 夜雨聆风
夜雨聆风





你的AI助理每天都在失忆,你知道吗?
上一篇龙虾的”手”是怎么长出来的?一文带你了解Skill我们详细讲了龙虾的“手”,今天我们来看看龙虾的记忆是怎么形成的。
金鱼的困境——没有记忆的AI有多糟
传说金鱼的记忆只有七秒。
没有记忆的AI,就是那条金鱼。你每次打开对话框,对它来说都是全新的人生开始。你永远是它”第一次见到”的用户。
这件事有多糟?
上下文断层最直观。 你告诉ChatGPT你是做电商运营的,偏好用数据说话,不喜欢emoji。关掉窗口,明天再打开——它全忘了。”您好,请问有什么可以帮您?”你又得从头自我介绍一遍。用了五年的Siri和用了一个月的Siri,没什么本质区别。它不记得你。
跨会话的任务直接断裂。 你让龙虾”帮我跟进A项目,每天汇总进展”。如果没有记忆,它每天都不知道昨天发生了什么。你以为它在帮你盯项目,其实它每天都在从零开始理解这个项目是什么。
最要命的是个性化能力没了。 没有记忆就没有成长,没有成长就不是”伙伴”,只是一个每次都要重新调教的工具。
没有记忆的AI是一条金鱼——你每次打开对话框,对它来说都是全新的人生。你永远是它”第一次见到”的用户。

“我上下文窗口大”不等于”我记性好”
看到这儿你可能会说:不对啊,现在的大模型上下文窗口不是越来越大了吗?Claude 系列模型已经拥有1M的上下文窗口了,把聊天记录全塞进去不就行了?
不够。问题根本不在”大不大”。
