 夜雨聆风
夜雨聆风





我用GLM-5.1做了两个App,一个人干了一个小团队的活
上周,智谱发了一条公众号说全体coding plan用户可以用上最新的旗舰模型GLM-5.1了,包括Lite用户。没有预热,没有发布会,直接让你用。 我当时正在用OpenClaw给自己的开源阅读器加功能。
我当时正在用OpenClaw给自己的开源阅读器加功能。
看到这条消息十分惊喜,因为我的Lite套餐也能用上了,我立马把配置文件里的模型切换成了glm-5.1,继续干活。
事情就是从这次切换开始变得不一样的。
先说背景
我之前写过几篇关于OpenClaw的文章。简单讲,OpenClaw是一个开源的AI中层管理工具,你用聊天软件给它发消息,它去调度你电脑上的AI工具干活。我一直拿它搭配Claude Code来做一些开发任务。
但这次我换上了GLM-5.1,因为Coding Plan的价格比其他方案便宜太多,而且我想亲自试试这个模型到底行不行。
结果这一试,我在接下来几天里,用它做了两个完整的App。
给阅读器完善了一套AI系统
我之前做了一个开源的AI阅读器叫PaperTok Reader。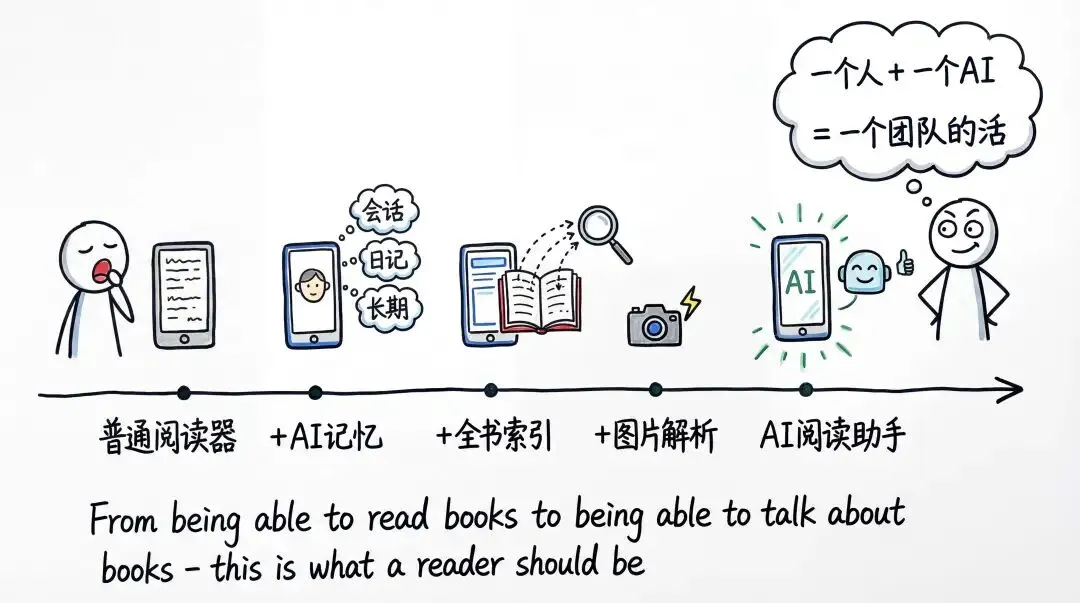 我一直想给它的AI能力加上AI记忆和全书索引以及图片解释等功能,但工程量太大,这些功能要是我自己做,至少要排几周的开发周期。
