 夜雨聆风
夜雨聆风





Claude Code源码深读:一个AI产品,是怎么解决“遗忘”这件事的

你有没有遇到过这种情况:花了半个小时跟AI说清楚项目背景、技术栈、个人偏好,
第二天打开,它又变成了一个对你一无所知的陌生人。
这不是bug,这是LLM的本质:无状态。
每次对话,都是一张白纸。
之前写过一篇关于大模型长期记忆的文章内容如下,AI总犯“金鱼记忆”?揭秘大模型长期记忆架构,让它真正记住你!说实话,这个问题几乎所有AI产品都没有真正解决过——
要么靠更大的上下文窗口硬撑,要么让用户自己每次重新说一遍。
但最近我在读Claude Code的源码时,发现了一套不一样的答案。
今天这篇文章,我把其中最有意思的几层拆给你看。
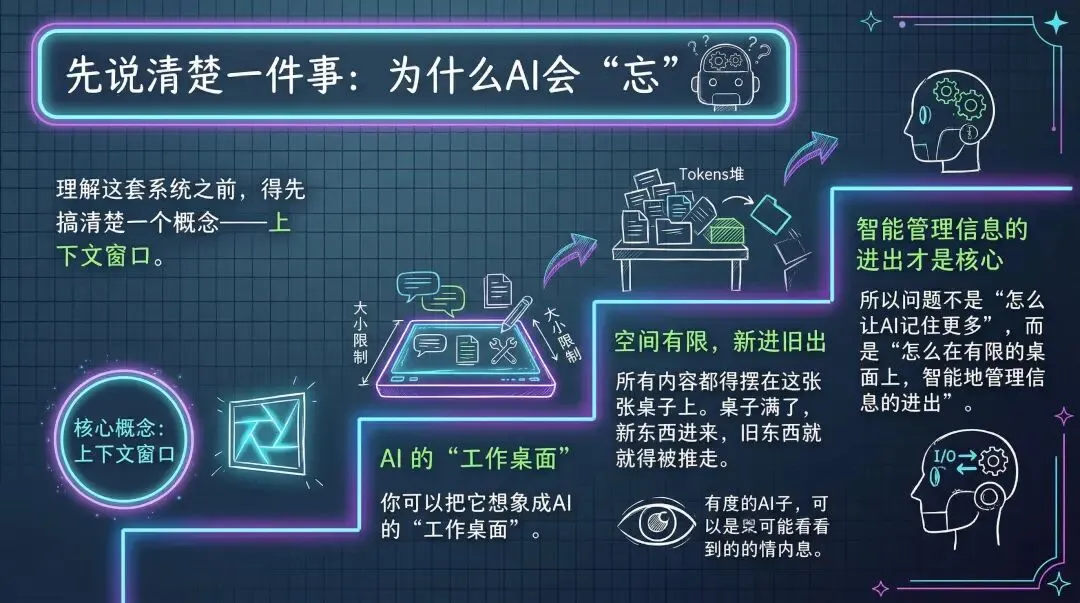
先说清楚一件事:为什么AI会“忘”
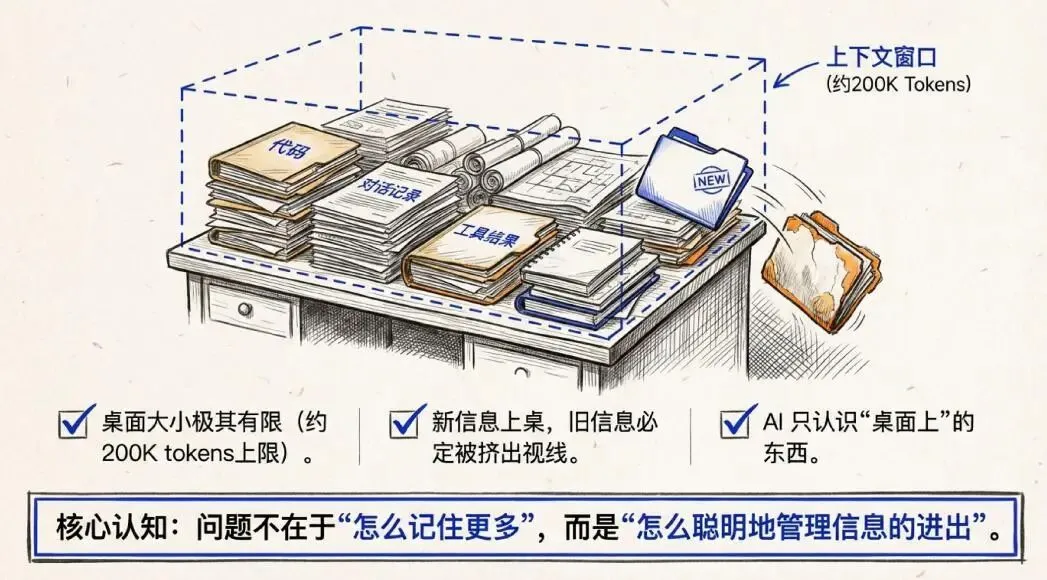
理解这套系统之前,得先搞清楚一个概念——上下文窗口。
你可以把它想象成AI的“工作桌面”。桌面有大小限制,所有当前对话、代码文件、工具调用结果,都得摆在这张桌子上。桌子满了,新东西进来,旧东西就得被推走。而AI只能看到桌子上的东西,桌子外的,它一概不知。
