 夜雨聆风
夜雨聆风





Claude Code 源码精读 | 05 上下文管理,是入门 AI 的第一步
这是「Claude Code 源码精读」系列的第 5 篇。上一篇梳理了 CC 的 Tool 工具模块。这一篇我们讨论「上下文管理」。
读完这篇,你会搞清楚以下3件事:
-
• 什么是上下文管理?为什么它是用好 AI 绕不开的概念。 -
• 一些实用的上下文管理技巧。 -
• 深入源码,看看 CC 是如何做上下文管理的?
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
最近有同学反映内容有点太深了,从这期开始会做一些优化,开头的部分会给较多的铺垫,在靠后的部分,才进行深入的源码解析。
这个系列的文章都会比较长,大家按需阅读。
什么是上下文管理?
不知道大家有没有好奇过,为什么最早在使用DeepSeek的时候,要不停的新建会话,有的时候,它还会提醒你会话已满。
难道不能直接一个会话一直聊下去吗?这样多简单。
这就要从大模型的工作原理说起。
我们使用大模型的时候,会觉得大模型可以记住我们的一些信息。但其实是一个误解,大模型在底层技术原理上并没有记忆机制。
它的本质是一个推理引擎:你给它的输入,就是上下文。它根据你的输入给你输出(给你输出的过程就叫推理)。每一次推理,它都是从零开始读一遍所有输入,然后生成回答。它不像人一样有持久的神经记忆,上一次对话发生了什么,下一次它完全不知道。
所以,为了让模型有类似于记忆的能力。每次你发一条新消息,Agent都会把整个对话历史重新打包发给模型。模型看的不是”上一条消息”,而是从第一条开始的完整对话记录。它每次都在重新阅读一遍所有内容,然后接着往下说。所以它好像是记得你说了什么。
但这并不是因为大模型具备这个能力,而是因为我们通过打包会话历史,管理了大模型的上下文。
更重要的是,大模型的工作方式决定了它只能根据你的上下文。去完成它的输出,所以你上下文的质量,是影响大模型效果的一个核心要素之一。
你上下文的指令越清晰,模型就能更好地去识别你的意图,给出更好的结果。比如,我们一直会推荐在使用DeepSeek的时候,在聊不同的事情的时候,尽量切换会话去聊。因为如果说你在同一个会话当中,既聊如何做菜,又聊怎么写代码?它就很难去分辨,你要求他输出的教程步骤,到底是做菜的步骤还是代码的步骤。
