 夜雨聆风
夜雨聆风





ILEAI:一个行业长期就业吸引力的评估框架

ILEAI:一个行业长期就业吸引力的评估框架
Industry Long-term Employment Attractiveness Index
引言
问题的提出
“选择大于努力”是职场中广为流传的一句话。大量实证研究表明,个体的职业发展轨迹不仅取决于个人能力和努力程度,更受到所处行业的深刻影响。处于扩张期的行业为从业者提供更多的晋升机会、更高的薪酬增长和更大的职业选择空间,而处于收缩期的行业则可能使个体陷入“电梯向下”的困境——即便个人表现优异,也难以抵消行业衰退带来的负面影响。
然而,当求职者面临“应该深耕哪个行业”这一关键决策时,却缺乏一个系统化的评估工具。现有的行业分析框架(如Porter五力模型、McKinsey行业生命周期模型)是为企业战略决策或投资决策设计的,其关注焦点是行业的竞争格局和投资回报率,而非行业对从业者的长期就业吸引力。
求职者关心的问题与投资者不同。投资者问的是“这个行业能赚多少钱”,而求职者需要回答的是一组更复杂的问题:这个行业的薪酬水平如何?它会不会在未来5-10年萎缩甚至消失?在这个行业里跳槽容易吗?在里面工作会不会身心俱疲?
ILEAI(Industry Long-term Employment Attractiveness Index,行业长期就业吸引力指数)正是为了填补这一空白而设计的。它提供了一个从求职者视角出发、系统评估行业长期就业吸引力的量化工具。
设计思路
ILEAI的设计基于一个核心类比:选择一个行业长期深耕,本质上等同于一项长期投资。
求职者将自己最宝贵的资产——时间、精力、学习成本——投入到一个行业中,期望获得经济回报、职业安全感、选择自由度和可持续的工作体验。这与金融学中评估长期投资的逻辑高度一致。
现代投资组合理论(Markowitz, 1952)和资本资产定价模型(Sharpe, 1964)确立了评估投资的四个核心维度:收益(Return)、风险(Risk)、流动性(Liquidity)和持有体验(Holding Experience)。这四个维度构成一个公认的MECE框架——任何影响投资决策的因素都可以归入其中一个维度,且维度之间互不重叠。
ILEAI将这一框架从金融投资映射到职业选择,形成四个评估维度:经济回报、行业可持续性、职业流动性、工作体验。在此基础上,每个维度下设置可量化、可获取公开数据的具体指标,形成一个结构化的评估体系。
理论基础
ILEAI的设计综合了以下理论:
职业选择理论。Parsons(1909)提出的特质-因素匹配理论认为,理想的职业选择需要三个步骤:(1) 清晰的自我认知;(2) 对职业世界的系统了解;(3) 前两者之间的合理匹配。ILEAI服务于第二步——为求职者提供一个结构化工具来系统了解行业世界。
投资组合理论。Markowitz(1952)和Sharpe(1964)确立的“收益-风险-流动性”评估框架是ILEAI四维模型的理论来源。本框架将其扩展为包含”工作体验”的四维框架,以反映职业选择中非经济因素的重要性。