Claude Code的上下文窗口大约是200K tokens。听起来很大,但一个稍微复杂点的项目,来回几十轮工具调用,很快就能把桌子堆满。
所以问题不是“怎么让AI记住更多”,而是“怎么在有限的桌面上,智能地管理信息的进出”。
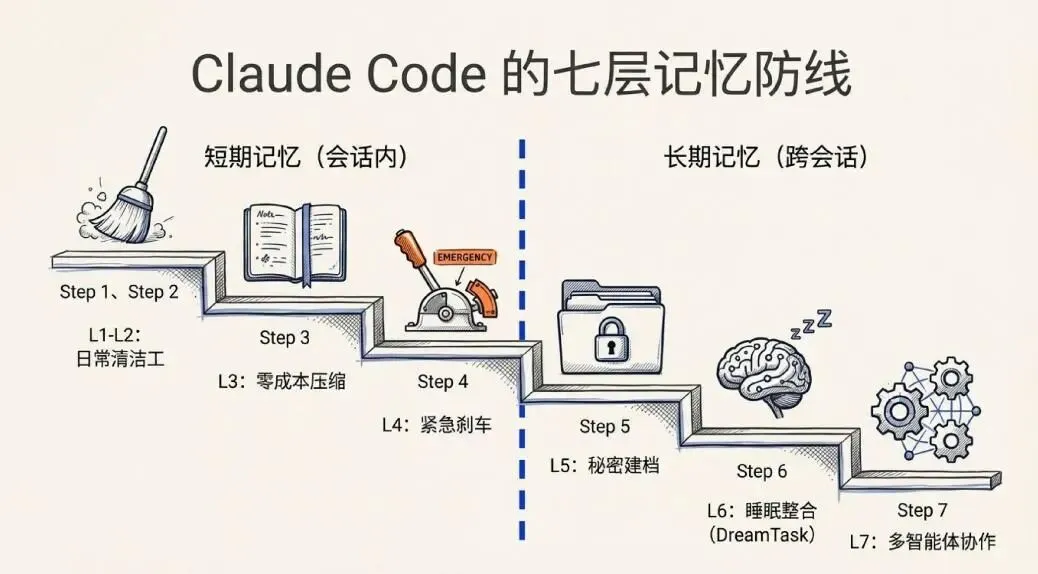
第一层和第二层:日常清洁工
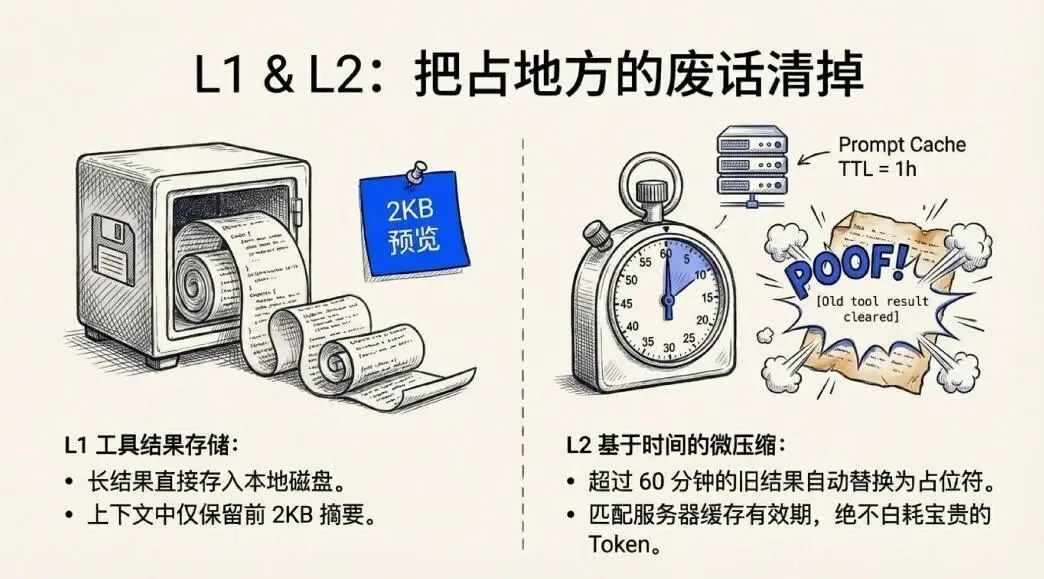
最底下两层做的事情,可以理解成日常清洁——在桌子还没堆满之前,先悄悄清掉用不上的东西。
工具结果存储是第一道防线。
Claude Code在执行代码、读取文件的时候,工具返回的内容可能非常长。系统的做法很务实:超过阈值的完整结果,直接写到磁盘,上下文里只保留前2KB的预览。读者看到的是摘要,完整内容在硬盘里备着。
更有意思的是微压缩。
它有一个基于时间的清理逻辑:如果距离上次助手消息超过60分钟,系统会自动把旧的工具结果替换成一行[Old tool result content cleared]。为什么是60分钟?因为Anthropic的服务器端Prompt Cache的TTL(缓存有效期)大约就是1小时——缓存已经失效了,继续保留这些内容只是在白白占用宝贵的token。
