夜雨聆风
夜雨聆风





Graphify:给 AI 编码助手装上知识库,Token 消耗降到 1/72

大家好,我是寂寞的熊猫。
之前写过一篇RAG 每次都从零开始,而 Karpathy 让知识”编译一次,反复使用”,说 RAG 每次查询都从零开始,没有积累,没有复用。很多人看完问:”道理我懂,有没有现成工具?”
今天给大家介绍一个基于Karpathy的知识库理论的skill。
省流版
- Graphify v3 是一个 AI 编码助手 Skill,支持 Claude Code、Codex、OpenCode、OpenClaw、Trae、Factory Droid,把任意文件夹(代码 + 文档 + 图片)编译成持久化的知识图谱
- 官方基准测试,52 个文件的混合语料库,Token 消耗降到原来的约 1/72。越复杂的项目收益越大,小项目降幅有限
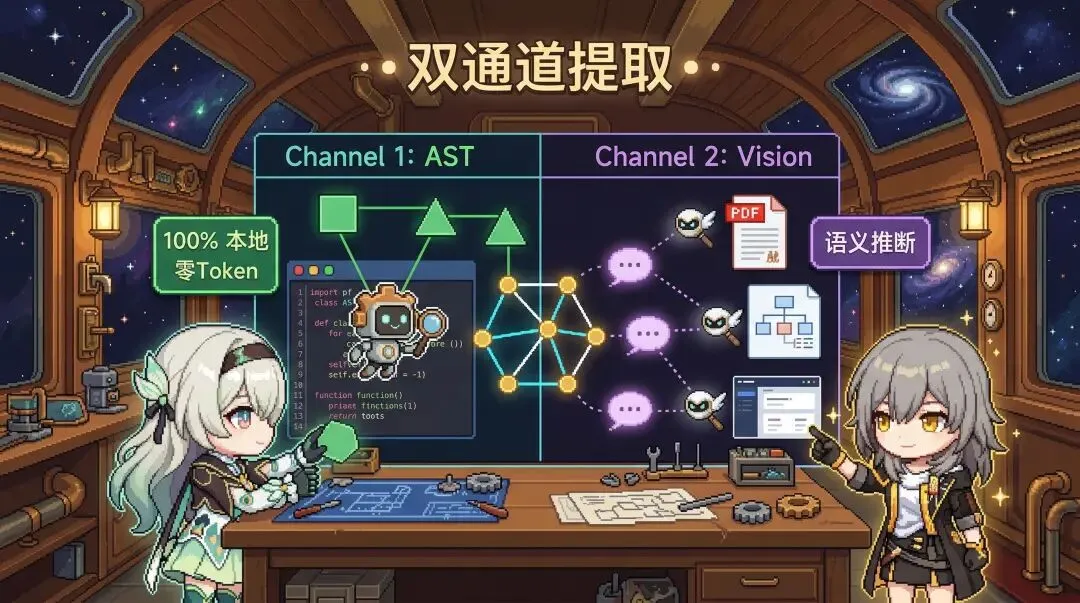
- 代码结构用 Tree-sitter 本地解析,不走 LLM,零 Token;文档和图片用 Claude Vision 子智能体并行提取,两条通道互不干扰
- 支持 8 种导出格式,包括 Obsidian Vault、Neo4j、MCP 服务器,能直接接入你现有的工具链
GitHub 地址:https://github.com/safishamsi/graphify/tree/v3[1]
AI 编码助手为什么总在”重新读代码”
用 Claude Code 的人应该都遇到过:让 AI 理解一个中型项目,它先 glob 扫文件结构,再 grep 搜关键函数,然后一个一个文件地读。几十个文件下来 Token 烧了一堆,结果对项目架构的理解还是浮在表面。
更烦的是每次开新会话都得重来。关掉终端,它对代码库的理解就归零。
这不是 bug。所有基于文件系统的 AI 编码助手都有同样的结构性问题。
Token 层面先崩。 理解一个跨模块调用链,AI 可能要把大量不相关的样板代码读进上下文窗口。试错式的读法,Token 消耗指数级上升。
然后是上下文窗口本身在浪费。 中间位置的内容被模型忽略,论文里叫 Lost in the Middle 现象。
最大的问题是认知不持久。 每次对话都是冷启动,之前梳理出来的调用关系、架构理解全部丢失。
Graphify 做的事用一句话概括:别让 AI 每次都从零开始读文件,提前把代码库编译成知识图谱,让 AI 直接查图。
这个思路和之前聊的 Karpathy 知识编译是同一件事。Karpathy 把它叫做”持久化、可复利的产物”。知识编译一次,持续维护,不每次查询时重新推导。上次聊的是文档领域,Graphify 把这个范式搬到了代码 + 文档 + 图片的混合领域。
