 夜雨聆风
夜雨聆风





《临床仿写》:IF=9.7 AI工具做出来了,临床为什么还是没变?预测工具不等于决策工具!来看这篇 TKA 决策试验的真正启发

这篇文章基于JAMA Network Open 2026的主文,讲的是一个AI预测工具对膝骨关节炎患者TKA决策的影响。说实话,它值得拆,但不是因为结果有多漂亮,而是因为它把一个很有时代感的问题——AI预测工具到底能不能真正改变外科决策——做成了一篇可发表、同时也很值得反向审视的随机试验。总体看,它更适合拿来当综合样本,尤其是作为反向审稿的标杆,教你一篇“阴性但规范”的工具干预试验是怎么站住脚,又是怎么露出边界的。
它能拆的地方不少。第一,题目踩中了“AI预测工具进入临床”这个期刊特别敏感的点。第二,作者没停在算法开发,而是往前走了一步,直接做了RCT,这本身就比很多只停在模型性能的工具论文高一个层级。第三,结果是阴性的,但阴性本身不是缺陷,反而点出了一个重要问题:一个预测工具即便预测本身成立,也不等于它就能真正改变患者的决策。第四,它的设计、终点和图表都足够规范,正好适合拿来讲“为什么能发”,同时也适合讲“为什么又没那么扎实”。
作者真正想问的,其实不是“这个AI工具准不准”,而是:把一个预测TKA术后获益概率的在线工具交给正在考虑手术的膝骨关节炎患者,会不会让他们更不愿意做手术,或者至少让他们更认真地重新想一遍这件事。这个问题在临床上值得一问。因为TKA不是一个轻决策,患者数量大、费用高、恢复周期长,而且术后并不是所有人都满意,大概10%到20%的患者并不满意。既然结局获益并不均匀,理论上就该有空间用预测工具帮患者和医生把“谁更该做、谁可以先等等”这件事说得更具体。
此前预测模型已经不少,但真正经过随机试验证明它们对患者决策有影响的证据很少。作者想补的空白,正是这个“从开发到落地”的证据断层。整体上看,问题问得不算差。它精准限定了人群:单侧膝OA、正在考虑初次单侧TKA、且已尝试过非手术治疗。但问题也在这里,作者把“工具有效”几乎等同于“降低手术意愿”,这个成功标准本身就有概念偏差。一个好的决策工具,未必应该让更多人不想做手术;它更应该提升决策质量、偏好-结局一致性和手术适配度。所以,这篇文章的问题切口是先进的,但主问题定义其实偏窄了一点。
它能发出来,我觉得主要靠三点。一是研究问题确实切中临床痛点:不是传统“某药有效吗”,而是“一个预测工具进入诊疗路径后,患者会不会因此改主意”。这类问题兼具临床价值、卫生政策价值和数字医疗热度,JAMA Network Open很吃这一套。二是设计总体匹配问题。要回答“工具会不会改变决策”,最合理的就是随机分配工具使用与否,而不是前后对照或满意度调查。作者用了parallel、double-masked、2-arm RCT,在工具评估研究里已经算认真了。