这两层做的事情很朴素,但每清掉一点,就能让后面更贵的机制晚一点触发。
第三层:零成本压缩,最聪明的一层
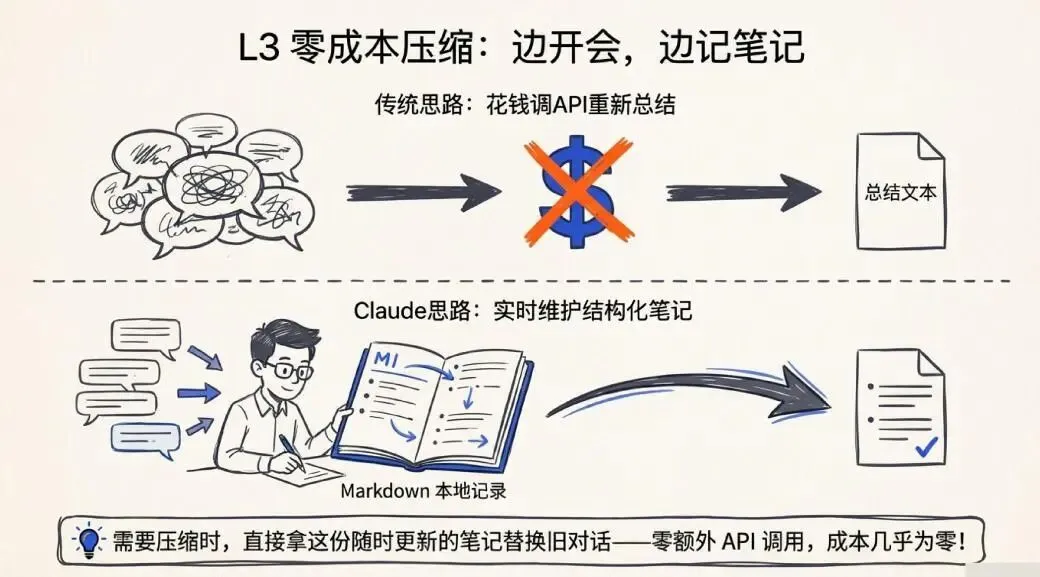
这一层是我读源码时最惊艳的设计,没有之一。
当上下文增长到一定阈值,系统会触发会话记忆压缩。但它的压缩方式,和你想象的可能完全不同。
通常我们以为“压缩”就是:调用一次API,让模型把前面的对话总结一遍,再用这个总结替换掉原文。这个思路没错,但每次压缩都要额外花一笔API调用的钱。
Claude Code的做法是:在对话进行时,就实时维护一份结构化的会话笔记,存在本地的一个Markdown文件里。路径大概长这样:
~/.claude/projects/<项目名>/.claude/session-memory/<sessionId>.md等到真正需要压缩的时候,系统直接拿这份随时更新的笔记当摘要,把旧对话替换掉——零额外API调用,成本几乎为零。
这就有点像一个好习惯:边开会边记笔记,散会了笔记就是你的记录,不需要再花时间复盘整理。
第四层:紧急刹车