我一直想给它的AI能力加上AI记忆和全书索引以及图片解释等功能,但工程量太大,这些功能要是我自己做,至少要排几周的开发周期。
光是AI记忆系统这一个模块,就涉及会话内上下文、每日日记、长期记忆三层结构,还要做候选记忆的审阅机制,防止没用的信息写进记忆库。全书索引要做文本分块、向量化、语义检索和引用回链四个环节。图片解析和快捷指令又各自是独立的功能模块。按照AI的粗略估算,这些功能加起来涉及大约15到20个独立的功能模块,如果按传统开发节奏,一个3人小团队大概需要3到4周才能完成。
我把需求发给OpenClaw,让GLM-5.1来做。
第一个让我意外的地方出现了。它没有直接开始写代码,而是先花了几分钟做了一份完整的技术方案。它把AI记忆系统拆成了数据模型层、服务层、ViewModel层和视图层,每一层的职责写得很清楚,然后按照依赖关系排好了开发顺序。
这个行为跟之前用的模型完全不同。以前的模型拿到需求就开始写,如果写到一半发现架构有问题再推倒重来,反复几次人就疲了。GLM-5.1拿到任务之后先想了一会儿,然后才动手。就这一个区别,后面省了很多返工的时间。
它开始一步一步推进。先搭数据结构,再写服务层逻辑,然后做ViewModel的状态管理,最后把视图层接上。中间有一个地方,候选记忆写入长期记忆的时机控制出了问题,会话上下文和长期记忆发生了冲突。它自己看了报错日志,分析了原因,调整了写入时机的判断逻辑,改完之后继续往下走。全程我没有介入。
AI记忆做完之后,我继续让它做AI全书索引功能。这个功能的核心是对一整本书进行embedding检索,用户问一个问题,AI能在整本书里找到相关的段落,给出有依据的回答,并且能指回具体的章节位置。
GLM-5.1用了大概两个多小时把这套链路跑通了。中间它做了一个我觉得挺聪明的决定,把引用回链的定位精度和检索速度做了一个权衡,选择了一个在移动端体验最好的方案。这种主动做取舍的能力,是我在之前用其他模型时比较少见到的。
后面我又让它做了AI图片解析和快捷指令两个模块。图片解析让用户可以把截图、拍照、图表直接发给AI进行分析。快捷指令让用户在iOS系统的任何地方都能通过分享面板把内容发给阅读器的AI助手,省去了复制粘贴的繁琐操作。快捷指令这个模块还做了冷启动防丢单的处理,即使App没有打开,分享过来的内容也会先排队,等App启动后再发送。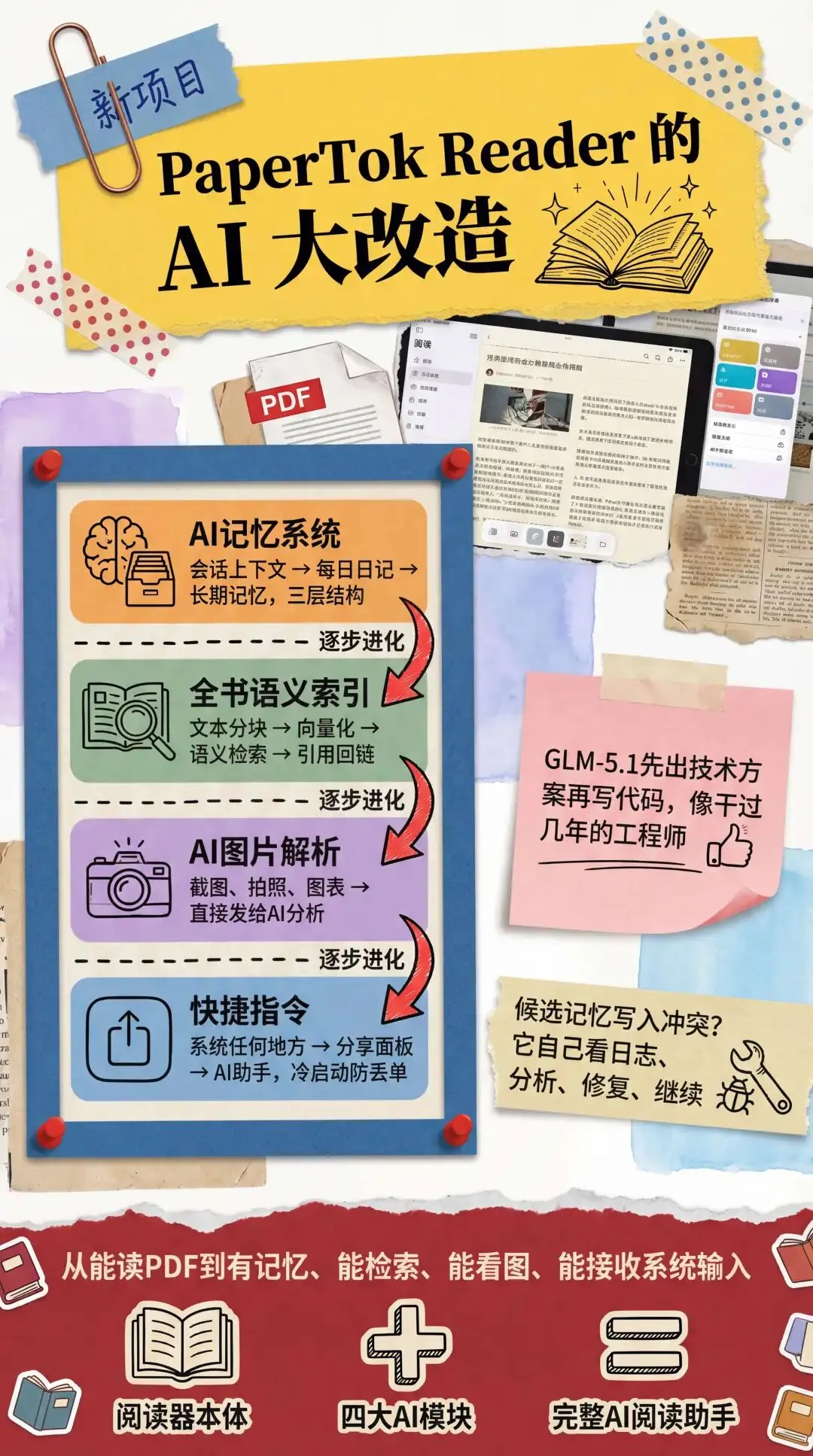 整个阅读器的AI升级,GLM-5.1前后持续运行了大约二十几个小时,累计新增和修改了大约21000行代码。这些功能加在一起,PaperTok Reader变成了一个有记忆、能检索整本书、能理解图片、能接收系统级输入的AI阅读助手。
