 夜雨聆风
夜雨聆风





扒完Claude Code源码,我看到了Agentic Harness设计的尽头
大家好,我是PaperAgent,不是Agent!
昨天,Anthropic 的 Claude Code 源码被动开源了,想必大家都刷到了。76k star了
从 cli.js.map 还原出 4756 个源文件后,我连续几周泡在这堆代码里,像考古一样把它的系统提示词、Agent 调度链、工具执行管道、权限模型、Hook 机制、Skill 生态……一块块拆开来看。美团LongCat-Next这波开源突破,挺出乎意料的~
说实话,扒之前我预想过它很强。但扒完之后,我的感受远不只是“强”——我看到的是一个设计理念上的代际差。
很多人以为 Claude Code 强在模型本身,或者强在某一段“神秘的 system prompt”。但真正扒开源码后你会发现:这些都不对。
它的强,来自一套被精心设计、工程化落地的 Agentic Harness。大模型冗余Token的问题被破解了
这个概念不是我自己编的。Anthropic 官方文档里写得清清楚楚:
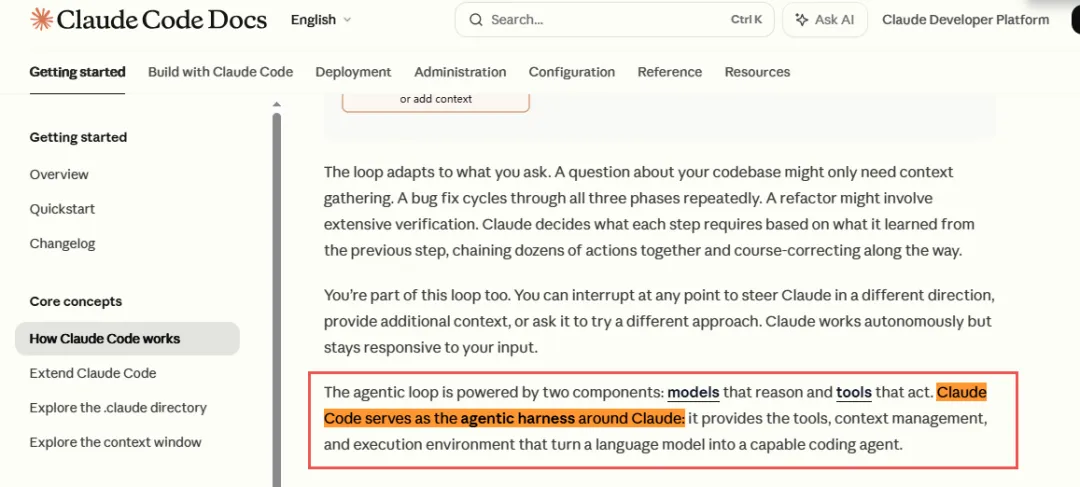
翻译过来就是:Claude Code 整个系统,就是套在 Claude 外面的那个 Harness。Anthropic:模型是壁垒?不,Harness 才是
它提供的不只是一个聊天界面,而是一整套“让模型变成可执行 Agent”的运行时框架:工具怎么调用、权限怎么控制、上下文怎么管理、子任务怎么编排、钩子怎么拦截……全都在这层 harness 里被制度化、产品化了。
很多人复刻 coding agent 时,只拿走了一个 system prompt + 文件编辑工具 + Bash + CLI 壳。但扒完 Claude Code 的源码后我意识到:真正拉开差距的,根本不是这几样东西。
今天这篇文章,我就把自己在源码里看到的那些“真正的差距”,掰开揉碎了讲给你听。

01 它不是一段 Prompt,而是一个 Operating Model
先看一个最容易被误解的问题:Claude Code 的 system prompt 到底有多神秘?
我一开始也以为,扒开 prompts.ts 就能看到一篇“神谕”。但实际打开之后,我看到的是一套 Prompt Assembly Architecture。
getSystemPrompt() 根本不是返回一段静态文本,它干的事情远比这复杂:
-
先拼静态前缀:身份定位、系统规范、任务哲学、风险动作规范、工具使用规范…… -
再注入动态后缀:session guidance、memory、MCP instructions、scratchpad、token budget、output style……
而且源码里明确存在 SYSTEM_PROMPT_DYNAMIC_BOUNDARY,注释直接写明:边界前尽量可 cache,边界后是会话特定内容,不能乱改,否则破坏 cache 逻辑。
这意味着什么?
