夜雨聆风
夜雨聆风





AI工具使用手册 | 科研提升篇








还在为劳动科学调研数据整理熬秃头?
还在浩如烟海的文献里“大海捞针”?
别慌!AI工具正化身科研“神队友”,
悄悄承包你科研中的“繁琐活”~
它能分分钟搞定问卷数据分类、提炼文献核心观点,让你从重复劳动中“解放双手”;更能通过精准建模,精准分析灵活就业群体的需求变化、预判行业人才流动趋势;还能挖掘劳动关系新规律——比如通过员工满意度数据定位企业管理痛点,让研究从“凭经验猜”变成“用数据说话”……对于劳动科学研究者来说,AI早已不是“高大上”的技术名词,而是能帮你提升效率、解锁科研新思路的实用工具,正悄悄改变我们探索劳动世界的方式~

AI工具使用手册主要分为六部分
(一)导论:AI工具基本原理与分类
(二)AI工具应用–日常学习
(三)AI工具应用–科研提升
(四)AI工具应用–职业发展
(五)AI工具与劳动科学
(六)总结与思考
本期推送呈现AI工具使用手册的第三部分
——科研提升篇。
实用路线图:AI赋能科研全流程
一、选题与文献综述阶段
做劳动科学研究,第一步就卡壳?面对知网、Web of Science上成千上万篇文献,要么找不到研究空白,要么被热点裹挟不知从何入手——这是很多研究者面临的的共同痛点。手动筛选文献、梳理研究脉络不仅耗时耗力,还容易遗漏关键信息,让选题陷入“重复劳动”或“方向跑偏”的困境。
AI工具并非替代人工阅读,而是成为文献综述的“高效助手”,帮你快速突破文献壁垒,聚焦核心研究方向。
(一)研究者核心任务
1. 核心文献深度精读:手动筛选顶刊、高被引、领域权威学者的代表性文献,逐句研读核心观点、研究设计细节与论证逻辑,建立对研究领域的“体感认知”;
2. 文献质量与关联性甄别:人工判断文献的研究范式、数据可靠性、结论普适性,剔除低质量、同质化或与研究方向关联性弱的文献;
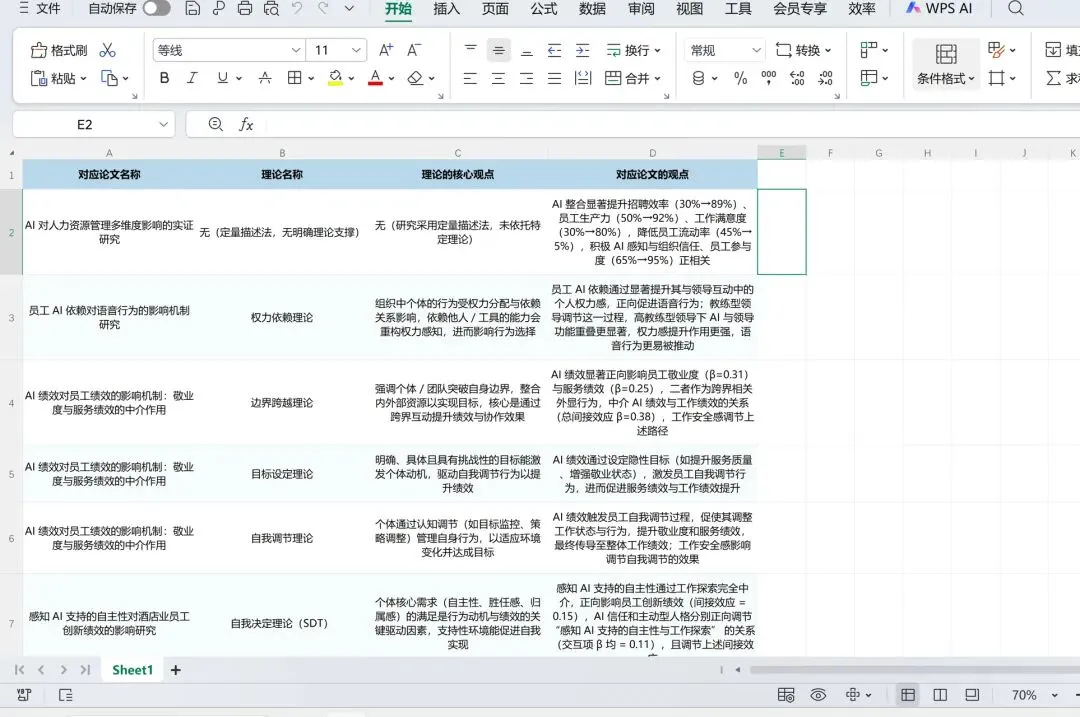
3. 文献表格搭建:手动整理关键信息(作者、年份、期刊、摘要、理论、未来研究方向),汇总成excel表格,为定位研究空白提供直接依据;
4. 研究空白的独立判断:基于人工精读与文献表格,自主提炼现有研究的未覆盖领域(如 “仅关注AI对高技能劳动者的影响,缺乏低技能群体的实证分析”),避免依赖AI直接给出“研究缺口”。
(二)AI 辅助场景
(1)确定感兴趣的研究主题后,可指令AI生成相关领域“核心观点、研究方法和关键结论”的结构化摘要框架,例如输入“总结近5年‘数字经济对制造业劳动力需求的影响’相关文献的核心理论、常用研究方法及关键结论,以表格形式呈现”,AI生成的框架可作为人工精读的前置参考,帮助快速建立整体认知;
