 夜雨聆风
夜雨聆风





从 Claude Code 源码学习怎么做 Agent 可观测性(下)
上篇讲了怎么给 agent observability 建模:目标分层、关联键、语义级 span、signal taxonomy(上篇链接)。这篇换个角度,聊三个更落地的工程问题。
此间的山林,公众号:此间山林从 Claude Code 源码学习怎么做Agent 可观测性(上)
上篇把建模的事说完了。但建模只是起点:trace 模型设计得再好,事件发不出去、敏感数据管不住、开关条件搞不清,实际价值就很有限。
下篇聚焦三件事:
-
可靠性与失败补偿:怎么保证不丢、不堵、不把主流程拖死。 -
隐私、字段基数与 feature gate:采集阶段的治理机制。 -
默认开关矩阵:客户端源码能直接确认的启停条件。
仍然只依据当前源码快照。暂时不去猜测源码里看不到的 collector、dashboard 和下游数仓。
一、可靠性与失败补偿
很多系统做可观测性时,默认假设是”打点失败就算了”。Claude Code 不是这样。至少从客户端源码看,它在几个关键位置把 observability 当成一条需要治理的基础设施链路。
1.1 启动早期事件不丢
analytics/index.ts 的公共入口是无依赖模块,内部带 eventQueue。sink 挂载前,logEvent() 不报错也不静默丢弃,而是先入队,等 attachAnalyticsSink() 之后再通过 queueMicrotask 异步排空。
exportfunctionattachAnalyticsSink(newSink: AnalyticsSink): void{if (sink !== null) return sink = newSinkif (eventQueue.length > 0) {const queuedEvents = [...eventQueue] eventQueue.length = 0 queueMicrotask(() => {for (const event of queuedEvents) {// drain ... } }) }}做法很朴素,但解决了一个实际问题:启动顺序可以更松,上层模块不用关心 analytics backend 是否已初始化,早期关键事件也不会因为”初始化晚一步”直接丢。对大型 CLI / agent runtime 来说,这种启动队列设计往往比”换哪家 backend”更重要。
1.2 1P event logging 带磁盘缓冲和退避重试
firstPartyEventLoggingExporter.ts 是整套可靠性设计里做得最深的一个模块。
这个 exporter 不是”POST 失败就结束”,它做了一条完整的失败补偿链路:
-
批量发送,由 OTel BatchLogRecordProcessor触发 -
失败事件写到 ~/.claude/telemetry,格式是 append-only JSONL(文件名包含 sessionId 和 batchUUID) -
下次进程启动时扫描并回放同一 session 的失败批次(按 sessionId 前缀过滤) -
发送成功后立刻尝试 drain 积压事件 -
二次退避(quadratic backoff)重试,最多 8 次( maxAttempts默认值,源码可配置) -
401 触发 auth fallback:先带 auth 发,失败后降级无 auth 重试 -
某批发送失败后,后续批次直接短路入队,不浪费请求
// Quadratic backoff (matching Statsig SDK): base * attempts²const delay = Math.min(this.baseBackoffDelayMs * this.attempts * this.attempts,this.maxBackoffDelayMs,)还有一个 killswitch 联动:每次 POST 前调 this.isKilled(),sink 被杀掉时直接抛异常('firstParty sink killswitch active'),调用方走短路逻辑把事件落盘,网络侧零流量。killswitch 清除后,backoff timer 自动恢复发送。
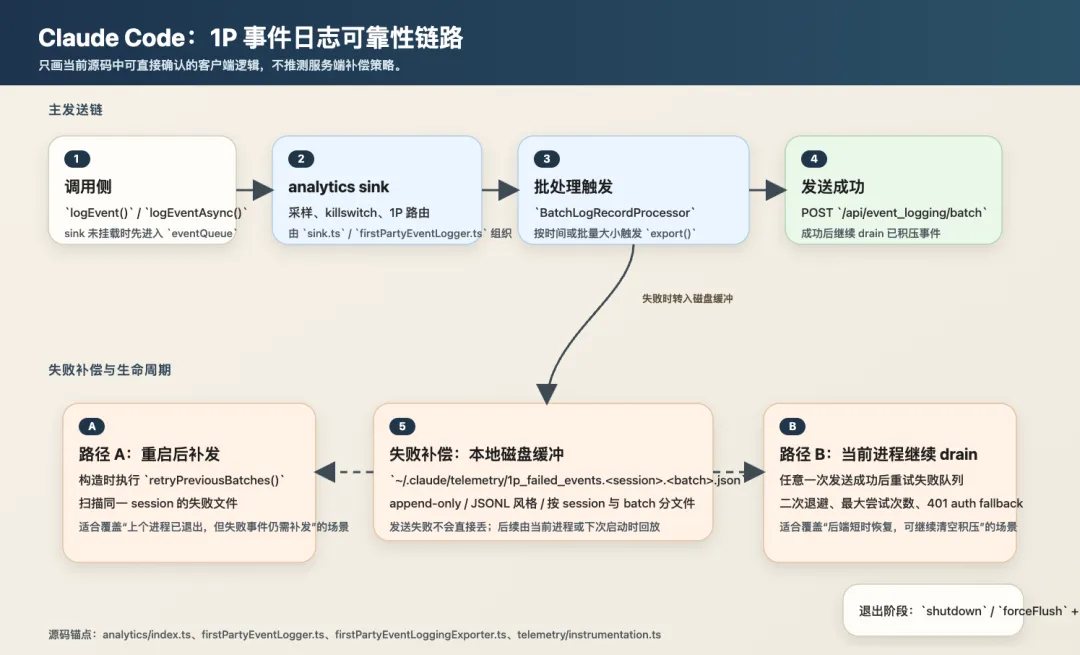
为什么对 agent runtime 特别重要?长会话、后台任务、远程模式、subagent,这些场景下最值得分析的失败信息往往出现在边缘状态和异常路径里。如果恰恰是这些事件最容易丢,整套可观测性的价值就打折扣了。
1.3 分 sink 的杀开关和采样
sink.ts 和 sinkKillswitch.ts 说明客户端自己就有按 sink 维度治理的手段。