意味着 Anthropic 连 system prompt 的 token 成本与缓存命中 都做了工程化优化。他们不是把“能想到的都塞进 prompt”,而是把 prompt 当作可编排的运行时资源来管理。
静态部分适合 cache,动态部分按需注入。这种做法在成本控制上,比“一把梭”的提示词高出不止一个维度。
但这只是冰山一角。
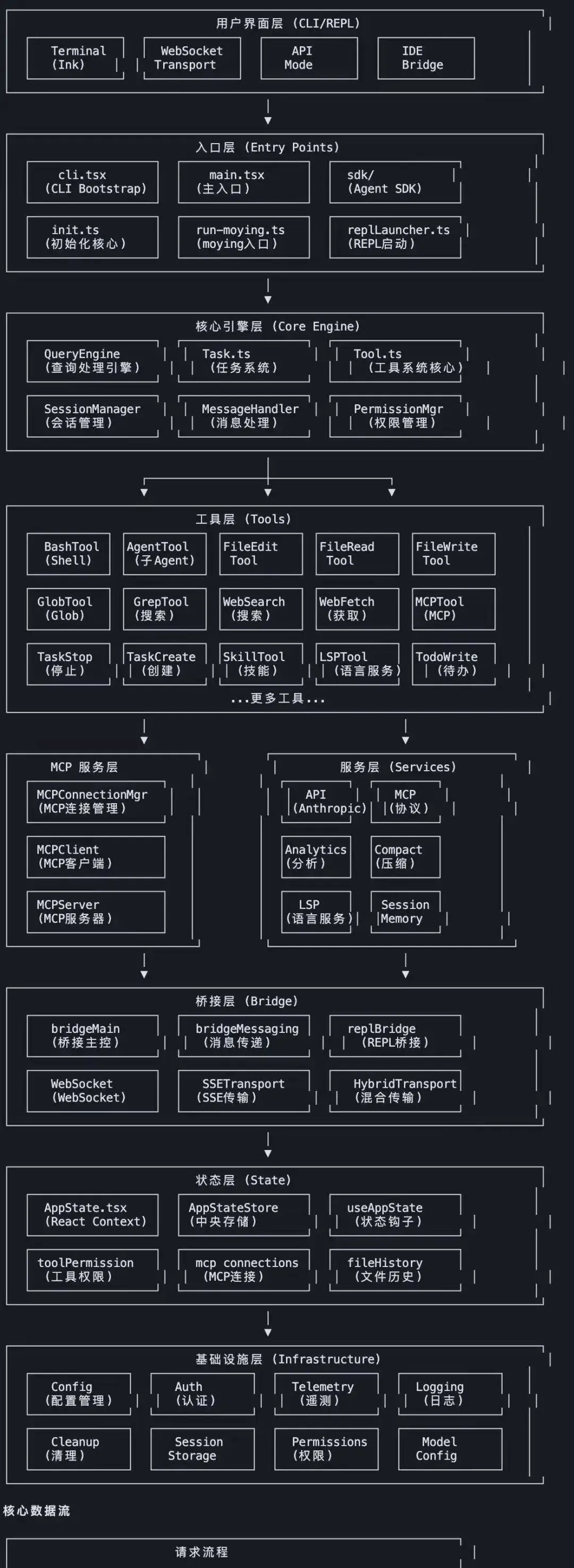
02 它把好行为制度化了
再看一个让我印象深刻的细节:getSimpleDoingTasksSection() 这一段,基本可以看作 Anthropic 对 AI 工程师行为规范的制度化表达。
它非常明确地约束模型:

这一段的意义,远不止“prompt 写得细”。它揭示了一个本质:Claude Code 不把“好习惯”交给模型即兴发挥,而是写进规则里,强制执行。
很多 coding agent 不稳定,不是因为模型不会写代码,而是因为行为发散。同一个需求,今天能跑通,明天可能就给你来一轮“过度重构 + 加一堆注释 + 顺便改个无关文件”的骚操作。
Claude Code 用这套制度化的约束,把行为方差压到了最低。
同样制度化的,还有风险动作规范:destructive operations、hard-to-reverse operations、修改共享状态、上传第三方工具……全部被标记为“需要确认”。源码里明确要求:发现陌生状态先调查,merge conflict/lockfile 不要粗暴删。
这是一种 blast radius 思维——把“破坏范围”写进模型的行为准则里。
03 它特别懂上下文是稀缺资源
扒源码的过程中,另一个让我反复感叹的点是:Anthropic 对上下文的珍惜程度,远超大多数人的想象。
大量设计都在围绕上下文做优化:
-
system prompt 的动静边界 + cache boundary -
fork path 共享父线程的 prompt cache -
skill 按需注入,不塞进全局 prompt -
MCP instructions 按连接状态动态注入 -
function result clearing、summarize tool results -
compact / transcript / resume 机制
其中 fork path 的设计尤其精妙。
当模型决定 fork 一个子 agent 时,源码里会走一条专门优化过的路径:继承父线程的 system prompt 和 tool defs,保持 API request prefix byte-identical,从而提高 prompt cache 命中率。
注释里写得很直白:fork 很便宜,因为共享 prompt cache。
这是什么级别的优化?