(2)若想洞察知识点间的关联,可要求AI生成“关于X主题的知识图谱”,比如“生成‘灵活就业与社会保障体系适配性’的知识图谱,呈现研究热点、核心理论与争议点”,通过可视化方式直观呈现领域脉络,辅助人工定位研究空白。
(三)推荐软件
秘塔AI:这款国内开发、完全免费的AI智能搜索引擎非常适合学术研究者快速了解某个主题。它的特点是可以限定搜索范围(全网搜索/中文文库/英文文库),在海量文献中筛选有用信息,结构化展示,并提供可直接下载的文献pdf。
比如,当你想研究“AI对工作技能需求的冲击”时,只需用秘塔AI搜索输入主题句,并勾选英文文库,它便会自动筛选近10年的高被引文献,并生成结构化摘要,同时标注出“技能偏向型技术进步”“数字技能溢价”等核心观点。让你更快从宏观研究方向中聚焦“AI如何影响低技能劳动者就业转型”等细分领域。

二、确定研究方法
短期小课题VS长期大课题
定性研究VS定量研究
实证研究VS文献综述
研究课题的复杂度不同,研究活动本身的性质与类别不同,适合的研究方法也大相径庭。有时,借助Deepseek、豆包等生成式AI工具,可获得更多元的方法思路,但研究方法的最终决策仍需研究者主导。
(一)研究者核心任务
1. 学习并掌握社会科学常用研究方法:例如组织行为学研究常用实验法、问卷调查法;劳动关系学研究常用深度访谈、扎根理论。此外,还有个案研究、文献研究等;
2. 根据研究目的界定研究本质:人工明确研究的核心属性——是定性or定量、实证or综述、描述型or因果型or预测型,这是选择研究方法的前提;
根据可行性最终确定研究形式:结合自身研究能力(如是否掌握量化模型、访谈技巧)、时间经费、人力资源,判断方法的落地可能性(如跨国公司的一手数据难以收集导致相关研究难以实行)。
(二)AI工具辅助场景
1. 寻找特定研究方法的文献:借用AI快速筛选方法类文献,归纳主流范式与常用工具。
2. 提供研究方法实施细节:比如,当你决定好使用问卷调查搭配访谈法研究“信息过载对员工工作倦怠的影响”,豆包、deepseek等AI工具可以为你制定纵深问卷分期发放与收集的时间线,或草拟访谈提纲、预估经费开销等等。
三、数据处理与分析
3.1数据清洗
通过问卷调查、实验或访谈记录编码等方法得到的数据都称作原始数据,我们需要对原始数据进行结构化清洗,确保数据质量。
