 夜雨聆风
夜雨聆风





泄漏的Claude Code源码是拆解Harness工程的绝佳案例
我是@卜寒兮,主要聊点【科技| AI |科研】方面的内容,这是我在公众号发布的第【33】篇原创内容,感兴趣的可以点击下方关注我。
大家都知道,昨天科技圈最大的乌龙是Claude Code源码泄漏了。
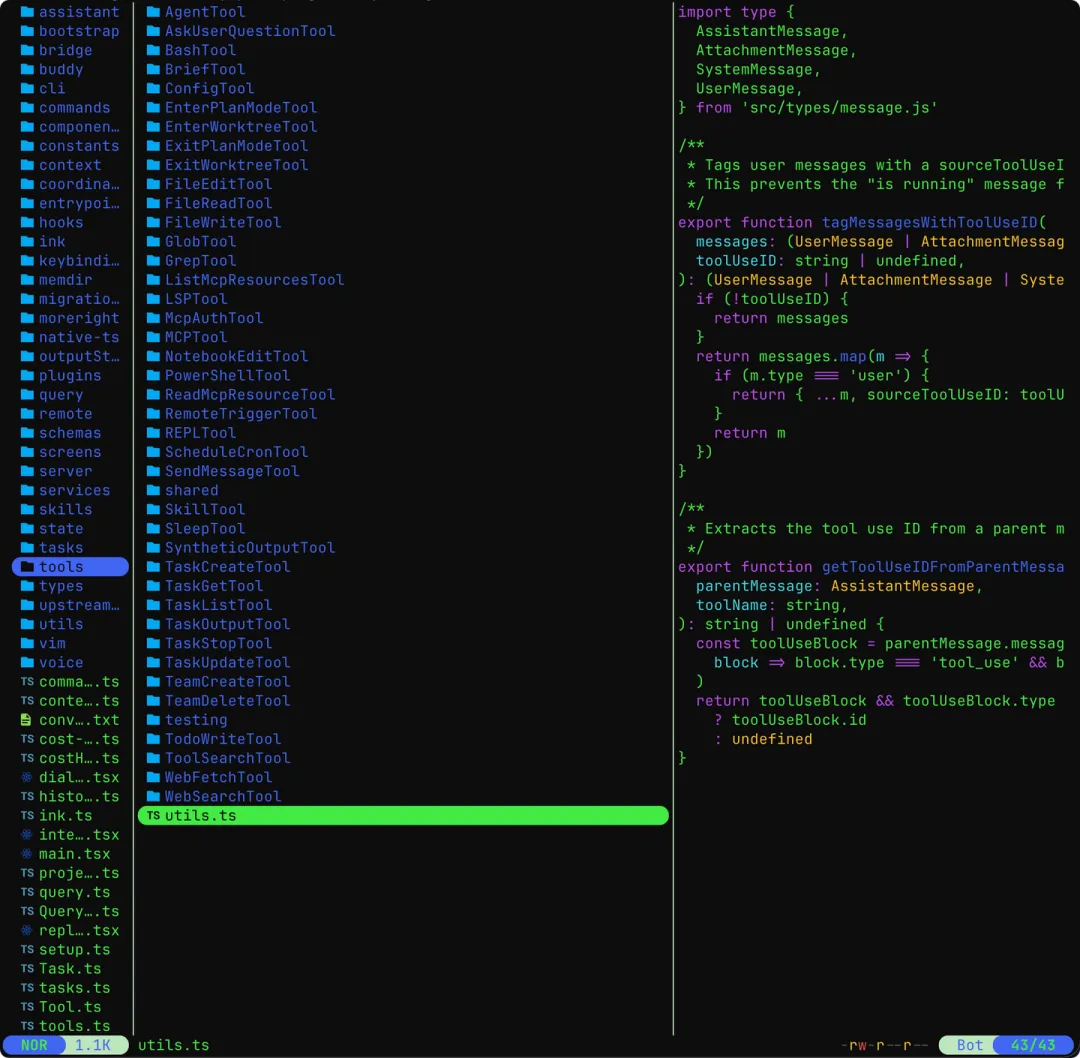
简单来说,官方团队在发布Claude Code最新版本v2.1.88的时候,在npm包里包含了source map文件,它指向了Anthropic的公有存储桶,能直接下载src.zip。
下载地址:https://t.co/jBiMoOzt8G
source map 原本应该是用于调试的文件,生产环境不应该打包,最近Claude code基本上每天一更,之前看到有人总结了近一个多月以来Claude code/Claude app的迭代细节,堪称劳模。
这次怕不是Claude code作者更新把自己都更麻了,才不小心弄了个大乌龙。
反正这款目前可以称为地表最强的CLI coding agent 就这么赤裸裸的展现在大家面前了。