斯坦福和UC伯克利有个被引了无数次的研究,发现了一个反直觉的现象,叫 “Lost in the Middle” 大模型对上下文开头和结尾的信息记得很清楚,中间的内容基本是”视而不见”的。
准确率曲线是一条U形——开头高、结尾高、中间塌。即便是专门为长上下文设计的模型,这个规律照样成立。说白了,Transformer的位置编码机制存在长程衰减,离得越远的内容,注意力权重越弱。
打个比方:把500页资料摊在桌上,理论上信息都在。但你的眼睛只会认真看第一页和最后一页,中间几百页草草翻过。
把资料堆在桌上,不等于记住了。这就是上下文窗口的本质。
真正的记忆,不能靠”塞满”,得靠”主动找”。
记忆到底是什么
那AI的”真正记忆”长什么样?
OpenAI研究员Lilian Weng写过一篇Agent综述博客,至今还是业界引用最多的基准框架。她把智能体的记忆类比成人类大脑的三层结构:
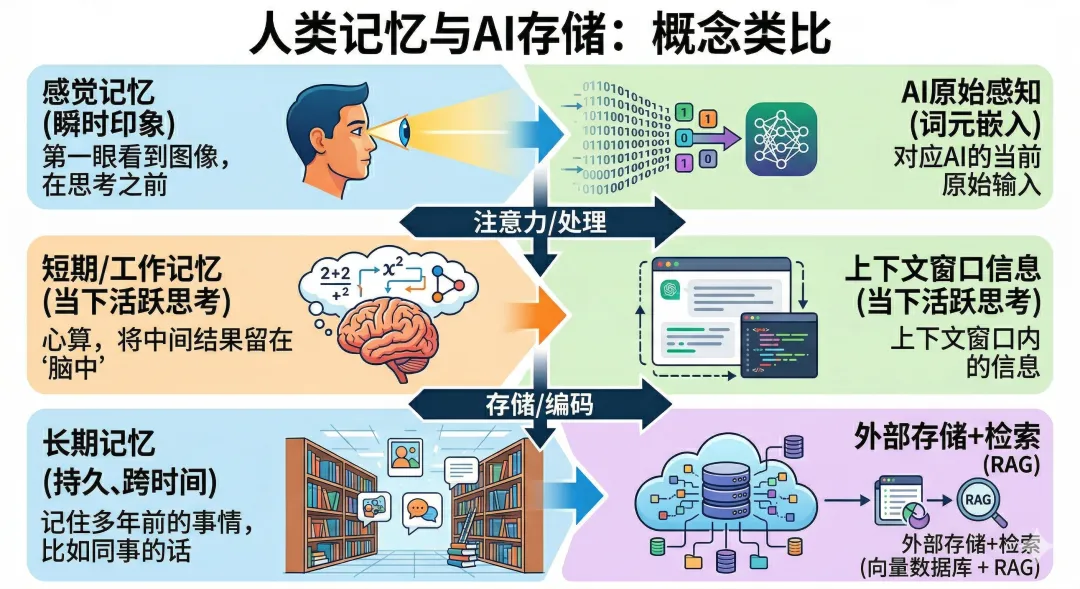
感觉记忆和短期记忆,模型天生就有——就是它的输入层和上下文窗口。真正要解决的,是长期记忆。
这就要说到一个关键技术:向量数据库。
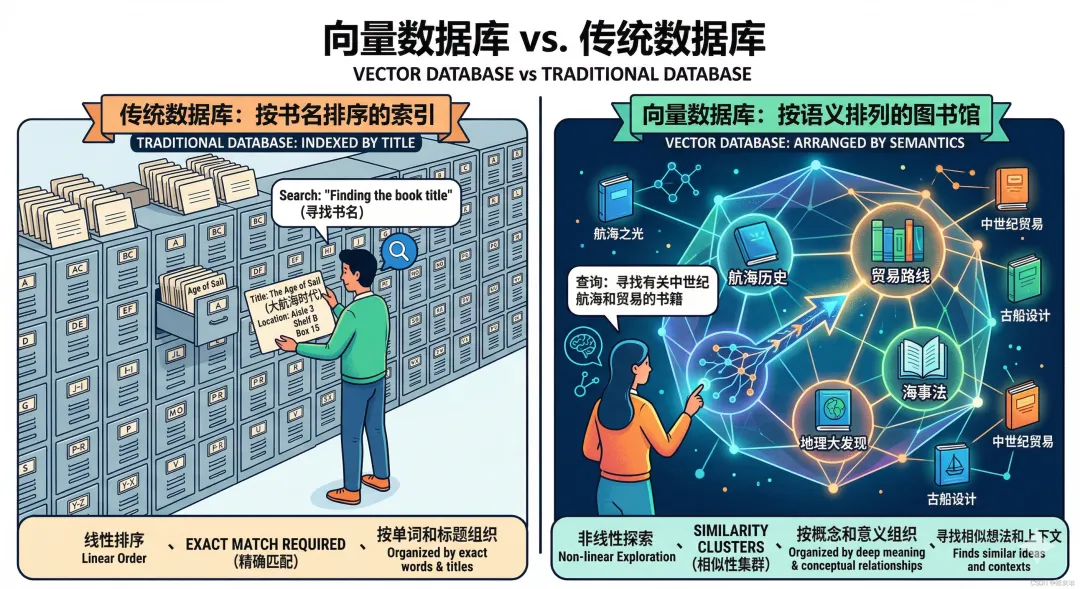
传统数据库(比如MySQL)像图书馆的书名索引——你必须知道确切的书名,才能找到那本书。搜”经济学”找不到《国富论》,因为书名里没有”经济学”三个字。