三是人群界定清晰,虽然带着明显的招募结构偏倚。纳入条件相对干净:45岁以上、单侧膝OA、考虑TKA、尝试过非手术治疗、会英文、能上网。但样本主要来自私保人群HCF,真正来自公立医院候诊名单的比例很小,Table 1里两组约89%都来自HCF,SVHM仅约10%到11%。这意味着它研究的更像“正在考虑手术的、数字可及的、偏早期或资源更充足的人群”,而不是全部TKA候选者。
终点设置是这篇文章最值得讨论的地方。主要终点是6个月时“是否愿意做手术”的二分类问题。这个终点的好处是直观、低成本、能快速做RCT;坏处也非常明显:它只是一个替代性行为意向指标,而不是实际手术、决策一致性、决策冲突、长期结局,甚至不是一个标准化程度很高的shared decision-making终点。换句话说,它好测,但不够硬。对照框架基本成立,工具组和TAU组都在网站输入相同变量,只有工具组会看到预测结果,这一点其实做得不错,至少把“填写数据本身”的影响尽量平衡了。双盲也用了limited disclosure,研究团队分析时也保持盲态。只是这仍然是个相对“弱干预”:一次性线上反馈,没有和门诊沟通、教育模块、医生会谈整合在一起。
统计呈现有增强,也有短板。增强之处在于作者老老实实给了未调整和调整后的OR,结果也很诚实:未调整时6周和12周一度显著,但一旦调整基线willingness的不平衡,效果就消失了,6个月调整后OR 0.85,95%CI 0.42-1.71,P=.64。这非常能说明问题:这不是一个稳的效应。但短板同样明显:他们主要采用complete case analysis,虽然做了multiple imputation敏感性分析,但主分析不是ITT风格的最强表达;此外,样本量远未达到原计划在两个站点都各纳入169例的目标,研究明显偏欠功效。
图表结构帮读者快速抓住重点。Figure 1交代筛查与流失,Table 1交代基线,Figure 2展示willingness随时间的走势,Table 2给主/次结果,Table 3放K-DQI。整体上是很标准的“工具试验”写法,读者不会迷路。讨论部分也成功把结果提升到了“有发表价值”的层面。作者很聪明,没有把论文写成“工具没用”,而是转向“工具可能仍有价值,只是当前设计和实施方式还不够”。这让阴性RCT仍然保住了发表价值。但也要说得直白一点:讨论部分有一定“帮结果找位置”的味道,尤其是把潜在益处往“更好筛选患者、节省资源、推迟不合适手术”上引,这些推论在本研究里并没有被直接测量。
