 夜雨聆风
夜雨聆风





Claude Code源码和 107页的《深度技术分析》及对 AI 应用的启示
Claude Code的所有源码因为一个非常低级的安全问题泄露了,估计全世界产品的Agent框架都要起飞了,这次又以一己之力推动了全球AI圈的进步。
源码地址:https://github.com/instructkr/claude-code关注公众号,回复关键词“0401” ,下载源代码和 107页的《Claude Code源代码深度技术分析》,仅供源代码泄露事件 的安全研究。

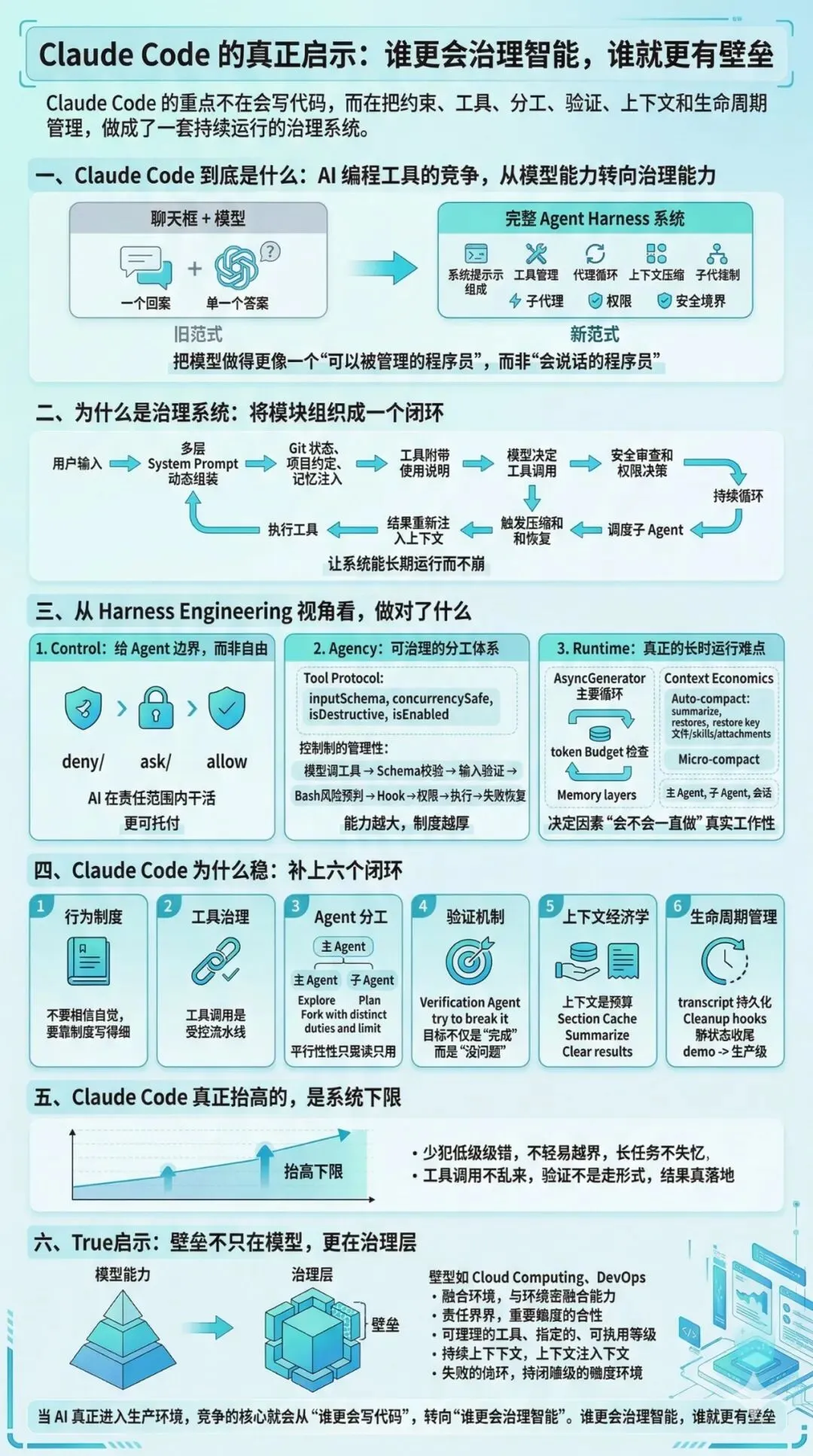
一、真正值得讨论的,不是 Claude 会不会写代码,而是 Claude Code 到底是什么
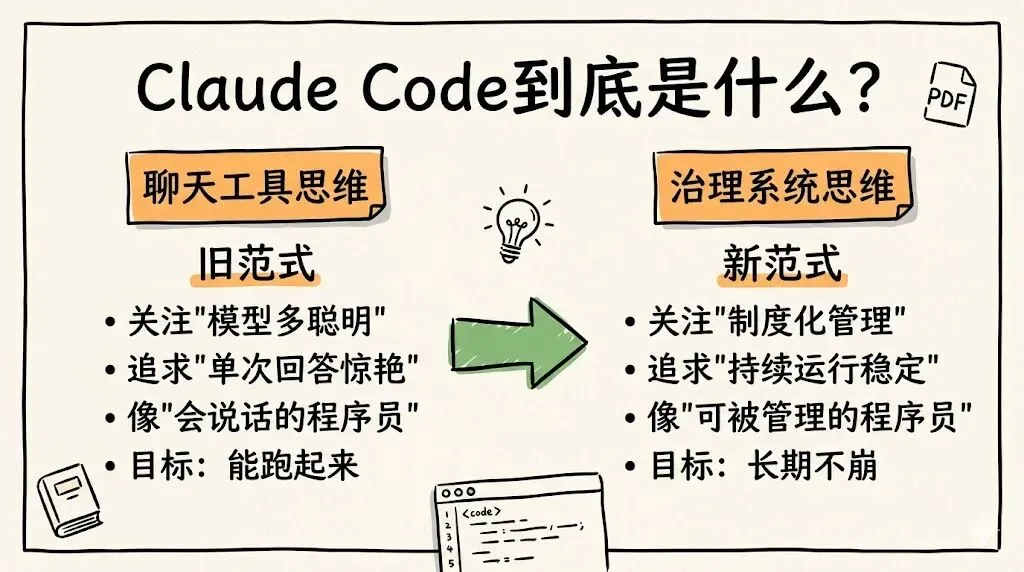
如果今天还用“哪个模型更聪明”来理解 AI 编程工具,其实已经有点落后了。
因为一旦 AI 真正进入生产环境,用户面对的核心问题就不再是一个抽象智力题,而是一组非常具体、非常工程化的问题:它会不会误改文件?会不会乱跑命令?能不能理解项目约定?长任务做着做着会不会失忆?出了错之后能不能继续推进?它说“做完了”,到底只是语言上的自信,还是环境里真的留下了正确结果?
这也是为什么,Claude Code 这类产品真正值得研究的,不是它的模型名字,也不是首轮代码有多惊艳,而是它背后的那套系统设计。
从你给我的那份《Agent Harness 指南》来看,Claude Code 并不是一个“聊天 + 调工具”的简单包装层,而是一个完整的 Agent Harness:它负责 system prompt 组装、工具集管理、agent loop 驱动、上下文压缩、子 Agent 协调,以及权限与安全边界控制。换句话说,它不是把模型接到终端上就算结束,而是先给模型搭了一套运行制度,再让模型在制度之内工作。
这件事听上去很抽象,但可以换一个更直观的说法:
Claude Code 的核心价值,不是把模型做得更像一个“会说话的程序员”,而是把模型做得更像一个“可以被管理的程序员”。
这看似只是措辞差异,实际上是产品范式的变化。