向量数据库换了一套玩法:它把每段文字变成一串数字(叫”向量”,本质是高维空间中的一个坐标点),语义相近的内容在这个空间里距离很近。你可以把它理解成一个 “按内容排列的图书馆”——不需要知道确切标题,描述个大概意思,它就能帮你找到最相关的书架。
有了向量数据库,记忆的完整流程就通了:
存入记忆时: 对话内容 → 嵌入模型(把文字变成向量)→ 存入向量数据库回忆时: 用户新提问 → 问题也变成向量 → 去数据库里找最近的记忆 → 取出来塞进上下文 → 大模型生成回答这个”检索→注入→生成”的流程有个专业名字:RAG(检索增强生成)。它是连接”大脑”(大模型)和”记忆仓库”(向量数据库)的桥梁。
就像一个秘书,她不是真的记住了你三个月前的每句话,而是她有一个分类精细的笔记本,需要的时候翻得又快又准。效果一样,机制完全不同。
记忆不止一种
你以为记忆就是”记住聊过什么”?没那么简单。
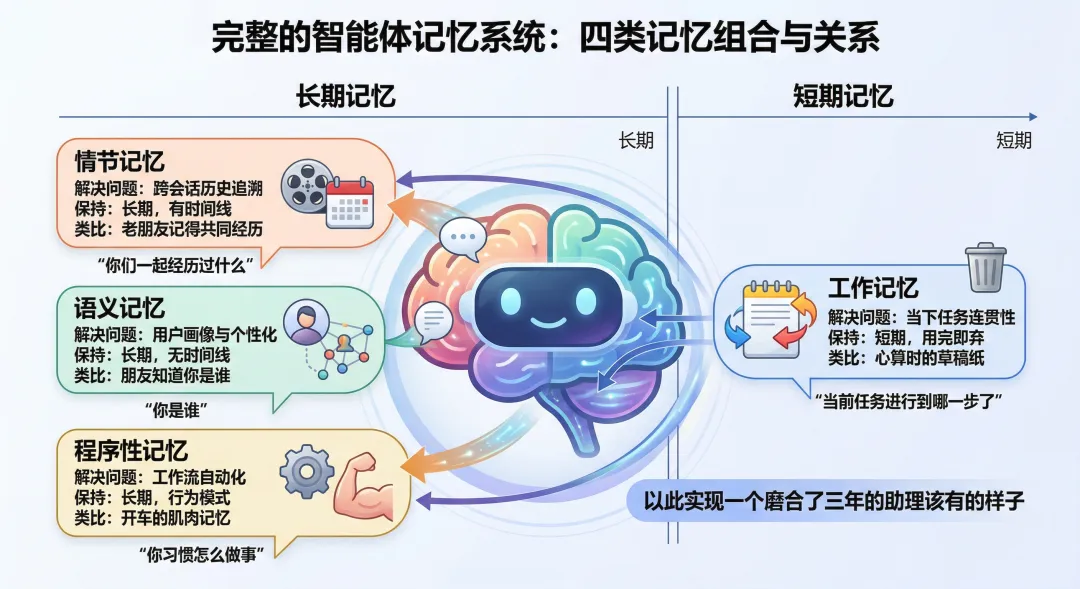
认知科学把人类记忆分成好几种,AI研究者照着这个框架建了智能体的记忆体系。四种类型,各管一摊。
情节记忆——”我经历过什么”
记录具体事件:什么时间、什么地点、发生了什么。
龙虾的情节记忆意味着:它记得”上周三你让我整理报告,用的蓝色系配色,三级标题结构,第二页放了数据图表”。下次你说”按上次的风格来”,它真的知道”上次”是什么。
客服AI的情节记忆意味着:它记得”上周三你投诉过快递延误,当时处理结果是退款50元”。你再打电话不用从头说起。
就像一个老朋友,他记得你们去年一起经历的那件事,而不是每次都问你”你好,我们认识吗?”