sinkKillswitch.ts 通过 GrowthBook 动态配置(配置名 tengu_frond_boric,名字做了混淆处理)按 sink 独立控制启停:
exportfunctionisSinkKilled(sink: SinkName): boolean{const config = getDynamicConfig_CACHED_MAY_BE_STALE< Partial<Record<SinkName, boolean>> >(SINK_KILLSWITCH_CONFIG_NAME, {})return config?.[sink] === true}Datadog 受 tengu_log_datadog_events gate 和 per-sink killswitch 双重控制,1P sink 受独立 killswitch 控制;采样配置来自 tengu_event_sampling_config。两个 sink 独立启停,不是捆绑关系。
出问题时不需要全局停掉可观测性:某个 sink 故障就只关这个 sink,某类事件量太大就调 sample rate,某个后端需要保护就杀对应 fanout。该关哪个关哪个。
1.4 退出时 flush 但不卡死退出
instrumentation.ts 在退出阶段用 Promise.race 把 flush 和 timeout 放一起赛跑:
awaitPromise.race([Promise.all(flushPromises), telemetryTimeout(timeoutMs, 'OpenTelemetry flush timeout'),])timeout 之后记录诊断信息,但不阻塞退出。registerCleanup() 注册了 shutdown 逻辑,确保退出路径会尝试 flush。
1.5 trace 的生命周期管理
上篇讲了 sessionTracing.ts 的 span 模型设计(interaction → llm_request → tool 这套语义级 span)。这里补充它在可靠性层面的处理。
activeSpans 用 WeakRef 保存 span context,strongSpans 用强引用保存不在 AsyncLocalStorage 里的 span(LLM request、blocked-on-user、tool execution、hook)。ensureCleanupInterval() 每 60 秒扫描一次,用 30 分钟 TTL(SPAN_TTL_MS = 30 * 60 * 1000)清理 orphaned span:
functionensureCleanupInterval(): void{// ...const interval = setInterval(() => {const cutoff = Date.now() - SPAN_TTL_MSfor (const [spanId, weakRef] of activeSpans) {const ctx = weakRef.deref()if (ctx === undefined) { activeSpans.delete(spanId) strongSpans.delete(spanId) } elseif (ctx.startTime < cutoff) {if (!ctx.ended) ctx.span.end() activeSpans.delete(spanId) strongSpans.delete(spanId) } } }, 60_000)if (typeof interval.unref === 'function') { interval.unref() // 不阻塞进程退出 }}源码注释写得很直接:这是 “safety net for spans that were never ended”。aborted streams、uncaught exceptions、mid-query 中断,在 agent runtime 里这些不是边缘情况,更像常态。
不做这种治理,长会话很快会出两类问题:span 没结束导致内存堆积;异步上下文错乱导致后续事件挂到错误父节点。”可靠性”不仅是”网络发不发得出去”,也包括”本地观测状态会不会反噬 runtime 本身”。
1.6 可靠性设计的整体思路
把这几个点串起来看:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
不是”尽力而为的附加日志”,显然是一条明确做过治理的基础设施链路,踩过不少坑的经验。
二、隐私、字段基数与 feature gate
