 夜雨聆风
夜雨聆风





Claude Code 源码里三个反常识的AI产品设计哲学
作为一个天天和AI产品打交道的产品经理,我拿到 Claude Code 源码的那一刻,直接失眠了。
我之前一直觉得Claude Code用起来很顺手,但从来没有细想过它到底好用在哪,现在仔细一研究,才发现它在产品设计上做的很多选择,和市面上大部分 AI 产品都是反着来的。
别人都在卷模型能力、卷上下文长度、卷 Agent 数量。但 Claude Code 让我震撼的,不是它的技术架构,而是它的产品哲学——
让用户从 “使用 AI” 变成 “管理 AI”。
这篇文章,我把从源码里提炼出来的产品设计思想,总结成三点,分享给所有做 AI 产品的朋友。
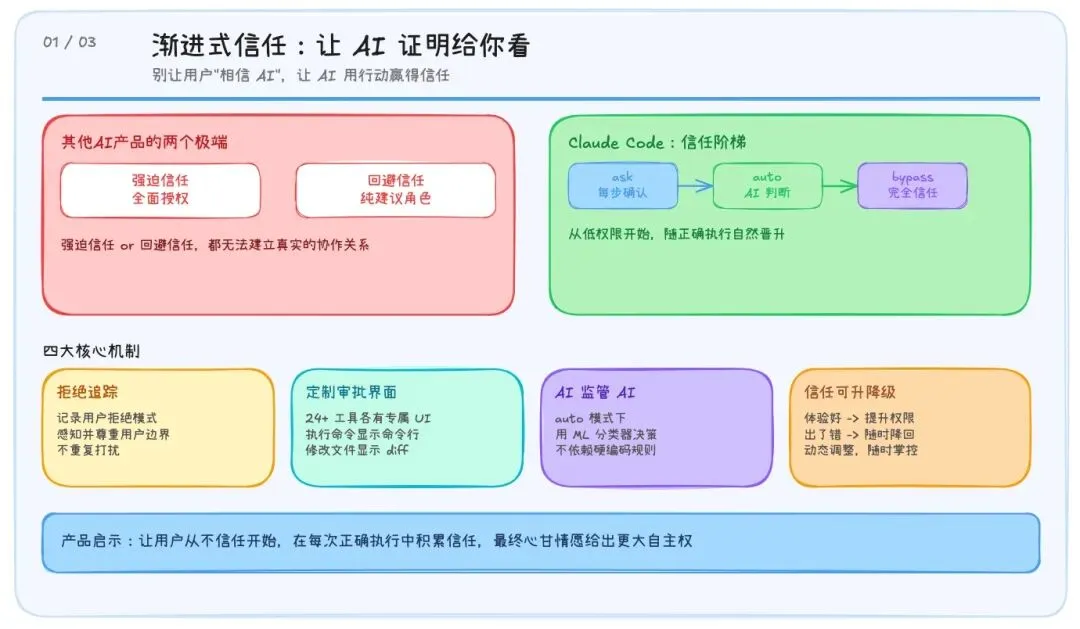
一、渐进式信任:别让用户“相信 AI”,让 AI 证明给你看
先说一个我从源码里发现的、市面上几乎没有产品做到的设计——拒绝追踪(Denial Tracking)。
什么意思呢?当用户反复拒绝 AI 的某类请求后(比如 “不要修改测试文件”),Claude Code 会自动记录这种拒绝模式,下次不再用同样的请求骚扰用户。
这个功能本身不复杂,但它背后是一个很容易被忽略的产品价值观——一个好的 AI 产品,应该能感知到用户的边界,并且尊重它。
而这只是 Claude Code 整套“渐进式信任”设计的冰山一角。
AI 产品和传统软件有一个本质区别:传统软件的行为是确定的——你点什么就发生什么,所以用户掌控感很强;但 AI 的行为就像开盲盒——用户永远无法完全预测 AI 这次给出的结果是好还是不好,这种不确定性天然制造不信任。
市面上大部分 AI 产品怎么处理这个问题?两个极端:
-
要么让用户全面授权(比如一些自动编程工具) -
要么把 AI 限制在纯建议角色(比如大部分对话式 AI)
前者是强迫信任,后者是回避信任。
但 Claude Code 走了第三条路:设计一条信任阶梯,让信任在使用过程中自然生长。
它怎么做的?