语义记忆——”我知道什么”
不是具体经历,而是抽象的事实和画像。
“用户:35岁,上海,做电商运营,不喜欢emoji,偏好数据说话。”“老板的汇报偏好:结论先行,三张图以内,不超过5分钟。”
这些信息不绑定在某一次对话里,而是从许多次对话中提炼出来的。就像一个认识你五年的朋友,不需要每次都问”你是干什么的”——他早就把关于你的基本事实内化了。
程序性记忆——”我会怎么做”
技能、流程、习惯性的操作序列。
“每周一早上9点,汇总上周数据,按固定格式生成报告,发给这三个人。”“遇到代码报错,先跑单元测试,再查日志,再提Issue。”
你第一次学开车,每个动作都要有意识地想。开了五年就是肌肉记忆——右脚自动踩刹车,眼睛自动看后视镜。程序性记忆就是AI的肌肉记忆,把你的操作习惯固化成自动化动作。
工作记忆——”我现在在想什么”
当前任务的即时上下文,任务完成后就清空。
多步任务中,Agent需要记住”第1步已完成,第2步还差一个API结果没回来,第3步还没开始”。这是AI的草稿纸——你心算一道数学题时,把中间结果”放在脑子里”,就是工作记忆在运转。
四类记忆速查:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
一个完整的智能体——比如龙虾——这四种记忆是组合使用的。它知道”你是谁”(语义)、”你们一起经历过什么”(情节)、”你习惯怎么做事”(程序性)、”当前任务进行到哪一步了”(工作)。
这才是一个磨合了三年的助理该有的样子。
谁来实现记忆
理论讲完了,谁在真正落地?
目前业界有几个主流的记忆框架,我重点拆三个——代表三种截然不同的思路。
Mem0——最好上手的记忆中间件
如果你只想花最小力气给AI加上记忆,Mem0是第一选择。
它的玩法很直接:用大模型自动从对话中提取关键信息,向量化之后存进数据库。下次对话时,按语义相似度检索相关记忆,塞进上下文。
代码简化到什么程度?大概这样:
from mem0 import Memorymemory = Memory()# 自动从对话提取关键信息并存储memory.add([ {"role": "user", "content": "我喜欢打篮球,平时也爱玩游戏"}], user_id="alice")# 后续任何时候都能检索results = memory.search("alice的爱好是什么?", user_id="alice")# → 返回:"喜欢篮球和游戏"这段代码在说什么:你告诉AI你喜欢篮球和游戏,Mem0自动把这个信息提炼出来存好。下次不管隔了多久、在哪个会话里,只要问”alice的爱好”,它都能找到。
官方数据说,用Mem0比把完整对话塞进上下文,Token消耗减少90%,回答质量提升26%。
不过Mem0有三个弱点你得知道:
一个是LLM驱动的提取本身是概率性的——它偶尔会提取错误或遗漏关键信息。你说”我上周提过想换工作”,它可能记成”你已经换工作了”。这叫记忆幻觉。
还有就是每次操作需要至少两次LLM调用(提取一次、回答一次),有额外成本。还记得上篇说龙虾”空转一天140块”吗?记忆维护是那140块里的一部分。
再一个,它不太懂时间。”你上周说的”和”你去年说的”在Mem0看来差别不大。
Zep——最懂时间线的记忆引擎
Mem0的时序软肋,恰好是Zep的杀手锏。
Zep的核心引擎叫Graphiti(已独立开源,GitHub超两万星),背后有一篇正经论文。它做了一件别人没做好的事:双时态建模。
什么意思?举个例子:
三个月前你告诉AI你住在上海。上周你搬去了北京。
Mem0的反应:知道你现在在北京,但对时间线模糊。
Zep的反应:清楚地知道”你现在在北京(上周至今)”,保留着”你曾经在上海(三个月前到上周)”,并且精确知道变化发生的时间。
Zep用了一个三层知识图谱:最底层存原始对话(一字不差),中间层用LLM提取实体和关系(”用户A 居住于 上海”),顶层把相关实体聚类成社区摘要。信息过期了不删除,只标记”失效”——完整历史永远可追溯。
Zep像一个从不扔日记的人——他知道你现在住北京,但也记得你三年前在上海,以及那年冬天你为什么搬走。