同时,上下文还是一种资源。大模型对于输入的内容是有上限的,他就只能够接受那么多内容。超过了它就没法工作了。行业会用context window(上下文窗口或者叫上下文长度)的Token 数来量化这个上限。
所以为了使得模型能够更好地按照我们的要求去工作。我们就需要,通过上下文管理,在有限的上下文窗口内,尽量好的让上下文更加清晰、简洁。
上下文管理的技巧
理解了上下文的原理,接下来是更实用的部分——你能做什么?
这部分梳理了上下文管理的四层技巧,从最基础的提示词习惯,到本地 Agent 的使用,再到主动配置上下文环境,最后是跨时间、跨项目的记忆沉淀。
第一层:清晰简洁的提示词
好的提示词是上下文管理的基本功。你的意图和目标只有你最清楚,AI 没有能力替你补全你没说的部分,它只能根据你给的内容去推断。
几个立竿见影的习惯:一个任务开一个会话,不要把不相关的事情混在一起聊,上下文越单一,AI 越能准确判断你的意图;会话开头主动交代背景,你是谁、这个任务的目标是什么、有哪些约束,不要等 AI 来问;用角色设定或系统提示词固定常用背景,如果你经常让 AI 做某类任务,把你的背景和要求写成一段固定的说明,每次开新会话带上,比每次重新解释高效得多。
提示词技巧这个话题讲的人很多,就不展开了,网上资料很多。但这一步不管是在网页对话、还是用 Claude Code、OpenClaw,都是最基础也最有效的起点。
第二层:使用本地 Agent
网页对话的上限是你能粘贴进去的内容,而本地 Agent(比如 Claude Code)可以直接读取你电脑上的文件——代码库、文档、笔记——不需要手动上传,也不需要粘贴。这意味着你可以把整个项目作为上下文,而不是每次只能给它看一个片段。
用好本地 Agent,需要几个配套习惯:
维护清晰的文件结构。 AI 读取文件的方式和人不同,它不会打开文件夹一个个翻,而是根据你的指令去找。文件命名混乱、层级不清晰,它就很容易读错位置、读到无关内容。好的文件结构,不只是让你自己找东西方便,也是在帮 AI 更准确地理解你的项目。一个简单的标准:让 AI 光看文件名和目录结构,就能大致猜出每个文件是干什么的。
用文件路径和 AI 沟通。 在本地 Agent 里,与其描述”上次那篇关于产品定价的文章”,不如直接说”看一下 内容/2026-03-定价策略.md“。路径越具体,AI 读取的范围越精准,它的回答也越准确。这个习惯养成之后,你会发现沟通效率提升很明显,减少了大量来回确认的步骤。