然后千千万万程序员过年,因为源码的泄露导致Claude code内部架构变得完全透明。很多人已经跃跃欲试的根据源码自己重新部署了,接下来肯定也会有一大波Claude code分支出现。
我看有网友说,接下来就是期待某个分支能让你Claude code的tokens消耗量减少97%。

不过除了会助力一大波 “xxx code” 的出现(就像openclaw繁衍出无数只“龙虾”一样),我觉得泄漏的源码的另一大用处就是用来学习harness工程,这绝对是harness设计和落地的绝佳案例。
因为harness engineering这个概念很火,而且它也是anthropic提出来的,前几天还专门发了一篇文,讲harness设计。

Claude code本身就是harness工程的最佳工程决策,现在用Claude code的源码去拆解harness工程的设计哲学。
还有比这更般配的么。
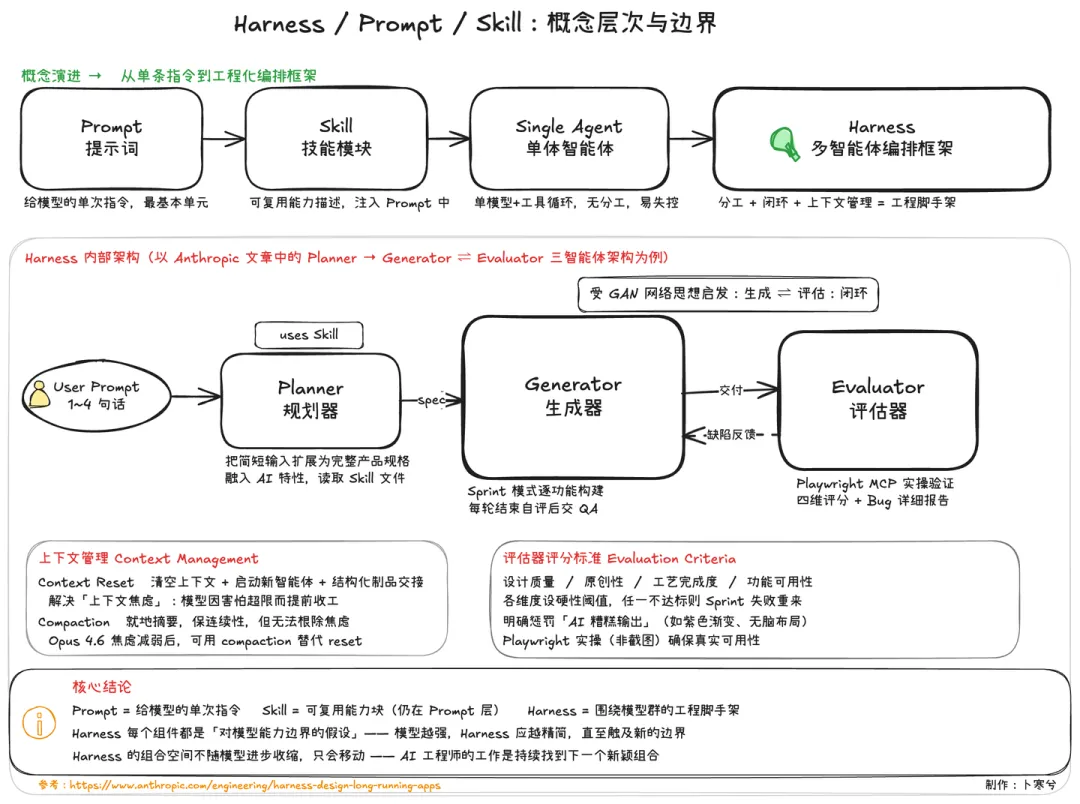
以免有人还不熟悉,先简单说一下什么是harness?
