 夜雨聆风
夜雨聆风





Claude Code 源码泄露,来学学 AI 编程助手的底层逻辑
Claude Code 源码泄露,来学学 AI 编程助手的底层逻辑
近期,AI 圈发生了一件引发广泛关注的事件——Anthropic 旗下备受好评的 AI 编程助手 Claude Code 的核心系统提示词(长达数万 Token)以及 CLI 源码被社区完整逆向并曝光。
作为目前体验十分惊艳的 Coding Agent 之一,Claude Code 能够直接在终端中读取代码库、执行命令、甚至自主完成复杂的开发任务。许多程序员在使用后都惊呼其效果远超预期。随着源码和底层 Prompt 的大白于天下,Anthropic 构建一流 Agent 的“秘籍”也随之公开。
令人意外的是,它的源码中并没有堆砌当下流行的复杂概念,反而处处透着务实与克制。对于想要开发 AI 应用或 Agent 的研发人员来说,这份泄露的源码简直是一份价值连城的“大师课”。以下是 Claude Code 源码中十分值得我们学习的五个核心设计理念。
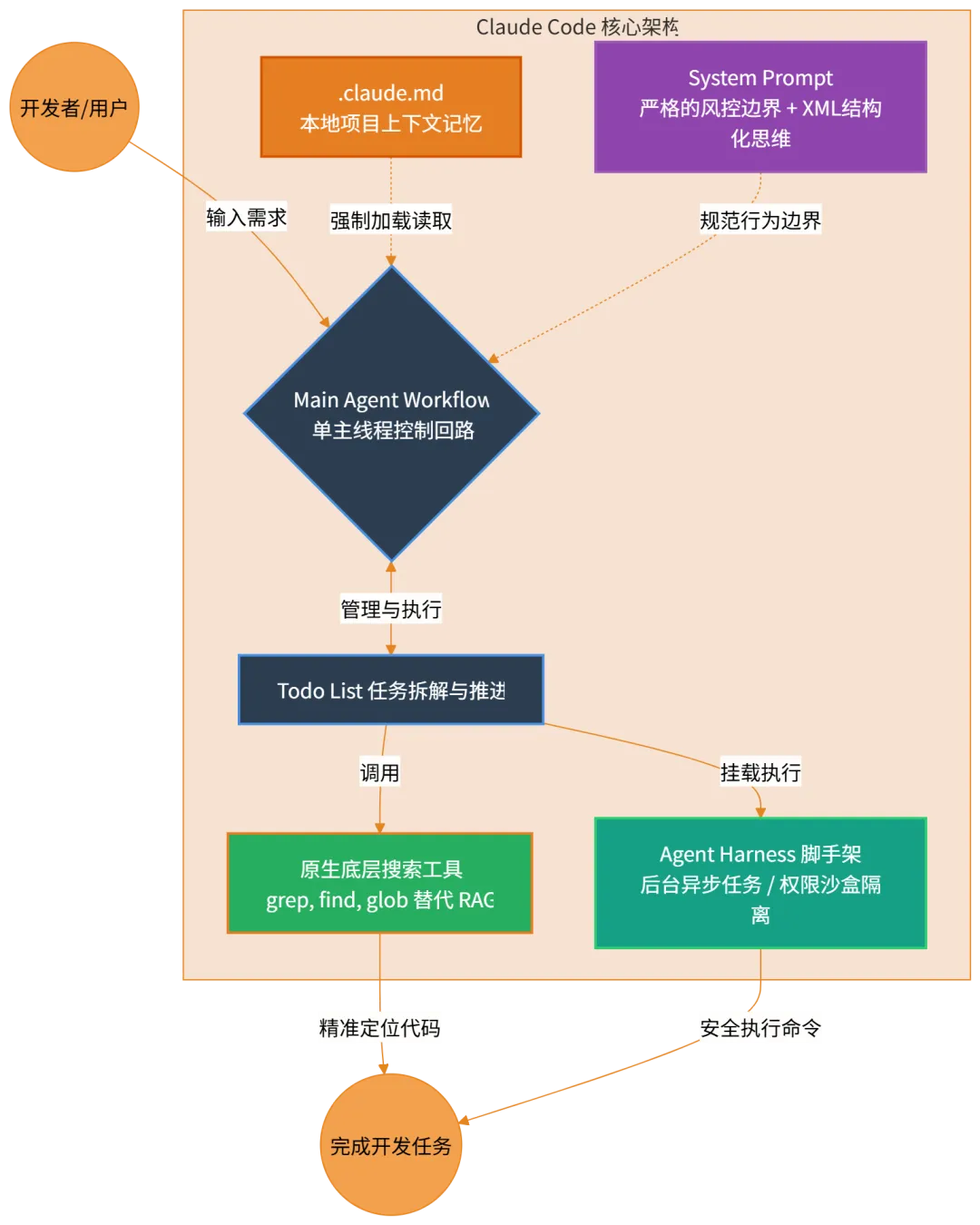
一、化繁为简:放弃复杂多智能体,回归主循环与 Todo List
在当前的 Agent 开发圈子里,大家非常热衷于设计复杂的“多智能体(Multi-Agent)”架构,给不同的 AI 分配角色,让它们相互对话、辩论和协作。然而,Claude Code 的源码却给这种趋势泼了一盆冷水。
Claude Code 并没有采用复杂的多智能体系统,它的核心控制回路(Control Loop)异常简洁:主要依赖一个单主线程(Main Agent Workflow)。
它之所以能处理复杂的工程任务,秘诀在于非常出色的 Todo 列表管理机制。面对复杂需求,Claude Code 会将大目标拆解为一个个具体的小任务,排好优先级,并记录在案。主 Agent 就像一个按部就班的资深工程师,严格按照 Todo 列表一步步推进,完成一项划掉一项。这种“One loop & Bash is all you need”的设计思路,不仅让 AI 的执行路径格外清晰,也让整个系统的稳定性和可调试性得到了质的飞跃。
二、反直觉的检索设计:抛弃向量 RAG,回归原生搜索
过去一年里,RAG(检索增强生成)几乎成了 AI 应用的标配,许多代码助手都会使用基于 Embedding 向量的索引来搜索代码。但 Claude Code 的源码揭示了一个令人反直觉的事实:它根本没有使用基于向量的 RAG 技术。
Anthropic 的工程师认为,对于逻辑严密、符号化特别强的代码工程来说,模糊的向量相似度匹配往往并不好用。Claude Code 采取的方式是:直接给大模型配备底层的文件搜索工具。
它内置了类似于 Linux 系统中的 grep、find、glob 等原生搜索命令。当需要查找某个函数或变量时,Claude 就像一个真实的人类程序员一样,利用正则表达式和关键字在代码库中进行准确搜索。事实证明,大模型非常擅长编写复杂的正则查询语句,这种“模仿人类行为”的搜索方式,在代码场景下比 RAG 更加灵活、准确且迅速。