- 精细化分层权限:Claude Code 设计了 5 种权限模式—— ask(每步都问)、acceptEdits(自动批准编辑)、auto(AI 自动判断)、plan(只规划不执行)、bypass(完全信任)。新用户从 ask 模式开始,用着用着觉得靠谱了,再一档一档往上调。
- 定制化审批界面:Claude Code 为 24 种以上的不同工具,分别定制了专属的权限请求界面。要执行命令?给你看完整命令行;要修改文件?给你看具体的 diff;要访问网络?展示完整 URL。
- 用 AI 监管 AI:在 auto 模式下,Claude Code 不是用硬编码规则来判断操作是否安全,而是用另一个 ML 分类器来做安全决策。
- 信任可升级,也可降级:某次体验好了,可以提升权限;某次出错了,随时降回去。信任是一个可以反复调整的动态博弈。
这对我们做 AI 产品来说,很重要的启示就是让用户从不信任开始,在每一次正确执行中积累信任,最终心甘情愿地给出更大的自主权。
二、可编程的 AI 行为:别做万能 AI,做塑造 AI 的工具
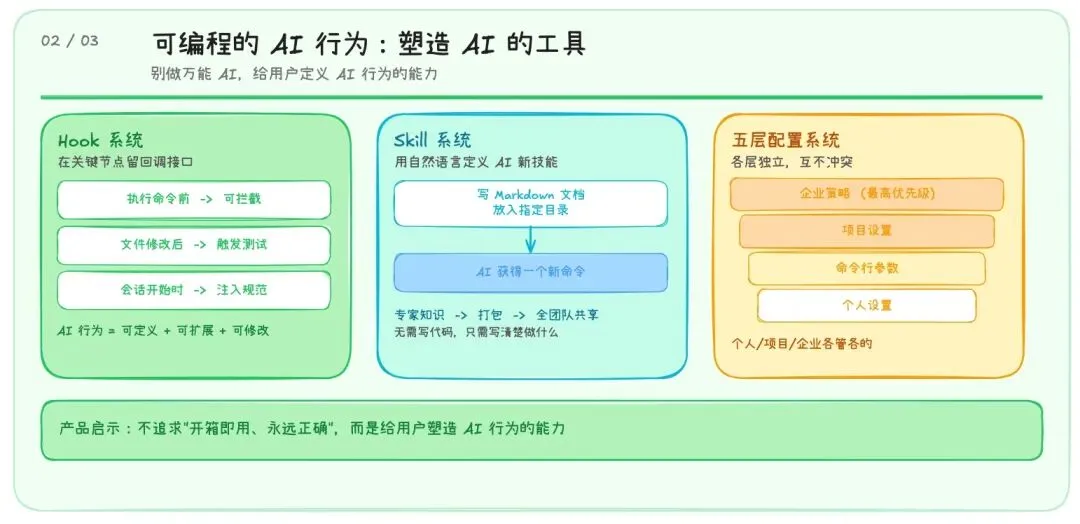
Claude Code 在 AI 执行操作的每一个关键节点(执行命令前、修改文件后、会话开始时、文件变更时……)都留了回调接口,用户可以写脚本来拦截、修改、甚至阻止 AI 的任何操作。
比如:
-
AI 改完代码后,自动触发你项目的测试套件 -
会话开始时,自动注入你团队的代码规范作为上下文
这等于让 AI 的行为像软件一样,可定义、可扩展、可修改。
除了 Hook 以外,Skill 系统也是一种非常重要的可编程设计——用自然语言定义 AI 新技能。
用户写一个 Markdown 文档放到指定目录下,就能创建 AI 的一个新命令。不需要写代码,只需要写清楚“你要做什么、怎么做、注意什么”。