普通人只想着“子任务能跑就行”,Claude Code 想的是“子任务能跑,而且尽量复用主线程 cache,不白烧 token”。
这是产品级系统思维,不是 demo 级实现。
04 Agent 分工:不是万能 Worker,而是 Specialist
很多人以为 Claude Code 的 Agent 就是一个“万能 worker”——给个任务,它自己去拆、去执行、去验证。
但扒开 built-in agents 后我发现:完全不是这样。
源码里至少定义了这几个内建 Agent:
-
Explore Agent:纯读模式,专门做代码探索。它的 system prompt 明确规定——不能创建文件、不能修改、不能删除、不能移动、不能用重定向写文件,Bash 只允许 ls、git status、git log、git diff、find、grep、cat、head、tail 这些读操作。 -
Plan Agent:纯规划,不做编辑。它的职责是先理解需求、探索代码库、输出 step-by-step implementation plan,最后必须列出 Critical Files for Implementation。 -
Verification Agent:这是我最惊艳的一个。它的 system prompt 开头就点明——你的工作是 try to break it。不是“确认实现看起来没问题”,而是主动找茬。它强制要求:跑 build、跑 test suite、跑 linter/type-check、做专项验证、跑浏览器自动化或 curl 实测、输出每个 check 的 command 和 observed,最后必须输出 VERDICT: PASS / FAIL / PARTIAL。
这套设计解决了一个很多系统长期存在的问题:一个 agent 既研究、又规划、又实现、又验收,最终哪件事都不够稳定。
Claude Code 的选择是:明确分工。Explore 只管读,Plan 只管规划,Verification 只管破坏性验证,通用任务交给 General Purpose Agent。
这不是“多了三个 agent”的问题,而是架构上的 specialization 思维。
05 调度链:AgentTool → runAgent → query
扒完 Agent 调度链后,我对“Agentic Harness”这个词的理解又深了一层。
整个链路可以抽象成:

AgentTool.call() 的职责远超“转发到子 agent”——它本质上是 agent orchestration controller,要处理权限过滤、MCP 依赖、worktree isolation、foreground/async 任务注册等一堆事情。
而 runAgent() 则是一个完整的 子 agent runtime constructor:初始化 agent-specific MCP、过滤 context messages、处理 read-only agent 的 claudeMd slimming、构造 permission mode、执行 SubagentStart hooks、预加载 frontmatter skills、合并 agent MCP tools、最后调用 query() 进入主循环。
最让我感慨的是,源码里还有大量产品级细节:recordSidechainTranscript、writeAgentMetadata、registerPerfettoAgent、cleanupAgentTracking、killShellTasksForAgent、清理 cloned file state、清理 todos entry……
Anthropic 不是只让 subagent“跑起来”,而是把 transcript、telemetry、cleanup、resume 都纳入正式生命周期。
这才是产品级的 runtime。
06 Skill、Plugin、Hook、MCP:不是可安装,而是模型可感知
很多系统也有插件、有工具、有外部协议,但模型本身不知道:有哪些扩展、什么时候该用、怎么用。