双通道提取:确定的归确定,模糊的归模糊
Graphify 的核心流程是:扫描文件夹 → 双通道提取实体和关系 → 构建 NetworkX 图谱 → Leiden 聚类 → 生成报告和导出。流程不复杂,但拆法值得展开。
第一通道:AST 解析,不走 LLM
用 Tree-sitter 对代码做抽象语法树分析,支持 20 种编程语言。这一步完全在本地跑,零 Token 消耗,零网络请求。
提取出来的东西包括:类、函数、接口声明作为图谱节点;import/require 关系作为 IMPORTS 边;跨文件函数调用栈作为 CALLS 边。
有一个设计我觉得特别聪明:它会把代码里带 # TODO:、# HACK:、# WHY: 这类标记的注释提取出来,自动生成 rationale_for 关系节点。啥意思呢?把开发者的架构意图和代码实现做了硬连接。AI 做重构的时候能直接看到某段看似不合理的代码背后有什么历史原因,不用再猜。
第二通道:多模态语义提取
PDF 论文、架构图、会议纪要、截图,AST 解析不了这些东西。Graphify 会启动多个 Claude 视觉子智能体并行处理,从中提取概念、实体和设计原理。
两条通道的结果合并到一个 NetworkX 图里。代码结构是确定性的,100% 可信;文档推断是概率性的,附带置信度分数。这种解耦的好处是:代码的底层逻辑不会被模型幻觉污染。
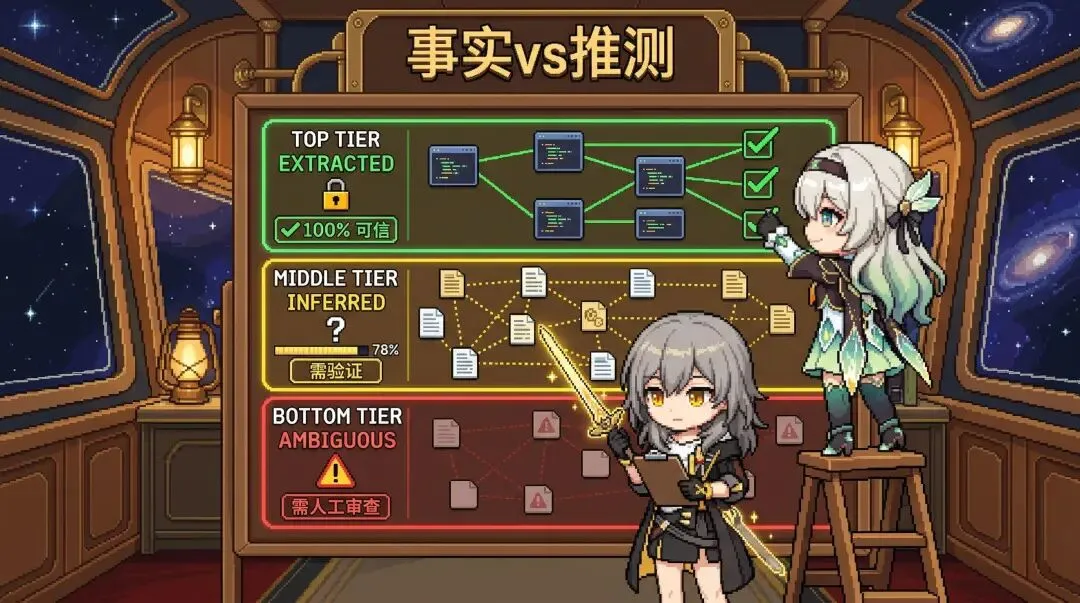
什么是事实、什么是猜测,标得清清楚楚
Graphify 给图谱中每条关系边打了三种标签:
EXTRACTED。 来自 AST 解析,100% 事实。
INFERRED。 来自 LLM 语义推断,概率假设,带置信度分数,用之前得验证。
AMBIGUOUS。 证据不足,需要人工审查。
说白了就是你始终知道什么是系统真正发现的,什么是模型猜的。
这在企业场景里很关键。写自动化测试,只允许基于 EXTRACTED 关系生成代码;写架构文档,才能参考 INFERRED 关系。该信什么、不该信什么,边界是划死的。
聚类不用向量,纯靠图拓扑
这块 Graphify 刻意没走向量嵌入路线。它用 Leiden 算法做纯图拓扑聚类。
道理很简单:两个函数之间频繁的直接调用关系,比它们命名上的语义相似度更能准确反映它们是不是同一个模块。而且第二通道推断出的语义边已经作为结构化边注入了图谱,Leiden 执行时语义信息自然参与聚类计算。图谱的拓扑结构本身就是相似度信号,不需要额外的向量数据库。
输出结果里比较重要的部分:
业务模块群落。 自动发现系统边界。比如所有认证相关的类、数据库脚本、甚至相关的 PDF 设计文档被归入同一个群落。你不用手动划分模块了,算法根据实际调用关系帮你切。