中小样本量的数据(小于300份)通常可以使用Excel自带的XLOOKUP等公式手动清洗。但对于极大样本量的数据(大于1000份),手动清洗非常繁琐且易遗漏,需要搭配Python、R、Stata等数据处理软件。现在的AI工具虽然不能直接读取并清洗数据,但可以按照研究者的要求给出数据清洗用到的代码,大大提高数据清洗的效率。
(一)研究者核心任务
1. 原始数据的真实性与合法性把关:人工核验数据来源(如问卷是否真实填写、访谈记录是否完整),确保数据采集符合学术规范与伦理(如未侵犯受访者隐私);
2. 关键数据决策:数据清洗中,人工判断缺失值或异常值的处理逻辑(如缺失值是删除还是插值,异常值是数据错误还是有效特例);
3. 清洗结果校验:对清洗后的结果进行人工复核,确保匿名化彻底、信息无遗漏、格式标准化准确。
(二)AI工具辅助场景
在大样本数据清洗中,AI 工具的核心价值是生成标准化、可复用的代码模板,而非直接操作数据,研究者需将代码手动复制到 Python、R 等软件中执行,既保证效率又守住数据安全与质量底线。
以 Python 数据清洗为例,可按“需求描述→代码生成→人工校验”三步完成:
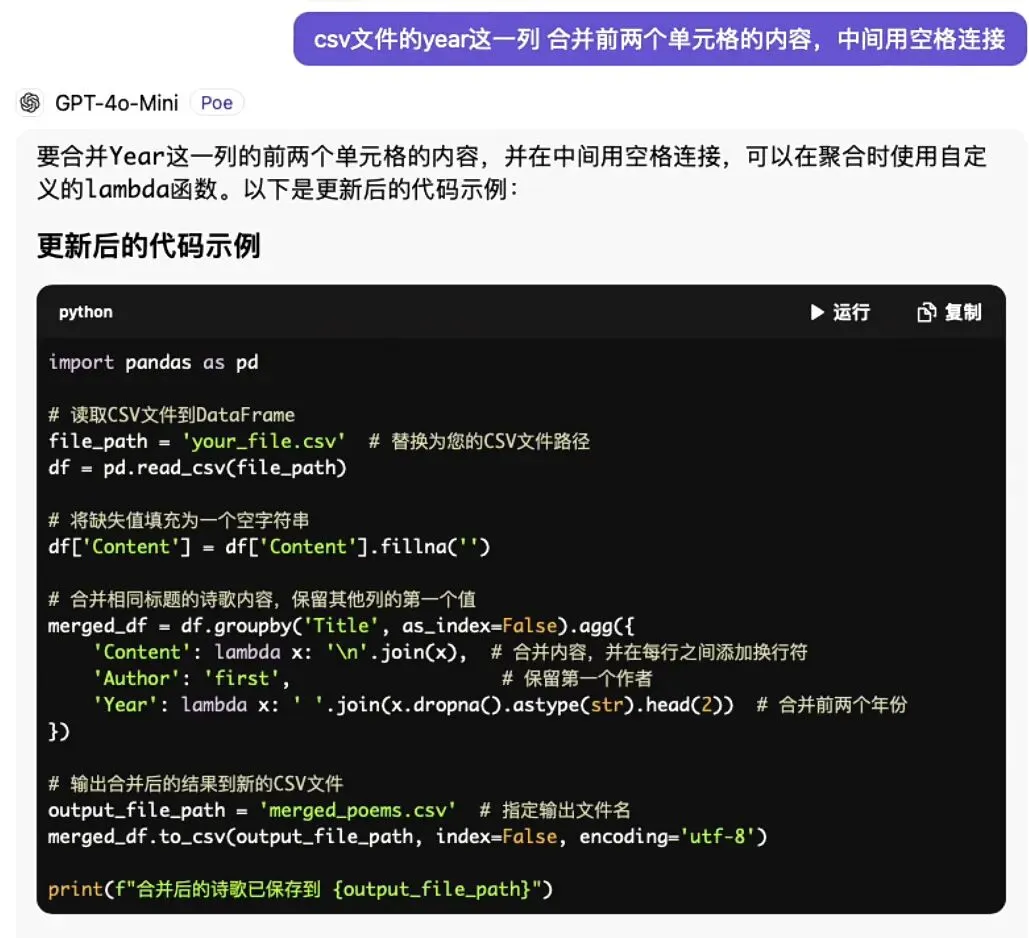
1. 明确清洗需求:向 ChatGPT 等工具清晰说明数据类型、清洗目标与约束条件,避免模糊指令。例如:“我有一份1500行的社科调研CSV数据,包含年龄、收入、教育程度等变量,需要完成以下清洗操作:①删除完全重复的行;②识别并标注缺失值的位置与占比;③对异常值(如年龄> 100 或收入为负数)进行标记并说明判断依据;④将分类变量‘教育程度’统一为‘小学及以下/初中/高中/大专及以上’四类。请生成可直接运行的Python代码,并标注关键步骤的注释。”
2. 代码生成与调试:AI 会快速输出包含pandas等库的完整代码,研究者可根据实际数据路径、变量名进行微调,比如将pd.read_csv(“data.csv”)替换为自己的文件地址,或补充自定义的异常值判定规则。
3. 结果人工复核:代码运行后,需人工核对清洗结果——比如检查缺失值占比是否符合预期、异常值标记是否准确、分类变量合并是否完整,确保数据清洗后仍能支撑后续研究分析,避免代码逻辑偏差影响结论可靠性。
对于质性访谈数据的清洗,也可沿用类似思路:将访谈文本的清洗规则(如匿名化、发言人标准化、非言语信息规范化)整理为指令,让 AI 生成 Python 文本处理代码,再手动运行实现批量清洗,大幅减少逐行手动修改的重复劳动,同时保留人工对关键信息的最终审核权。
3.2数据分析
数据分析的具体步骤与方法基本可分为质性分析和定量分析两类。
(一)质性分析