前一种范式,关心的是单次回答像不像、聪不聪明、生成得漂不漂亮。后一种范式,关心的是这个系统能否在真实开发环境中持续运行,能否在风险边界内行动,能否在长任务里不漂移,能否在失败后恢复,能否把人的工程纪律变成机器的执行秩序。
而这,正是我认为 Claude Code 给行业最重要的启示:
AI 编程工具的竞争,正在从模型能力竞争,转向治理能力竞争。
二、为什么说 Claude Code 不是“更强聊天框”,而是一套治理系统
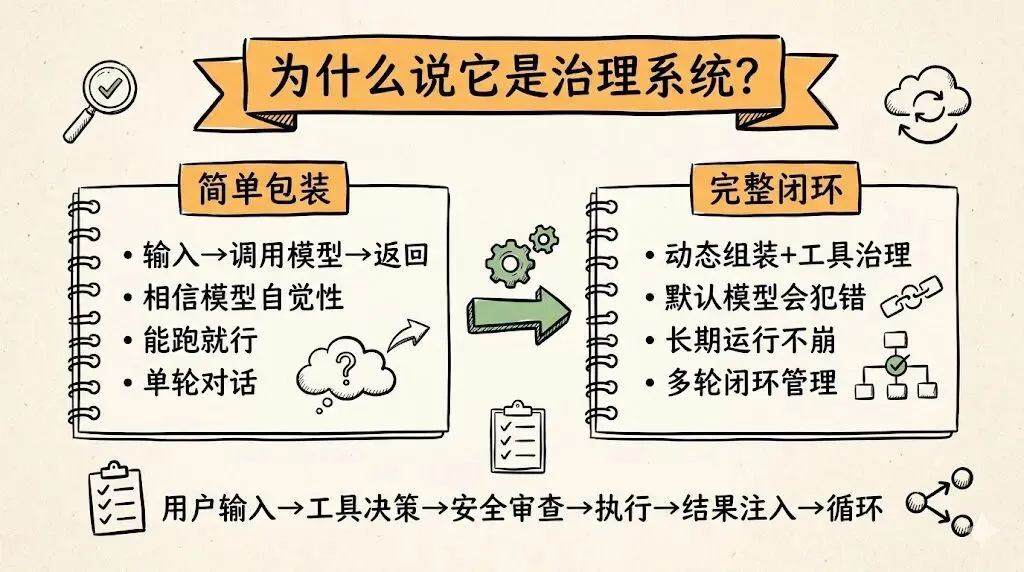
很多人第一次理解 Claude Code,会把注意力放在 prompt、模型、工具数量、多 Agent 这些表面标签上。
但如果你把系统链路真正拆开,你会发现 Claude Code 的重点根本不在这些孤立模块,而在于它把这些模块组织成了一个闭环。
按照你补充的源码解读,它的内部链路并不是“用户输入 → 调用模型 → 返回结果”这么简单,而更像是:
用户输入→ 动态组装多层 system prompt→ 注入 Git 状态、项目约定、历史记忆→ 给工具附上自己的使用说明→ 模型决定用哪个工具→ 安全审查链和权限决策→ 执行工具→ 将工具结果重新注入上下文→ 当上下文接近上限时触发压缩和恢复→ 在复杂任务里调度子 Agent→ 持续循环直到任务结束。
光是把这条链看全,你就会明白一个问题:Claude Code 真正厉害的,从来不是“那段 prompt 写得神”,而是它背后这整套 runtime + governance 的组织能力。
它看起来更稳,不是因为模型“天生更乖”,而是因为系统默认模型会犯错,默认工具会误用,默认上下文会爆,默认任务会中断,默认状态会变脏,默认世界不会一直正常。
所以它的设计哲学不是“相信模型自觉”,而是“把正确行为制度化,把常见失败系统化处理”。
这恰恰就是治理系统和普通产品的根本差别。
普通产品追求的是“能跑起来”。治理系统追求的是“能长期运行而不崩”。
三、从 Harness Engineering 视角看,Claude Code 真正做对了什么
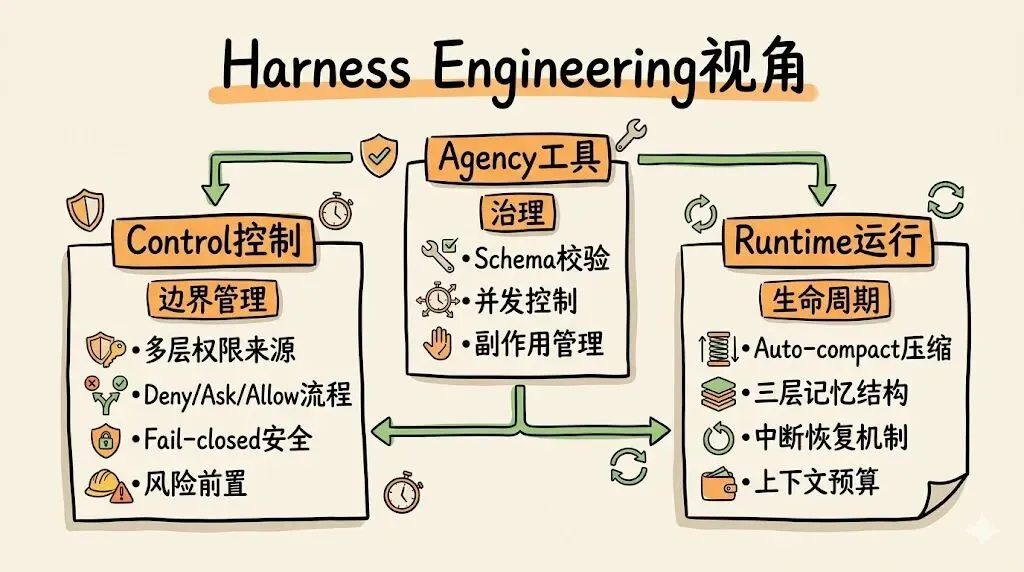
如果借用 Harness Engineering 这个分析框架,Claude Code 的价值就更容易看清。