行业分析理论。Porter(1980)的行业竞争分析和McKinsey的行业生命周期模型为ILEAI中“行业可持续性”维度的指标设计提供了分析视角。
金字塔原理。Minto(1987)的结构化思维方法指导了ILEAI的分层设计——从维度到指标再到数据,每一层解决不同抽象层次的问题。
目录
1. 模型概述
-
1.1 四维框架
-
1.2 三层评分机制
-
1.3 核心假设与适用边界
2. 四个维度:从哪些角度评估一个行业
-
2.1 经济回报(Return)
-
2.2 行业可持续性(Sustainability)
-
2.3 职业流动性(Liquidity)
-
2.4 工作体验(Experience)
3. 十二个指标:用什么数据衡量
-
3.1 指标设计原则
-
3.2 经济回报维度指标
-
3.3 行业可持续性维度指标
-
3.4 职业流动性维度指标
-
3.5 工作体验维度指标
4. 评分与加权:如何得出最终结论
-
4.1 指标评分方法
-
4.2 权重设定方法
-
4.3 ILEAI计算公式
-
4.4 评级标准
5. 应用指南
-
5.1 应用流程
-
5.2 与职业规划其他环节的衔接
6. 局限性与未来方向
附录A:行业分类标准与初筛方法
附录B:个性化权重设定示例
附录C:指标数据来源汇总表
1. 模型概述
1.1 四维框架
ILEAI从四个相互独立、共同穷尽的维度评估一个行业对求职者的长期就业吸引力:
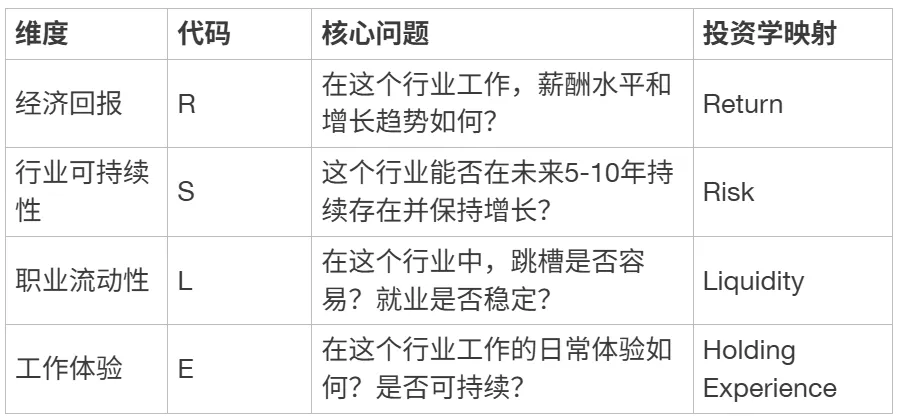
[ { “维度”: “经济回报”, “代码”: “R”, “核心问题”: “在这个行业工作,薪酬水平和增长趋势如何?”, “投资学映射”: “Return” },
{ “维度”: “行业可持续性”, “代码”: “S”, “核心问题”: “这个行业能否在未来5-10年持续存在并保持增长?”, “投资学映射”: “Risk” },
{ “维度”: “职业流动性”, “代码”: “L”, “核心问题”: “在这个行业中,跳槽是否容易?就业是否稳定?”, “投资学映射”: “Liquidity” },
{ “维度”: “工作体验”, “代码”: “E”, “核心问题”: “在这个行业工作的日常体验如何?是否可持续?”, “投资学映射”: “Holding Experience” }]
为什么是这四个维度?
这四个维度对应了求职者进行行业选择时需要回答的四个本质问题,且它们之间满足MECE条件:
-
R回答“我能得到什么”(经济层面)
-
S回答“我可能失去什么”(风险层面)
-
L回答“我的选择权有多大”(灵活性层面)
-
E回答“过程中我的感受如何”(体验层面)
任何一个影响求职者行业选择的因素——无论是薪资水平、政策风险、跳槽便利性、加班强度还是人才环境——都可以被归入这四个维度之一,且不会同时属于两个维度。
1.2 三层评分机制
ILEAI采用三层结构,从底层数据到最终评分逐层抽象:
第一层:指标数据层(Data Layer)。定义每个指标的数据来源、取数口径和数据加工方式。这一层的目标是从公开数据源获取可信、可比较的原始数据。
第二层:指标分数层(Score Layer)。将原始数据映射为标准化的0-10分。每个指标都有明确的锚点——即特定数据值对应特定分数——确保评分有客观依据而非主观判断。锚点之间采用线性插值,使得任何可能出现的数据值都能对应唯一的分数。
第三层:维度分数层(Dimension Layer)。通过加权汇总计算各维度得分和ILEAI总分。权重分为两级:先在维度层面分配(4个维度的相对重要性),再在每个维度内部分配给各指标。权重由使用者根据个人偏好和价值观设定,框架提供默认均等权重作为起点。
三层分离的设计使得框架具有灵活性:底层数据可随数据可获得性更新,中层评分标准可随研究深入优化,顶层权重可因人而异。
1.3 核心假设与适用边界
ILEAI建立在以下假设之上:
假设一:行业选择对职业发展有实质性影响。 即“电梯效应”成立——行业整体的兴衰会显著影响个体的职业发展轨迹。这一假设得到了劳动经济学大量实证研究的支持。
假设二:行业特征具有一定的持续性。 ILEAI评估的是行业的中长期特征(5-10年),假设当前的行业趋势在中期内不会发生根本性逆转。对于正在经历颠覆性变化的行业,评估结论的有效期可能缩短。
假设三:公开数据能够合理反映行业的就业吸引力。 部分指标(如工作规范度、职业健康度)依赖定性评估,可能存在信息不对称。框架通过多数据源交叉验证来降低这一风险。
假设四:行业层面的薪酬回报可近似代表岗位层面的回报。 本框架暂不区分具体岗位差异,具体岗位、具体公司的薪酬与发展空间在后续(行业选择→公司选择→岗位选择)环节单独评估。
假设五:行业转换存在较高成本。 个体一旦在某一行业持续积累经验,其能力、履历与机会将逐步路径依赖,跨行业转换通常较为困难,这也是行业选择具有长期意义的重要前提。
适用边界:ILEAI适用于知识型白领求职者评估行业选择。对于蓝领岗位、体制内岗位(公务员/事业单位)或创业方向的评估,本框架的适用性有限。此外,ILEAI评估的是行业整体特征。
2. 四个维度:从哪些角度评估一个行业
2.1 经济回报(R)
经济回报维度衡量的是在该行业长期工作所能获得的经济收益水平及其增长趋势。
这是求职者最直观关心的维度,但需要注意的是:ILEAI在这一维度中评估的是行业整体的薪酬水平,而非特定岗位的薪酬天花板。
本维度包含两个指标:
-
R1 行业薪酬溢价:该行业的当前薪酬水平相对于全社会平均水平的位置——回答“现在给多少”
-
R2 薪酬增长率:该行业薪酬水平的增长速度——回答“未来能给多少”
两个指标分别捕捉了薪酬的水平和斜率,共同刻画了行业经济回报的全貌。
2.2 行业可持续性(S)
行业可持续性维度衡量的是该行业在未来5-10年内持续存在、保持增长或至少不萎缩的可能性。
这是一个底线型维度——如果一个行业正在萎缩或面临政策禁止的风险,那么无论其薪酬多高、体验多好,长期深耕的价值都会被侵蚀。
本维度包含三个指标:
-
S1 行业增长动能:行业规模的增长趋势——回答“行业在变大还是变小”
-