这些 Skill 可以被命名、分享、版本管理。你团队里最懂某个业务的同事,可以把自己的专家知识打包成一个 Skill,让整个团队的 AI 都拥有这项能力。
同时 Claude Code 还有五层配置来源:个人设置、项目设置、企业策略、命令行参数、会话内修改。每层都可以覆盖上一层,个人、项目、企业各管各的,开发者自定义自己的习惯,团队 Lead 定义项目规范,安全团队定义合规策略——互不冲突,各司其职。
这对我们做 AI 产品来说:别试图做一个“开箱即用、永远正确”的 AI——那不现实。更好的策略是:给用户塑造 AI 的能力
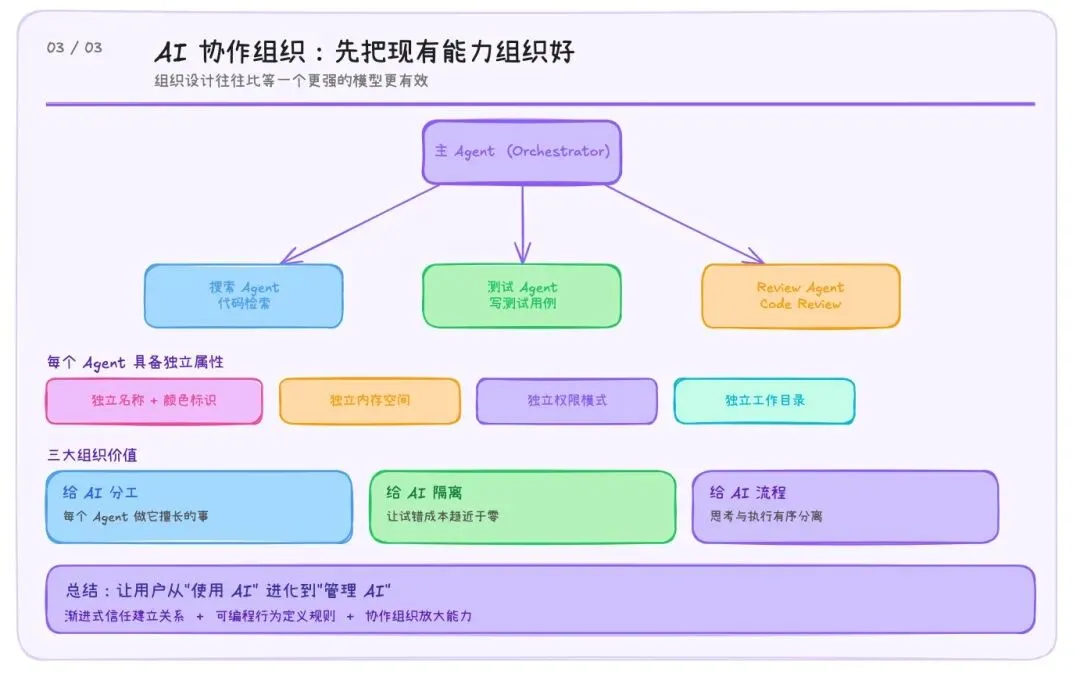
三、AI 作为协作组织:先把现有能力组织好
最后一个设计——多 Agent 团队协作系统。这和最近 Anthropic 刚发布的 Harness Engineering 实践直接对上了。
(顺便做个小预告,下期我会来全面解读下 Harness 这个新名词)
在 Claude Code 里,一个主 Agent 可以召唤多个子 Agent,组成一个团队:一个负责搜索代码、一个负责写测试、一个负责做 code review。每个 Agent 有独立的名称、颜色标识、内存空间、权限模式和工作目录。
- 给 AI 分工:让每个 Agent 做它擅长的事
- 给 AI 隔离:让试错的成本趋近于零
- 给 AI 流程:让思考和执行有序分离
在现有模型能力的约束下,做好组织设计,往往比等一个更强的模型更有效。
写在最后
读完 Claude Code 源码,最大的感受是:Anthropic 不只是在做一个 AI 工具,它在设计一套人与 AI 的协作范式。
这三个设计思想,总结成一句话就是——
让用户从“使用 AI”进化到“管理 AI”:通过渐进式信任建立关系,通过可编程行为定义规则,通过协作组织放大能力。
这条路,可能比卷模型参数、卷上下文长度、卷 Agent 数量,都要走得更远。
我是吃土,带你用产品视角看懂 AI。