那篇关于 harness 的论文,把 harness 定义为一个治理多次模型或 agent 调用的编排层。它至少处理三件事:control,也就是工作如何分解与调度;contracts/gates,也就是需要产出什么、满足什么条件才算完成;以及 state,也就是哪些东西必须在多步骤、多分支、多子代理之间持续保存。论文还明确区分了 harness 和 runtime:前者负责任务家族级的控制逻辑,后者提供工具接口、sandbox、child lifecycle 之类的底层运行能力。
把这个框架套到 Claude Code 上,我们会发现它恰好是一个非常高完成度的样本。
1. 它在做 Control:不是给 Agent 更多自由,而是给 Agent 更清晰的边界
Claude Code 最厚的一层工程,其实是控制层。
在 PDF 里,权限系统被明确拆成一套独立架构:权限有 user、project、local、flag、policy 等多层来源;policy 优先级最高,用户不能覆盖;每次工具调用都要经过 deny / ask / allow 的决策流程;即便在某些高权限模式下,安全检查也不会完全失效;Bash 分类器如果不可用,会采取 fail-closed;而且文档直接写明,沙箱只是便利特性,不是真正安全边界,真正的边界来自权限系统。
这意味着 Claude Code 解决的不是“AI 能不能做”,而是“AI 在什么边界内做”。
这是一个非常关键的转向。
因为对真实开发环境来说,问题从来不是“让 AI 尽量多干点”,而是“让 AI 在你能承担责任的范围内干活”。你可以接受它读文件、搜代码、做计划,但不一定接受它随便删目录、改共享配置、执行高风险命令、把敏感信息上传到第三方服务。也就是说,真正重要的不是“自主性有多大”,而是“自主性有没有边界”。
Claude Code 的控制层,本质上就是把人的风险意识翻译成系统规则。
你不能指望一个概率模型每次都自己想清楚 blast radius。但你可以在系统里明确写下:到了这个位置,先别乱动,先问用户。
这也是为什么我会说,Claude Code 最重要的不是“更强”,而是“更可托付”。
2. 它在做 Agency:不是工具堆砌,而是可治理的分工体系
很多人分析 AI 编程工具,第一反应是数工具:有多少个工具、能接多少插件、支不支持 MCP、能不能多 Agent。