S2 政策合规稳定性:行业面临的政策风险——回答“行业会不会突然被禁止或严重限制”
-
S3 行业技术颠覆风险:行业核心商业模式被新技术颠覆的可能性——回答“行业会不会被技术淘汰”
三个指标分别从市场力量、政策力量和技术力量三个外部驱动因素评估行业的可持续性,确保不遗漏任何可能导致行业衰退的主要风险来源。
需要特别说明的是,S3评估的是行业级的技术颠覆(如“互联网颠覆了线下旅行社行业”导致整个行业萎缩),而非岗位级的自动化替代(如“AI替代了初级数据录入员”但行业本身仍在增长)。岗位级的技术替代风险应在后续的岗位选择阶段评估。
2.3 职业流动性(L)
职业流动性维度衡量的是求职者在该行业中的职业选择自由度——能否顺畅地跳槽、切换雇主和调整方向。
高流动性意味着求职者有更强的议价权和更大的容错空间:即使第一份工作不理想,也有足够多的替代选择。低流动性则意味着被“锁定”在少数雇主中,一旦当前雇主出现问题,转换成本极高。
本维度包含三个指标:
-
L1 雇主数量与行业集中度:行业内可供选择的雇主数量及其分布——回答“有多少公司可以跳”
-
L2 就业稳定性:行业就业人数的波动程度——回答“这个行业会不会周期性大裁员”
-
L3 正式雇佣比例:正式劳动合同vs.外包/派遣的比例——回答“身份是否有保障”
三个指标分别从选择面(有多少选择)、稳定性(选择是否可靠)和雇佣质量(选择的质量如何)三个层面刻画职业流动性。
2.4 工作体验(E)
工作体验维度衡量的是在该行业中工作的日常体验质量。
这一维度之所以重要,是因为职业选择不仅是经济决策,更是一个关乎生活质量的长期承诺。一个薪酬优厚但身心俱疲的行业,其长期吸引力会随着从业年限的增加而递减。
本维度包含四个指标:
-
E1 实际工时:行业平均每周实际工作时长——回答“要工作多久”
-
E2 工作规范度:行业对劳动法规的遵守程度——回答“规则是否被尊重”
-
E3 人才密度:行业内高学历/高素质人才的聚集程度——回答“和什么人一起工作”
-
E4 职业健康度:行业的身体和心理健康风险水平——回答“工作是否可持续”
四个指标分别从时间投入、制度环境、人际环境和健康影响四个方面全面覆盖了工作体验的核心要素。
3. 十二个指标:用什么数据衡量
3.1 指标设计原则
每个指标的设计遵循以下原则:
可获取性:指标数据应来自公开数据源(政府统计、行业报告、招聘平台数据),不依赖内部数据或付费数据库。
可比较性:不同行业的同一指标应采用相同的取数口径和算分标准,确保横向可比。
有锚点:每个指标的评分标准都有明确的现实参照物(如“全社会平均工资”作为薪酬溢价的基准线),而非凭主观感觉打分。
连续映射:评分采用0-10分连续区间+线性插值,确保任何可能出现的数据值都能对应唯一的分数,避免“刚好在两个等级之间”的模糊情况。
3.2 经济回报维度指标
R1 行业薪酬溢价
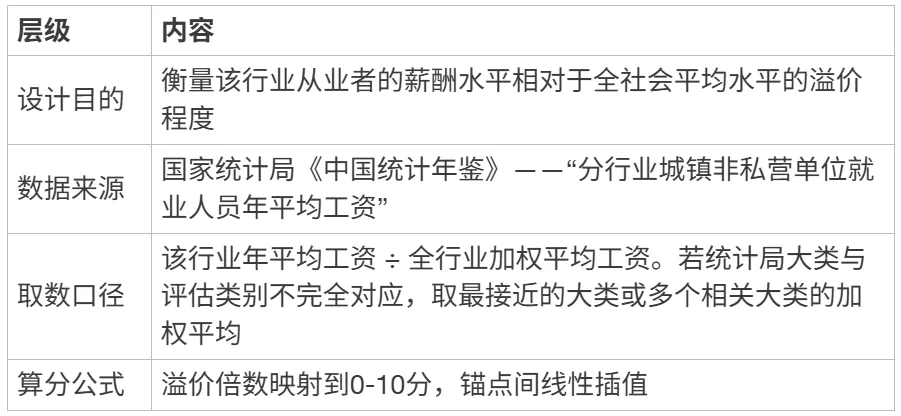
[ { “层级”: “设计目的”, “内容”: “衡量该行业从业者的薪酬水平相对于全社会平均水平的溢价程度” },
