 夜雨聆风
夜雨聆风





别瞎花钱了!我测完 18 个文档 6 类场景,告诉你怎么选适合你的OCR 模型?(项目已开源+实测数据)
起因:73k Star 之后,朋友们问了个问题!
前几天 PaddleOCR 登顶 GitHub OCR 榜单,Star 数突破 73k+,成为全球最受欢迎的开源 OCR 项目。我在 X 上分享了这个消息,评论区直接炸了。
好几个朋友都在问同一件事:“智谱的 GLM-OCR 最近也挺火的,号称专门做文档识别,你能不能测一下,跟 PaddleOCR 比到底谁更好用?”
说实话,我也好奇。
两个模型参数量都是 0.9B,都有免费的 Cloud API,但架构思路完全不同。官方跑分看着都挺好,不如自己动手测测看。
我这里直接使用了本地脚本+API 的方式快速可以测试到结果的方式进行!
于是就有了这篇免费自来水,自己用了 Claude Code Sonnet4.6 帮我撰写测试脚本,最后来撰写实测的文章。
两位选手:同样 0.9B,不同的路

在开始测试之前,先介绍一下两个模型的背景和核心差异。
OCR(Optical Character Recognition,光学字符识别):把图片里的文字“读出来”,变成可编辑文本的技术。你手机扫描名片、银行识别卡号、PDF 论文转 Word,背后都是 OCR 在干活。就像给计算机装了一双能读字的眼睛。
传统 OCR 只认识印刷体,遇到公式、表格、手写笔记就会出错。近两年出现了基于视觉语言模型(VLM)的新一代 OCR,它们能同时理解图像内容和文字语义,识别能力大幅提升。
这次测试的两位选手,都采用了相同的两阶段架构,甚至共享同一个布局分析模型。
GLM-OCR(智谱 AI)
GLM-OCR 是智谱 AI 推出的轻量级 OCR 模型,参数量 0.9B,基于 GLM-V 编码器-解码器架构 + CogViT 视觉编码器。
它采用两阶段 Pipeline:先用 PP-DocLayout-V3 进行布局分析,将页面切分成不同区域,再通过 GLM-V 多模态模型对各区域进行并行识别。
模型引入了多令牌预测(MTP)损失和稳定的全任务强化学习,提升训练效率和泛化能力。
-
擅长手写体、印章、代码、复杂表格和公式
-
输出含版面坐标(bbox),可精确还原文档空间结构
-
支持 vLLM / SGLang 本地部署,速度 1.86 页/秒
-
Cloud API 免费额度:open.bigmodel.cn
PaddleOCR-VL-1.5(百度飞桨)
PaddleOCR-VL-1.5 是百度飞桨团队的新一代文档识别模型,同样 0.9B 参数。
它同样采用两阶段 Pipeline:先用自家开发的 PP-DocLayout-V3 进行布局分析,将页面切成若干区域(标题、正文、表格、公式……),再让 VLM 按区域逐一识别,最后拼接成完整的 Markdown。
-
Pipeline 架构对复杂版面耗时更稳定
-
支持 80+ 语言,中英文混排开箱即用
-
GitHub 73k+ Star,国内最广泛使用的开源 OCR 项目
-
支持昆仑、昇腾等国产 GPU
-
Cloud API 免费额度:aistudio.baidu.com
架构对比一览
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
一句话总结:两个模型都采用“先布局分析、再识别”的两阶段流程,甚至共享同一个布局分析模型 PP-DocLayout-V3(百度飞桨开发)。
性能差异主要来自识别阶段:GLM-OCR 使用 GLM-V + 强化学习训练,PaddleOCR 使用 VLM + 传统监督学习。
测试怎么做的