整个阅读器的AI升级,GLM-5.1前后持续运行了大约二十几个小时,累计新增和修改了大约21000行代码。这些功能加在一起,PaperTok Reader变成了一个有记忆、能检索整本书、能理解图片、能接收系统级输入的AI阅读助手。
让视频和音频变成可以对话的知识材料
做完阅读器的升级,我开始做第二个工具。
我平时会看大量的播客和视频课程。最大的痛点是,看完之后很多内容记不住,想回顾的时候又不知道关键信息在哪个时间点。传统的播放器只解决了看和听的问题,但在学习和研究的场景里,我真正需要的是理解和对话。
所以我想做一个工具,能把视频和音频的内容转成文稿,然后围绕文稿进行AI问答。你可以问它,这段视频的核心观点是什么,作者在第几部分讨论了某个概念,帮我把这一段整理成结构化摘要。AI的回答能指回文稿里的具体位置,点一下就能跳到对应的时间点。
这个工具我叫它MediaTalk。
MediaTalk的搭建,涉及5个核心模块。它需要一个基于VLC的播放引擎来兼容各种媒体格式,一个基于WhisperKit的端侧转写模块把音视频变成文字,一个文稿管理系统来组织转写结果,一个上下文装配模块从文稿里抽取和用户问题最相关的片段,最后还有一个完整的AI对话层把这些能力串起来。