{ “层级”: “数据来源”, “内容”: “国家统计局《中国统计年鉴》——“分行业城镇非私营单位就业人员年平均工资”” },
{ “层级”: “取数口径”, “内容”: “该行业年平均工资 ÷ 全行业加权平均工资。若统计局大类与评估类别不完全对应,取最接近的大类或多个相关大类的加权平均” },
{ “层级”: “算分公式”, “内容”: “溢价倍数映射到0-10分,锚点间线性插值” }]
评分锚点:
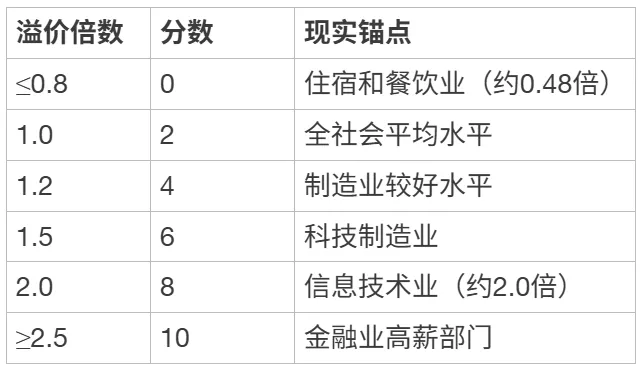
[ { “溢价倍数”: “≤0.8”, “分数”: 0, “现实锚点”: “住宿和餐饮业(约0.48倍)” },
{ “溢价倍数”: “1.0”, “分数”: 2, “现实锚点”: “全社会平均水平” },
{ “溢价倍数”: “1.2”, “分数”: 4, “现实锚点”: “制造业较好水平” },
{ “溢价倍数”: “1.5”, “分数”: 6, “现实锚点”: “科技制造业” },
{ “溢价倍数”: “2.0”, “分数”: 8, “现实锚点”: “信息技术业(约2.0倍)” },
{ “溢价倍数”: “≥2.5”, “分数”: 10, “现实锚点”: “金融业高薪部门” }]
注:锚点数据基于国家统计局2024年发布的2023年度数据,全行业城镇非私营单位年均工资约12.2万元。
R2 薪酬增长率

[ { “层级”: “设计目的”, “内容”: “衡量该行业薪酬的增长速度,反映未来的累积收益潜力” },
{ “层级”: “数据来源”, “内容”: “国家统计局历年分行业平均工资数据” },
{ “层级”: “取数口径”, “内容”: “近5年行业平均工资的年复合增长率 CAGR = (末年工资/初年工资)^(1/4) – 1” },
{ “层级”: “算分公式”, “内容”: “CAGR映射到0-10分” }]
评分锚点:
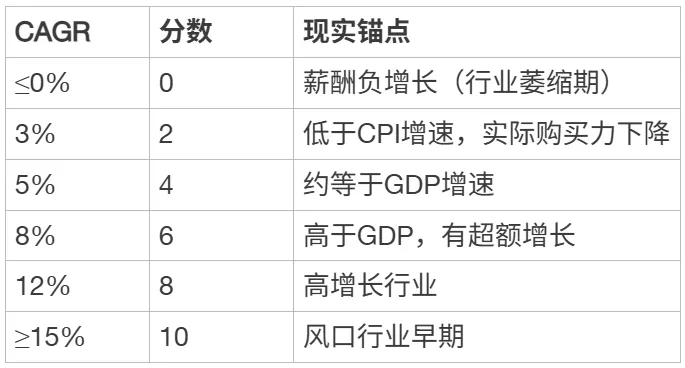
[ { “CAGR”: “≤0%”, “分数”: 0, “现实锚点”: “薪酬负增长(行业萎缩期)” },
{ “CAGR”: “3%”, “分数”: 2, “现实锚点”: “低于CPI增速,实际购买力下降” },
{ “CAGR”: “5%”, “分数”: 4, “现实锚点”: “约等于GDP增速” },
{ “CAGR”: “8%”, “分数”: 6, “现实锚点”: “高于GDP,有超额增长” },
{ “CAGR”: “12%”, “分数”: 8, “现实锚点”: “高增长行业” },
{ “CAGR”: “≥15%”, “分数”: 10, “现实锚点”: “风口行业早期” }]
3.3 行业可持续性维度指标
S1 行业增长动能

[ { “层级”: “设计目的”, “内容”: “衡量行业整体规模的增长趋势,增长的行业意味着更多岗位和机会” },
{ “层级”: “数据来源”, “内容”: “国家统计局行业增加值数据;信通院/IDC/Gartner/前瞻产业研究院行业报告” },