三、四两拨千斤的上下文管理:.claude.md
如果你使用过 Claude Code,会发现它对项目背景的理解异常敏锐。源码中揭示了这个奇妙体验的来源——对 .claude.md(或类似配置文件)的充分利用。
在执行重要的请求时,Claude Code 的工作流会强制读取项目根目录下的这个 Markdown 文件。这个文件就像是 Agent 的“记忆挂载盘”,技术人员可以在里面写入项目的技术栈、编译命令、代码规范,甚至是“永远用中文回复”等强制性偏好。
这个看似简单的设计解决了 Agent 开发中的一大痛点:上下文冗余与幻觉。AI 不需要每次都通过盲目搜索来猜测项目的运行方式,也不需要在多轮对话中反复确认用户偏好。用到什么知识,就临时加载什么知识,这种轻量级的本地上下文管理,显著地提升了交互的准确率和用户体验。
四、教科书级的 Prompt 工程:用严厉的规则“驯服”猛兽
本次泄露的重头戏是长达数万字的 System Prompt。这份提示词向我们展示了 Anthropic 是如何通过纯文本指令来构建一个高度可靠的安全与行为边界的。
首先是 XML 标签的广泛应用。Claude Code 的提示词中大量使用了 <thinking>、<tools> 等 XML 标签。这种高度结构化的指令不仅帮助大模型更好地理解复杂的逻辑层级,也让输出结果更容易被外层的代码解析和拦截。
其次是非常严厉的语气与风控边界。因为大模型的输出具有概率分布的不可控性,Anthropic 在提示词中使用了大量诸如 “CRITICAL”(致命/关键)、”IMPORTANT”(重要)、”NEVER”(严禁)等大写词汇。例如,提示词中多次强调“仅协助防御性安全任务”,并严格规定了在遇到破坏性指令时的升级路径。这种在控制层面对行为边界的死磕,是保证 Agent 在拥有核心系统权限时依然安全的根本。
五、代码即脚手架:Agent Harness 工程的胜利
在开源社区对源码的分析中,有一个观点被反复提及:“The model is the agent, the code is the harness”(模型就是智能体,代码就是脚手架)。Claude Code 之所以强大,不仅仅是因为 Claude 3.5 Sonnet 模型本身聪明,更在于外围那一套十分健壮的工程代码。
源码中展示了许多精妙的脚手架设计。例如后台任务(Background Tasks)机制:当需要执行耗时的编译或测试命令时,代码框架会将这些慢操作丢到后台异步执行,并让 Agent 继续思考下一步,而不是傻傻等待;再比如沙盒与权限隔离:CLI 实现了细粒度的文件系统权限控制,通过白名单和黑名单机制准确管理文件的读写权限,在执行 Bash 命令时还有安全检查机制,防止越权操作。
Claude Code 的泄露不仅没有损害其神级工具的地位,反而为全行业的 AI 从业者提供了一份出色的参考架构。它告诉我们,构建一个好用的 Agent,不需要盲目追逐前沿、高度复杂的学术概念。用非常清晰的主循环控制流程、高度贴近人类直觉的工具链、完全结构化的提示词,再加上扎实的工程脚手架,就足以打造出令人惊叹的智能体验。这些务实的设计哲学,值得每一位 AI 探索者在自己的项目中实践与深思。