从设计上看,这是典型的平行、双盲、两臂随机临床试验。严格说不是典型多中心,研究协调由一个大学研究中心完成,招募来源有两个:一家三级医院候诊名单和一个大型私保会员群体。更准确的说法是单一协调中心、双来源招募。它是前瞻性、随机、双盲的,带一点务实色彩的工具干预试验。纳入逻辑服务主问题:围绕“正在考虑TKA的单侧膝OA患者”来设,且要求既往尝试过非手术治疗。排除里真正有选择性影响的是英文理解和网络接入要求,这决定了样本天然更偏数字健康可及人群。
核心干预不是药,也不是手术,而是一次性的在线预测反馈。工具根据年龄、性别和基线症状生成术后健康相关生活质量改善概率,并以1到10的decile呈现。这个设定很重要,因为它决定了工具本质上只提供“术后获益概率”,并不包含完整决策教育。主要终点是6个月时willingness for surgery,次要终点包括treatment preference、treatment uncertainty和Knee Decision Quality Instrument的各项反应。作者把“愿不愿意做手术”放在比“决策质量”更核心的位置,这本身就决定了整篇论文的逻辑方向。最关键的协变量其实就是基线手术意愿,因为随机后两组在这点上不平衡,后续几乎所有关键分析都得为它做调整。作者自己也承认这一点。
样本量随机211例,工具组105,TAU组106。随机化采用blockrand、区组大小5。最大的设计问题在于样本量:按方案,本来每个站点都希望达到169例,但实际公立医院端严重招募不足,最后整个研究都明显低于原本两站点平衡招募的设想。统计主线很清楚:先比较不同时间点willingness,再用logistic regression看组间差异,随后对baseline willingness做调整;次要终点则看treatment preference和K-DQI。技术上不复杂,属于很标准的临床试验统计。
这套设计最聪明的地方,不是算法,而是作者意识到:真正值得发表的,不是“我们又做了个预测模型”,而是“这个模型交给患者之后,决策会不会变”。也就是说,它把研究从模型性能推进到了临床行为层面。这个升级是对的。最脆弱的地方有三个。第一,主终点定义得并不代表“高质量决策”,而更像“更少想做手术”。第二,随机后基线willingness不平衡,直接伤到主结果解释。第三,干预太弱:一次性线上decile反馈,没有整合医生沟通、替代治疗教育和多时间点reinforcement,结果很容易被稀释。再加上样本量不足,这篇研究注定很难打出清晰阳性信号。
写作上,标题是典型JAMA Network Open路数:干预对象+关键结果领域+study type。它没有夸张,也没有把工具包装成AI神器,而是老老实实写“Predictive Tool Use and Willingness for Surgery”。优点是可检索、稳。缺点是略宽,没把“患者决策”这个真正的故事张力写得更尖一点。