{ “层级”: “取数口径”, “内容”: “取“近3年实际营收CAGR”与“权威机构未来5年预测CAGR”的均值,作为综合增长动能” },
{ “层级”: “算分公式”, “内容”: “综合增长动能映射到0-10分” }]
评分锚点:
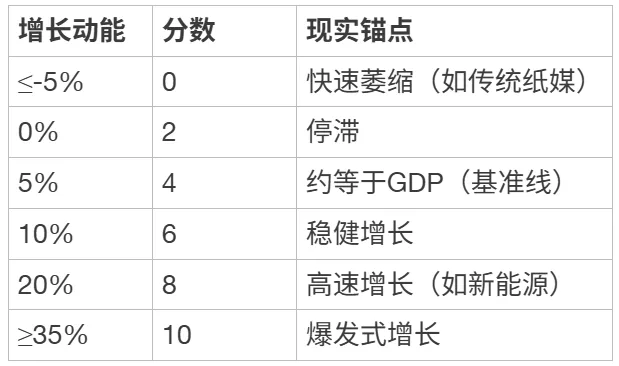
[ { “增长动能”: “≤-5%”, “分数”: 0, “现实锚点”: “快速萎缩(如传统纸媒)” },
{ “增长动能”: “0%”, “分数”: 2, “现实锚点”: “停滞” },
{ “增长动能”: “5%”, “分数”: 4, “现实锚点”: “约等于GDP(基准线)” },
{ “增长动能”: “10%”, “分数”: 6, “现实锚点”: “稳健增长” },
{ “增长动能”: “20%”, “分数”: 8, “现实锚点”: “高速增长(如新能源)” },
{ “增长动能”: “≥35%”, “分数”: 10, “现实锚点”: “爆发式增长” }]
S2 政策合规稳定性

[ { “层级”: “设计目的”, “内容”: “衡量行业面临的政策风险。这是底线型指标——政策风险一旦触发,不可逆” },
{ “层级”: “数据来源”, “内容”: “国务院/发改委/工信部政策文件;产业目录(鼓励类/限制类/淘汰类)” },
{ “层级”: “取数口径”, “内容”: “定性评估。判断维度:是否有国家产业政策明确支持?是否在负面清单中?过去5年是否发生过重大监管变化?核心商业模式是否依赖政策红利?” },
{ “层级”: “算分公式”, “内容”: “定性映射到0-10分” }]
评分锚点:
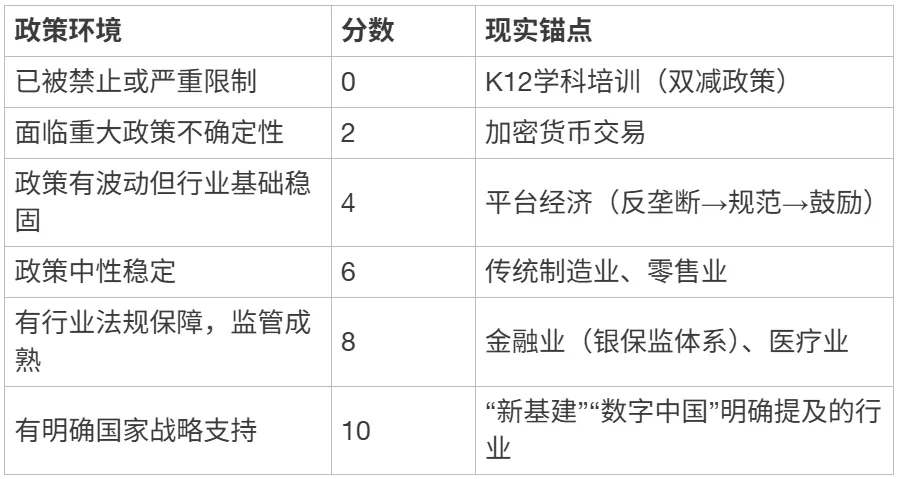
[ { “政策环境”: “已被禁止或严重限制”, “分数”: 0, “现实锚点”: “K12学科培训(双减政策)” },
{ “政策环境”: “面临重大政策不确定性”, “分数”: 2, “现实锚点”: “加密货币交易” },
{ “政策环境”: “政策有波动但行业基础稳固”, “分数”: 4, “现实锚点”: “平台经济(反垄断→规范→鼓励)” },
{ “政策环境”: “政策中性稳定”, “分数”: 6, “现实锚点”: “传统制造业、零售业” },
{ “政策环境”: “有行业法规保障,监管成熟”, “分数”: 8, “现实锚点”: “金融业(银保监体系)、医疗业” },
{ “政策环境”: “有明确国家战略支持”, “分数”: 10, “现实锚点”: ““新基建”“数字中国”明确提及的行业” }]
S3 行业技术颠覆风险

[ { “层级”: “设计目的”, “内容”: “衡量行业核心商业模式被新技术从根本上颠覆的可能性(行业级颠覆,非岗位级替代)” },
{ “层级”: “数据来源”, “内容”: “McKinsey Global Institute报告;世界经济论坛《Future of Jobs Report》;行业AI应用研究” },