我把整个需求描述发给了GLM-5.1,它做的第一件事还是先输出技术方案。它把整个App拆成了五个核心模块,按照依赖关系画好了开发路径,然后一个模块一个模块地推进。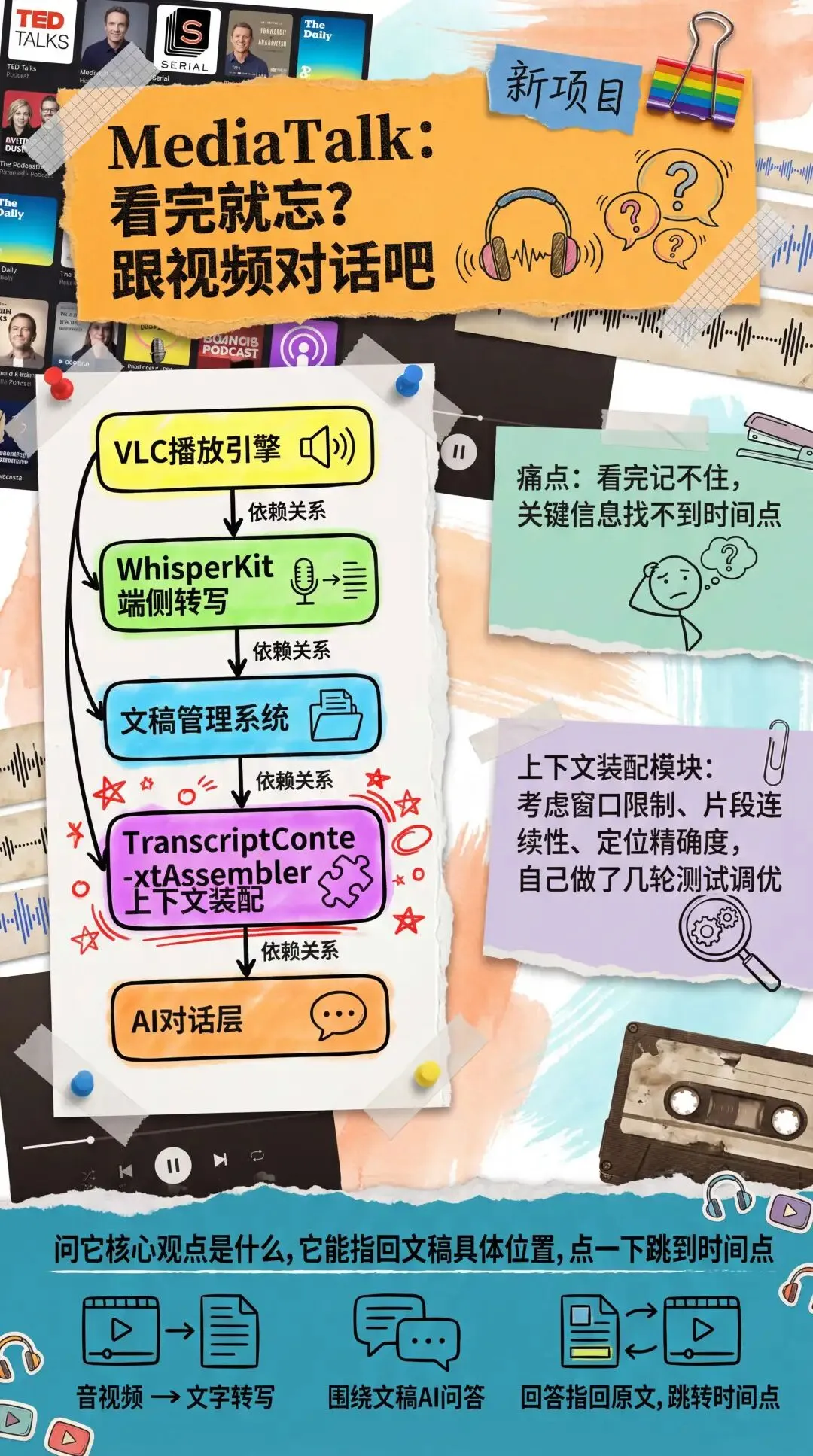 MediaTalk的整条开发链路,我跟GLM-5.1对话了12次,持续运行了大约18个小时,累计生成了约1600行代码,覆盖了从播放引擎到AI对话的完整功能骨架。
MediaTalk的整条开发链路,我跟GLM-5.1对话了12次,持续运行了大约18个小时,累计生成了约1600行代码,覆盖了从播放引擎到AI对话的完整功能骨架。 从播放引擎到转写链路到文稿管理到AI对话,整条链路跑通之后,MediaTalk已经具备了一个可用产品的骨架。
从播放引擎到转写链路到文稿管理到AI对话,整条链路跑通之后,MediaTalk已经具备了一个可用产品的骨架。
长程任务这件事,为什么重要
做完这两个App之后,我回过头来想,这次的体验跟之前到底有什么不同。
我总结了一下,核心区别在四个字,长程任务。GLM-5.1在这一点上给我的感受确实不太一样。
它记得前面做了什么。开发阅读器AI记忆模块的时候,它在第七步还能准确引用第二步定义的数据结构。开发MediaTalk的时候,它在做AI对话层的时候还记得播放引擎层的接口定义。