用 Git 管理版本。 让 AI 直接修改本地文件,最大的风险是改出问题不好回滚。Git 解决的就是这个问题:每次让 AI 做一批修改之前先 commit 一个版本,即使出了问题,也不会影响过去的版本记录,一条Git 命令就恢复到上个版本。
这不只是工程习惯,在 AI 大量介入文件编辑的场景下,版本控制是你的安全网。就算你不写代码,用 AI 整理文档、管理笔记,也值得养成这个习惯。
对于一些非程序员背景的同学,可能会觉得 git有点复杂。但相信我们只要稍微花1-2个小时去跟AI学习一下,一定能学会,它其实跟各种云文档的版本控制本质是一样的。
使用本地的 Agent,你就能解锁这些优势。它也是后续更进阶玩法的基础。如果说 Claude Code 暂时用不了,Codex、Cursor、WorkBuddy、Kimi Code 这些也都是可以的。
第三层:主动配置Tool 的上下文环境
前面我们讲过 Skill、MCP、Plugin 这类功能,这些本质都是模型的tool工具(如果不理解这些是什么的,可以翻一翻我前几篇的文章)。他们在本地也都是以文件的形式存在的,所以,我们需要管理它在什么样的场景下,去使用这些工具。在你开口之前,提前把重要的背景信息注入到上下文里。
以 CLAUDE.md 为例。这是 Claude Code 里一个专门用来写”长期指令”的文件。你希望模型在整个项目里始终遵守的规则、背景信息、行为偏好,都可以写在这里。
但 CLAUDE.md 是有层级的:你可以在用户级(全局)配置一份,也可以在每个项目目录下单独放一份,还可以在子目录里再放一份,越靠近当前工作目录的配置优先级越高。全局配置写你所有任务都适用的通用规则,项目配置写这个项目专属的背景和约束。
Skill 和 MCP 的逻辑是一样的。你可以把它们配置在用户级,让所有项目都能用;也可以只在某个项目目录下启用,只在这个项目里生效。
核心原则只有一条:按需配置,不要堆全局。 上下文不是越多越好,和当前任务无关的配置塞进来,一样是一种污染——它会占用上下文额度,也会干扰模型的判断。不同项目用不同的配置,用不到的及时关掉。定期检查一下你的全局配置,清掉那些装了很久但其实一直没用到的插件和指令。
第四层:跨时间、跨项目的记忆沉淀
这是最容易被忽视、但长期收益最大的一层。AI 的自动记忆是有的,但它记什么、怎么记,你很难控制。更可靠的做法是主动维护记忆文件,把重要的决策、经验、偏好手动沉淀下来,下次开新会话时带进来。