{ “层级”: “取数口径”, “内容”: “定性评估。判断维度:行业核心价值创造是否可被技术完全替代?行业是否有强“物理世界”属性?技术是“增强”还是“替代”该行业?” },
{ “层级”: “算分公式”, “内容”: “定性映射到0-10分(注意:此指标方向为“风险越低分越高”)” }]
评分锚点:
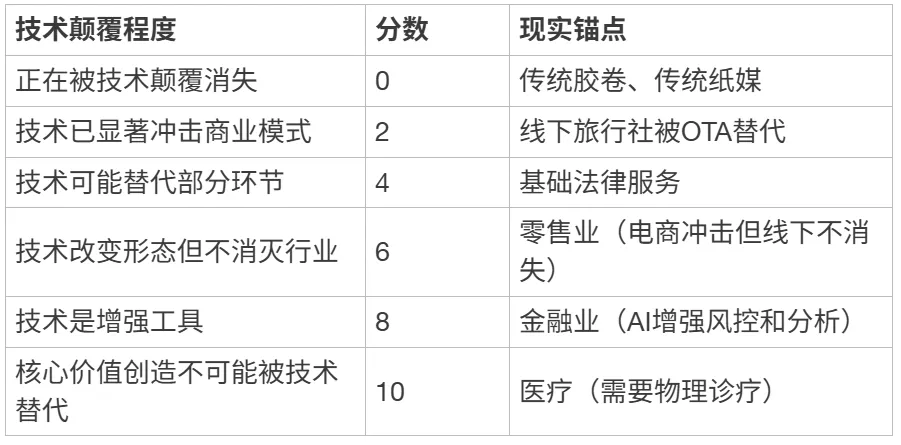
[ { “技术颠覆程度”: “正在被技术颠覆消失”, “分数”: 0, “现实锚点”: “传统胶卷、传统纸媒” },
{ “技术颠覆程度”: “技术已显著冲击商业模式”, “分数”: 2, “现实锚点”: “线下旅行社被OTA替代” },
{ “技术颠覆程度”: “技术可能替代部分环节”, “分数”: 4, “现实锚点”: “基础法律服务” },
{ “技术颠覆程度”: “技术改变形态但不消灭行业”, “分数”: 6, “现实锚点”: “零售业(电商冲击但线下不消失)” },
{ “技术颠覆程度”: “技术是增强工具”, “分数”: 8, “现实锚点”: “金融业(AI增强风控和分析)” },
{ “技术颠覆程度”: “核心价值创造不可能被技术替代”, “分数”: 10, “现实锚点”: “医疗(需要物理诊疗)” }]
3.4 职业流动性维度指标
L1 雇主数量与行业集中度

[ { “层级”: “设计目的”, “内容”: “衡量行业内可供选择的雇主数量和分布均匀度” },
{ “层级”: “数据来源”, “内容”: “天眼查/企查查行业统计;上市公司年报/行业协会报告” },
{ “层级”: “取数口径”, “内容”: “雇主数量:年营收≥5000万元或员工≥100人的企业数量。行业集中度:CR5(前5名企业市场份额之和)。两者联合判断” },
{ “层级”: “算分公式”, “内容”: “综合判断映射到0-10分” }]
评分锚点:
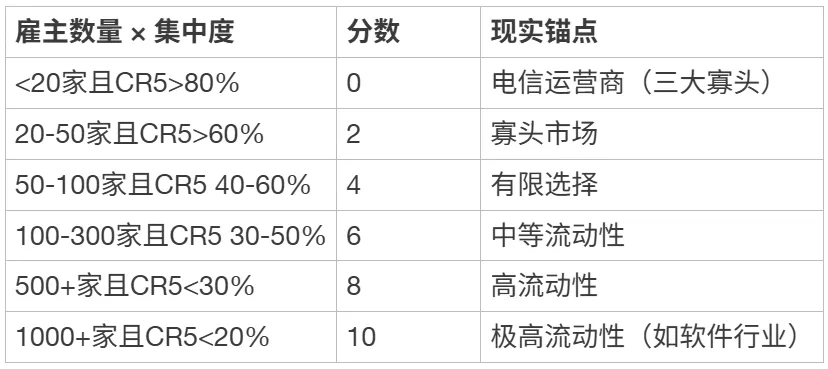
[ { “雇主数量 × 集中度”: “<20家且CR5>80%”, “分数”: 0, “现实锚点”: “电信运营商(三大寡头)” },
{ “雇主数量 × 集中度”: “20-50家且CR5>60%”, “分数”: 2, “现实锚点”: “寡头市场” },
{ “雇主数量 × 集中度”: “50-100家且CR5 40-60%”, “分数”: 4, “现实锚点”: “有限选择” },
{ “雇主数量 × 集中度”: “100-300家且CR5 30-50%”, “分数”: 6, “现实锚点”: “中等流动性” },
{ “雇主数量 × 集中度”: “500+家且CR5<30%”, “分数”: 8, “现实锚点”: “高流动性” },
{ “雇主数量 × 集中度”: “1000+家且CR5<20%”, “分数”: 10, “现实锚点”: “极高流动性(如软件行业)” }]
L2 就业稳定性

[ { “层级”: “设计目的”, “内容”: “衡量行业就业人数的波动程度,反映周期性裁员风险” },