对于质性分析,选择哪种方法主要取决于我们的研究问题、数据类型(如访谈记录、田野笔记、文本资料)和理论立场。主流的质性分析方法包括扎根理论法、主题分析法、比较分析法等。其中扎根理论法更加强调数据处理分析。
用AI工具辅助扎根理论的编码,可以极大地提升效率,但关键在于“辅助”而非“替代”。整个过程可以分为三个阶段:
①AI初步编码(开荒):将你的访谈稿(建议先少量投喂,测试效果)和研究问题输入给AI,让它快速生成开放编码和主轴编码。这个过程非常快,可能只需要几十分钟。
②人工审核与深化(精装修):AI生成的编码只是一个起点。你需要仔细检查,剔除不准确或不相关的编码,并根据自己的研究问题和理论框架进行修改、合并或拆分。这一步是确保研究质量的关键。
③整合到专业软件(展示与深化):一些高级AI工具可以直接将编码结果导出为NVivo等质性分析软件的格式。
提示词设计思路:
开放编码指令:“你现在是一名教育学研究者,在运用扎根理论方法研究研究生数学课程教学改革。请对以下访谈文本进行程序性扎根的第一步——初始概念的提取。请逐句分析原文,形成初始概念,并以表格形式输出,包含编号、原文、初始概念三列。”
主轴编码指令:“现在你已经完成了开放性编码的提取,接下来要进行主轴性编码的提取。请将以下形成的开放性编码,按照表达内涵与逻辑,将一致的归类为同一主轴编码。每个编码不超过8字。”
(二)定量分析
对于量化研究,在完成数据清洗后,我们要对数据进行统计分析得到变量间的关系,从而验证研究假设。在这一步,AI 的作用是帮你把重复、机械的代码化工作高效完成,让你聚焦分析逻辑本身。
1.研究者核心任务
①先锚定自己的研究问题,再确定要做的是描述现状、探索关联还是验证因果。
②其次,根据变量类型(连续/分类/计数)、数据结构(横截面/面板/时间序列)和研究目标,自主选择合适的统计方法。比如用线性回归看连续变量影响、用逻辑回归分析二分类结果、用双重差分法评估政策效应。
③注意手动检验模型的前提条件,比如线性回归要验证线性关系、正态性和同方差,避免因假设不成立导致结果偏误。
④亲自解读系数大小、显著性水平,判断结果是否符合理论和现实逻辑,比如系数方向是否与预期一致、显著水平是否足够支撑结论,不被机械的统计结果牵着走。
2.AI工具辅助场景
①方法与代码参考:你可以把研究问题、数据类型和技术基础告诉AI,比如 “我有一份横截面数据,想研究教育年限对起薪的影响,会基础 Python,麻烦推荐合适模型并写出可直接运行的代码”,它会快速给出包含数据导入、描述统计、回归分析、结果可视化的完整代码模板,你只需替换文件路径和变量名即可运行。