这套可观测性设计里有一点值得单独拿出来说:治理逻辑不是事后补的,采集阶段就开始生效。
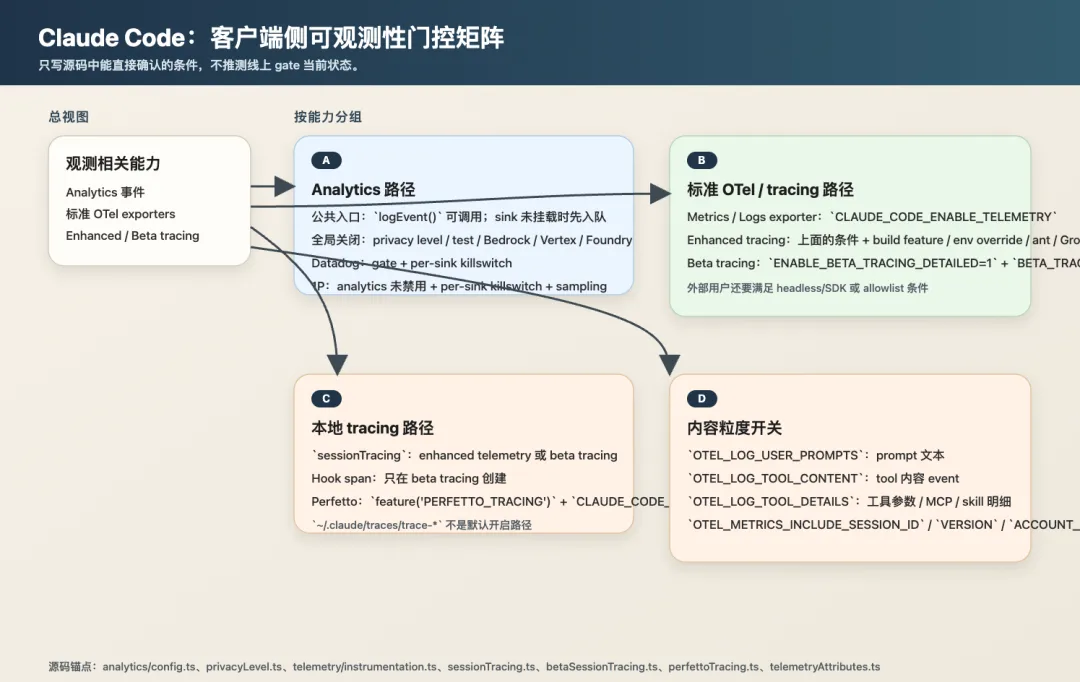
2.1 privacy level 直接决定链路启停
privacyLevel.ts 定义了三档:
type PrivacyLevel = 'default' | 'no-telemetry' | 'essential-traffic'no-telemetry 禁用 analytics 和 telemetry(由 DISABLE_TELEMETRY 环境变量触发)。essential-traffic 更激进,禁止所有非必要网络流量(由 CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC 触发),源码注释列出的范围包括自动更新、grove、release notes、model capabilities 查询等。
配合 config.ts(isAnalyticsDisabled()),test 环境、Bedrock / Vertex / Foundry 场景下 analytics 也会被完全禁用。
隐私限制在这里不是”少发几条日志”的意思,它直接决定整条可观测性链路开还是关。
2.2 字符串不是默认就能打出去
logEvent() 的类型约束是我觉得这套设计里比较巧妙的一个点。
默认 event metadata 限制为 boolean、number、undefined(类型定义 LogEventMetadata)。字符串要进来,必须显式声明已验证不包含代码片段或文件路径:
exporttype AnalyticsMetadata_I_VERIFIED_THIS_IS_NOT_CODE_OR_FILEPATHS = never名字看着像玩笑,意图很认真:限制误把 prompt、代码、路径打进 analytics;把”我确认这能发”变成显式动作;让隐私治理在编码阶段发生,不是上线后靠审计补救。
另一个配套的 marker type 是 AnalyticsMetadata_I_VERIFIED_THIS_IS_PII_TAGGED,用于标记允许进入 1P 特权列(源码注释描述为 “PII-tagged proto columns”,对应 BQ 的 privileged access columns)的值。两个 marker type 分别控制通用后端和特权后端的数据边界。
2.3 _PROTO_*:单点可信的分层脱敏
_PROTO_* 的设计思路是:不让所有 sink 收到同一份 payload 再各自决定怎么脱敏,反过来做。
-
普通后端绝不能看到 _PROTO_*字段 -
sink.ts在 Datadog fanout 前统一调stripProtoFields() -
只有 1P exporter 拿到完整 payload,再把 _PROTO_*字段提升到 proto 顶层字段
// sink.tsif (shouldTrackDatadog()) {// Datadog is a general-access backend — strip _PROTO_*void trackDatadogEvent(eventName, stripProtoFields(metadataWithSampleRate))}// 1P receives the full payload including _PROTO_*logEventTo1P(eventName, metadataWithSampleRate)只要统一 fanout 点没漏,通用后端就不会意外收到高敏感字段。比让每个 sink 自己记得过滤靠谱得多。
1P exporter 那边也做了防御:已知的 _PROTO_skill_name、_PROTO_plugin_name、_PROTO_marketplace_name 提升到 proto 顶层字段后,对剩余 metadata 再跑一次 stripProtoFields(),防止未来新增的 _PROTO_* key 意外落进 additional_metadata。
2.4 内容粒度开关
高价值内容不是默认就全采上来的。当前源码能确认若干显式开关:
|
|
|
|---|---|
OTEL_LOG_USER_PROMPTS |
|
OTEL_LOG_TOOL_CONTENT |
|
OTEL_LOG_TOOL_DETAILS |
|
OTEL_METRICS_INCLUDE_SESSION_ID |
|
OTEL_METRICS_INCLUDE_VERSION |
|
OTEL_METRICS_INCLUDE_ACCOUNT_UUID |
|