摘要推进很标准:先讲importance,再讲objective,再设计、干预、主要终点、结果、结论。真正值得学的是,它把阴性主结果一句话钉死:adjusted OR 0.85,P=.64。没有绕。引言用了一个很顺的三段论:预测工具越来越多;真正经过RCT检验其对决策影响的很少;因此要测试SMART Choice。它写得干净,也很会找发表点,没有把背景写成OA综述,而是聚焦在“工具进入决策流程”这一个缺口上。
方法部分服务主问题,而且服务得很直接。几乎所有细节都围绕“把工具交给患者后看手术意愿是否改变”来布置。问题不在服务不服务,而在服务得过于单一:它太像在测“一个网页能不能改变想法”,而不是在测“一个决策支持系统能不能改善决策”。结果部分顺序合理,先交代样本,再讲随访完整度,再讲主终点,再讲次要终点。对这种阴性RCT,这个顺序很重要,因为必须先让读者相信试验做成了,然后才谈结果没出来。讨论部分做了四件事:承认主结果阴性,拿其他决策工具研究对照,提出工具可能更适合“强化已有决定”而不是“逆转决定”,强调未来需要优化设计和实施。这些都很像成熟作者会做的事。问题是,它有点过早把工具的潜在系统价值讲得很大,但本研究并没有测到这些系统层面结局。结论算克制:工具没有降低6个月内的手术意愿,也没有改善围绕TKA的决策质量。可争议的地方在于,作者同时又说predictive tools might still enhance health outcomes,这句话方向上不算错,但已经超出本研究直接证据。
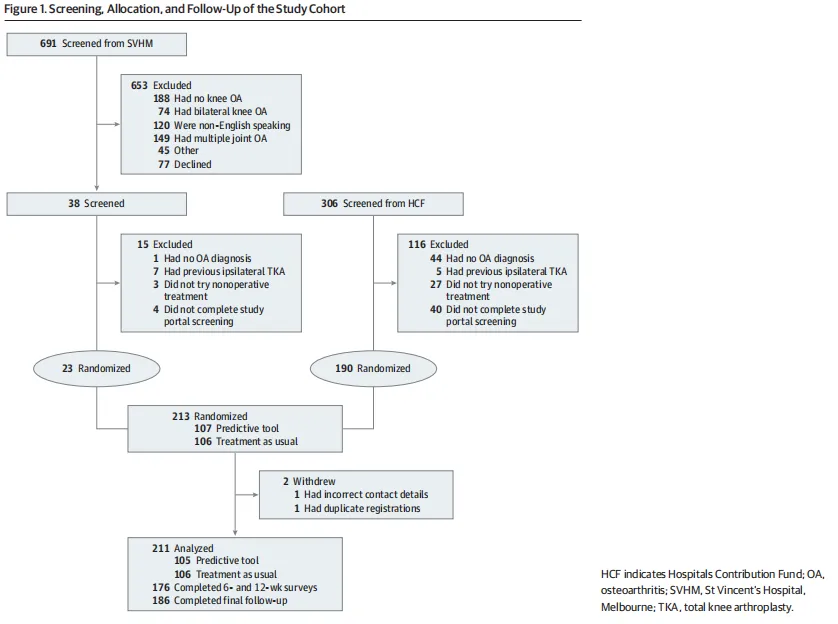 图表里,Figure 1是筛查与流程图,它承担解释设计和样本形成路径的功能。放在这里很必要,因为这篇研究的人群并不天然来自单一临床场景,而是医院候诊名单和私保会员两路进入,必须先交代来源结构。它最值得模仿的地方是把排除原因拆得很细,尤其把“无OA诊断”“双侧OA”“未尝试非手术治疗”“非英语”“既往同侧TKA”等写清楚,读者一眼就能看出作者到底研究的是哪类人。这张图还有一个隐藏价值:它让你看到样本结构问题。691人来自SVHM、306人来自HCF,最后随机却是23 vs 190,说明公立候诊端几乎没招进来多少人,这对外推性是个很强的提醒。
图表里,Figure 1是筛查与流程图,它承担解释设计和样本形成路径的功能。放在这里很必要,因为这篇研究的人群并不天然来自单一临床场景,而是医院候诊名单和私保会员两路进入,必须先交代来源结构。它最值得模仿的地方是把排除原因拆得很细,尤其把“无OA诊断”“双侧OA”“未尝试非手术治疗”“非英语”“既往同侧TKA”等写清楚,读者一眼就能看出作者到底研究的是哪类人。这张图还有一个隐藏价值:它让你看到样本结构问题。691人来自SVHM、306人来自HCF,最后随机却是23 vs 190,说明公立候诊端几乎没招进来多少人,这对外推性是个很强的提醒。
