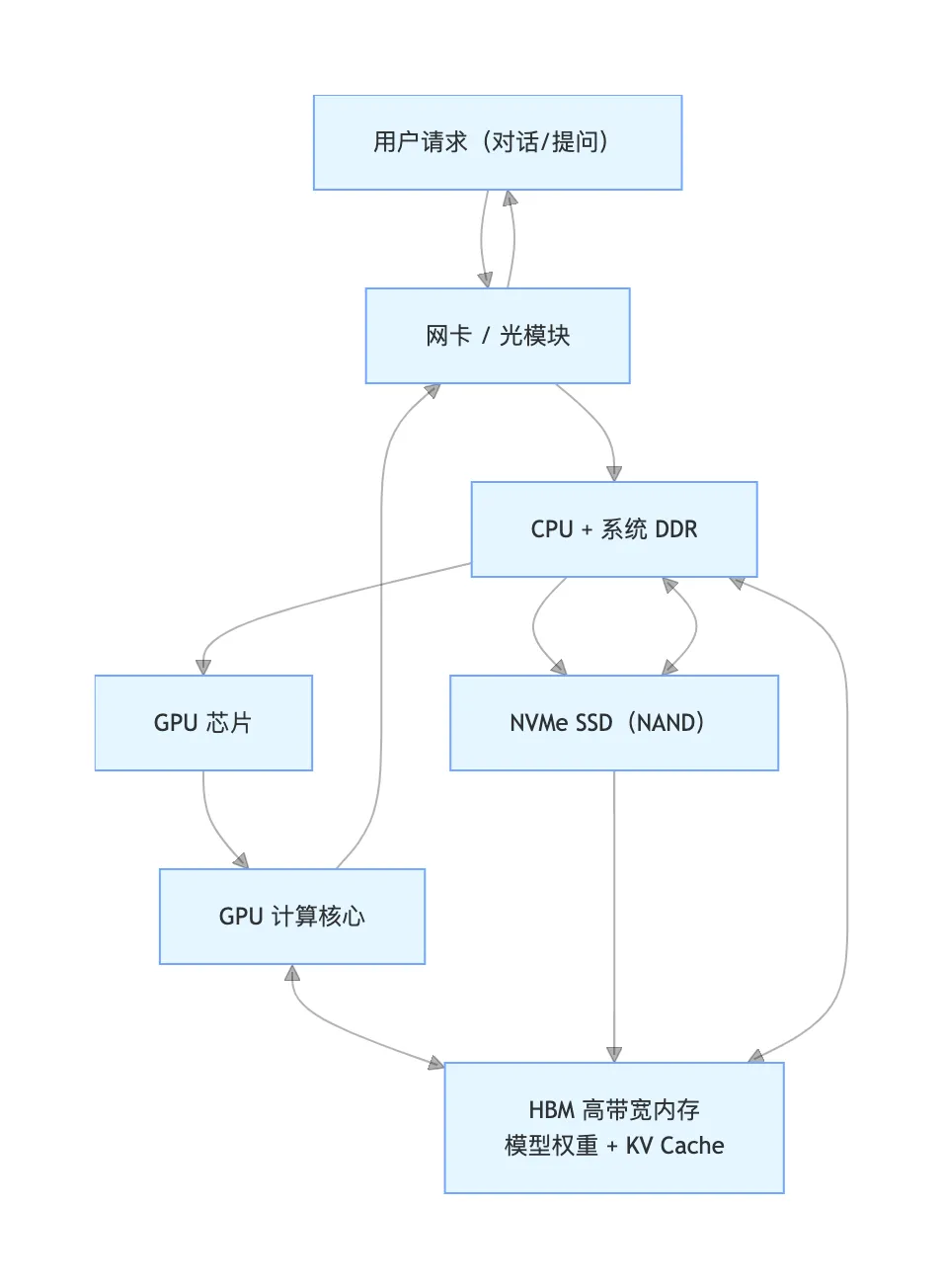
一张图说明大模型推理时代的瓶颈是存储 单 GPU 推理服务器・数据流向图 注意是单GPU机器 各个节点作用解释: 网卡 / 光模块的作用: 只收用户请求、回结果,几乎无大数据传输 CPU + 系统 DDR 的作用: 排队、调度用户请求 从向量库(NAND)做 RAG 检索 把模型权重加载到 GPU GPU 卡的作用: 推理计算 HBM(高带宽内存)的作用: 存放:模型权重 + KV Cache 推理真正的瓶颈所在 NVMe SSD(NAND 闪存)的作用: 存放: 完整模型文件(7B/70B/130B) RAG 向量数据库(海量知识库) 历史对话、冷 KV Cache 关键流向解释(非常重要) 1. 数据从进→出,不横向乱跑 用户请求进来 → 网卡 → CPU → GPU GPU 算完 → 结果直接回用户 GPU 之间、服务器之间几乎不通信 2. 光模块只做 “轻量级收发” 只传用户提问和回答(KB~MB 级) 不传模型、不传梯度、不传大参数 → 所以光模块压力极低 3. 真正的数据流全部发生在: GPU ↔ HBM ↔ DDR ↔ NAND 这就是存储内部循环,和网络无关。 瓶颈到底在哪? 一眼看懂 HBM 瓶颈 装不下 KV Cache → 并发上不去 DDR 瓶颈 调度、队列、RAG 检索卡住 NAND 瓶颈 向量库太大、检索太慢 光模块?几乎没有瓶颈 一句话总结: 推理 = 存储内部循环 训练 = 网络集群狂飙 所以推理时代,存储才是 C 位。
 夜雨聆风
夜雨聆风