评测基准:OmniDocBench
OmniDocBench:由上海人工智能实验室(OpenDataLab)发布的文档理解评测基准,发表于 CVPR 2025。完整版包含 1355 页真实文档,涵盖 9 种文档类型。可以理解为 OCR 界的“高考”。
本次我用的是 OmniDocBench 的公开 Demo 子集,共 18 张图片,覆盖 6 类典型场景:中文电子书(4 张)、学术论文(2 张)、教材(4 张)、报纸(2 张)、手写笔记(2 张)、PPT/研报(4 张)。
测试流程
-
将 18 张图片逐一通过 Cloud API 发给两个模型,收集 Markdown 格式的识别结果
-
使用 OmniDocBench 官方评测脚本(pdf_validation.py),将模型输出与人工标注 Ground Truth 逐块对比
-
计算各项指标并生成对比报告
为了大家方便自己测试,我直接将我的测试脚本开源给大家使用。
记得 Star⭐️啊,兄弟们!
基于 OmniDocBench 的 OCR 模型基准测试框架,对比评测 GLM-OCR 和 PaddleOCR-VL-1.5 两款 0.9B 参数多模态模型在真实文档场景下的识别能力。
覆盖文本识别、表格解析、公式识别、版面检测、阅读顺序等多维度评测,支持一键运行推理、评测和报告生成。
项目地址:
https://github.com/andyhuo520/ocr_benchmark
测试环境
-
硬件:Apple M1 Pro 32GB
-
网络:Cloud API 调用
-
评测工具:OmniDocBench v1.5 官方脚本
-
测试时间:2026 年 4 月 1 日
💡 所有测试图片和输出结果均来自真实测试,数据可复现验证。
评估指标说明
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
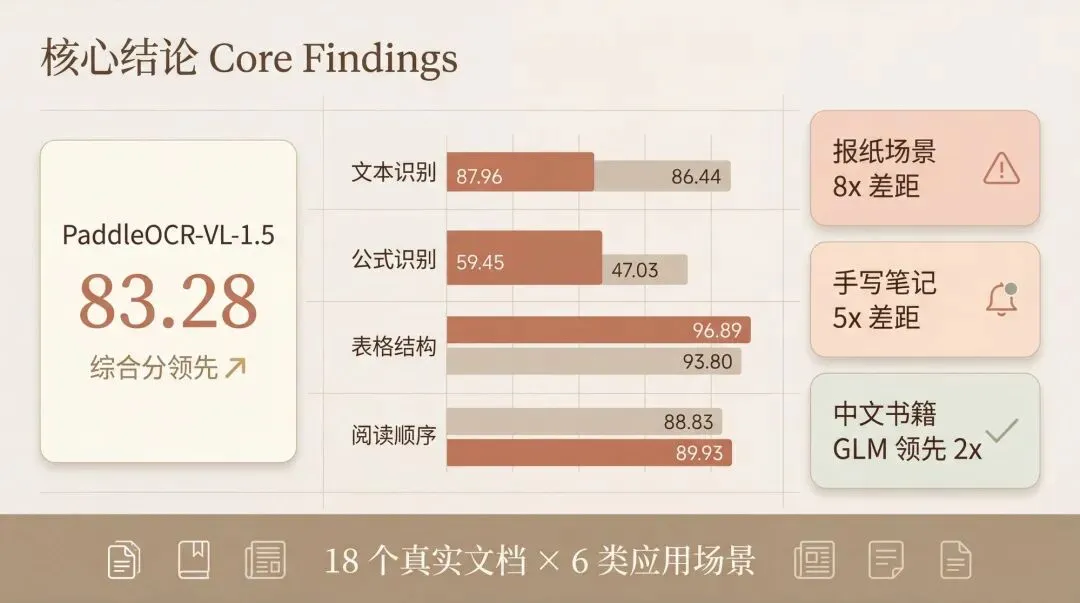
综合分公式:综合分 = ((1−文本 ED) + (1−公式 ED) + 表格 TEDS + (1−阅读顺序 ED)) ÷ 4 × 100,满分 100。
总成绩:PaddleOCR 领先近 4 分
直接上结果:
|
|
|
|
|
|---|---|---|---|
|
|
|
87.96 |
|
|
|
|
59.45 |
|
|
|
|
96.89 |
|
|
|
89.93 |
|
|
|
|
|
|
|
PaddleOCR 在文本、公式、表格三个维度全面领先,GLM-OCR 只在阅读顺序上小幅胜出(差距不到 1.1 分)。
两个模型的公式识别都是短板,错误率超过 40%。这个方向,整个行业还有很长的路要走。
但总分只是一个数字,真正有价值的是逐个场景看细节。下面我把每一类文档的测试图片和两个模型的实际 OCR 输出都展示出来,大家自己判断。
📚 场景一:中文电子书
测试样本:双栏混合排版 · 学术讨论类正文胜者:GLM-OCR(ED 0.0958 vs 0.2195)