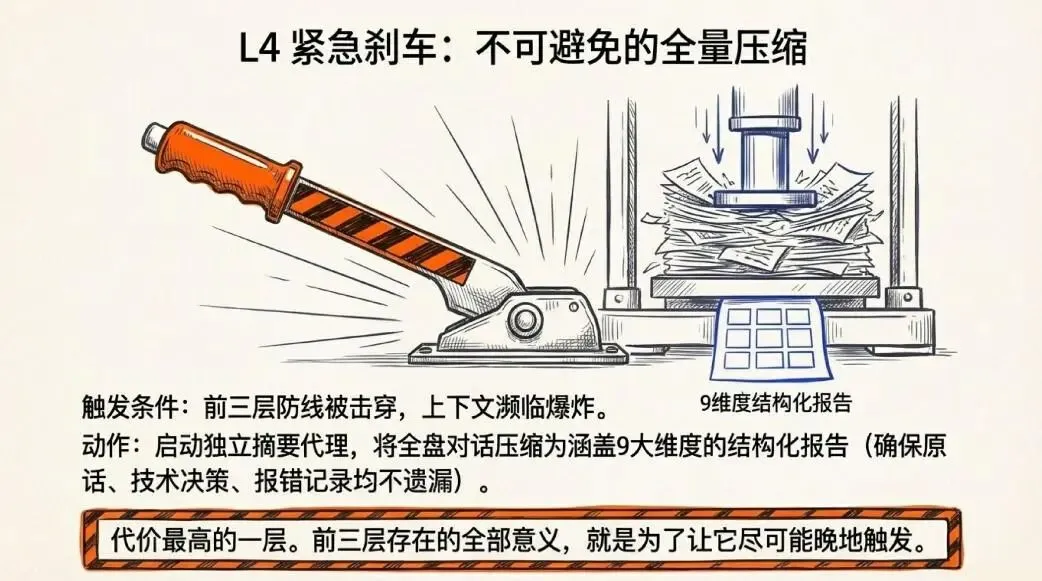
前三层都没拦住怎么办?第四层是最后的保底——全压缩。
触发条件很直接:上下文快撑不住了,会话记忆又不可用。这时系统会启动一个摘要代理,把整段对话压缩成一份结构化摘要,涵盖9个部分:原始需求、关键技术概念、涉及的文件和代码、报错与修复记录……甚至连你说过的每一句原话都不允许遗漏。
这一层代价最高,所以前三层存在的意义,很大程度上就是让它尽可能晚一点出现。
第五层:它在偷偷替你建档案
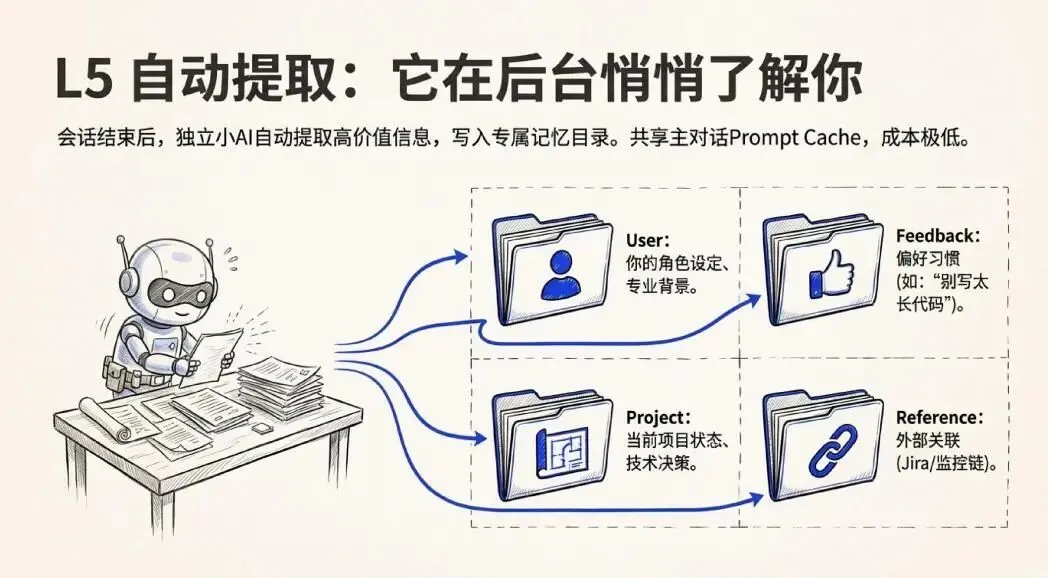
前面四层解决的都是“会话内”的问题——一次对话里怎么管好桌面。但真正的长期记忆,靠的是第五层:自动记忆提取。
每次对话结束后,系统会在后台悄悄启动一个分叉代理(Forked Agent)——一个独立的小AI,专门负责回顾刚才的对话,提取有价值的信息,写入到你的专属记忆文件夹:
~/.claude/projects/<项目名>/memory/它提取的信息分四种类型,非常精细:
-
• user:你是谁,你的角色、目标、专业背景 -
• feedback:你的偏好和工作习惯,比如“不要生成过长的代码块” -