基准测试数据:Deep Memory Retrieval准确率94.8%,比Mem0精确度高17%,检索延迟低60%,生产环境P95延迟300毫秒。
代价呢? 图数据库的基础设施部署复杂,维护成本高。如果你只是做个快速原型,Zep是大炮打蚊子。它更适合企业级场景——客服、医疗、金融,那些对”时间线”敏感度极高的领域。
Letta(前身MemGPT)——最像人脑的记忆管理
Letta的灵感来源特别有意思:它不是从认知科学出发的,而是从操作系统出发的。
核心论文发在ACL 2024,标题直接叫”Towards LLMs as Operating Systems”。它把AI记忆类比成电脑的内存层级:
┌──────────────────────────────────────────────┐│ Working Memory = 上下文窗口 [RAM] ││ ┌─────────────┐ ┌──────────────────────┐ ││ │ Core Memory │ │ Message Buffer │ ││ │ 用户档案 │ │ 最近几条对话 │ ││ │ 当前任务状态 │ │ 满了就触发摘要归档 │ ││ └─────────────┘ └──────────────────────┘ │└─────────────────────┬────────────────────────┘ │ 满了 → 摘要 → 归档(蒸发70%) ▼┌──────────────────────────────────────────────┐│ Recall Memory = 对话历史归档 [SSD] ││ 完整对话存储,不在当前窗口但可以搜索调取 │└─────────────────────┬────────────────────────┘ ▼┌──────────────────────────────────────────────┐│ Archival Memory = 外部知识库 [硬盘] ││ 向量数据库,处理过的结构化知识 │└──────────────────────────────────────────────┘翻译成人话:上下文窗口是RAM(快但有限),向量数据库是硬盘(慢但无限)。AI自己知道什么时候该”换页”——把硬盘上的文件调进内存来用。
上下文满了不是直接丢弃,而是先做摘要、再归档,只蒸发70%,保留30%的连续性。AI可以主动修改自己的Core Memory——发现你换了工作,它自己更新”我知道用户现在在新公司了”。空闲时后台跑一个”Sleep-time Agent”,整理和优化记忆——就像人类睡觉时大脑在巩固白天的记忆。更绝的是,Agent甚至可以在对话中主动说”等等,让我回忆一下”——像人一样意识到自己需要去查记忆。
弱点? 自主记忆管理引入了不确定性。AI自己决定记什么忘什么,它可能做出让你意外的取舍。架构也相对复杂,调试起来比Mem0难不少。
除了上面的三个框架,再简单快速补两个:
LangChain Memory——LangChain里的可组合记忆积木。从最简单的”存全部对话”到”自动摘要””语义检索””知识图谱”,五六种组件任你拼。适合已经在用LangChain的开发者快速加入基础记忆。2025年的趋势是LangChain官方自己都建议,复杂记忆外包给Mem0或Zep,自己专注做编排。
MemOS——学术界最前沿的记忆操作系统概念,发表在EMNLP 2025。它提出了一个叫”MemCube”的最小记忆单元,记忆有三种形态:普通文本、高频热缓存、直接融入模型权重(LoRA级别的深度学习)。还有热度驱动的内存调度——常用的记忆自动升到”热区”快速访问,冷数据降级归档。论文数据很惊人(F1 Score比GPT-4o-mini提升48%)。
五个框架的对比表:
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
现实中的记忆
理论和框架说完了,看看真实世界。
ChatGPT的记忆——2025年最大的一次升级。
