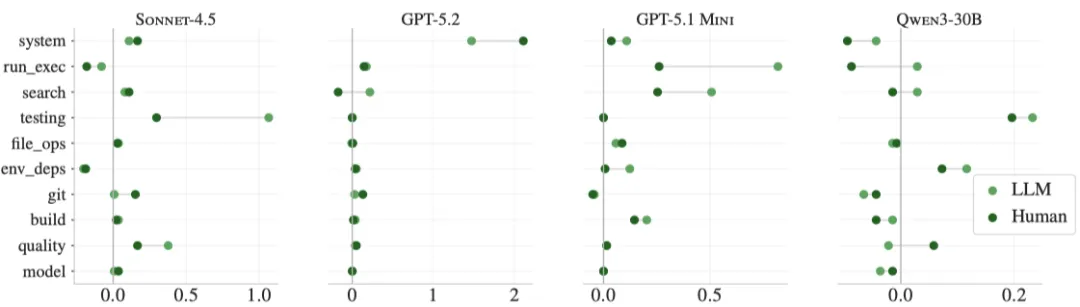
图:与没有上下文文件的平均工具使用相比,包括LLM生成的(亮绿色)或开发人员提供的(深绿色)上下文文件时,平均工具使用(分为高级类别)的增加。对于高级类别,使用LLM对各种工具调用进行分类。
-
2. 智能体通常会遵循上下文文件中的指令
上下文里提到的工具会被大量使用例如,当在上下文文件中提到uv时,每个实例平均使用1.6次,而没有提到时则不到0.01次,当提到存储库特定的工具时,每个示例平均使用2.5次,而当没有提到时,则不到0.05次。
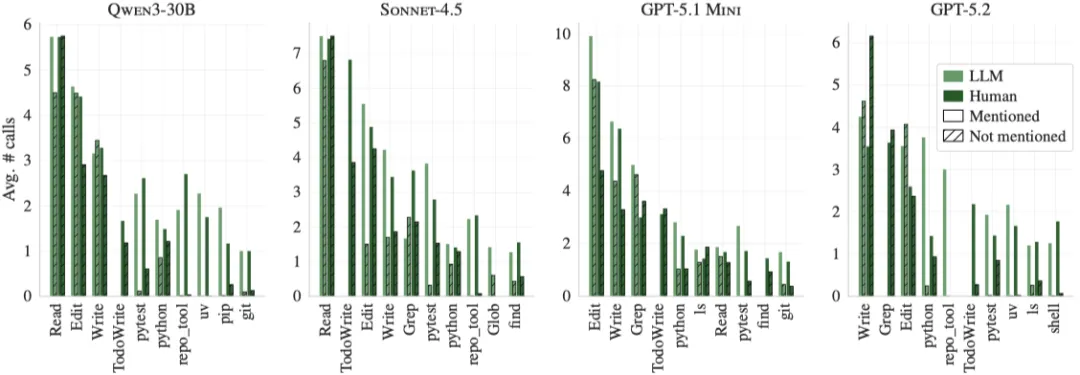
图:工具调用的平均次数取决于上下文文件中是否提到工具名称。对于工具名称,使用下表中的等价类,如果上下文文件中提到了相应等价类中的任何工具,则认为该工具在上下文文件中被提及。

-
3. 额外的指令会使任务变得更加困难
通过分析了GPT-5.2和GPT-5.1 MINI使用的推理token的平均数量,因为它们的自适应推理允许它们为它们认为更难的任务使用更多的推理token。
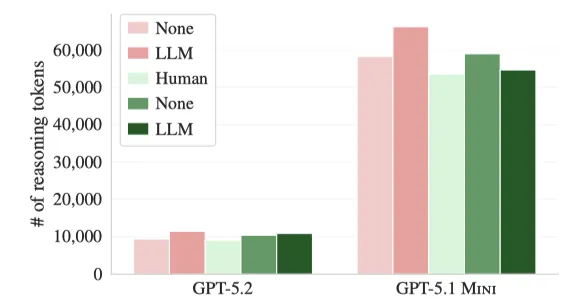
在上图中,发现LLM生成的上下文文件确实使SWEBENCH LITE上GPT-5.2和GPT-5.1 MINI的推理token的平均数量分别增加了22%和14%(在AGENTBENCH上分别增加了14%和10%),并且开发人员编写的上下文文件使GPT5.2和GPT-5.1MINI的推导token的数量分别增加20%和2%。
论文中也有消融(Ablations)实验部分,多组对照实验,结论一致:
- 1. 更强模型生成的文件不一定更好:用GPT-5.2生成的文件在SWE-bench Lite略好(+2%),但在AGENT BENCH反而下降3%(见下图)。