|
|
|
|
|
|---|---|---|---|
|
|
0.0958 |
|
|
GLM-OCR 输出(耗时 7.2s)
与通常一般意义上理解的文学创作或文学作品的“文学”字面一样,所以,弄得“比较文学”成为一个“有缺陷的词”。$^{1}$ 因此,为了减少像比较文学那样的歧义,我们在学科的命名上使用“美术学”,而不使用“美术”这个名称来框定这个跨越中西双方的美术研究的工作,是为了使“中西比较美术学”中的“美术学”不让人往“美术作品”或“美术创作”方面认识。不仅如此,仅从名称上看,“美术学”是一个学科名称(1990 年国务院学位委员会专业目录调整会议决定,将“美术历史与理论”专业正式改名为“美术学”,成为一级艺术学下属的二级学科),与“美术”(Fine Art)这个词是有区别的。
PaddleOCR-VL-1.5 输出(耗时 17.9s)
与通常一般意义上理解的文学创作或文学作品的“文学”字面一样,所以,弄得“比较文学”成为一个“有缺陷的词”。$^{1}$ 因此,为了减少像比较文学那样的歧义,我们在学科的命名上使用“美术学”,而不使用“美术”这个名称来框定这个跨越中西双方的美术研究的工作,是为了使“中西比较美术学”中的“美术学”不让人往“美术作品”或“美术创作”方面认识。不仅如此,仅从名称上看,“美术学”是一个学科名称(1990 年国务院学位委员会专业目录调整会议决定,将“美术历史与理论”专业正式改名为“美术学”,成为一级艺术学下属的二级学科),与“美术”(Fine Art)这个词是有区别的。
这一页两个模型输出几乎一模一样,标点、注释编号、专业术语都没问题。GLM 的编辑距离更低,可能得益于其强化学习训练策略对长文本连贯性的优化。
中文书籍场景,GLM-OCR 明显更强。
📄 场景二:学术论文(公式密集)
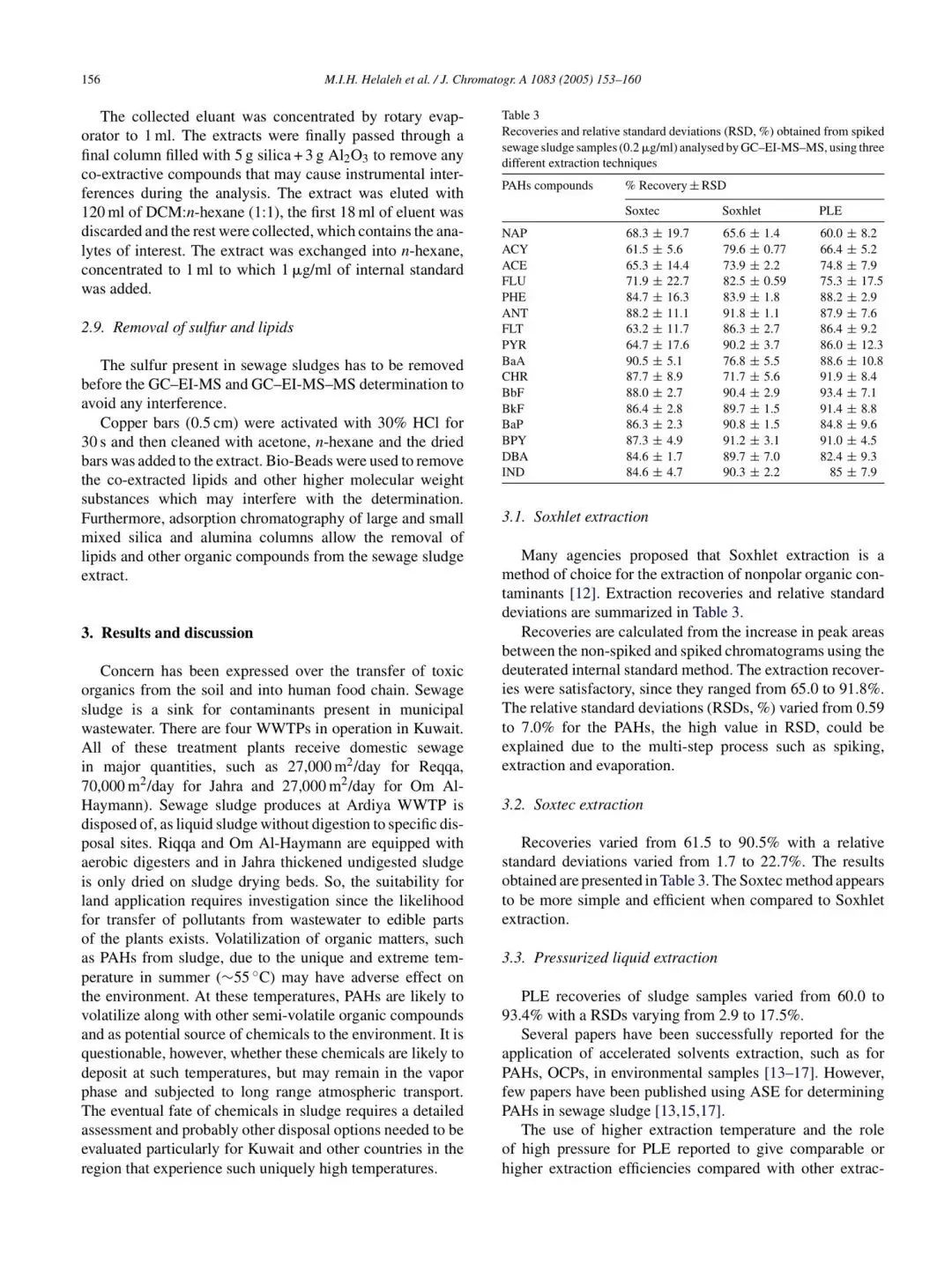
测试样本:英文 SciHub 论文 · LaTeX 公式 · 化学数据表胜者:GLM-OCR(ED 0.0125 vs 0.0194,但耗时差距巨大)
|
|
|
|
|
|---|---|---|---|
|
|
0.0125 |
|
|
GLM-OCR 输出(耗时 87.2s)
Removal of sulfur and lipids