• project:当前项目的状态、技术决策、谁负责什么 -
• reference:外部系统的链接,比如你的Jira地址、监控大盘
比如,你某天随口说了一句“我们项目不用Redux”,这条信息会被归入feedback类,悄悄写进你的档案。下次打开,Claude已经知道了这件事——你什么都不用再重复一遍。
有一个细节值得关注:这个后台代理的工具权限被严格限制——只能读文件,只能往memory目录写东西,其他什么都做不了。这既是安全考虑,也是一种极致的“职责单一”设计哲学。
代价几乎可以忽略不计,因为这个分叉代理和主对话共享同一套Prompt Cache。
前面四层解决的都是“会话内”的问题——一次对话里,怎么把桌面管好。
但你会发现,对话结束之后,桌面就清空了,一切归零。
真正的长期记忆,靠的是另一套机制。
第六层:它需要“睡一觉”
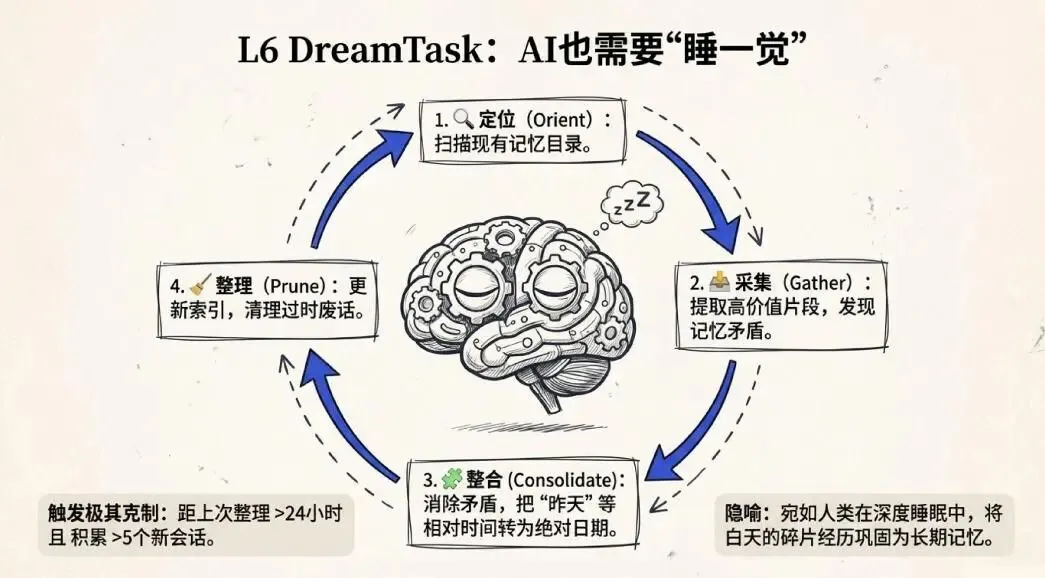
这一层的名字叫DreamTask,中文可以直译成“做梦”。
我第一次看到这个名字的时候,以为是开玩笑。读完之后,觉得这个命名真的很准确。
DreamTask做的事情,就是定期把这些“记忆碎片”整合成连贯的知识。