2025年4月,OpenAI把ChatGPT的记忆从”保存特定记忆”升级为”引用所有历史对话”。
现在的ChatGPT有两套记忆模式并行:一套是显式记忆——你主动告诉它”记住我是素食主义者”,它就保存这条;另一套是隐式记忆——它自动从你所有的历史对话中提炼偏好和上下文,不用人主动跟他说,它能自己主动记忆。
OpenAI官方给的定性是:“这是迈向终生AI伴侣的一步。”
争议随之而来。有用户发现ChatGPT在一个完全不相关的对话里,突然主动提起了自己几个月前说过的私密内容。”AI到底记住了我什么?”——这个问题开始让人不安。
欧盟因隐私法规直接把这个功能禁了。Plus/Pro用户能用完整记忆,免费用户只有基础版,EEA、英国、瑞士的用户——不好意思,没有。
Cursor——代码领域的记忆标杆。
如果你写代码,可能已经用过这个AI编辑器。Cursor能跨会话记住你的项目代码风格、你不喜欢用的设计模式、你们项目用REST还是GraphQL。效果是实实在在的:减少重复说明,代码建议更贴合项目实际。
企业级场景也在跑。 摩根大通用持久化记忆加实时金融数据,让AI顾问记住客户的风险偏好和持仓历史。医疗系统基于AWS Bedrock做患者历史追踪,相当于AI版数字病历。
记忆的代价
吹完了,该泼冷水了。(是的,这个系列的传统艺能。)
记忆幻觉。 AI会”记错”。LLM驱动的记忆提取本身是概率性的,它可能歪曲细节、捏造不存在的历史。你说”我上周提过想换工作”,它可能”记住”成”你已经换工作了”——然后自信满满地基于这个错误记忆给你建议。一个记错了事情还特别自信的助理,比不记事的还危险。
隐私的双面性。 “AI记住你的一切”——贴心还是令人不安?
谁来保管这些记忆?在谁的服务器上?能保证安全吗?如果AI记忆被黑客获取,相当于你所有的私密对话一次性泄露。欧盟GDPR已经明确要求”被遗忘权”——你有权要求AI彻底删除关于你的一切。但目前大多数平台在这方面的用户协议描述,说实话,都是模糊的。
记忆漂移。 你的偏好会变,AI可能还抱着旧的不放。”我三年前告诉它我喜欢极简风,现在换了品味,但它还一直给我推极简。”Zep的双时态模型部分解决了这个问题,但大多数框架处理得不好。一个抱着过时印象不放的助理,有时候比没记忆更烦人。
成本。 Mem0等框架每次操作需要额外的LLM调用——提取一次、检索一次、回答一次,至少三次。记忆越积越多,存储和检索的成本也随时间增长。
数据主权与平台锁定。 你的记忆全存在一个平台的服务器上。换平台等于从零开始建立记忆,迁移成本极高。更深的问题:谁”拥有”这些关于你的数据?平台能用这些数据训练下一代模型吗?
时间越长,它越像磨合了三年的助理——问题是,这三年的”你”,存在谁的服务器上?
你自己的记忆会退化吗? 上篇的”坑五”我说过:龙虾帮你写了三个月的代码,你还记得怎么写吗?记忆这件事同理——AI帮你记住所有的会议内容、所有的客户偏好、所有的项目进展,你还会主动去记吗?
更深的问题:当AI越来越了解你,”它认为的你”和”真实的你”之间,会不会出现偏差?它根据过去的你来预判现在的你,但你是一直在变的。有一天你可能发现,AI比你自己更”了解”你——或者更准确地说,它了解的是一个被数据定义的你。
你是在被一个系统理解,还是在被一个系统定义?
记忆让AI从工具变成了伙伴
记忆是AI从工具进化为伙伴的分水岭。没有记忆的AI是金鱼,有记忆的AI才有可能成为那个”磨合了三年的助理”。从感觉记忆到长期记忆的三层架构,从情节记忆到程序性记忆的四种类型,从Mem0的简单向量检索到Zep的双时态知识图谱再到Letta的操作系统式管理——这个领域在用非常认真的工程力量,试图让AI真正”记住”你。
但伙伴是需要信任的,信任是需要透明的。在我们把越来越多的”自己”存进这些系统之前,有一个问题值得每个人想清楚——
“它认为的你”和”真实的你”,是同一个人吗?
我不知道。但我觉得这个问题本身,比任何技术方案都重要。
如果你也在用AI助手,不管是ChatGPT、Cursor还是龙虾——你愿意它记住你的工作偏好吗?那私人生活呢?底线画在哪儿? 评论区聊聊,我很好奇大家的答案。