它知道现在在哪一步。每完成一个阶段,它会自己回顾进度,确认当前状态,然后规划下一步。不需要我说,该做下一个模块了。
它能处理中途出现的意外。开发过程中遇到的报错、冲突、兼容性问题,它自己排查、自己修复、自己继续。不是那种遇到问题就停下来问你怎么办的模式。
这三个能力加在一起,就是长程任务能力。它意味着你可以给AI一个完整的目标,它自己拆解步骤、持续推进、处理异常、最终交付结果。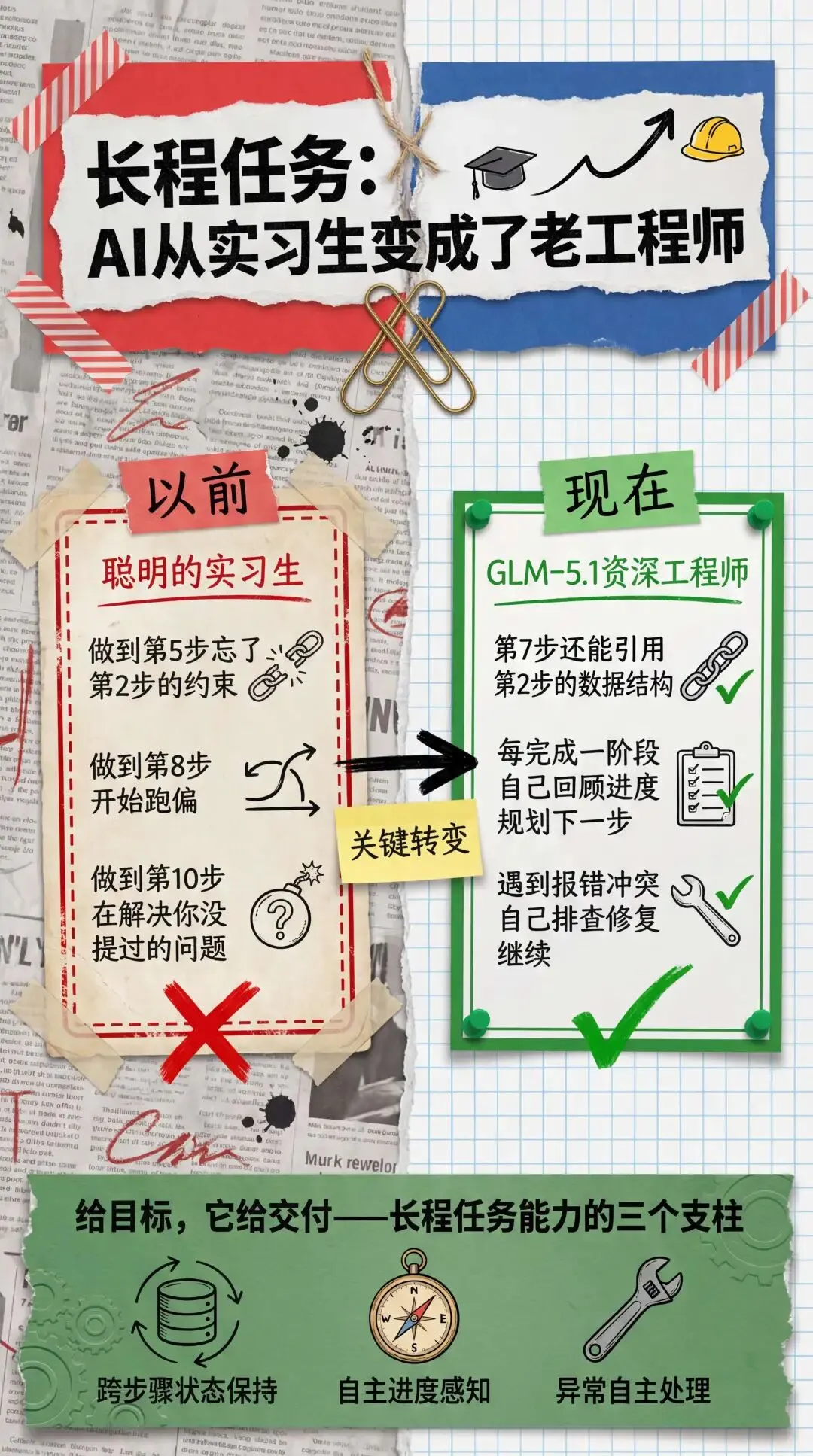 两个App加起来,GLM-5.1累计持续运行超过40小时,单次最长的长程任务一次在后台持续运行了5个多小时,跨越了30多个开发步骤,生成了约2万行代码。这个工作量放在传统开发模式下,大约相当于一个3人开发团队一个月的产出。当然,后续的打磨和测试还需要不少时间,但从零到一的搭建阶段,确实被大幅压缩了。
两个App加起来,GLM-5.1累计持续运行超过40小时,单次最长的长程任务一次在后台持续运行了5个多小时,跨越了30多个开发步骤,生成了约2万行代码。这个工作量放在传统开发模式下,大约相当于一个3人开发团队一个月的产出。当然,后续的打磨和测试还需要不少时间,但从零到一的搭建阶段,确实被大幅压缩了。