The sulfur present in sewage sludges has to be removed before the GC-EI-MS and GC-EI-MS-MS determination to avoid any interference. Copper bars (0.5 cm) were activated with 30% HCl for 30 s and then cleaned with acetone, n-hexane and the dried bars was added to the extract. Bio-Beads were used to remove the co-extracted lipids…
PaddleOCR-VL-1.5 输出耗时 23.4s
Removal of sulfur and lipids
The sulfur present in sewage sludges has to be removed before the GC–EI-MS and GC–EI-MS–MS determination to avoid any interference. Copper bars (0.5 cm) were activated with 30% HCl for 30 s and then cleaned with acetone, n-hexane and the dried bars was added to the extract. Bio-Beads were used to remove the co-extracted lipids…
分析:两个模型对标准英文学术排版都能轻松应对,输出几乎一致。但耗时差距巨大:GLM 花了 87.2 秒,PaddleOCR 只用了 23.4 秒。公式密集页面让 GLM 的识别阶段承受了很大的计算压力。结论:文本质量两者不相上下,但 GLM 在公式密集页面的耗时不可预期。
📖 场景三:教材(中英文)
数学练习册 · 分数符号 · 多选项排布 · 图文混排
测试样本:英文数学练习册 · GLM 文本 ED 0.0957 vs Paddle 0.1353
|
|
|
|
|
|---|---|---|---|
|
|
0.0957 |
|
|
GLM-OCR 输出耗时 2.1s