上帝节点。 被大量模块依赖的核心节点。评估技术债、规划重构方向、预测”改一处炸几处”的爆炸半径,都靠这个。God Nodes 这个名字很形象——权力太大,一旦出事影响面广。
令人惊讶的连接。 本应隔离的模块出现了深层耦合。手动 code review 很难发现这些,图谱分析才能看出来。
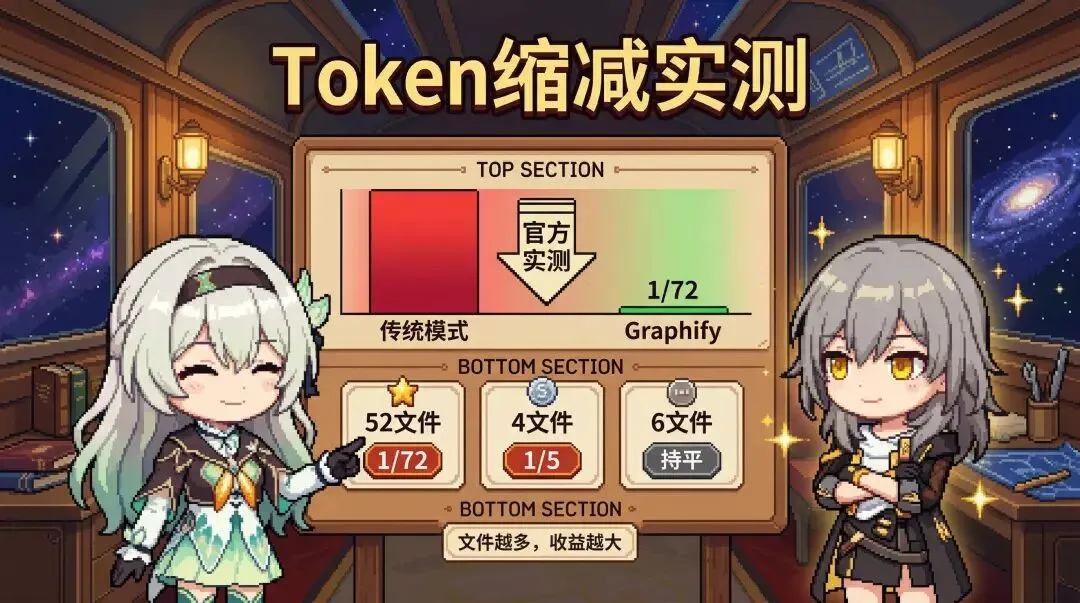
Token 消耗到底能省多少
官方 README 给了三组基准数据:
| 语料规模 | 文件数 | Token 变化 |
|---|---|---|
| Karpathy 代码仓库 + 5 篇论文 + 4 张图 | 52 | 降至约 1/72 |
| 小型项目 | 4 | 降至约 1/5 |
| 极小项目 | 6 | 基本持平 |
这是官方给出的 worked examples,不是我测的。实际效果取决于项目规模和文件类型。
但核心逻辑不复杂:传统模式下 AI 每次查询都要读大量原始文件,Graphify 模式下 AI 直接查已编译的图谱报告,只读高密度的元数据。文件越多、项目越复杂,收益越大。小项目看不出差别,中型以上降幅急剧拉开。
还有一个被忽略的好处:图谱以 JSON 格式持久化在本地,跨会话持续存在。AI 的认知不再随着终端关闭归零。用 Karpathy 的话说,这叫”知识复利”。
常驻机制:强制让 AI 先查图再搜文件
这是 Graphify 最激进的设计。
它在 AI 的工具调用链中装了拦截器。执行 graphify claude install 后做两件事:一是向 CLAUDE.md 注入行为契约,要求 AI 在回答架构问题前必须先读图谱报告;二是设置 PreToolUse 拦截器,每当 AI 试图调用 Glob 或 Grep,如果检测到已有图谱,会自动注入系统警告:”知识图谱已存在,先查图谱再搜原始文件。”
这不是建议,是强制。AI 的默认行为从”关键字匹配”切换到”图谱拓扑导航”。开发者自己的评价是:”如果没有这个设置,Claude 默认还是会去 grep 原始文件,即使图谱已经存在。有了这个设置,图谱就成了 Claude 最先触及的东西。”
另外还有 --watch 模式和 Git hooks。--watch 后台监听文件变更,代码改了图谱自动增量更新,只调 Tree-sitter 不调 LLM,几乎零延迟。Git hooks 让每次 commit 或 checkout 自动重建图谱,确保 AI 看到的永远是当前代码树的真实拓扑。

8 种导出格式
Graphify 不是封闭系统,导出生态做得很全:
| 导出格式 | 干什么用 |
|---|---|
graph.html |