在实际操作上,可以配置一个/log 的命令,每次完成一个阶段性任务,让 AI 根据你的要求沉淀一份总结,记录”做了什么、遇到什么问题、下次注意什么”。这份文件就是你跨会话的记忆。比起让系统自动记忆,手动维护的内容更精准、更可控,不会丢掉关键细节。
当然,现在也有很多Agent的框架,在不断的优化这点,比如Hermes Agent,它在记忆管理这个方向有很多优化,但仍然存在有不符合你预期的情况,所以针对重要的部分,还是建议去做主动的管理。
源码解析
/context 命令
CC 有一个内置的 /context 命令。你输入这个命令,它会实时告诉你当前的上下文组成,以及每个部分占用了多少 token。
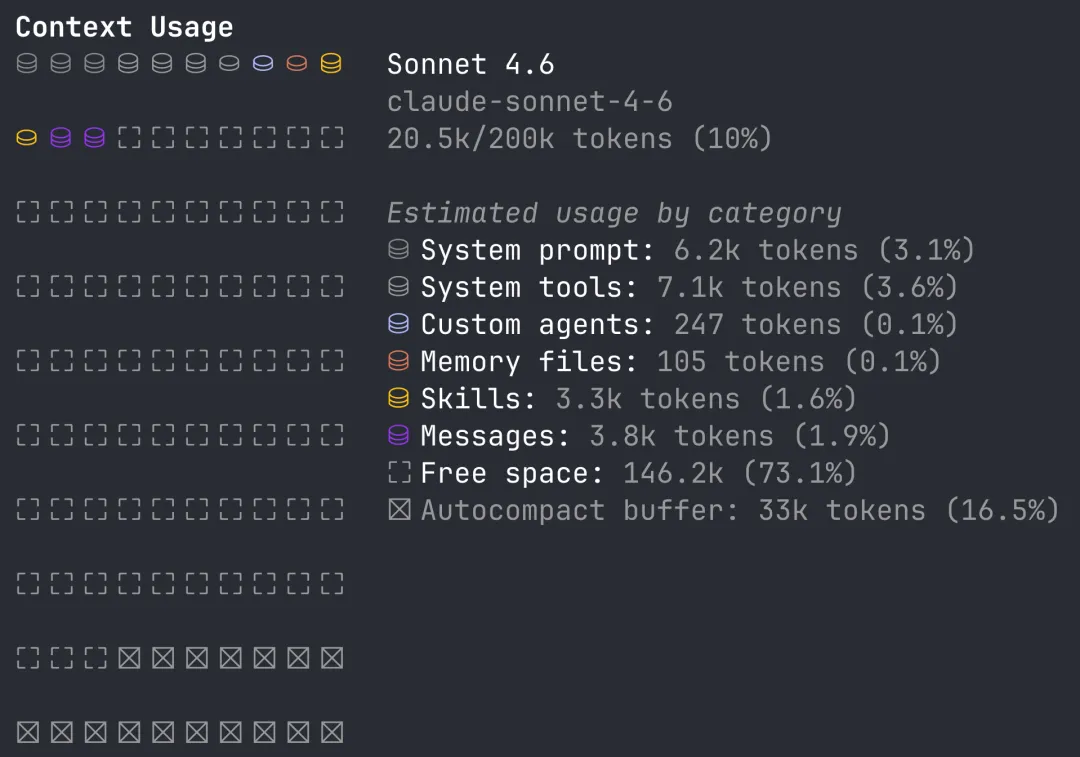
它把整个上下文窗口分成七类:
|
|
|
|
|---|---|---|
| System prompt |
|
|
| System tools |
|
|
| MCP tools |
|
|
| Memory files |
.claude/rules/ 里的规则) |
|
| Skills |
|
|
| Custom agents |
|
|
| Messages |
|
|
最后,还有一项 Autocompact buffer,这不是上下文内容,而是 CC 预留给压缩机制的缓冲区。
CC 设计思路
上下文如何组装?
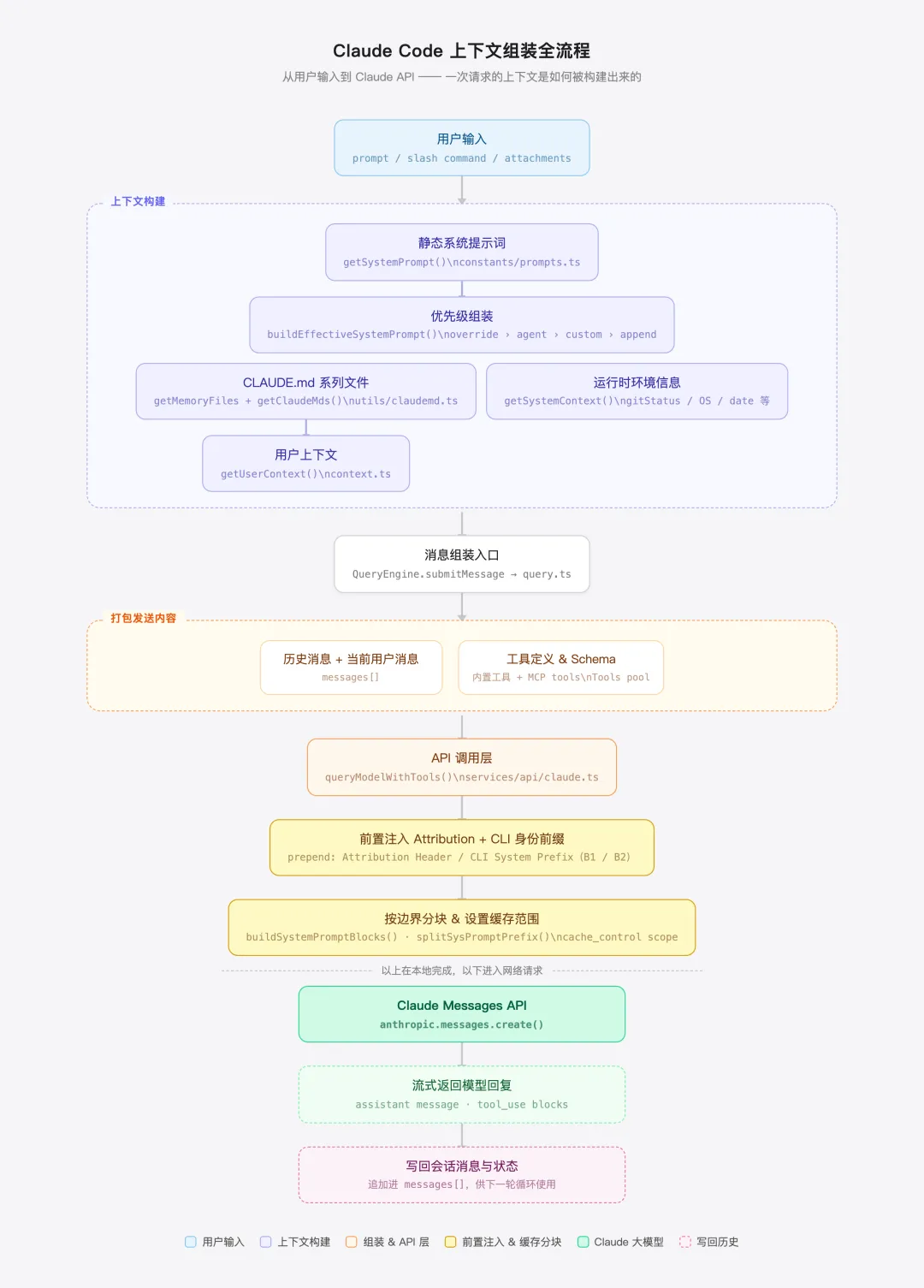
通过这张图可以看出来,在发送给模型之前,上下文是如何组装起来的。
CC 没有”用户说什么就发什么”,而是在每次用户的对话请求发出之前,经过多个层次的组装、过滤、优先级处理,最终才形成一份精心构造的上下文发给模型。
上下文组成的代码级总览图
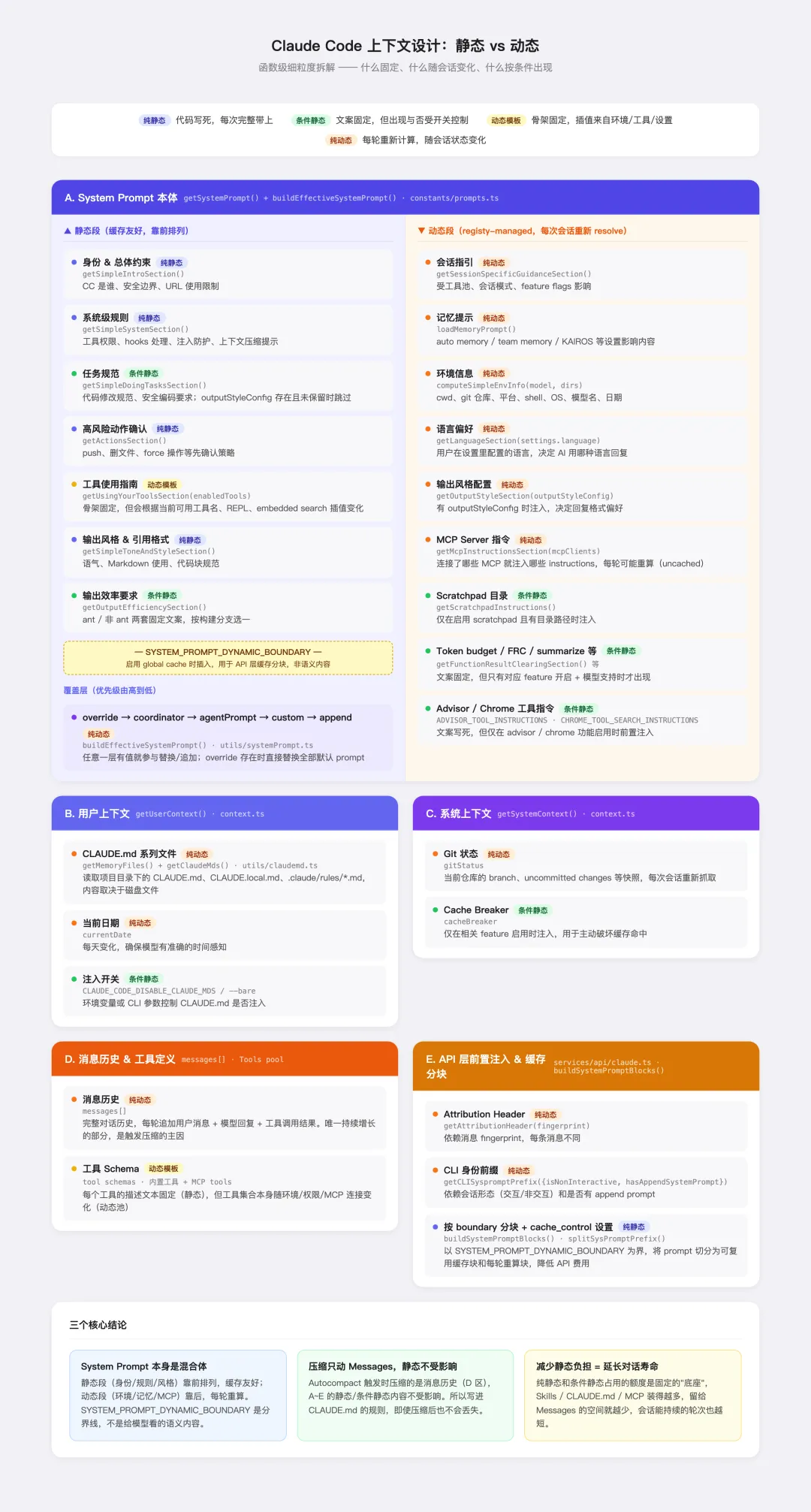
这张图则展示了一个更重要的视角:CC 发给模型的上下文,是按静态和动态两类严格分层的。
这样分层设计的好处有:
静态与动态分离,缓存降本。 System Prompt 内部以 SYSTEM_PROMPT_DYNAMIC_BOUNDARY 为界,把内容切成两块:前半段是每次对话都不变的静态规则(身份定义、任务规范、工具指南),后半段是随会话变化的动态段(环境信息、MCP 指令、记忆内容)。API 层的 buildSystemPromptBlocks() 会识别这个边界,给静态块打上 cache_control,让它在多次请求之间复用,避免重复计费。