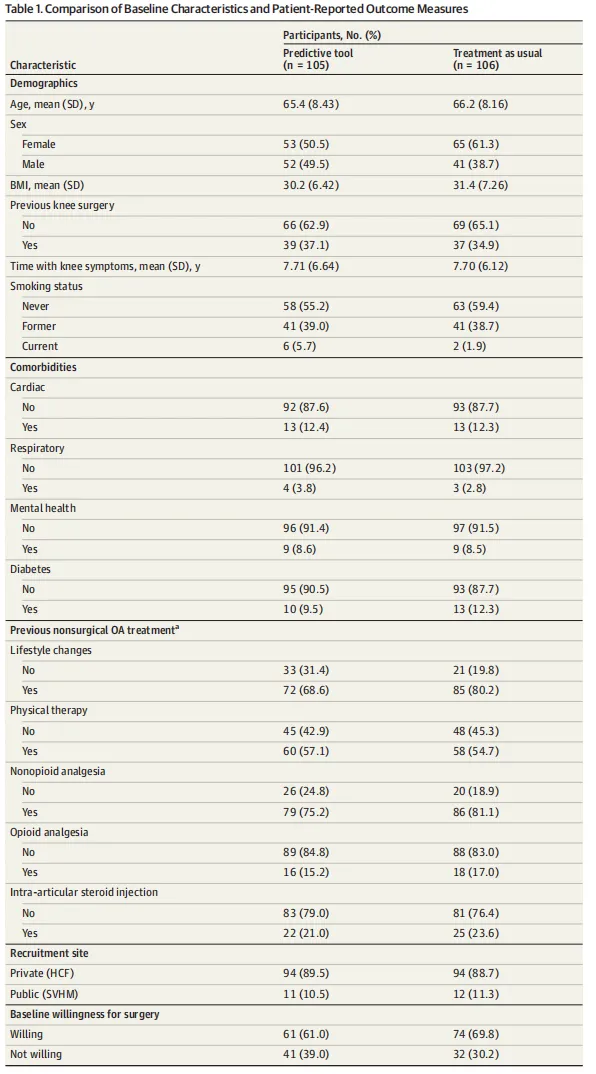
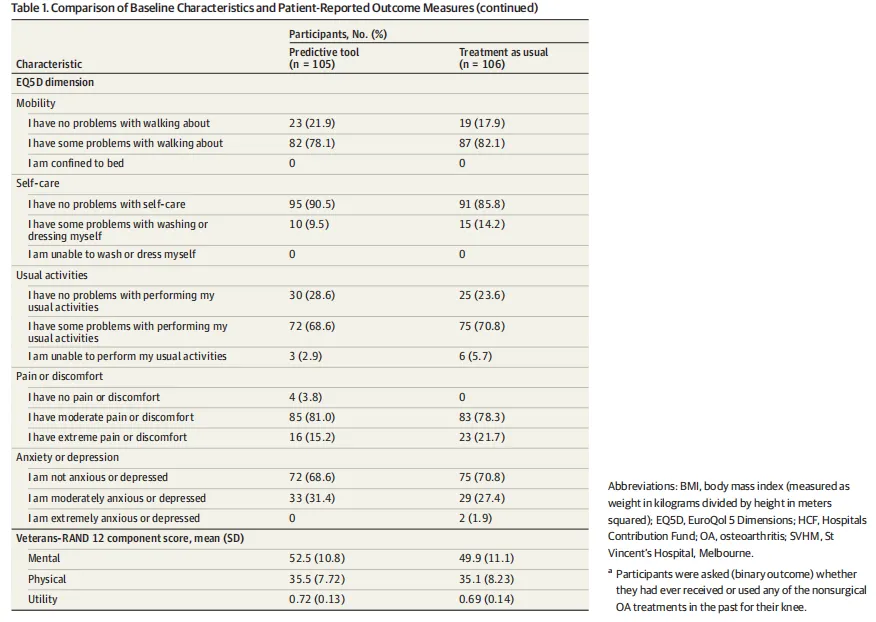 Table 1是基线特征,它承担证明两组可比、同时刻画样本面貌的功能。最值得模仿的是除了人口学变量,作者把既往非手术治疗经历、招募站点、基线willingness、EQ-5D、VR-12都放进来了,这让你知道这不是一个“空壳人群”。但这张表也直接暴露出研究最尴尬的一点:随机后两组baseline willingness不平衡,工具组61.0%,TAU组69.8%。这不是表格的错,却是Table 1最关键的警报。
Table 1是基线特征,它承担证明两组可比、同时刻画样本面貌的功能。最值得模仿的是除了人口学变量,作者把既往非手术治疗经历、招募站点、基线willingness、EQ-5D、VR-12都放进来了,这让你知道这不是一个“空壳人群”。但这张表也直接暴露出研究最尴尬的一点:随机后两组baseline willingness不平衡,工具组61.0%,TAU组69.8%。这不是表格的错,却是Table 1最关键的警报。
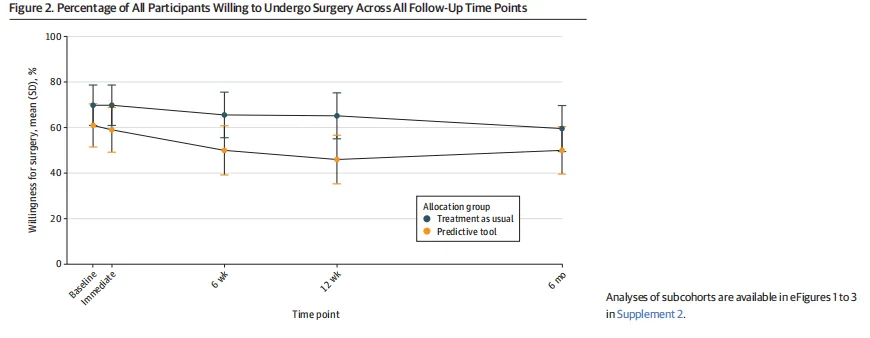 Figure 2是随时间变化的手术意愿曲线,它承载主结果趋势。最值得模仿的是把基线、即时、6周、12周、6个月串起来,能让读者直观看到两组并没有出现清晰分叉。不过我也得指出,这张图的表达效率并不算最优。主要终点是二分类willingness,图里却用“mean (SD) %”的折线式表达,视觉上有点像连续变量趋势图。对于这种结局,若直接展示adjusted probability或risk difference的置信区间图,会更贴近统计主线,也更不容易让人误读。
Figure 2是随时间变化的手术意愿曲线,它承载主结果趋势。最值得模仿的是把基线、即时、6周、12周、6个月串起来,能让读者直观看到两组并没有出现清晰分叉。不过我也得指出,这张图的表达效率并不算最优。主要终点是二分类willingness,图里却用“mean (SD) %”的折线式表达,视觉上有点像连续变量趋势图。对于这种结局,若直接展示adjusted probability或risk difference的置信区间图,会更贴近统计主线,也更不容易让人误读。