再看一张中文彩色教材:

测试样本:小学语文练习卷(含拼音和手写生字)
题目和分数选项两个模型都识别对了。有个小区别:GLM 按原文横向排列(A-C-B-D),PaddleOCR 自动重排成了顺序(A-B-C-D)。中文教材那张,GLM 把“咩咩”看成了“哗哗”,拼音声调也有点问题;PaddleOCR 在生字上也有偏差,但拼音整体更准。
教材场景 GLM 稍微领先一点,不过两个都够用。
📰 场景四:报纸(复杂多栏)
三至四栏混合 · 小字体 · 高密度文本 · 差距最大的场景

测试样本:中文传统报纸 · GLM 文本 ED 0.5246 vs Paddle 0.0658(差距 8 倍)
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
GLM-OCR 输出耗时 100.8s
本报记者 蔡茂楷
在中央财政支款下,融资安全受较大影响,可用“财政、金融等各类资金支持”。中央财政支持的资金,95% 将选在 30% 的 3M 办公软件上,资金供应量占全省 30% 的 9 单办公软件,出出国资金
改生态,要宜居好环境。在其“大院”门厅的东端,早在 1990 年,有数百名白鹭自南向北飞来于门廊山坡上山林。
记者采集本地大型鸟类各产区区鸟类,在城镇核心区的大型鸟类采集数据,每隔 300 米就收集了一台 TFC 型太阳能出虫器
自理设备应用在安保实验以来,多次通过建立击虫监测点,配备 TEC 太阳型灭虫虫,击虫灯,双眼灭虫灯,生物显微镜,机示显微镜等设备提升茶叶质量。
PaddleOCR-VL-1.5 输出耗时 15.3s
在中央财政支持下,福建突出无性系良种大面积推广应用,现在,全省拥有国家级茶树良种 19 个,省级良种 21 个,无性系良种推广面积达 95%,远高于全国 35% 的平均水平,居全国领先地位。
☑本报记者蔡茂楷
福建具有“茶之乡”“茶之祖”等诸多美誉。2008 年以来,为推进现代茶产业,围绕“五促进,两带动”的目标,中央财政连续三年注入资金,总额达 2.29 亿元,整合省相关部门资金 4.33 亿元投入茶产业。
记者来到全国最大乌龙茶主产区安溪县,在城区茶叶公园的生态茶园里,记者看到,每隔 500 米就安装了一台 TFC 型太阳能灭虫器。工作人员李旭云介绍说,灭虫器收集取之不尽的太阳能作为能源,针对害虫生活习惯,诱杀害虫。
红色标注的是 GLM-OCR 的“幻觉”输出。原文说的是“福建茶产业”,GLM 输出了“3M 办公软件”“出出国资金”;原文说“乌龙茶主产区安溪县”,GLM 读成了“大型鸟类各产区区鸟类”;“太阳能灭虫器”变成了“太阳能出虫器”。这些词在原文中根本不存在。
再看第二张报纸(英文联邦公报):

测试样本:英文联邦公报(多栏法律文书)
两个模型使用同一个布局分析模型(PP-DocLayout-V3),但 GLM 在多栏复杂版面上表现不稳定,问题出在识别阶段:GLM-V 在处理复杂切分区域时容易产生幻觉内容。PaddleOCR 的 VLM 识别模型更稳健,就算某一块出问题,也不会把整页带偏。
报纸场景是 GLM 的重灾区。如果你的业务会碰到多栏复杂版面,这个风险得考虑清楚。
✍️ 场景五:手写笔记

印刷+手写混合 · 含表格 · GLM 出现严重乱码

测试样本:中文课堂手写笔记 · GLM 文本 ED 0.1885 vs Paddle 0.0359(差距 5 倍)
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
GLM-OCR 输出耗时 2.7s
(4) 天气预报的内容:
① 卫星云图:蓝色表示海洋,绿色表示陆地,白色表示云区
② 斑币天报搬胀、配币一日内削膈、PL 晶光挂水晕常烦痛。另外还护莎尘雾空晕雾、痰水、太象雾所报报。
PaddleOCR-VL-1.5 输出耗时 14.8s
(4) 天气预报的内容:
① 卫星云图:蓝色表示海洋,绿色表示陆地,白色表示云区
② 城市天气预报:说明一日内阴晴、风、气温和降水等常规情况,另外还有沙尘暴、空气质量、海浪、冰雹、大雾等特殊预报。
前半部分两者都正确。但到了第②条手写内容,GLM-OCR 彻底崩溃:“城市天气预报”变成了“斑币天报搬胀”,“降水”变成了“痰水”,“大雾”变成了“空晕雾”。
再看第二张手写笔记(英语语法笔记):