但在 Claude Code 这里,真正重要的从来不是“多少”,而是“有没有治理”。
从 PDF 看,它的 Tool 协议非常完整:工具不只有 name 和 call,还包括 inputSchema、prompt、isConcurrencySafe、isReadOnly、isDestructive、isEnabled 等描述字段;工具池不是直接暴露给模型,而是先经过 feature gate、环境适配、deny rules、去重排序,再和 MCP 工具合并;执行时也不是一股脑全跑,而是依据并发安全性自动分批,只读操作并发,有副作用操作串行;工具太多时,还会启用 Tool Search,把描述按需延迟加载。
你补充的那篇长文把这套链路说得更直白:模型要调工具,不是“说调就调”,中间还有 schema 校验、输入验证、Bash 风险预判、PreToolUse hooks、权限解析、正式 permission 流程、PostToolUse hooks、结构化输出处理、失败恢复。也就是说,Claude Code 对工具的态度不是“多多益善”,而是“必须经过治理后才允许进入模型的行动空间”。
这一点非常重要,因为 Agent 系统最怕的根本不是“没工具”,而是“乱用工具”。
一个没有治理的工具生态,就像给实习生发了一大串 root 权限和脚本入口,然后希望他自己别乱按。看起来能力很大,实际上只是事故半径更大。
Claude Code 对 agency 的理解,恰恰相反:
代理能力不是自由度,而是被约束后的分工能力。
3. 它在做 Runtime:真正的难点,不是推理,而是长时运行
Claude Code 这套系统最有工程味的地方,我觉得不在 prompt,也不在工具,而在 runtime。
PDF 对这一层写得很清楚:主循环是 AsyncGenerator 驱动的 agent loop;每轮都重新检查 token 预算;上下文接近阈值时触发 auto-compact;compact 不是简单裁切,而是先生成结构化摘要,再重新读取最近修改的关键文件、恢复活跃 skills 和关键 attachment;除此之外,还有 micro-compact,会对大型工具结果做即时瘦身;记忆也不是一层,而是主 Agent 记忆、子 Agent 记忆和会话记忆三层结构。
为什么这些东西值钱?