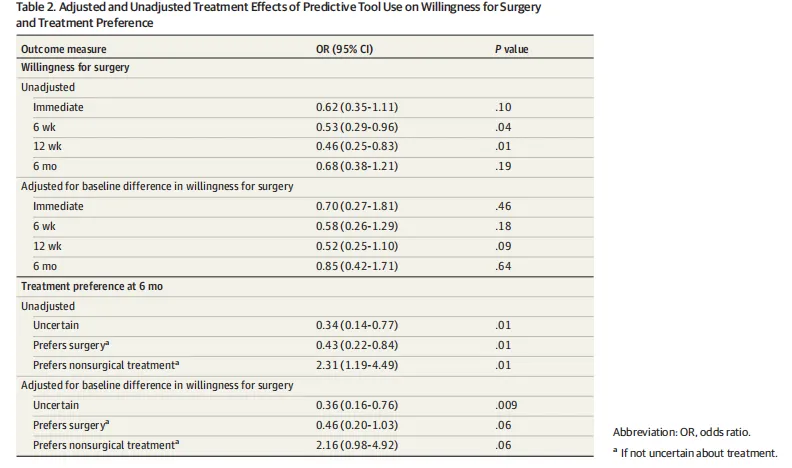 Table 2是调整前后治疗效应,它是全文最核心的论证主骨架。最值得模仿的是作者没有只给一个最终OR,而是把未调整和调整后都摆出来。你能清楚看到,未调整6周和12周看起来还有信号,但一调整baseline willingness,就塌了。这是非常好的结果呈现。这张表也是全文最值得读者学习的一张,因为它教的是:好的结果表不是“显著不显著”,而是把结果为何站不住或站得住,完整摆出来。同时它也暴露出文章的另一个微妙点:adjusted OR for uncertainty=0.36,P=.009,其实提示工具可能降低“不确定性”,但整篇文章没有把这个信号作为一个真正的讨论重心。
Table 2是调整前后治疗效应,它是全文最核心的论证主骨架。最值得模仿的是作者没有只给一个最终OR,而是把未调整和调整后都摆出来。你能清楚看到,未调整6周和12周看起来还有信号,但一调整baseline willingness,就塌了。这是非常好的结果呈现。这张表也是全文最值得读者学习的一张,因为它教的是:好的结果表不是“显著不显著”,而是把结果为何站不住或站得住,完整摆出来。同时它也暴露出文章的另一个微妙点:adjusted OR for uncertainty=0.36,P=.009,其实提示工具可能降低“不确定性”,但整篇文章没有把这个信号作为一个真正的讨论重心。
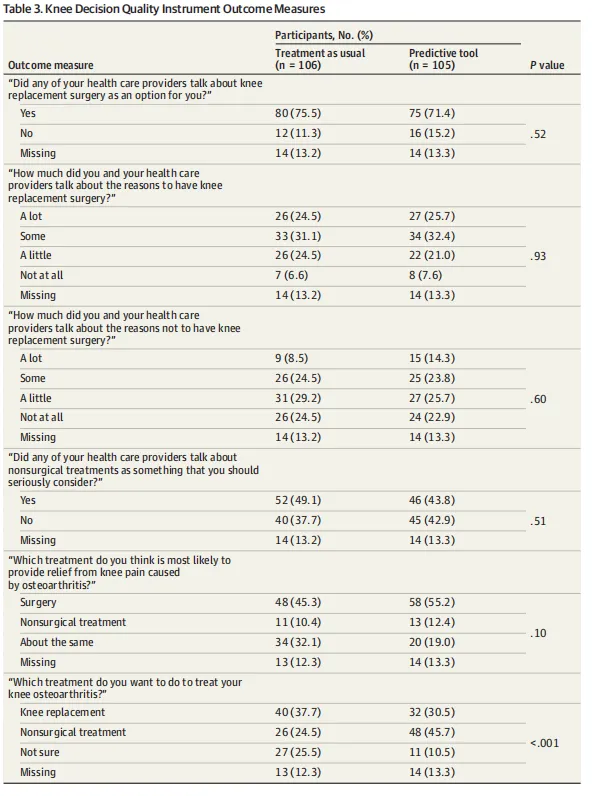
Table 3是K-DQI结果,它补强“决策质量”这条副线。最值得模仿的是没有把K-DQI压缩成一个抽象总分,而是把关键条目逐项列出来,读者能看到到底哪一项动了、哪一项没动。但这张表也有问题。原始条目里,“Which treatment do you want to do”这一项P<.001,看起来很强;可一进调整模型,偏好非手术治疗只剩边缘性,真正显著的是“不确定性下降”。这说明原始条目显著并不等于稳健的组间效果显著。如果普通作者只抓Table 3原始P值来讲故事,很容易过度解读。
整体图表布局的节奏是:样本形成—基线校准—主结果走势—主结果模型—决策质量补充。节奏成熟,期刊感很强。最像“主心骨”的不是Figure 2,而是Table 2。真正决定这篇文章站得住的,是调整前后效应表,不是折线图。最适合读者学习和模仿的是Table 2,因为它最能训练临床作者如何老实呈现结果。表达效率不高的,反而是Figure 2。它有用,但略偏“杂志展示感”;若换成更直接的调整后概率差图,信息会更紧。
这篇文章最值得学的东西,是选题方式:不要盯着“某工具开发出来了没有”,而要往前追一步:这个工具进入患者决策场景之后,会不会改变行为、偏好或路径。这是从“方法学论文”升级到“临床发表问题”的关键一步。结构上,一个好临床工具论文的骨架,不是“工具很先进—我们验证了一下—结果不错”,而是:为什么这个工具值得进入临床、它真正应该影响什么、我们用什么设计去检验它是否真的产生了行为层面的后果。这篇文章这一套是对的。图表上,最可迁移的有三点:流程图要为外推性服务,不只是交代纳排数量;结果表最好同时放未调整和调整分析;问卷或决策量表不要只给总论,要把关键条目拆开展示。
