 夜雨聆风
夜雨聆风





Claude Code 源码泄露事件:被动开源、社区反应与 Anthopic 的下一步
3 月 30 日,Claude Code 负责人 Boris Cherny 在 X 上发了一条长推,兴致勃勃地分享 Claude Code 那些隐藏的、低利用率的功能: loop 自动循环、hooks 生命周期管理、session fork 分支会话。

24 小时后,整个互联网都知道了 Claude Code 的所有功能,不是因为 Boris 的推文写得好,而是因为 Anthropic 把完整源码打包发到了 npm 上。
这可能是 AI 行业迄今为止最具讽刺意味的被动开源事件。
事件起因
2026 年 3 月 31 日,安全研究员 Chaofan Shou 在 X 上发布了一条震动整个开发者社区的帖子:Anthropic 旗下的 AI 编程工具 Claude Code,其完整源代码通过 npm 包中的 source map 文件意外泄露。这条推文迅速获得千万次浏览,成为当日技术圈最大的新闻。
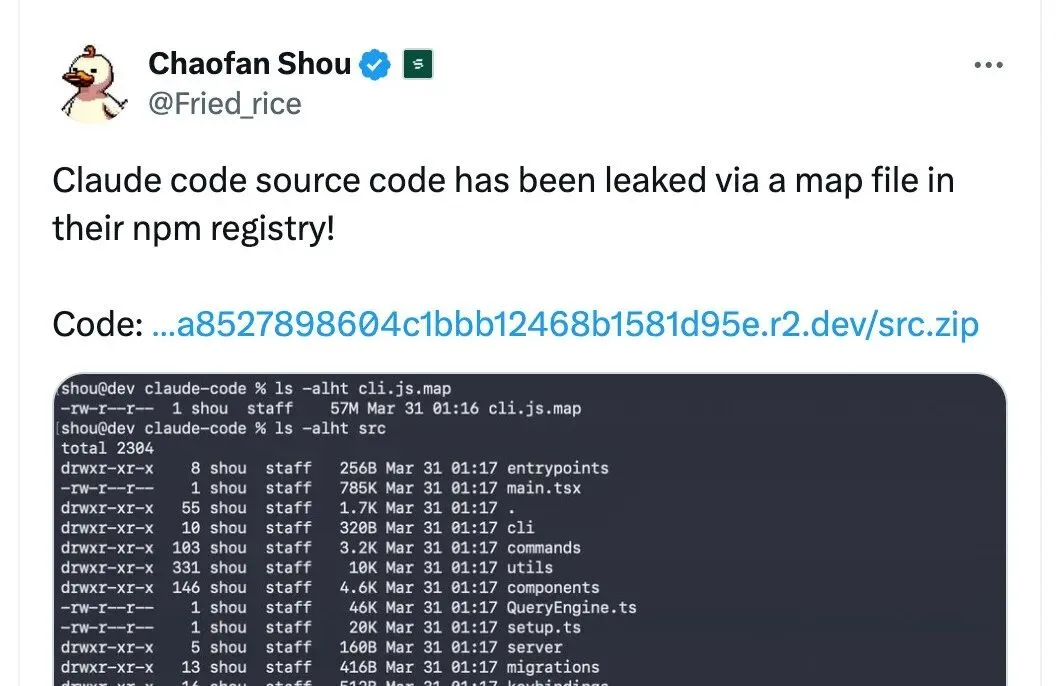
事情的技术细节并不复杂。Anthropic 在发布 @anthropic-ai/claude-code v2.1.88 版本时,未在 .npmignore 中过滤掉 source map 文件。一个 59.8MB 的 .map 文件被直接打包进了 npm 发布物,其中包含 4756 个源文件的完整内容。
提取方式极其简单:source map 本质就是一个 JSON 文件,sources 数组存储文件路径,sourcesContent 数组存储对应的完整源码,两者索引一一对应。不需要反编译,不需要反混淆,所见即所得。
什么是 Source Map?为什么它会导致源码泄露?