什么是Harness?
Harness原意是“马具”,也就是让一匹马进入到工作状态所需的一套装备。
到AI 这里,harness工程就是给模型建立一套规则和框架,约束模型行为,让它按照你制定逻辑和策略去工作,目的是完成那种光靠模型裸跑所完不成的任务。
你可以按照 prompt –> skills –> harness工程 这个演化过程来理解harness。
Claude Code源码拆解
然后再来看 Claude code,表面上看它是一个独立的cli智能体,但是透过源码,可以发现它并不是单agent,比如:
-
• tools/AgentTool/ 目录中有可以 spawn的子 agent -
• utils/forkedAgent.ts 表明上下文压缩有专门 forked agent 完成 -
• tasks/LocalAgentTask/ 是负责后台任务的agent -
• 以及utils/swarm/ 下的多 agent 协作工具 -
• 等等
Claude code本身就是一个被深度优化过的 harness,里面有很多工程决策。
以泄漏的源码为准,Claude code完整的结构如下:
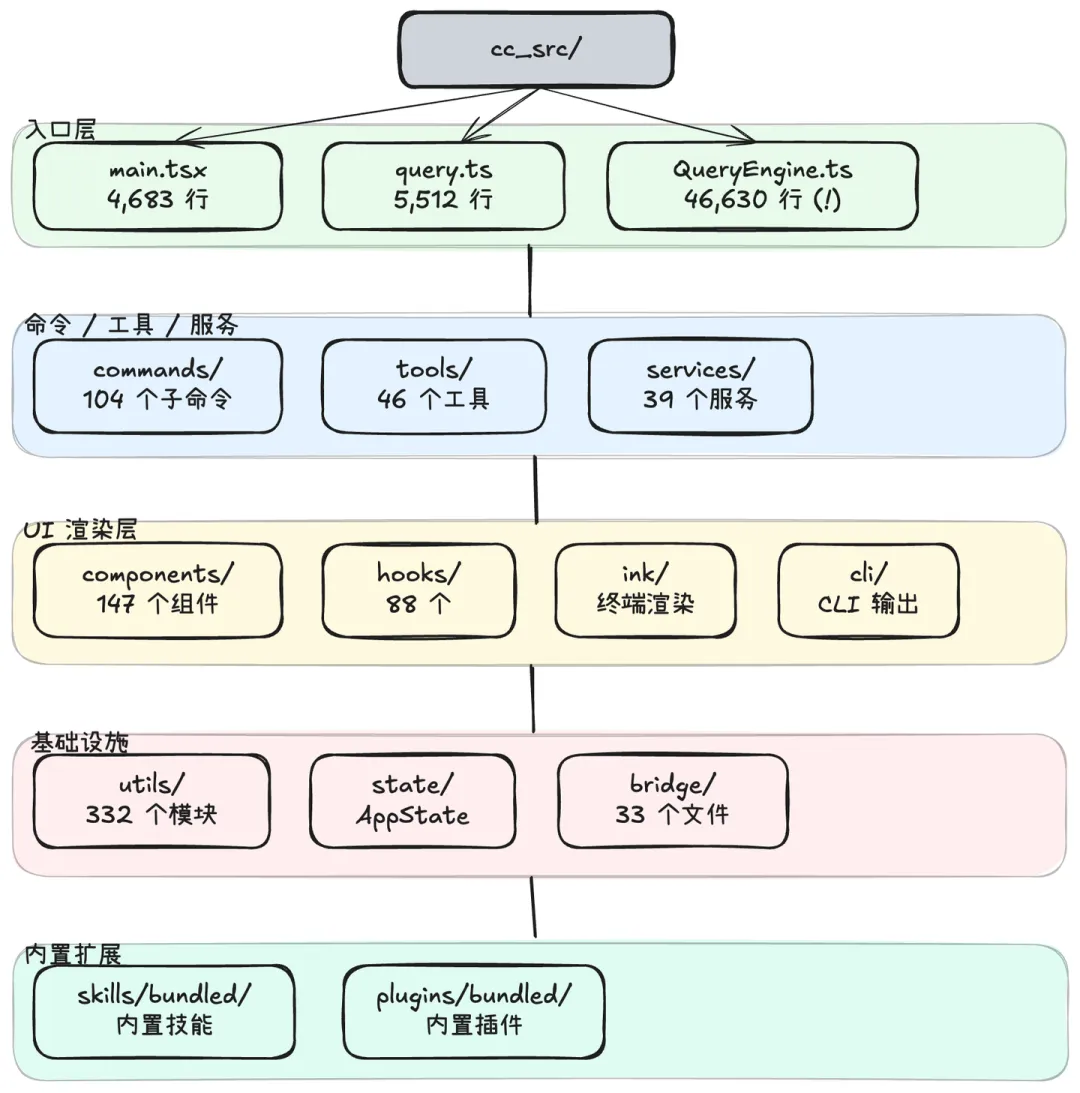
核心模块包括:
-
• 查询引擎 (query.ts → QueryEngine.ts) 。处理用户输入、调用 claude api、执行工具调用的主循环 -
• 工具系统 (tools/) 。46 种工具,每个有独立权限检查逻辑 -
• 命令系统 (commands/) 。104 个斜杠命令,我看到了/btw
-
• MCP (services/mcp/) 。MCP的客户端实现 -
• 权限系统 (utils/permissions/) 。逐个的工具使用权限控制 -
• Bridge (bridge/) 。本地与远程 Claude code 会话通信 -
• plugins和skills系统 。可扩展的第三方集成和自定义命令
从harness设计的角度看它具体的工程决策。
### 1、AsyncGenerator 核心
大多数 AI 应用的结构是”发请求,拿响应”。Claude code 的核心函数 query() 不是:
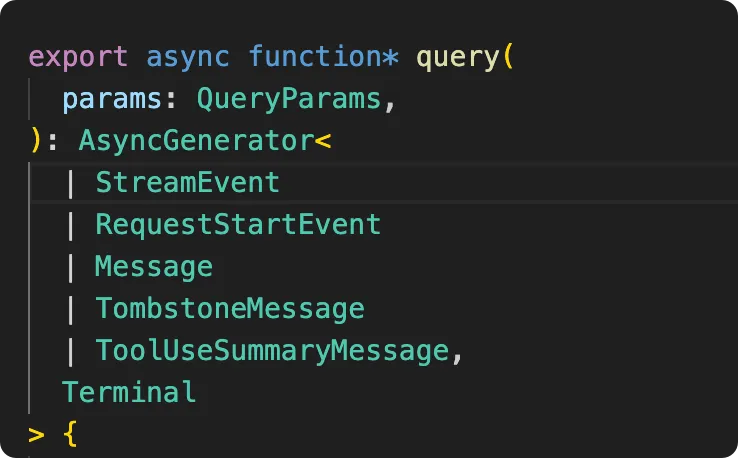
它是一个AsyncGenerator,用 yield 流出每一个事件:token、工具调用结果、错误等。
这个设计直接解决了 long-running agent 里最麻烦的执行时间不确定问题。
一个任务可能需要 3 秒,也可能需要 3 小时。用传统的 async/await,要么阻塞等待,要么手写回调。AsyncGenerator 让调用方随时可以消费下一个事件,或者中途 .return() 终止整个生成器链。
这个模式也方便组合:compaction 是一个 generator,工具执行是一个 generator,主循环用 yield* 把它们串起来。每个环节可以独立测试,也可以拼在一起用。
开头提到Harness design那篇文章提到 agent 系统需要“处理中断和恢复”——AsyncGenerator 在语言层面就提供了这个能力,不需要额外的状态机。