当然它也有边界。最严重的三个局限,第一,主终点选得不够硬,也不够“对”。工具成不成功,不该只看是否降低手术意愿。第二,随机后基线willingness不平衡,直接伤到主分析。第三,样本量不足且招募结构单一,尤其公立候诊端严重不足,导致功效和推广性都受限。“工具可能改善资源配置、延迟不合适手术、提升长期结局”这些话方向上可以写,但都不是本研究直接测得的。再一个不够扎实的地方,是把一次性线上decile反馈当作“预测工具进入临床决策”的代表,这其实只是最轻量的一种实现方式。
真正还没回答清楚的是:工具到底有没有改善决策质量,还是只是没有能力改变既有偏好?其次,患者到底理解没理解decile分数,作者自己都在讨论里承认后续定性研究提示可能存在误读。第三,它没有真正追踪willingness与实际TKA发生之间的对应关系。最容易被误读成“已经做完了”的,是两种人。一种会以为“预测工具对TKA决策没用”;另一种会以为“只要有预测概率就能做好shared decision-making”。其实两边都没被证明。文章真正证明的只是:一个单次、线上、以decile形式呈现的术后获益预测工具,不足以在6个月内稳定改变这群患者的手术意愿。
如果要从它延伸自己的题目,我觉得最合理的路径是抓住“预测信息嵌入共享决策后,能不能提升治疗选择与真实获益的匹配度”这个核心问题。最合适的研究对象是门诊中已经接受过一次骨科评估、但尚未最终决定是否排TKA的膝OA患者。这类人群比“已经在等手术的人”更有决策可塑性。首要终点应换成决策质量或决策一致性,而不是单纯willingness。次要终点可放:是否接受强化非手术治疗、3到6个月内是否进入手术队列、12个月实际TKA、12个月PRO。最需要提前规避的是基线手术意愿不平衡、回归均值(膝OA症状波动会带动willingness自然下滑)和对工具分数的误读。在中国单中心环境里,最实际的改造不是直接上复杂AI,而是做一个“预测分层+门诊标准化宣教+共同决策表单”的前瞻性研究。人群可来自关节外科门诊,结局用中文版决策冲突量表、是否接受康复/减重/物理治疗、3到6个月治疗路径变化。这样比复制一篇澳大利亚数字工具RCT更可落地。
一句话总结:这篇文章最值得借鉴的,不是又做了一个膝关节置换预测工具,而是它把“工具开发”往前推了一步,真正去检验工具是否会影响患者决策。它最大的启发,不是AI工具没有用,而是预测信息如果不嵌入完整的决策支持流程,往往不足以改变真实临床选择。如果读者想从中长出自己的题,最该抓住的是把“预测”升级为“决策支持”,把结局从“愿不愿意做”升级为“是否做了更匹配的决定”。