这里简单解释一下这次事件的技术背景。
现代软件在发布前通常会经过编译和压缩,把开发者写的、结构清晰的源代码,变成一团机器高效执行但人类几乎无法阅读的压缩代码。你可以把这个过程想象成把一本排版精美的书,用碎纸机打成纸浆再压成一块砖。最终用户拿到的是那块砖,功能完好,但你已经无法还原出原来的书了。
Source Map 就是那份碎纸机的逆向说明书。 它是一个 JSON 文件,记录了压缩后的代码与原始源码之间的逐行对应关系。它的设计初衷是为了方便开发者调试,当线上程序出了 bug,开发者可以借助 source map 把报错信息映射回自己熟悉的源代码,快速定位问题。
正常情况下,source map 只应该存在于内部开发环境,绝对不应该被发布到公开的软件包仓库里。这就好比你把碎纸机的逆向说明书和纸浆砖一起寄给了所有人——任何人都可以用这份说明书把砖头还原成原来的书。
Claude Code 使用 Bun 作为打包工具,而 Bun 默认生成 source map。如果发布时忘记在 .npmignore 文件中加一行 *.map 来排除它,这份”逆向说明书”就会原封不动地混进发布包。在这次事件中,这正是所发生的事情:一个配置疏忽,1906 个源文件的完整内容被一览无余地呈现在所有人面前。
社区反应
消息传开后,社区的反应速度远超 Anthropic 的危机响应。在 Anthropic 团队醒来之前,整个代码库已经被下载、复制并镜像到了多个 GitHub 仓库。
技术博主 ITGuy 详细列出了泄露内容的规模:1900 多个文件、51 万行代码,涵盖完整的工具系统、50 多个 slash 命令、多 Agent 协调器、基于 React/Ink 的终端 UI、IDE 桥接层和权限引擎,甚至包含若干未公开发布的功能。
中文社区同样反应迅速。@chenchengpro 撰写了详尽的中文技术分析,从架构层面解读了 Claude Code 的设计:REPL 循环、自然语言输入与 slash 命令的双轨模式、底层工具系统与 LLM API 的交互逻辑。@dotey 则直接动手将泄露的代码跑了起来,并分享了可运行的仓库地址。

最具戏剧性的故事是一位名叫 Sigrid Jin 的韩国开发者 (据称是全球最活跃的 Claude Code 用户),在凌晨 4 点被手机消息轰炸醒来。他的女朋友担心仅仅是在本地保存了这份代码就会被起诉。
于是他做了任何工程师都会做的事:在日出之前用 Python 从零重写了整个项目,命名为 claw-code 并推送到 GitHub。因为 Python 重写属于 clean-room 全新创作(不包含一行原始 TypeScript),DMCA 无法触及。该仓库在发布后约 2 小时内突破了 5 万 star,创下 GitHub 历史上最快达成该里程碑的记录。之后他又开始用 Rust 重写,目前已获超过 5.5 万 star 和 5.8 万 fork。
源码里到底藏了什么
泄露发生后的 24 小时内,多位技术博主和研究者对源码进行了详细分析。他们的发现远比”看看代码写得好不好”有趣得多。
秘密武器不是模型
AI 研究者 Sebastian Raschka 在泄露当天发表了一篇引发广泛讨论的博文《Claude Code’s Real Secret Sauce Isn’t the Model》。他的核心觀點是:Claude Code 之所以比直接在 Claude 网页版里写代码好用那么多,不是因为模型更强,而是因为围绕模型搭建的工程脚手架做得好。
他从源码中提炼出 6 项关键的工程优化:
-
实时仓库上下文:启动时自动加载 git 分支、最近提交、CLAUDE.md 等信息
-
激进的 Prompt Cache 复用:静态内容全局缓存,避免每次都重新处理昂贵的上下文
-
专用工具替代裸 Bash:用专门的 Grep/Glob/LSP 工具代替通用 shell 命令,权限更安全、结果收集更精准
-
上下文膨胀控制:文件去重、超大结果写磁盘只保留摘要引用、自动截断和压缩
-
结构化 Session Memory:每个会话维护一份结构化 Markdown 笔记
-
Fork + Subagent 并行:子 Agent 复用父级缓存,可在不污染主循环的情况下做后台分析
如果把 DeepSeek、MiniMax 或 Kimi 的模型放进同样的 harness 并做些适配,也能获得非常强的编码表现。换句话说,Claude Code 卖的不只是智能,更是工程。
三大争议发现
博主 alex000kim 对源码做了深入分析,他的分析文章标题直接剧透了最劲爆的发现:《fake tools, frustration regexes, undercover mode》。
Undercover Mode(卧底模式):源码中有一个 undercover.ts,实现了内部员工模式。当开启时,Claude Code 会自动隐藏所有内部代号(如 Tengu、Capybara 等项目名),并且以人类开发者的风格撰写 commit message 和 PR 描述,刻意不透露 AI 参与的痕迹。Hacker News 上的讨论迅速两极分化:一方认为这是正常的企业保密措施(防止无意间泄露商业机密),另一方则认为这是系统性的欺骗,如果 Anthropic 员工用 AI 写代码并伪装成人类提交到开源项目,这是否意味着整个开源社区需要重新审视来自 Anthropic 的贡献?