因为 AI 编程工具最容易被高估的,就是第一轮回答;最容易被低估的,就是第十轮还记不记得自己在干什么。
短任务里,一个聪明模型已经能给你很多惊艳时刻。但一旦进入真实开发工作流,问题就变了:
-
• 你要读很多文件 -
• 你要跨多个目录 -
• 你要反复调用工具 -
• 你要在多轮里维持上下文 -
• 你要在失败后接着推进 -
• 你要在中断、恢复、重启后还能续上
这时候,决定体验的就不再是“会不会答”,而是“会不会一直做”。
Claude Code 真正解决的,恰恰是这个问题。
它把上下文当预算来花,把记忆当正式对象来管理,把中断和恢复当生命周期问题来处理。这是一个 demo 产品和一个生产级系统之间最典型的差别。
demo 关注的是“这一轮多亮眼”。生产系统关注的是“跑一百轮之后还干不干净”。
四、Claude Code 为什么会显得“更稳”:因为它把六个闭环都补上了
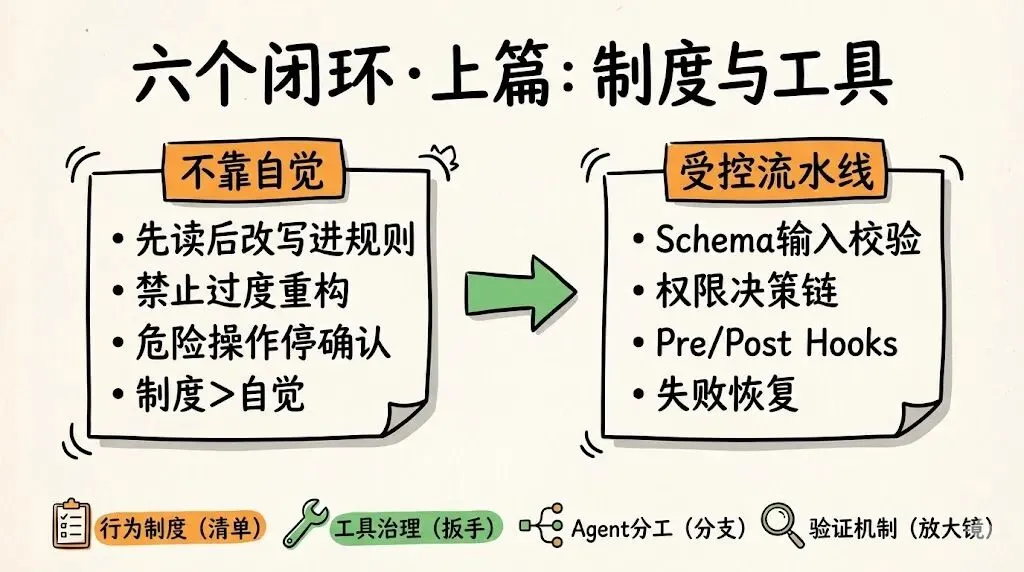
如果一定要把 Claude Code 的“手感”拆开,我觉得你补充的那六个词是最准确的:
行为制度、工具治理、Agent 分工、验证机制、上下文经济学、生命周期管理。
这六个词,基本就构成了它和很多同类工具之间的真正差异。
1. 行为制度:不要相信模型的自觉性
你补充的文本里有一个判断我很认同:Claude Code 稳,不是因为模型更乖,而是因为规矩写得足够细。
这背后其实是一个特别朴素、但特别重要的产品哲学:
好行为不能靠模型临场发挥,要写成制度。
你希望它先读再改,就把“先读后改”写进规则。你希望它不要顺手大重构,就把“不要过度抽象、不要乱加功能”写进规则。你希望它碰到危险操作先停下来确认,就在 runtime 里加权限判断和 risk gate。
这跟很多 Agent 产品的思路正好相反。很多系统默认模型只要足够聪明,就会自然学会这些行为;Claude Code 的思路则更接近传统工程管理:不要相信自觉,要靠制度。
2. 工具治理:不是让模型想调什么就调什么
工具是 Agent 的手,但手不能直接连到所有危险动作。
Claude Code 真正做对的一点,是它没有把工具暴露当成一个静态列表,而是把工具调用变成了一条受控流水线。模型不是说一句“我要用 Bash”就直接执行,而是要先过输入校验、权限决策、hooks、后处理、失败恢复这些层。工具越强,治理越重。能力越大,制度越厚。
这背后有一个被很多产品忽略的事实:Agent 最怕的不是工具不够,而是工具无序。
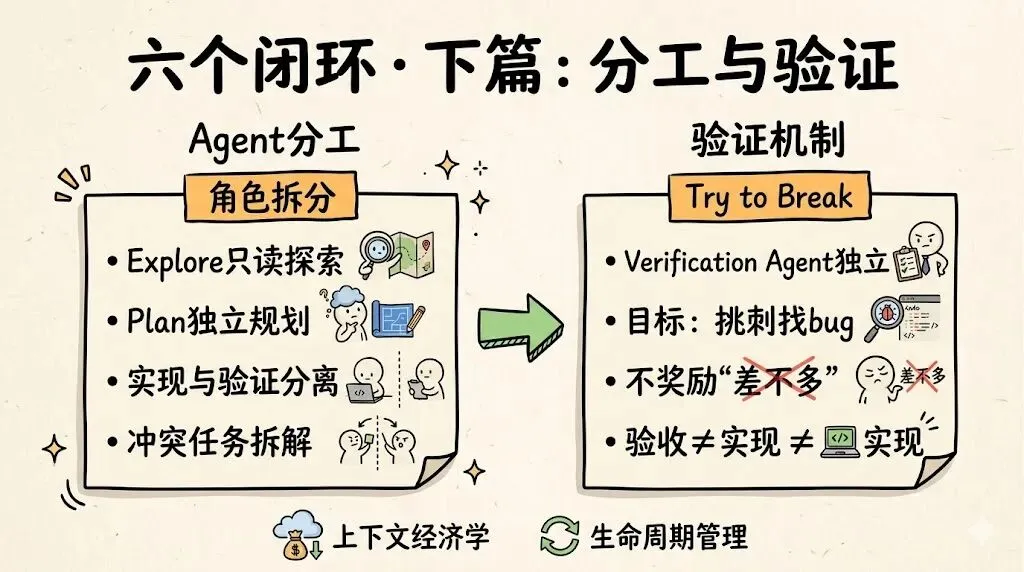
3. Agent 分工:不是多 Agent,而是把角色拆开
Claude Code 不是一个 Agent,而更像一组角色化的 Agent 体系。
PDF 里明确列出了主 Agent、子 Agent、Fork Agent 三种类型;Explore 和 Plan 这种子 Agent 拥有独立消息历史、独立 token budget、独立 system prompt,而且工具访问受限,Explore / Plan 只能用只读工具,不能直接修改代码。并行也只在无依赖、只读任务中开放。