2、Agentic Loop:while(true) 状态管理
核心循环在 queryLoop 里,结构是:
1 2 3 4 5 6 7 8 9 while (true) { 1. 上下文预处理(压缩/截断) 2. 调用 Claude API(流式) 3. 解析响应,收集 tool_use 块 4. 执行工具 5. 把结果追加到消息历史 6. 如果没有工具调用 → return(终止) 如果有 → continue(下一轮)}
这是标准的 ReAct(Reason + Act) 模式,细节在状态管理上。
循环里有一个 State 类型,记录每轮迭代间需要携带的可变状态:
1 2 3 4 5 6 7 type State = { messages: Message[] maxOutputTokensRecoveryCount: number hasAttemptedReactiveCompact: boolean transition: Continue | undefined // 上一轮为何 continue ...}
transition 字段记录”为什么进入下一轮”,可选值有 reactive_compact_retry、collapse_drain_retry、max_output_tokens_recovery 等。这不只是调试信息——它是防止死循环的断路器:如果上一轮已经因 X 重试过一次,就不再重试 X,而是进入下一个恢复策略。
Harness Design 里有一个类似的观点:long-running task 的错误恢复需要分层次,而不是”catch 一下再试一次”。
3、五层压缩策略的上下文管理
上下文焦虑是 long-running task 的头号问题,anthropic在文章中提到,context 快满时,模型就会开始草草收尾,质量急剧下降。
Claude Code 对此有五层策略,从轻到重依次触发:
|
|
|
|
|
|---|---|---|---|
|
|
microcompact |
|
|
|
|
snip |
|
|
|
|
autocompact |
|
|
|
|
reactiveCompact |
|
|
|
|
contextCollapse |
|
|
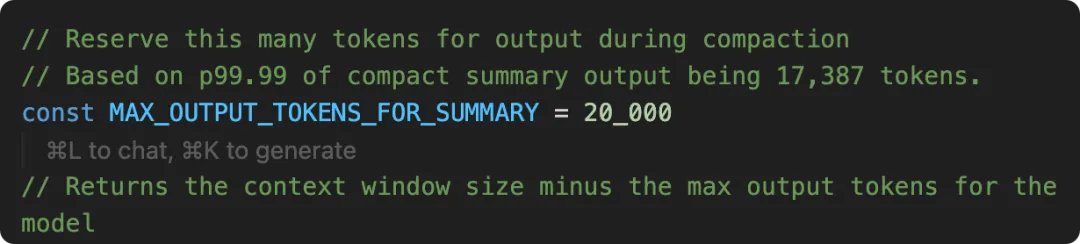
1 2 3 4 // autoCompact.tsexport const AUTOCOMPACT_BUFFER_TOKENS = 13_000 // 主动压缩的安全余量export const MAX_OUTPUT_TOKENS_FOR_SUMMARY = 20_000 // 压缩摘要的 token 预算// 实测 p99.99 的压缩摘要输出为 17,387 tokens,因此取 20k
20_000 这个数字不是估算,注释写明来自生产数据的 p99.99。
autocompact 本身也是一个 forked agent——fork 出子 agent,共享父对话的系统提示和工具定义(保证 prompt cache 命中),再用 Claude Haiku 生成摘要。CacheSafeParams 类型描述了哪些参数必须与父 agent 完全一致才能命中缓存:
1 2 3 // forkedAgent.ts// CacheSafeParams carries system prompt, tools, model, messages (prefix), thinking config.// Thinking config is derived from inherited toolUseContext.options.thinkingConfig
4、流式并发执行,工具不用模型说完就开始跑
通常的实现是:等模型完整输出所有 tool_use 块 → 全部执行完 → 把结果返回模型。
Claude Code 有一个 StreamingToolExecutor,模型还在流式输出时,已经完成的 tool_use 块就立刻开始执行:
1 2 3 4 5 6 7 8 9 10 // 在 for await 流式循环内if (streamingToolExecutor) { for (const toolBlock of msgToolUseBlocks) { streamingToolExecutor.addTool(toolBlock, message) // 立即入队并尝试执行 }}// 同时,已经完成的工具结果也在同一循环里被 yield 出来for (const result of streamingToolExecutor.getCompletedResults()) { yield result.message}
模型输出和工具执行是并行的。对于需要读取 10 个文件的任务,这意味着在模型还没说完”我需要读哪些文件”的时候,前几个文件已经读完了。
并发引入了新问题:哪些工具可以并行?每个工具实现一个 isConcurrencySafe() 接口,自己声明:
1 2 3 4 5 6 7 8 9 10 11 // GrepTool - 只读,天然并发安全isConcurrencySafe() { return true }// BashTool - 视命令内容而定isConcurrencySafe(input) { return this.isReadOnly?.(input) ?? false // isReadOnly 会分析命令的 AST,判断是否包含写操作}// McpAuthTool - 涉及认证状态,强制串行isConcurrencySafe: () => false
调度规则很简单:只有当所有正在执行的工具都是并发安全的,才能启动新的并发安全工具;非安全工具必须独占执行。
还有一个细节:并发执行时引入了 siblingAbortController——当某个并行工具报错,同批次的其他工具立即收到取消信号,而不是等它们跑完再处理错误。
5、Hook 架构:在正确的时机插入逻辑
Harness 文章里提到的 generator-evaluator 分离,在 Claude code 里是以 hook 的形式实现的:evaluation 逻辑(stop hooks 检查任务是否完成)与 generation 逻辑完全解耦。
Claude Code 提供了 PreToolUse、PostToolUse、PostSampling、PreCompact、PostCompact 几个 hook 点。