测试样本:英语语法手写笔记(以印刷体为主)
GLM-OCR 输出耗时 2.0s
Which hotel have you booked for your holiday?
(为了度假你预订了哪家族馆?)
(4) 疑问代词不分单复数,视它所替代的人或事物决定单复数,但是通常用单数;如果修饰名词,则以名词的单复数力填。
each other, one another 是相互代词,译为“互相”。可以通用。each other 表示两者之间,而 one another 表示许多人之间,它们有绚丽格形式。
PaddleOCR-VL-1.5 输出耗时 10.9s
—Which hotel have you booked for your holiday?
(为了度假你预订了哪家旅馆?)
(4)疑问代词不分单复数,视它所替代的人或事物决定单复数,但是通常用单数;如果修饰名词,则以名词的单复数为准。
each other, one another 是相互代词,译为“互相”,可以通用。each other 表示两者之间,而 one another 表示许多人之间。它们所有格形式:each other‘s, one another’s.
就算是印刷体为主的笔记,GLM 也翻车了好几处:“哪家旅馆”→“哪家族馆”,“为准”→“力填”,“所有格”→“绚丽格”。PaddleOCR 这些全对。
手写笔记场景,PaddleOCR 稳定性强太多了。
📊 场景六:PPT / 研报
语文教学 PPT · 金融研报 · 图文并茂 · 含表格数据

测试样本:语文教学 PPT(诗词赏析)
|
|
|
|
|
|---|---|---|---|
|
|
0.1417 |
|
|
GLM-OCR 输出耗时 35.1s
“游人”指那些忘了国难,苟且偷安,寻欢作乐的南宋统治阶级。诗人面对这不停的歌舞,看着这些“游人们”陶醉其中,不由得表现出自己的感慨之情。其中,“暖风”一语双关,在诗歌中,既指自然界的春风,又指社会上淫靡之风。在诗人看在,正是这股“暖风”把“游人”的头脑吹得如醉如迷,忘记了自己的国家正处于危难之中。
PaddleOCR-VL-1.5 输出耗时 9.9s
“游人”指那些忘了国难,苟且偷安,寻欢作乐的南宋统治阶级。诗人面对这不停的歌舞,看着这些“游人们”陶醉其中,不由得表现出自己的感慨之情。其中,“暖风”一语双关,在诗歌中,既指自然界的春风,又指社会上淫靡之风。在诗人看在,正是这股“暖风”把“游人”的头脑吹得如醉如迷,忘记了自己的国家正处于危难之中。
再看一张金融研报:

测试样本:常熟银行投资研报(含财务数据表格)
两个模型都正确识别了股票代码(601128. SH)、股价(7.15 元)、表格中的财务数据(总市值 196 亿元、资产负债率 92.1%)等。GLM 的输出保留了 bbox 坐标信息,PaddleOCR 的表格 HTML 结构更完整。
结论:PPT 和研报场景,两者表现接近,GLM 略胜。排版相对简单时,两个模型都很稳。
阅读顺序:共享 PP-DocLayout-V3 却结果不同?
两个模型都使用 PP-DocLayout-V3 做版面分析,按理说阅读顺序应该完全一致。实测发现并非如此:
|
|
|
|
|
|---|---|---|---|
|
|
0 |
|
|
|
|
0 |
|
|
|
|
0 | 0 |
|
|
|
0 | 0 |
|
|
|
|
0.1101 |
|
|
|
|
0.1692 |
|
|
|
0.1111 |
|
|
|
|
0.3333 |
|
|
原因分析:虽然两者共用 PP-DocLayout-V3 做版面检测,但从 API 端输出 Markdown 时,区块的拼接顺序受到各自后处理逻辑的影响。PaddleOCR API 严格按 block_order 拼接(有时表格/副文被提前),而 GLM-OCR 的 Pipeline 在拼接时做了额外的顺序调整,某些场景下更贴近人类阅读习惯。
⏱️ API 响应耗时:平均值骗人
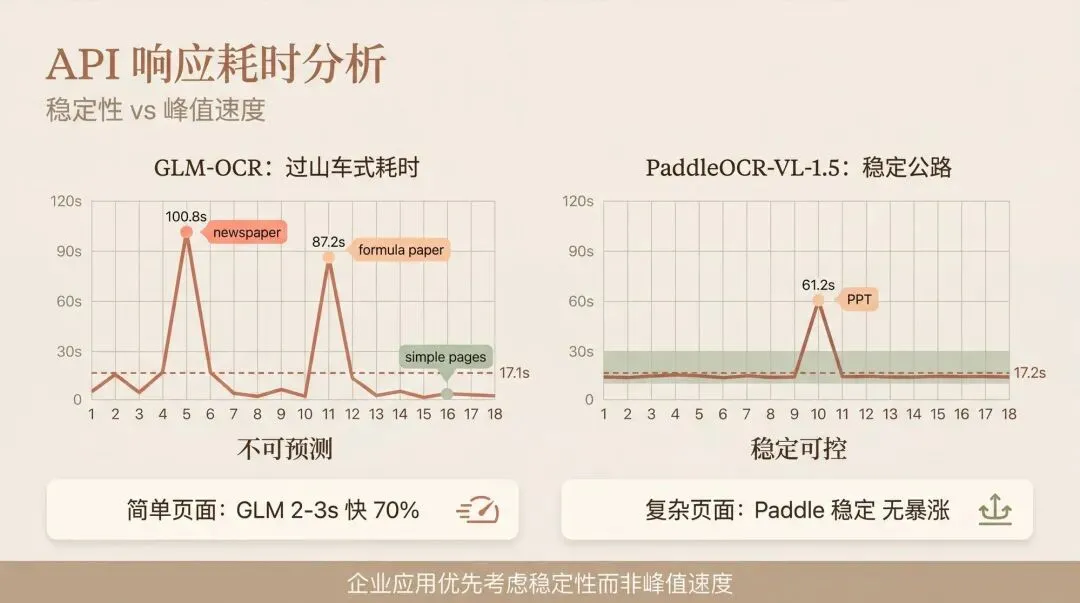
两个模型的平均 API 响应耗时几乎相同:GLM-OCR 17.1 秒,PaddleOCR 17.2 秒。但这个平均值掩盖了本质差异。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
GLM 的耗时像坐过山车:简单页面 2-3 秒飞快,但遇到报纸直接飙到 100.8 秒,公式密集的论文也要 87.2 秒。去掉这两个极端值,GLM 平均只要 7.4 秒左右。
PaddleOCR 的耗时就稳多了,大部分在 10-30 秒之间,唯一的例外是一张 PPT 用了 61.2 秒。
这就是两种架构的性格差异。GLM 处理简单页面快得飞起,但复杂版面就说不准了。PaddleOCR 速度不是最快的,但基本不会慢到离谱。对企业应用来说,稳定性往往比峰值速度更重要。
一个有趣的统计学现象
看完分场景数据,你可能注意到一个矛盾:按文档来源细分,GLM-OCR 在 9 个类别中赢了 6 个,PaddleOCR 只赢了 3 个。但综合分反而是 PaddleOCR 领先。
这是统计学中经典的辛普森悖论。
辛普森悖论(Simpson‘s Paradox):一个趋势出现在几组不同的数据中,但当数据合并时,趋势反转了。就像一支篮球队在大多数节次得分领先,但因为某一节被对手暴打,总分反而落后。
原因很简单:GLM 赢的那些类别,赢得很小(书籍 ED 差距 0.12);但 GLM 输的两个类别,输得很大(报纸 ED 差距 0.46,手写笔记差距 0.15)。巨大的落差吞噬了所有优势。
这也提醒我们:选模型不能只看“赢了几个场景”,还得看“输的时候输得有多惨”。
场景选型建议
说了这么多数据,最实际的问题是:我的场景该选哪个?
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
总体建议:如果你不确定选哪个,默认选 PaddleOCR-VL-1.5。它在文本、公式、表格、耗时稳定性上综合更优,开源生态成熟(73k+ Star),国内生产环境验证也多。
GLM-OCR 适合两个明确场景:一是中文书籍/教材的高精度识别(特别是需要版面坐标还原的时候),二是团队已经在用智谱 AI 生态的。
最后说几句
写这篇文章的初衷很简单,就是想给大家一个客观的参考。两个模型都是 0.9B 参数量,都有免费 Cloud API,都在快速迭代。今天的测试结论,可能几个月后就会因为模型更新而变。
但有一点值得记住:短板决定下限。
GLM 在报纸上输出“3M 办公软件”“太阳能出虫器”那一刻,不只是一个 OCR 错误。它意味着如果你的文档流水线里混进了一张复杂排版的扫描件,整条流水线的结果都不可信了。
PaddleOCR 的 Pipeline 架构虽然不是每个场景都最优,但它有种“优雅的降级”能力:某个区域识别不好,不会把整页带崩。
这次测试用的只是 OmniDocBench 的 18 页 Demo 子集。有时间的话,我后面会跑完整版 1355 页的测试,到时候再跟大家分享。
有问题欢迎留言讨论。
项目地址:
https://github.com/andyhuo520/ocr_benchmark
交流:358848136