你补充的文本则进一步指出,Claude Code 的关键不在“有一堆 Agent”,而在“把研究、规划、实现、验证拆成不同职责”。这不是炫技,而是一种稳定性设计。因为让同一个 Agent 一边探索、一边设计、一边修改、一边给自己验收,往往最后每一件事都做得不够扎实。
角色拆分的本质,是把冲突任务拆开。探索阶段要保守、只读。实现阶段要敢改、敢写。验证阶段要挑刺、要怀疑。
这种分工,恰恰是传统软件工程里最朴素的经验,只是现在被重新搬进了 AI Agent 系统。
4. 验证机制:把“差不多”变成“try to break it”
我觉得你补充文本里最值钱的一个点,是把 Verification Agent 单独拎了出来。
因为 LLM 在验证阶段最容易犯的错,不是不会验证,而是“差不多就算了”。
它看一眼代码,觉得逻辑通。跑一两个测试,觉得大概没问题。UI 有 80% 正常,就忽略剩下 20%。它天然倾向于把“看起来像完成”误当成“真的完成”。
而 Verification Agent 的价值,恰恰在于它和实现者的目标不一样。实现者要交付一个能跑的结果,验证者的目标则是:try to break it。它天然应该更怀疑、更挑刺、更像传统 QA 或 code reviewer。
这件事非常关键,因为生产环境不奖励“差不多”。生产环境只认结果。系统里最终留下来的是什么状态,才是 outcome。也正因为如此,把“做事的人”和“验收的人”拆开,往往会让系统稳定性明显上一个台阶。
5. 上下文经济学:上下文不是空气,而是预算
Claude Code 真正像“操作系统”的地方,很多时候不是权限,也不是多 Agent,而是它对上下文的态度。
你补充的文本把这件事说得特别准确:system prompt 被切成静态区和动态区,方便缓存;fork path 尽量复用主线程前缀;skills 按需注入;MCP instructions 随连接状态变化;有 summarize tool results,有 function result clearing,有 compact、transcript、resume 机制。所有这些设计,都在表达同一个判断:
上下文不是空气,而是预算。
PDF 里的 auto-compact、micro-compact、section cache、DYNAMIC_BOUNDARY 也是这个逻辑。它们不只是优化 token 成本,更是在管理长期运行时的上下文质量。
这背后的深层含义是:Claude Code 不是在做一个“能跑起来”的 Agent,而是在做一个“每天大规模运行依然划算”的 Agent。
这就是产品和 demo 的差距。
6. 生命周期管理:不只关心它怎么跑起来,还关心它跑完留下什么
最后一个经常被忽视,但其实极其值钱的点,是生命周期管理。
你补充的文本里列了很多单看不惊艳、但缺了系统会迅速变脏的东西:transcript 持久化、agent metadata、性能追踪、hooks 清理、shell task 清理、todo 清理、前后台切换、中断恢复。
这些东西为什么重要?
