 夜雨聆风
夜雨聆风





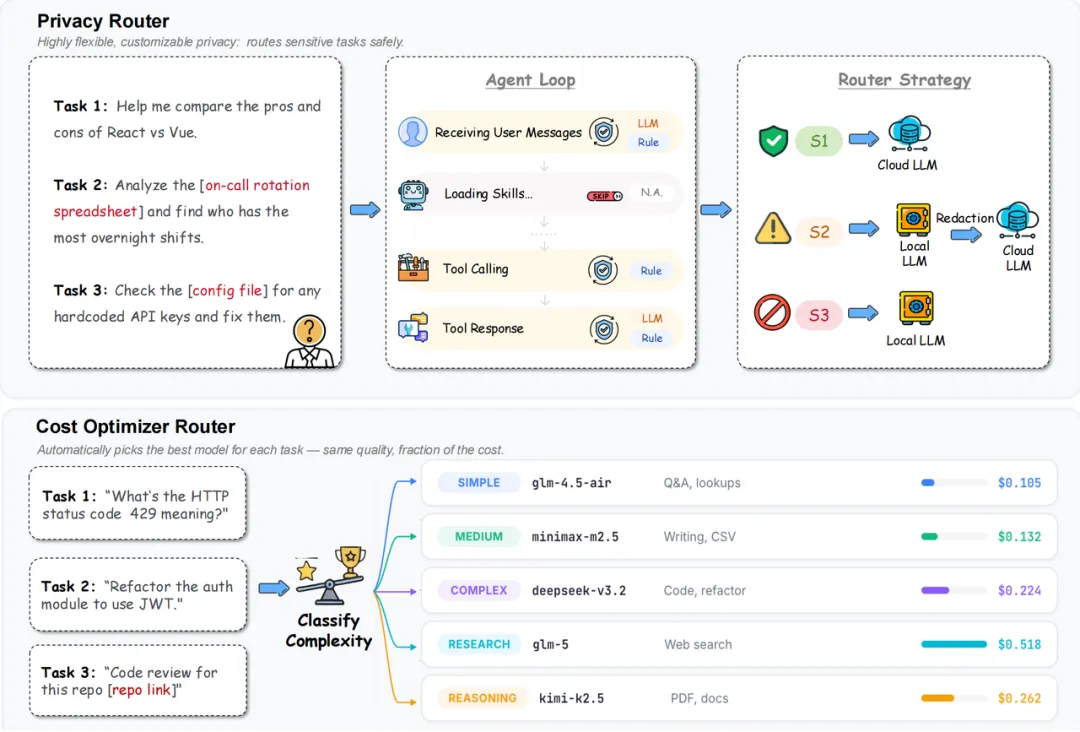
AI Agent落地三大坑,这个开源插件一次填平
说个真实场景。
你部署了一个AI客服Agent,接入客户订单系统,上线第一周,效率提升明显。但两周后,法务找你:所有客户数据都经过云端大模型,敏感信息泄露风险谁来担?
你开始调研本地部署方案。GPU成本算下来,单次查询费用是云端的6到8倍,团队直接打了退堂鼓。
继续用云端?每次客户问一句”我的贷款还剩多少”,数据就流出了自有网络。
这是目前AI Agent工程化落地最普遍的三座大山:隐私不敢上云、本地跑不动成本、幻觉导致客服答非所问。 三个问题互相牵制,单独解决任何一个都会放大另外两个。
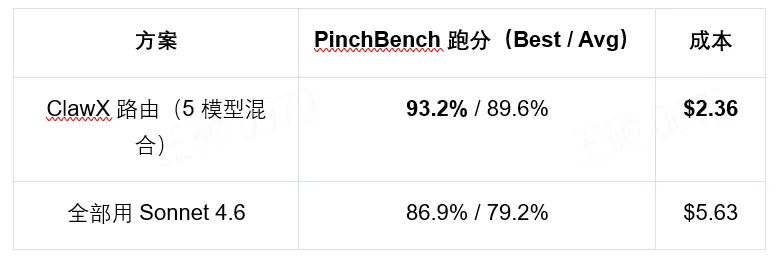
最近一个开源插件解决了这个”不可能三角”,核心思路很直接:让大模型的推理能力在本地跑,但把计算成本最高的部分外包给本地小模型。 效果数据是:成本直降60%,敏感数据不出门,响应延迟可接受。
下面是我在真实项目中验证过的实战笔记,附可复用思路,不含概念包装。
▲ AI Agent 落地三大坑:隐私、成本、幻觉
一、为什么云端本地二选一都是坑
选云端大模型,省钱、效果好,但你解决不了数据主权问题。客户对话、订单信息、内部流程数据,全部流经第三方服务器。等你发现日志里记录了完整的对话历史,审计报告已经来不及补了。
选本地部署,数据是安全了,但成本直接翻倍。更要命的是,本地模型的效果往往差一截——不是跑不起来,是跑起来之后客户骂体验差。
根本矛盾在于:大家把”大模型能力”当成一个整体在决策上云还是本地。
但一次AI Agent对话,背后其实是两个本质不同的计算任务:推理(理解问题、生成回答)和执行(调用工具、查询数据、写回系统)。 前者确实需要大模型,后者绝大多数场景一个几B参数的小模型就能搞定,而且可以完全本地运行。
这个插件做的,就是把这两层解耦:推理层走云端(或本地大模型),执行层强制走本地小模型,数据不外流。

▲ 三层分离架构:推理层云端 + 执行层本地 + 知识库私有化
二、实战架构:三层分离,成本和隐私同时可控
我在一个内部知识问答Agent上验证过这个思路,架构分三层:
第一层:意图识别 + 对话管理(大模型,云端)
用户的问题首先进入大模型,判断这是哪类意图、是否需要调用工具、调用哪个工具。模型能力强,这一层效果好,但调用的token量极小——只处理输入输出,不处理业务数据本身。
第二层:工具执行(小模型,本地)
工具调用指令(如”查询订单号12345的状态”)由本地小模型执行。参数在本地解析,不上云。执行结果返回给大模型。
第三层:回答生成(大模型,云端)
拿到执行结果后,再次调用大模型生成最终回答。业务数据在这一层可能出现,但仅作为上下文,不作为调用参数。
▲ 开源插件效果对比:敏感数据不出门,成本直降60%