②模型调试与问题排查:当代码报错或模型假设不满足时,比如发现异方差、多重共线性,可把报错信息或数据特征告诉AI,让它提供修正方案,比如添加稳健标准误、使用逐步回归筛选变量。
③结果可视化与格式整理:让AI帮你生成描述统计表格、回归系数图、交互效应图等可视化代码,或把回归结果整理成符合学术规范的表格格式,省去手动排版的繁琐。
3.应用案例
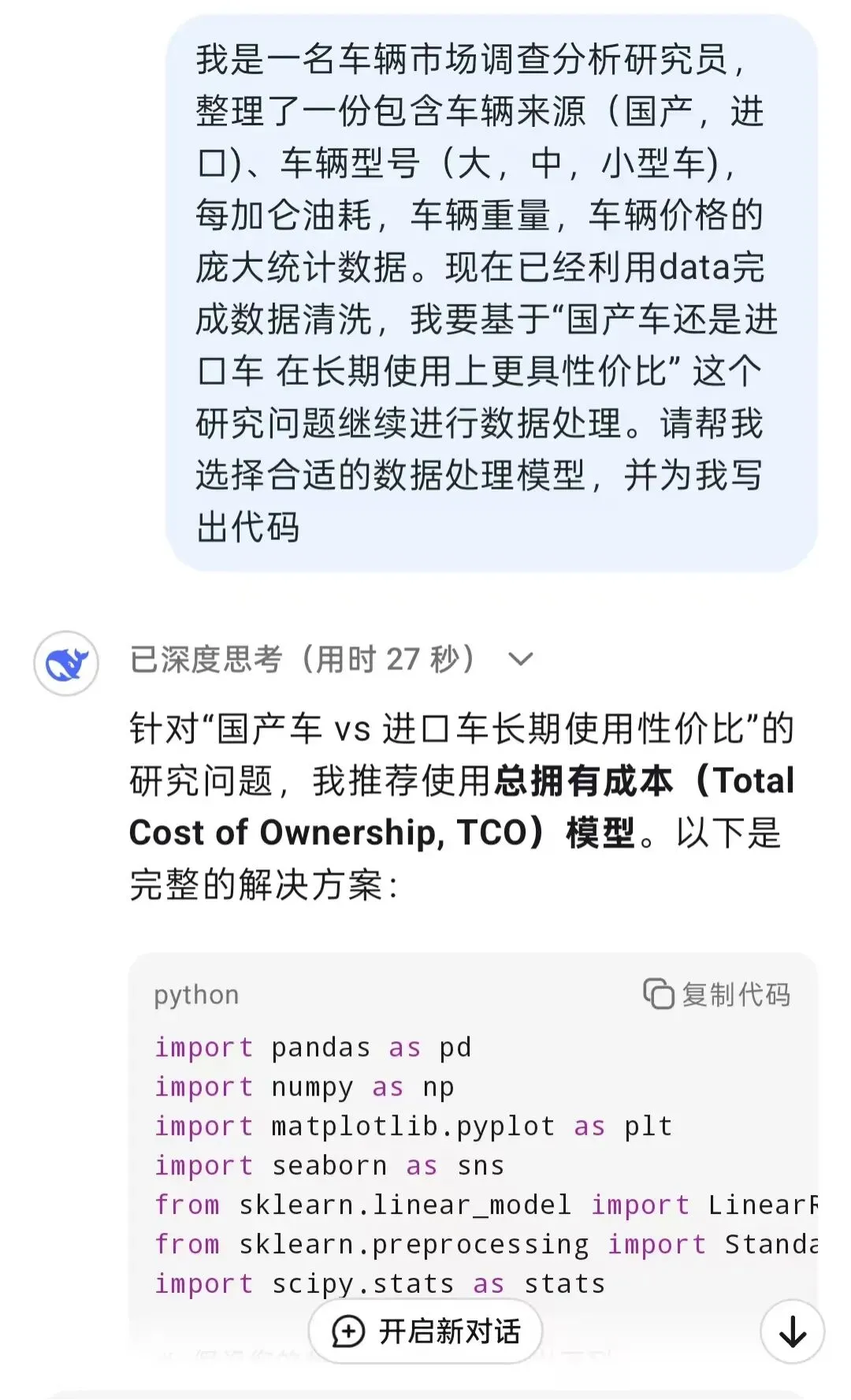
举个例子,在研究 “国产车与进口车长期使用性价比” 时,你可以告诉 AI“我有一份包含车辆来源、油耗、重量、价格的数据集,想分析两类车的总拥有成本差异,请你推荐合适的数据处理模型,并按步骤给出python运行代码”,AI 会推荐 TCO 模型并生成对应的Python分析代码,你运行后得到初步结果,再亲自验证模型假设、解读差异背后的现实原因,完成最终结论。
四、论文撰写与优化阶段
论文的撰写与优化是研究成果最终呈现的关键环节,常常伴随着写作卡顿、格式繁琐、超长文档信息提炼困难等痛点。AI 工具可作为 “初稿生成器” 与 “格式助理”,但论文的核心观点、逻辑框架与学术原创性必须由研究者主导。
适用AI模型推荐:
|
主力模型 |
GPT-5、Claude Sonnet 4.5 |
它们在逻辑推理、生成高质量文本等方面表现较佳,能很好地处理复杂的学术指令。 |
|
学术写作辅助 |
Gemini 3.0 |
其在复杂推理、长文本处理和多模态信息融合方面优势显著,能深度理解学术图表与文档,进行更精准的跨域知识推理,尤其擅长在大量信息中建立逻辑关联,非常适合用于对研究数据与结果进行综合性、洞察性的深度解读与总结提炼。 |
|
长文本处理 |
Kimichat |
如果您的论文全文很长,需要它进行通篇格式检查或逻辑梳理,其长上下文能力是巨大优势 |
|
辅助工具 |
Microsoft Copilot |
它的核心优势在于深度集成Office与Windows生态系统,能够有效完成数据处理、论文撰写与可视化和调整格式等任务。 |
具体应用场景:
(一)摘要初稿
提示词设计思路:
【角色设定】你是一位资深的学术期刊编辑,善于用精炼的语言概括研究的核心价值。
【任务背景】我需要为我的论文生成一份摘要。
【研究核心信息】以下是研究的核心信息:研究问题、研究方法、关键发现、主要结论。
【具体任务】请根据以上信息,为我生成一份约250-300字的学术摘要。本次摘要的侧重点在于 [请选择:理论贡献 / 实践启示 / 方法论创新]。
【输出要求】摘要需包含研究背景、目的、方法、结果和结论五个要素,语言严谨、简洁。


(二)政策建议