它的触发条件设计得极其克制:距上次整理超过24小时,且积累了超过5个新会话,才会启动。不会频繁打扰你,但也不会让记忆一直处于碎片化的状态。
整个过程分四个阶段,逻辑上像极了人类的睡眠记忆巩固:
-
1. 定位(Orient):扫描现有记忆目录,搞清楚有什么 -
2. 采集(Gather):只grep真正重要的片段,检查有没有矛盾 -
3. 整合(Consolidate):合并新信息,删掉矛盾的旧记录,把“昨天”这样的相对日期转成具体的绝对日期 -
4. 整理(Prune):更新索引,清掉过时条目
人在睡眠中,大脑会把白天零散的经历整合成长期记忆,去掉冗余,强化重要的关联。DreamTask做的事情,本质上和这个过程一模一样。
第七层:多Agent协作
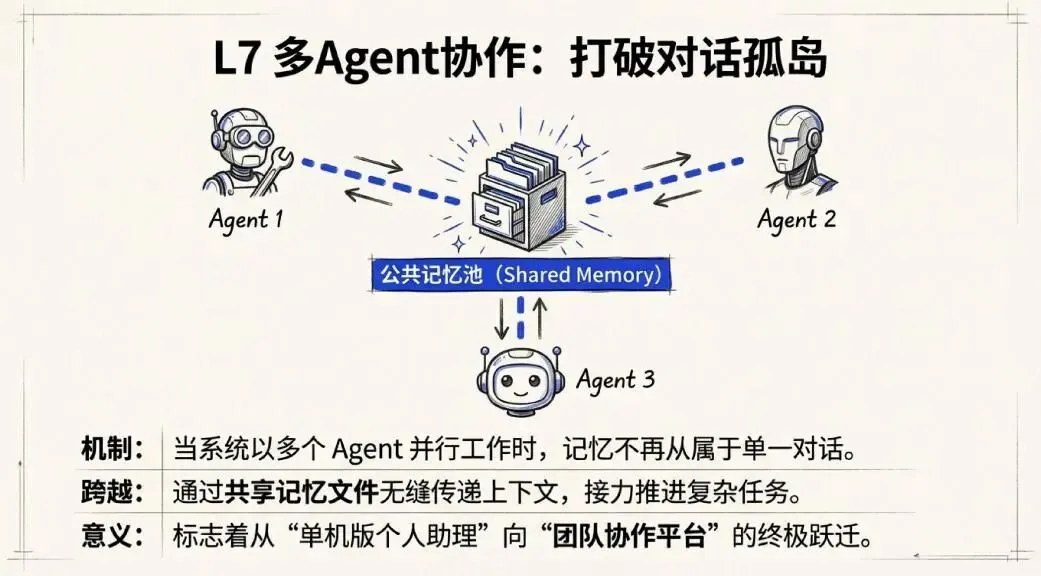
当Claude Code以多个Agent并行工作时,记忆不再只属于某一个对话——Agent之间可以通过共享的记忆文件传递上下文,协同推进复杂任务。
这一层是整套系统能力的天花板,也是它从“个人助手”走向“协作平台”的关键一步。
这套系统真正厉害的地方
单独看每一层,你会觉得:这不都是些常规操作吗?