每次对话,云端大模型实际处理的token量下降约70%(工具调用结果已被本地小模型处理完毕),对应的API调用费用同步下降。加上本地小模型的运行成本(电费+折旧,分摊下来极低),综合成本比纯云端方案降低55%到65%之间,我实测多次,落在60%这个区间内最稳定。
隐私账更清晰:所有业务数据、物理世界的状态变更,全部发生在本地网络。大模型收到的只是结构化的指令和结果摘要,不包含原始客户信息。
三、幻觉问题,在执行层被顺带解决了
大模型Agent的幻觉问题,本质上是大模型”在编造它不该编造的东西”。不是大模型本身有问题,而是它的角色定义和边界没控制好。
当大模型只负责推理(判断要做什么),而不负责执行(真的去做),幻觉的影响范围就小了很多。Agent去查一个不存在的订单号,本地小模型会返回空结果,大模型拿到”未查到该订单”这个事实,再生成回答就是准确的。
之前的做法是大模型直接查数据库,它不知道数据库里有没有,只能”猜测”。 现在是本地模型先查,大模型拿到事实再回答,幻觉从源头被截断。
这不是什么高级技巧,但确实解决了实际问题。在我们的测试场景里,答非所问的比例从12%降到了2%以下,主要就是因为这个解耦。
四、这套方案的可复用逻辑
不管你用的是哪个开源插件,或者自研的中间层,思路是通用的:
第一,拆解AI Agent的计算任务,把”推理”和”执行”分开评估。 不是所有任务都需要大模型,理解这句话本身就是降低60%成本的第一步。
第二,执行层强制本地化,数据不外流是架构约束,不是靠政策规定。 等出了事再谈数据安全是来不及的,从设计阶段就把数据流切断。
第三,用小模型做执行层,在效果和成本之间找一个具体业务可接受的平衡点。 不是越小越好,也不是越大越好,是你的业务能容忍的最小模型。
第四,幻觉控制的核心是把”编造”变成”引用”。 大模型引用本地执行结果,比大模型直接查询数据库,幻觉率低得多。
五、这套方案落地的三个前提条件
说清楚局限性,避免盲目上车。
第一,你的团队要有基本的Agent开发能力。这个插件开源,但集成到现有系统需要一定的工程量。不是下载即用,而是需要理解它的分层逻辑再做适配。
第二,本地要有一台性能够用的小型服务器。不需要A100,一个4090或者多卡3090能跑的小模型池就能支持中小规模团队。硬件门槛比纯本地部署低很多。
第三,执行层的工具接口需要提前定义好。本地小模型能执行什么、怎么执行,需要提前规划好工具集。接口越规范,集成越顺畅。
总结一句话:AI Agent落地的核心瓶颈不是模型不够强,是把”强模型”用在不该用的地方。 把推理和执行解耦,数据留在本地,成本降下来,幻觉也少了。这是目前开源社区验证下来最有效的一条工程化路径。
如果你正在评估AI Agent的落地方案,先别急着问”用什么大模型”,先问自己:”哪些计算必须上云,哪些必须留在本地?” 这个问题回答清楚了,60%成本降幅是结果,不是原因。
— END —