Anti-Distillation(反蒸馏)机制:源码中包含一个 ANTI_DISTILLATION_CC 标记,开启后会在 API 请求中注入假工具(fake tools)到系统提示词中。目的是:如果有人录制 Claude Code 的 API 流量来训练竞品模型,这些假工具会污染训练数据。社区对此的评价很分裂——工程上有巧思,但任何认真做蒸馏的人”读一小时源码就能绕过”,真正的保护大概率还是法律层面的。
Frustration Regex(挫败感正则):Anthropic 用基本的正则表达式来检测用户是否在表达沮丧或不满。这一发现引发了大量调侃——”一家估值数百亿的 AI 公司用 regex 做情绪分析”。但很快也有开发者为之辩护:一个正则表达式的执行速度远快于一次 LLM 推理,在需要快速判断用户状态以调整行为的场景下,这恰恰是最务实的工程选择。
50 万行 Vibe Code 与隐藏功能
社区项目 ccunpacked.dev 制作了一份可视化架构拆解,试图将整个代码库的结构映射成可导览的图表。这份分析揭示了一个让很多人意外的事实:Claude Code 的代码量约为 50 万行。
围绕代码质量的讨论也很有看头。不少开发者评价整个项目是 vibe coded ——这是一个带贬义的术语,意思是用 AI 快速堆出来的代码,追求速度而不太在意技术债务和架构优雅。批评者指出了 Bash 工具实现中的深层嵌套逻辑、到处读取环境变量的层级违规、以及冗余的哈希函数实现。但也有人反驳:一个一年内从零做到年化 25 亿美元收入的产品,如果代码不脏一点,那才说明优先级有问题。
源码中最引人遐想的是几个未发布的功能:
-
Kairos:一个持久记忆系统,被认为是 Claude Code 下一代上下文管理的核心
-
Coordinator Mode:支持并行 git worktree 的多 Agent 协调模式
-
Buddy:一个……终端宠物 (現在已經正式推出)。根据用户账号 ID 生成一个 ASCII art 精灵动物作为编程伙伴,社区反应两极。
Anthropic 的回应
Anthropic 迅速从 npm 撤回了 v2.1.88 版本,版本号从 v2.1.87 直接跳到 v2.1.89。随后向 GitHub 提交 DMCA 版权保护通知,波及整个 fork 网络,共计 8100 个仓库被禁止公开访问。然而,代码已被镜像到去中心化平台,有人留言称永远不会被删除。
Anthropic 的官方声明措辞刻意轻描淡写:This was a release packaging issue caused by human error, not a security breach. (这是一个由人为失误导致的发布打包问题,不是安全漏洞。)后续报道还透露,Anthropic 内部明确表示 no one was fired (没有人因此被解雇)。
但 TechCrunch 的报道画风就没这么轻松了。文章标题直接用了《Anthropic is Having a Rough Month》,并暗示内部的反应并没有这么淡定。文章还提到一个意味深长的背景:OpenAI 在今年砍掉了视频生成产品 Sora,部分原因正是为了重新聚焦开发者市场以应对 Claude Code 的强劲势头。
DMCA 的执行也并非毫无瑕疵。有用户指出,takedown 通知误伤了 Anthropic 自己的公开 issue tracker 仓库(anthropics/claude-code)的 fork,这些仓库和泄露的源码毫无关系,只是恰好在同一个 fork 网络里。
值得注意的是,这并非首次。2025 年 2 月 Claude Code 首次发布时就因同样的原因被社区提取过源码。同样的错误,时隔一年多,再次发生。
Anthropic 的三月危机
单看源码泄露这一件事,影响其实有限,社区很快就指出,泄露的是软件脚手架,不是模型权重。Claude Code 的核心竞争力在于底层模型的能力,代码被看光了,别人也不一定能复制出同等水平的产品。
但这不是獨立事件。
就在五天前,Fortune 独家报道了另一起泄露:Anthropic 将近 3000 个内部资产遗留在一个未加密的公开数据缓存中,任何人都可以检索和下载。被曝光的内容包括一篇尚未发布的博客草稿,描述了一个名为 Mythos 的新模型。Anthropic 在草稿中承认,这个模型在网络安全方面构成了前所未有的风险。Fortune 通知 Anthropic 后,他们才紧急关闭了公开访问。
也就是说,一周之内,Anthropic 连续两次因为基本的配置疏忽导致敏感信息外泄。第一次是内部文件放在不设防的数据库里,第二次是 source map 混进 npm 发布包。两次事故的根因都不是什么高级攻击——是有人忘了检查一个设置项。
与此同时,Claude Code 的用户也在经历另一种信任危机。The Register 报道,大量开发者投诉配额消耗速度远超预期,部分用户发现复杂任务的 token 消耗在短短几个月内暴涨了数倍。有开发者逆向分析后怀疑存在 prompt cache bug,可能导致 token 成本被静默虚增最高达 20 倍。Anthropic 将此列为最高优先级问题,但截至目前尚未给出完整解释。
Claude Code 不会因为源码曝光就失去竞争力,正如赌场的竞争力不在于老虎机的机械结构是否保密,而在于赌客愿不愿意来玩。但是当一家公司一边告诉全世界 AI 需要极其谨慎地对待,一边在自己的发布流程中重复犯同样的低级错误时,故事的讽刺意味就不仅仅是被动开源了。