按需注入,不堆全局。 动态段里有十几个 section,但不是每次都全部注入——它们由注册表统一管理,只有对应条件满足时才出现(比如连接了 MCP 才有 MCP 指令,开启了 scratchpad 才有目录路径)。上下文额度是有限资源,不相关的内容不应该占位。这也是为什么建议 Skill 和 MCP 按项目配置而不是堆全局,你装的每一个都在消耗这个有限的静态底座。
覆盖层优先级明确,给高级用法留口。 System Prompt 有五层覆盖机制:override → coordinator → agentPrompt → custom → append,优先级由高到低。这让 CC 可以在不同场景下灵活替换或追加提示词——SDK 直接传 custom,多 Agent 模式用 agentPrompt,有最高权限需求时用 override 直接替换全部默认内容。多数普通用户永远用不到这些,但这个设计让 CC 能支撑从个人工具到企业级定制的各种场景。
压缩只动 Messages,静态内容不受影响。 当你的上下文在快达到上限的时候,会出现自动压缩Autocompact。但触发时,被压缩的是消息历史,System prompt、CLAUDE.md、工具定义这些静态内容完好无损。这意味着你写在 CLAUDE.md 里的规则和约束,即使对话跑了很长、经历过多次压缩,依然有效。所以跨时间跨会话的数据沉淀是有策略的,当你判断你跟模型的对话有一些值得沉淀的关键内容,就可以主动去做。因为模型压缩的效果可能并不符合你的预期,会丢失掉你的一些重要的结论。
减少静态负担 = 延长对话周期。 静态内容(System prompt、工具定义、CLAUDE.md、Skills、MCP)占用的额度是每次会话的固定底座,在你说第一句话之前就已经用掉了。底座越大,留给消息历史的空间就越小,会话能持续的轮次也越短。所以按项目去配置,不仅仅是避免上下文污染的问题,也能让你更加节省token、节省上下文窗口,延长对话周期。
写在最后
这期从上下文是什么,为什么它很重要?到梳理了上下文管理的四层实用技巧,最后深入 CC 源码,看清楚了它是怎么组装上下文的、又是怎么把内容分成静态和动态两层来管理的。理解了 CC 在上下文管理上的设计思路。
下一期,我们讲什么是Skill,为什么Skill 这么有价值?
我们下期见。
「Claude Code 源码精读」系列持续更新,关注我,带你理解最顶尖的 Agent 设计。