Claude Code 不一样。
通过 skills 列表、agent 列表、MCP instructions、session-specific guidance、command integration,它让模型知道自己的扩展能力是什么。
Skill 不是说明文档,而是一个 prompt-native workflow package:markdown prompt bundle + frontmatter metadata + 可声明 allowed-tools,按需注入当前上下文。
Plugin 不只是外挂,而是 prompt + metadata + runtime constraints 的扩展机制。
Hook 是 runtime governance layer:PreToolUse 可以改写输入、直接给 allow/ask/deny、甚至 preventContinuation;PostToolUse 还能追加 message、注入 additional context。
MCP 不只是工具桥,还能同时注入工具 + 如何使用这些工具的说明——getMcpInstructionsSection() 会把这些 instructions 拼进 system prompt。
这意味着 MCP 的价值远高于简单 tool registry,它同时是 behavior specification channel。
07 工具执行链:不是直调,是 Pipeline
最后一个让我印象深刻的部分,是 toolExecution.ts 里的工具执行链路。
它不是“模型决定 → 直接跑函数”。实际链路大致是:

这是一条标准的 runtime pipeline,不是直连函数调用。
其中 PreToolUse hooks 的拦截能力非常强:hook 可以改写输入(updatedInput)、直接给出 permissionBehavior(allow/ask/deny)、甚至 preventContinuation——即使没 deny,也能阻止流程继续。
而 resolveHookPermissionDecision() 这层逻辑确保了:hook 的 allow 不自动绕过 settings 规则,如果需要 user interaction 而 hook 没提供 updatedInput,仍要走统一 permission flow。
Hook 很强,但没有绕开核心安全模型。
尾声:Agentic Harness 设计的尽头
扒完这 4756 个文件后,我一直在想一个问题:Agentic Harness 设计的尽头到底是什么?
如果让我用一句话回答,我会说:
是把 prompt architecture、tool runtime、permission model、agent orchestration、skill packaging、plugin system、hooks governance、MCP integration、context hygiene 和 product engineering 全部统一起来的那个系统。
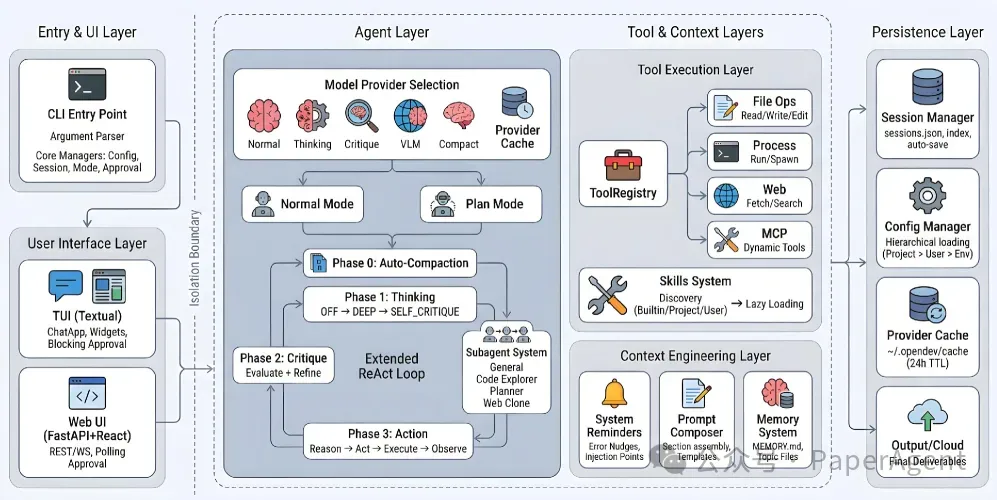
很多人复刻 coding agent 时,只会拿走:
-
一个 system prompt -
一个文件编辑工具 -
一个 bash 工具 -
一个 CLI 壳
但 Claude Code 真正的护城河,是那层把它们全部制度化、工程化、产品化的 Harness。
少一个环节,体验都会掉一档。而把它们全部做对、做深、做到能大规模稳定运行,需要的远不止“写 prompt”的能力,而是一整套系统架构思维。
这也许就是 Agentic Harness 设计的尽头:不是更聪明的模型,而是更完整的系统。
https://github.com/instructkr/claw-codehttps://github.com/tvytlx/claude-code-deep-dive每天一篇大模型Paper来锻炼我们的思维~已经读到这了,不妨点个👍、❤️、↗️三连,加个星标⭐,不迷路哦~