智谱官方把GLM-5.1定位为面向长程任务的开源第一模型。我不好说它和所有模型比起来处在什么位置,但就我自己的使用体验来看,在开源模型里面,能稳定完成这种跨十几个步骤、持续好几个小时的完整开发任务,GLM-5.1确实给了我一些之前没有过的体验。
一点实际的建议
如果你也想试试GLM-5.1,有几件事需要注意。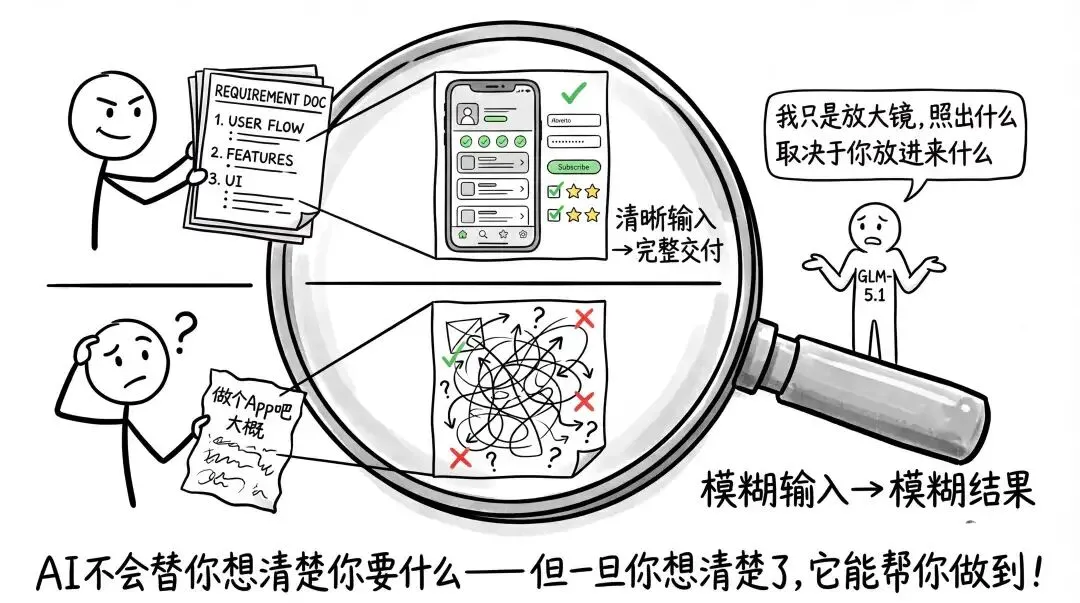 Coding Plan的全体用户现在都可以用了,包括Lite用户。但你需要手动切换模型。在你使用的Coding Agent的配置文件里,把模型名称改成glm-5.1就行了。比如用Claude Code的话,去修改配置文件里的模型参数。
Coding Plan的全体用户现在都可以用了,包括Lite用户。但你需要手动切换模型。在你使用的Coding Agent的配置文件里,把模型名称改成glm-5.1就行了。比如用Claude Code的话,去修改配置文件里的模型参数。
如果你搭配OpenClaw使用,体验会更好。你可以用手机发消息给OpenClaw,让它调度GLM-5.1去执行开发任务,然后你去做别的事情。等它做完了会把结果汇报给你。这种工作模式特别适合长程任务,因为你不需要一直盯着屏幕等它。