agent 和普通 web service 不一样,最有价值的数据往往也是最敏感的:用户 prompt、工具参数、shell 命令、tool output。没有细粒度开关,要么采得太少没分析价值,要么采得太多难以治理。
2.5 Beta tracing 按用户类型分层
betaSessionTracing.ts 对不同用户类型暴露不同内容(源码文件头部注释的 Visibility Rules 表):
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Thinking output 只对内部用户可见。做 agent 观测的时候,这提醒我们内容可见性不只是开关两个状态,也可以按用户群体分层。
一个实现细节:beta tracing 用 hash-based 去重(seenHashes: Set<string>)来避免重复发送 system prompt 和 tool schema。源码注释的原话:”System prompts and tool schemas are large and rarely change within a session. Sending full content on every request would be wasteful.” 所以只在内容首次出现时发完整数据,后续请求只发 hash,这样应该能显著节省流量。
2.6 Taxonomy 在采集点就生效
上篇提到 metadata.ts 里对 MCP 工具名的处理(sanitizeToolNameForAnalytics()),这里补充一点:这种 taxonomy 约束不只是分类,它会直接限制哪些信息能被采集出去。
用户自定义的 MCP server 名可能包含个人信息,不可不防。默认收敛成 mcp_tool,只有在满足特定条件时(如 claude.ai connector 或 allowlist 注册的 server)才放更细的名字出去。Taxonomy 在采集点就开始生效。
2.7 治理机制的分层
把这些治理手段按层次整理:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
_PROTO_*
|
|
|
|
OTEL_LOG_*
|
|
|
|
|
|
|
|
|
|
|
|
OTEL_METRICS_INCLUDE_* |
|
每一层管自己的事,各有各的粒度。
三、默认开关矩阵
这一节我也只写客户端源码能直接确认的启停条件。不推测服务端默认值,也不推测某个 GrowthBook gate 在生产环境里到底开没开。
GrowthBook 是一套开源的 feature flag / experimentation / remote config 平台
3.1 产品事件与 analytics sink
|
|
|
|---|---|
|
|
|
|
|
tengu_log_datadog_events
|
|
|
|
|
|
tengu_event_sampling_config
|
“事件能不能被调用”和”最终会不会被送到某个后端”是两层不同的问题。logEvent() 总能调用成功(最差入队),但事件最终送到 Datadog 还是 1P、还是两个都不送,取决于 gate、killswitch、privacy level 的组合状态。
3.2 标准 OTel telemetry
|
|
|
|---|---|
|
|
CLAUDE_CODE_ENABLE_TELEMETRY |
|
|
CLAUDE_CODE_ENABLE_TELEMETRY
isEnhancedTelemetryEnabled() |
|
|
|
|
|
ENABLE_BETA_TRACING_DETAILED=1
BETA_TRACING_ENDPOINT;外部用户还要满足 headless/SDK 或 tengu_trace_lantern allowlist |
标准 OTel tracing 开了 telemetry 也不会自动全开,它还叠加了 enhanced telemetry 这一层。isEnhancedTelemetryEnabled() 的优先级链是:
-
如果 build feature ENHANCED_TELEMETRY_BETA存在: -
env var显式关闭 → 关 -
env var显式开启 → 开 -
ant 用户 → 开 -
否则走 GrowthBook gate enhanced_telemetry_beta -
如果 build feature 不存在 → 关