因为很多 Agent 系统第一天都很好,问题都出在第二天、第三天和第一百天。
-
• 中断了怎么续 -
• 脏状态怎么收 -
• 子 Agent 留下的进程怎么杀 -
• 连接泄漏了怎么办 -
• 崩掉之后怎么恢复 -
• 长任务切回来时如何知道之前做到哪
如果这些问题不解决,系统永远只能停留在 prototype 阶段。Claude Code 的价值,恰恰在于它不只管“让 Agent 跑起来”,还把“它跑完之后会留下什么问题”一并纳入了系统设计。
五、Claude Code 真正抬高的,不是上限,而是下限
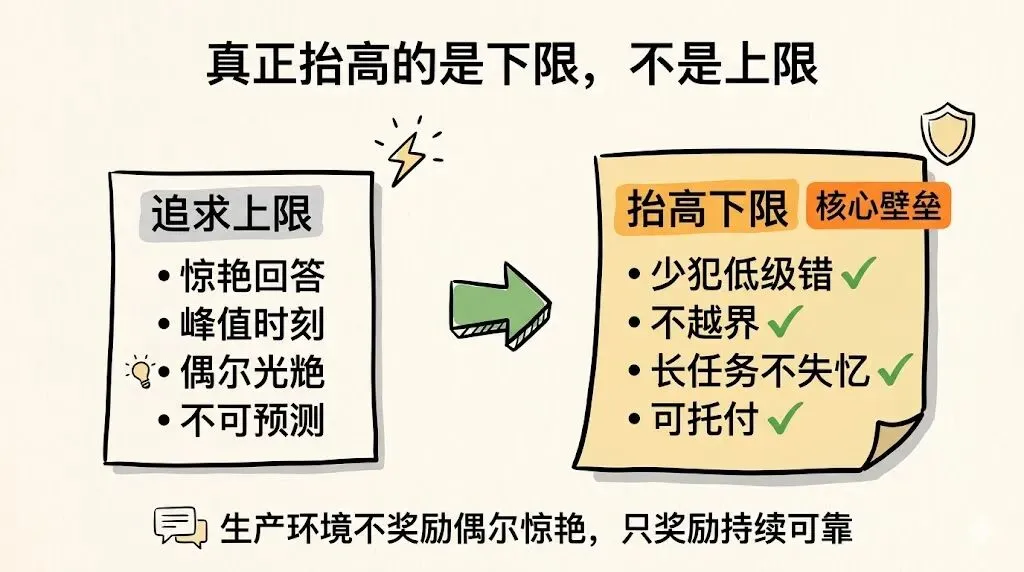
把前面这些都合起来看,我觉得 Claude Code 最值得带走的洞见可以压缩成一句话:
它真正抬高的,不是智力上限,而是系统下限。
这是一个特别值得强调的判断。
因为大家太容易被 AI 产品的“峰值时刻”带走:某次回答特别惊艳,某段代码一把写对,某个 demo 看起来像魔法一样顺滑。
但日常使用里,真正决定体验和购买决策的,往往不是这些峰值,而是另一些更朴素的东西:
-
• 少犯低级错 -
• 不轻易越界 -
• 长任务不失忆 -
• 工具调用不乱来 -
• 中断之后能恢复 -
• 验证不是走形式 -
• 结果真能落到环境里
这些都是下限问题。
而在生产环境里,下限通常比上限更重要。组织可以接受一个系统偶尔不够惊艳,但很难接受它偶尔误删目录、偶尔瞎改代码、偶尔状态漂移、偶尔说做完了但其实根本没完成。
Claude Code 的系统工程价值,恰恰就在这里:它把大量“偶尔会出事”的地方,尽量前置成制度和运行机制。它让自主性不只是“更能干”,而是“更可托付”。
六、Claude Code 给行业的真正启示:壁垒不只在模型,更在治理层
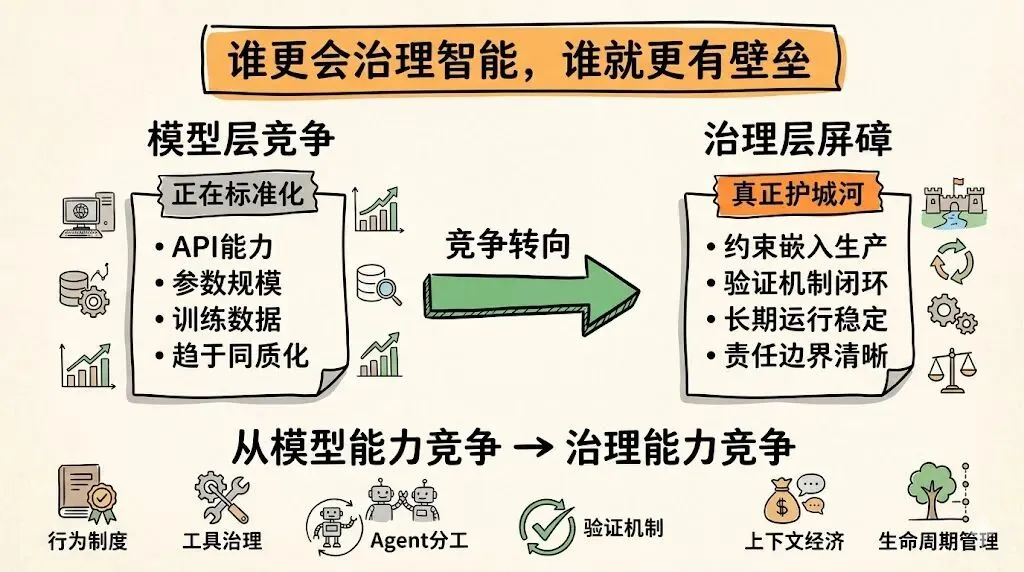
如果把视角再拉高一点,Claude Code 最值得行业认真对待的,可能还不是它本身,而是它代表了一种更大的竞争转向。