【角色设定】你是一位资深政策顾问,擅长将学术研究成果转化为面向政府或公共机构的具体、可行建议。
【任务背景】我的研究发现:[用1-2句话总结研究的核心结论]
【具体任务】请基于以上核心发现,为相关政策制定者(如:[指明部门,如教育部、工信部等])生成3至5条简明扼要的政策建议。
【输出要求】
·每条建议必须具体、可操作,避免空泛。
·每条建议需简要说明其依据(即它基于研究的哪个发现)。
·语言应清晰、专业,适合政策文件使用。
(三)格式调整
【角色设定】你是一位一丝不苟的学术写作助手,对论文格式和逻辑结构有极高的敏感度。
【任务与要求】请对以下文本执行 [请选择1项或多项]任务:
·检查逻辑结构:检查段落的过渡是否自然,论述逻辑是否流畅,并指出不连贯之处。
·统一引用格式:将文内的参考文献引用格式统一为[例如:APA 7th / GB/T 7714]格式。
·提取关键信息:从文本中提取出所有的研究假设、核心发现或待办事项。
【待处理文本】[在此粘贴您的论文章节或全文]
【输出要求】请清晰地分点列出你的修改建议、格式调整结果或提取出的信息。
关于内容生成与学术诚信:在使用AI生成摘要、政策建议等关键内容时,建议研究者以自身学术思考为主导,明确核心观点与逻辑框架,再引导AI进行辅助扩充与表达优化。对于AI生成的文本初稿,务必进行深入的思考与修改,确保其准确反映您的研究成果,并严格进行学术不端检测,确保文本的原创性,维护学术研究的严肃性与个人学术声誉。
总结与展望
人工智能正以前所未有的力量重塑科研的范式,为我们提供了洞察社会复杂性的强大透镜。对于劳人院的学子而言,这些工具在提升研究效率、拓展分析维度的同时,更是一面映照我们初心的镜子。我们须臾不能忘记,所有冰冷的数据与算法背后,是鲜活而具体的劳动生命与真实的社会脉络。
因此,在拥抱技术红利的同时,我们必须更加警惕,坚守人文社科的独特使命:对劳动权益的深切关怀、对结构不平等的敏锐洞察以及对人的价值与尊严的永恒追问。展望未来,愿诸位能驾驭AI之力,而非为其所驾驭,让技术的光芒,最终照亮我们对于公平、正义与更美好劳动世界的追求之路。
声明:本手册为劳动人事学院学生会智研拓展中心自主研讨、凝聚集体智慧的实践成果,仅供科研学习参考使用。本手册所载AI工具使用方法与建议均为学子实践经验总结,不代表专业学术指导意见,科研工作中请结合自身研究实际审慎使用,相关使用风险由使用者自行承担。
智启新境,研拓未来
文案&图片:学生创新训练中心
学生会智研拓展中心 代钰辉 郭美麟 王曼睿
编辑:宣传部 胡福麟
审核:郭瑜 王鸿飞 陈力凡 张悦悦 王思琪 黄晨宇