Beta tracing 又在 enhanced telemetry 之上再叠一层,需要同时满足 ENABLE_BETA_TRACING_DETAILED=1 和 BETA_TRACING_ENDPOINT。外部用户还有额外条件:必须是 headless/SDK 模式(getIsNonInteractiveSession()),或者组织通过 tengu_trace_lantern GrowthBook gate 被 allowlist。
exportfunctionisBetaTracingEnabled(): boolean{const baseEnabled = isEnvTruthy(process.env.ENABLE_BETA_TRACING_DETAILED) &&Boolean(process.env.BETA_TRACING_ENDPOINT)if (!baseEnabled) returnfalseif (process.env.USER_TYPE !== 'ant') {return ( getIsNonInteractiveSession() || getFeatureValue_CACHED_MAY_BE_STALE('tengu_trace_lantern', false) ) }returntrue}3.3 本地 tracing
|
|
|
|---|---|
|
|
|
|
|
|
|
|
feature('PERFETTO_TRACING')
CLAUDE_CODE_PERFETTO_TRACE,ant-only build |
~/.claude/traces/trace-* 这条路径不是默认开启的。明确 opt-in,Perfetto 的源码注释也写得很清楚:”This feature is ant-only and eliminated from external builds”。推测主要用于性能诊断。
3.4 内容粒度
|
|
|
|---|---|
|
|
OTEL_LOG_USER_PROMPTS |
|
|
OTEL_LOG_TOOL_CONTENT |
|
|
OTEL_LOG_TOOL_DETAILS |
|
|
OTEL_METRICS_INCLUDE_SESSION_ID |
|
|
OTEL_METRICS_INCLUDE_VERSION |
|
|
OTEL_METRICS_INCLUDE_ACCOUNT_UUID |
客户端在”是否采集”和”采集到什么粒度”之间做了两层分离。
3.5 开关之间的层级关系
把上面的矩阵画成依赖图会更清楚:
privacy level (链路总开关) └── CLAUDE_CODE_ENABLE_TELEMETRY (OTel 总开关) ├── metrics / logs exporter └── isEnhancedTelemetryEnabled() (tracing 附加条件) ├── sessionTracing span 模型 └── isBetaTracingEnabled() (详细 tracing 附加条件) ├── hook span ├── system prompt 去重记录 └── 内容可见性矩阵 (ant vs external)analytics sink (独立链路) ├── Datadog (gate + killswitch) └── 1P (killswitch + 采样)Perfetto (完全独立,ant-only build feature)理解这个层级结构,是排查”为什么没数据”的前提。可观测性行为同时受 USER_TYPE、feature('...')、privacy level、env var、GrowthBook、sink killswitch 影响。灵活是灵活了,但排查链路也会更长。
写在最后
上篇讲的是建模:怎么把 agent runtime 的语义映射成可观测的结构。这篇讲的是工程:怎么让这套结构在真实环境里可靠运行、可控治理。
几个我觉得值得带走的点:
-
可靠性是一组机制叠出来的,不是靠某个单点设计。启动队列、磁盘缓冲、退避重试、flush timeout、span TTL cleanup,缺了哪个都会在某个场景下漏事件。
-
治理要前置到采集阶段。marker type、
_PROTO_*分层、内容粒度开关、用户分层可见性,等到下游平台再做脱敏就晚了。 -
开关之间有层级关系。不理解 privacy level → telemetry → enhanced telemetry → beta tracing 这条依赖链,就很难排查”为什么没数据”。
上下两篇提到的源码大多在 services/analytics/ 和 utils/telemetry/ 两个目录下。如果你想直接看这些 session 数据长什么样,可以试试 TMA1[1],一行命令装上,agent 跑一次就有数据了。
TMA1: https://github.com/tma1-ai/tma1