浏览器交互图,点击节点、按群落过滤 |
GRAPH_REPORT.md |
纯文本架构审计报告,AI 优先读取的对象 |
graph.json |
序列化图谱,跨会话持久化认知 |
--obsidian |
导出 Obsidian Vault,用 Obsidian 关系图导航 |
--wiki |
生成 Wikipedia 风格离线知识库,对 RAG 系统友好 |
--neo4j / --neo4j-push |
导出 Cypher 语句或直接推送到 Neo4j 实例 |
--graphml |
Gephi/yEd 兼容格式 |
--svg |
静态矢量图,插入文档或 PPT |
--mcp |
启动 MCP 服务器,供 Cursor 等其他 AI IDE 实时调用 |
我个人比较在意最后那个 --mcp。这意味着 Graphify 的图谱不只服务 Claude Code,Cursor、Windsurf 等支持 MCP 协议的 AI 工具也能直接查询。跨平台认知层,不是只给一家用的。

--wiki 也值得多说一句。它生成一个类似 Wikipedia 的离线知识库,每个群落和上帝节点都有独立页面。这种格式对不支持 JSON 解析的通用 AI 爬虫或传统 RAG 系统很友好,等于把图谱知识降维成了文档形态,什么工具都能消费。
隐私模型:代码不出本地
最后说信任问题。
代码 AST 解析完全本地运行,Tree-sitter 不走网络。企业核心商业机密,底层代码实现、私有算法、内部服务器地址,永远不离开你的机器。
只有文档和图片的语义提取才会发到 Claude API。走你自己的 API Key,受你的企业协议保护。系统零遥测,不收集使用数据,不发任何未经授权的网络请求。
这种分叉式隐私模型我觉得是正确的设计:代码结构是企业的命根子,必须留在本地;文档和图片的语义理解确实需要 LLM 能力,但范围可控、可审计。
写在最后
之前写知识库编译那篇,我说 RAG 的核心问题是”没有积累”。Graphify 把这个判断工程化了。
Token 消耗降低只是表面结果。真正的原因是 AI 编码助手有了一个持久化的认知层。它不再每次打开终端都从零理解你的项目,而是带着之前编译好的架构知识开始工作。
如果你在用 Claude Code、OpenClaw 或任何支持的 AI 编码助手,且项目文件超过几十个,建议试一下。越复杂的项目收益越明显。小项目就算了,省不了几个 Token,不值当。
如果对AI个人提效,以及副业感兴趣,而不只是围观,也推荐加入 IDO 老徐 的知识星球:AI 落地实战 · DeepSeek · OpenClaw。
里面会持续分享 OpenClaw 相关内容、AI 工作流搭建、商业化落地和各种实战避坑经验。