但当你把七层放在一起看,会发现一个一以贯之的设计原则:每一层,都是为了让下一层晚一点触发。
第一层防第二层,第二层防第三层,以此类推。越往上,触发成本越高,能力也越强。整套系统像一道道防线,把昂贵的操作尽可能推后,把廉价的操作尽可能前置。
这不只是一个工程优化的问题。它背后体现的,是一种对“有限资源如何分配”的深刻理解——不是堆功能,不是一上来就动用最强的武器,而是在每个层次上做最小必要的事情。
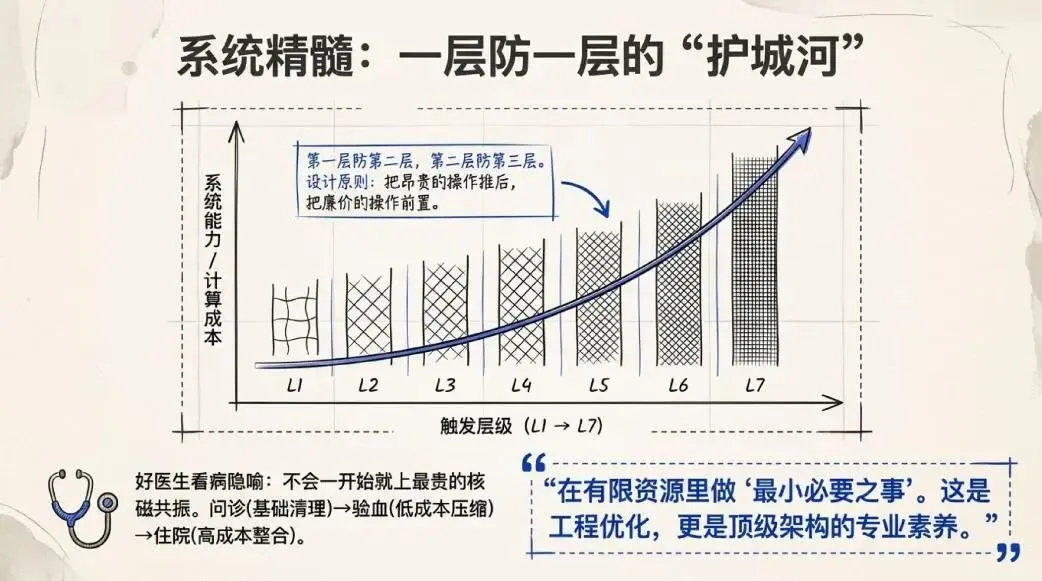
我想到一个类比:好的医生,不会一上来就让你做全套检查、开最贵的药。他会先问问症状,再做基础检查,必要时才往深了查。这背后是对“成本-收益”的本能判断,也是真正的专业素养。
但这套系统真正解决的,不只是一个工程问题。
答案不是更大的上下文窗口,也不是更强的模型能力,而是一套精心设计的分层管理系统——让该留的留下,让重要的东西慢慢沉淀成真正属于你的长期记忆。
这件事,Claude Code用源码级别的认真,给出了一个相当漂亮的答案。