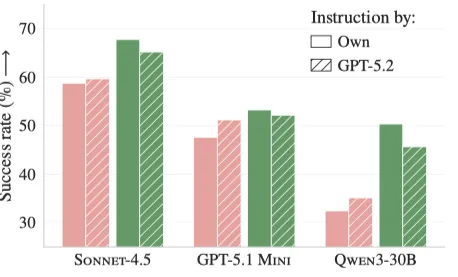
图:在SWE-BENCH LITE上,与使用智能体底层的模型相比,使用GPT-5.2生成的上下文文件可以提高性能,而在agent BENCH上,性能会下降
- 2. 提示词来源影响很小:无论用Codex prompt还是Claude Code prompt,成功率无一致差异(见下图)。
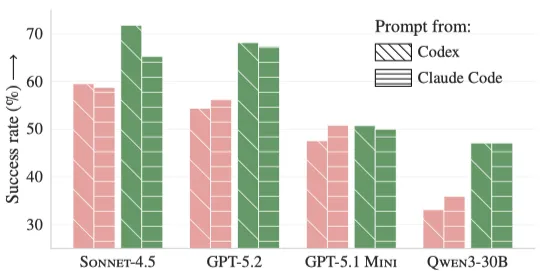
- 3. Human vs LLM:在文档稀缺的仓库中LLM生成的文件胜出;在文档丰富的仓库中人类生成的文件略优,但整体LLM文件多为“冗余指令”。
总结再次强调:AGENTS.md(尤其是LLM生成版)大多增加探索、测试和成本,却没有提升成功率;开发者手写版也仅小幅收益,且必须极简才能避免“戴脚镣”。
结尾
最后,用一句话来总结的话:不必要的指令会让任务更难。人类写AGENTS.md应该只写最少、最关键的要求!
我读完后的真实感受:这篇论文太狠:直接把行业里“写AGENTS.md”这个默认最佳实践给打脸了。 原来我们以为的“给Agent塞技能手册”——很多时候其实是在给它戴脚镣。以后我再给项目写AGENTS.md,只会写三句话:
-
项目核心目标是什么 -
绝对不能碰哪些文件/操作 -
必须使用的工具/命令
其余的……让Agent自己探索去吧!
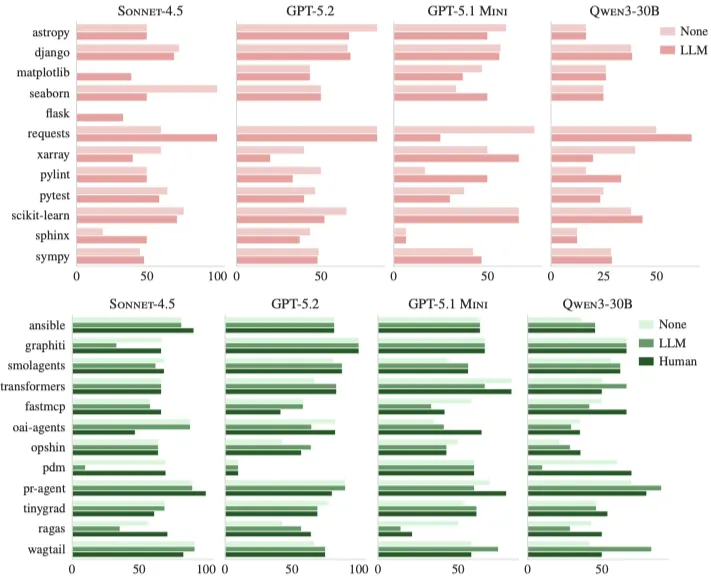
图:按存储库对四种不同模型的解决率进行分组:1.没有上下文文件,2.有LLM生成的上下文文件,以及在SWE-BENCH LITE(顶部)和AGENT BENCH(底部)上3.有开发人员编写的上下文文件。特别是对于SWE-BENCH LITE,大多数实例来自同一个存储库(django),这使得每个存储库的成功率估计都很嘈杂
https://arxiv.org/abs/2602.11988