这对应了 Harness Design 的一个思路:agent 的行为需要在不改动核心循环的情况下被调整。
PostSampling Hook 在每次模型生成完成后触发,让外部逻辑可以观察主循环而不干扰它。注意它的错误处理:
1 2 3 4 5 6 7 8 // postSamplingHooks.tsfor (const hook of postSamplingHooks) { try { await hook(context) } catch (error) { logError(toError(error)) // 只记录,不 rethrow }}
Hook 的错误被吞掉,不会破坏主循环。监控、日志、评估逻辑出问题了,不应该把主任务也带崩。
6、运营数据驱动的工程决策
Harness 文章的一个重要观点:harness 编码了对”模型不能独立完成什么”的假设,这些假设值得随着模型能力的提升不断重新审视。也许模型有一天变更强了,这些假设就不成立了。
Claude Code 源码里有几处注释,直接体现了这种做法:
1 2 3 // 2026-03-10: 1,279 sessions had 50+ consecutive failures (up to 3,272)// in a single session, wasting ~250K API calls/day globally.// Based on p99.99 of compact summary output being 17,387 tokens.
每一个数字背后都是实际经验或统计分析。把这些数据直接写进注释而不是只留常量,意味着下一个来改代码的人知道这个数字是怎么来的、改了会有什么后果。
这说明 Claude code 团队把 harness 当做一个需要持续迭代的运营系统,而不是一次设计完就不动的基础设施。从这个角度看,这些注释其实是最重要的文档。
总结
回到上面那句话:harness 编码了对”模型不能独立完成什么”的假设(“the harness itself encodes assumptions about what models cannot do independently”。)
Claude code的harness 告诉你:当前模型需要被辅助管理上下文、需要并发调度、需要权限沙箱、需要多层错误恢复。这些都是现阶段的假设,不是永久的结论。随着模型能力的变化,哪些假设还成立、哪些可以去掉,值得持续观察。
既然已经看到这里,不如来个“点赞、在看、转发”三连再走,非常感谢。也欢迎你关注我
推荐阅读
-
• Claude: 不会编程也能写软件——如何让一个想法直接变成应用程序? -
• 为什么谷歌NotebookLM被认为是目前最好用的文献分析工具? -
• 为什么刚过去两天,o1 的热度就消失了? -
• 给 AI 用上这个 Prompt,我再也不用亲自整理读书笔记了 -
• 如何用AI搞科研? -
• 读研期间最忌讳的是什么? -
• ChatGPT 最实用的指令(Prompt) -
• 全新版 ChatGPT 使用体验——OpenAI 16 款 GPTs、All Tools -
• 读研期间最忌讳的是什么?
点击“阅读原文”了解更多信息↓