另外,给GLM-5.1布置任务的时候,尽量把需求描述得完整一些。它的长程规划能力很强,但前提是你得把目标说清楚。你给它一份详细的需求文档,它能自己拆解成十几个步骤然后一口气做完。你给它一句含糊的描述,它也只能给你一个含糊的结果。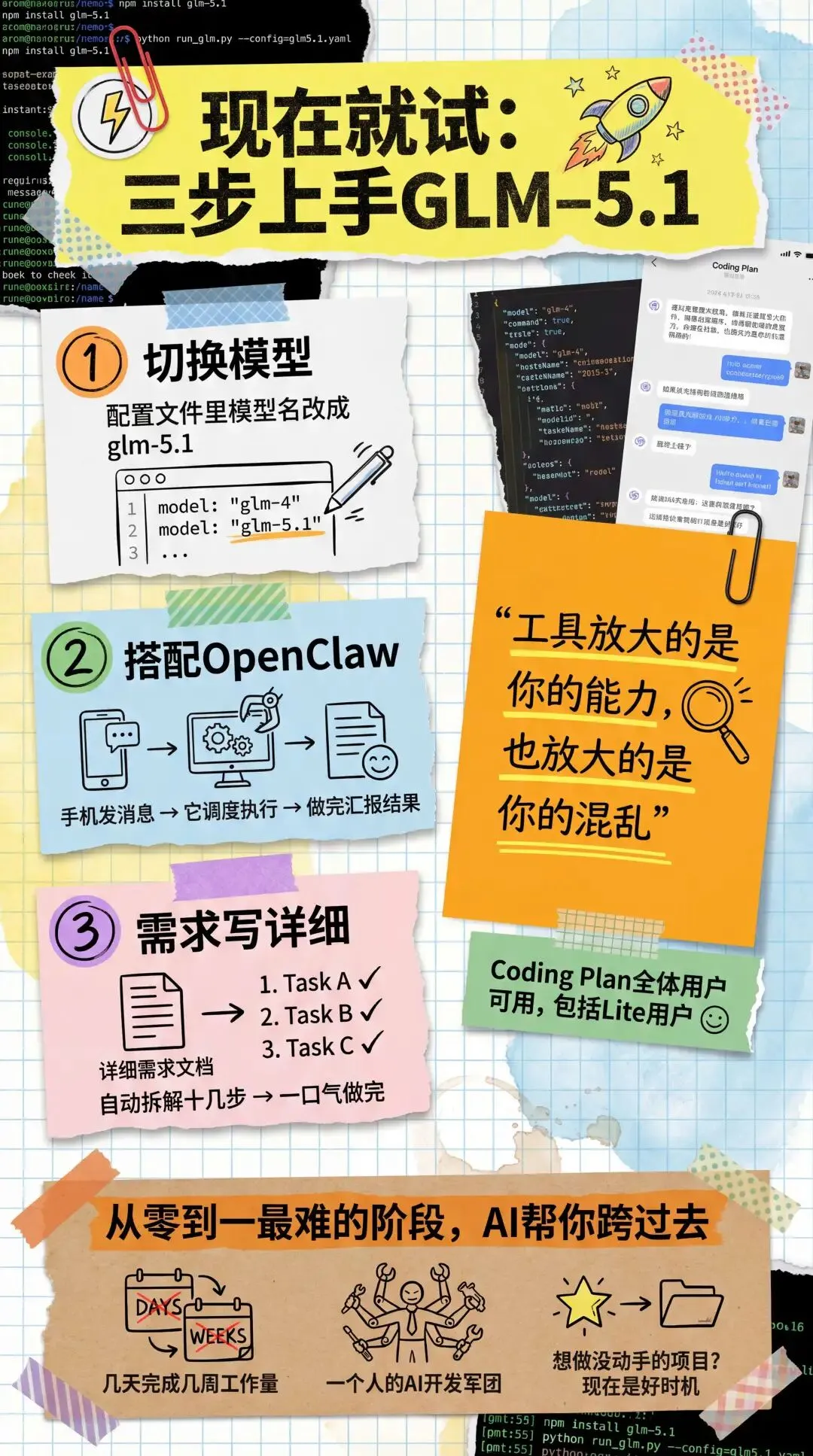 工具放大的是你的能力,也放大的是你的混乱。这句话我在之前的文章里说过,放在这里依然适用。
工具放大的是你的能力,也放大的是你的混乱。这句话我在之前的文章里说过,放在这里依然适用。
写在最后
现在这两个App的核心功能已经跑通了,后续我也会把它们都进行开源和详细的软件使用介绍。
一个人,一个GLM-5.1,一个OpenClaw,几天时间,累计生成约2万行代码,做了两个完整的iOS App。这个工作量放在以前,可能需要一个小团队花几周才能完成。
我知道有人会说,你做的这些东西能不能上生产环境还不好说。确实,后面还有大量的打磨、测试和优化要做。但关键的转变已经发生了。从零到一的那个最难的阶段,AI帮我跨过去了。
以前AI像一个聪明的实习生,你让它做什么它做什么,但你得一直在旁边盯着。现在GLM-5.1更像一个干了几年的工程师,你给目标,它给交付。至少在我这两个项目里,它做到了。
这个变化的速度比我预想的要快。
GLM-5.1的Coding Plan全体用户都能用。如果你有想做但一直没动手的项目,现在可能是一个好的时机。记得在配置里手动把模型切换成glm-5.1。
我们下期见。