过去大家习惯把 AI 产品理解成模型的外延:模型越强,产品越强。但 Claude Code 这类系统在提醒我们,事情没有这么简单。
当底层模型能力越来越平台化之后,真正形成产品差异的,很可能不再只是“会不会生成”,而是:
-
• 能不能把智能接进真实环境 -
• 能不能给智能加上责任边界 -
• 能不能把工具变成可治理的行动面 -
• 能不能把任务拆成合适的阶段和角色 -
• 能不能让系统在长时运行中保持上下文连续性 -
• 能不能把失败、恢复、验证、记忆都纳入闭环
换句话说,未来真正形成壁垒的,不只是模型层,而是治理层。
这和云计算、容器编排、DevOps 的产业演化逻辑其实很像:当底层能力逐渐标准化,护城河就会从“有没有能力”转向“如何组织能力、约束能力、验证能力,并把能力嵌入生产体系”。
Claude Code 之所以值得研究,不在于它已经被证明绝对领先,而在于它非常清楚地暴露出一件事:
AI 编程工具的下半场,不再只是模型竞赛,而是治理竞赛。
七、最后总结:谁更会治理智能,谁就更有壁垒

如果要把整篇文章压缩成一句话,我会这样说:
Claude Code 真正厉害的,不是某段 prompt、更不是工具数量,而是 Anthropic 把行为制度、工具治理、Agent 分工、验证机制、上下文经济学和生命周期管理,做成了一套闭环系统。
也正因为如此,它带给行业最重要的启示不是“模型更强了”,而是:
当 AI 真正进入生产环境后,竞争的核心就会从“谁更会写代码”,转向“谁更会治理智能”。
未来那些真正能沉淀成壁垒的能力,很可能都长在这一层:
不是单次回答多惊艳,而是长期运行多稳定;不是模型看起来多聪明,而是系统能不能被托付;不是会不会调用工具,而是能不能在边界内把事情做完。
所以,与其说 Claude Code 像一个更强的 AI 编程助手,不如说它更像一套“治理过的执行系统”。
而这,也许才是 AI 编程行业真正开始分层的地方。
谁更会治理智能,谁就更有壁垒。