{ “层级”: “数据来源”, “内容”: “国家统计局分行业就业人数(历年);人社部就业监测数据” },
{ “层级”: “取数口径”, “内容”: “过去5-10年行业就业人数序列的变异系数 CV = 标准差/均值 × 100%” },
{ “层级”: “算分公式”, “内容”: “CV映射到0-10分(CV越小分越高)” }]
评分锚点:
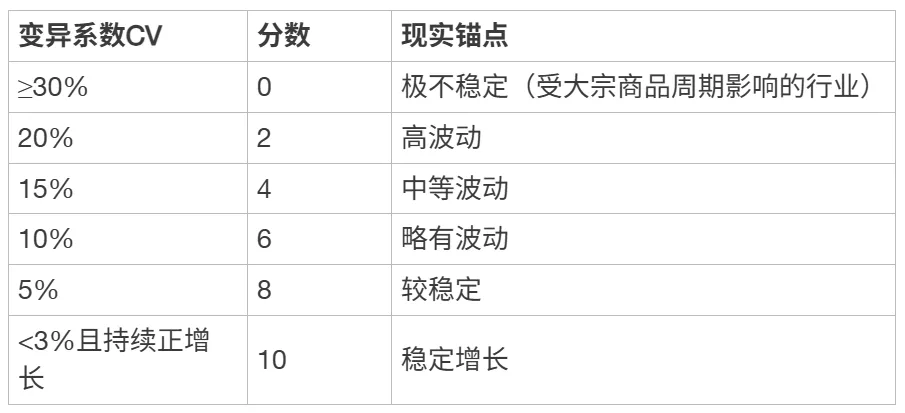
[ { “变异系数CV”: “≥30%”, “分数”: 0, “现实锚点”: “极不稳定(受大宗商品周期影响的行业)” },
{ “变异系数CV”: “20%”, “分数”: 2, “现实锚点”: “高波动” },
{ “变异系数CV”: “15%”, “分数”: 4, “现实锚点”: “中等波动” },
{ “变异系数CV”: “10%”, “分数”: 6, “现实锚点”: “略有波动” },
{ “变异系数CV”: “5%”, “分数”: 8, “现实锚点”: “较稳定” },
{ “变异系数CV”: “<3%且持续正增长”, “分数”: 10, “现实锚点”: “稳定增长” }]
L3 正式雇佣比例

[ { “层级”: “设计目的”, “内容”: “衡量行业内正式劳动合同(vs.外包/派遣/灵活用工)的占比” },
{ “层级”: “数据来源”, “内容”: “人社部统计;行业调研报告;上市公司年报用工结构披露” },
{ “层级”: “取数口径”, “内容”: “正式雇佣人数 / 总从业人数 × 100%” },
{ “层级”: “算分公式”, “内容”: “比例直接映射到0-10分” }]
评分锚点:
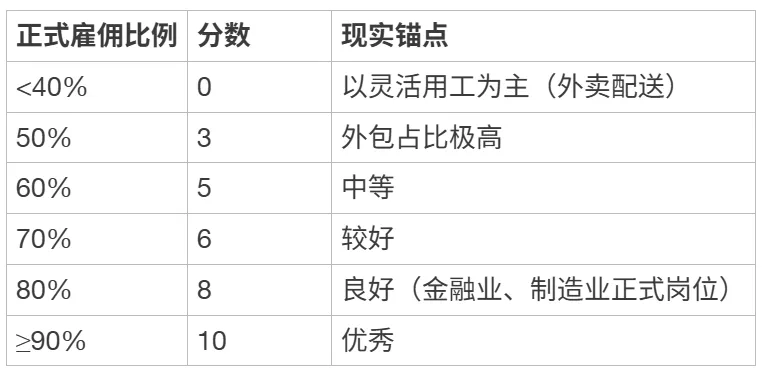
[ { “正式雇佣比例”: “<40%”, “分数”: 0, “现实锚点”: “以灵活用工为主(外卖配送)” },
{ “正式雇佣比例”: “50%”, “分数”: 3, “现实锚点”: “外包占比极高” },
{ “正式雇佣比例”: “60%”, “分数”: 5, “现实锚点”: “中等” },
{ “正式雇佣比例”: “70%”, “分数”: 6, “现实锚点”: “较好” },
{ “正式雇佣比例”: “80%”, “分数”: 8, “现实锚点”: “良好(金融业、制造业正式岗位)” },
{ “正式雇佣比例”: “≥90%”, “分数”: 10, “现实锚点”: “优秀” }]
3.5 工作体验维度指标
E1 实际工时

[ { “层级”: “设计目的”, “内容”: “衡量行业从业者的实际工作时间,反映时间投入成本” },
{ “层级”: “数据来源”, “内容”: “国家统计局《企业就业人员周平均工作时间》(按行业分);脉脉/看准网行业工时调研” },
{ “层级”: “取数口径”, “内容”: “行业平均每周实际工作时长(含加班),单位:小时” },
{ “层级”: “算分公式”, “内容”: “工时映射到0-10分(工时越短分越高)” }]
评分锚点:
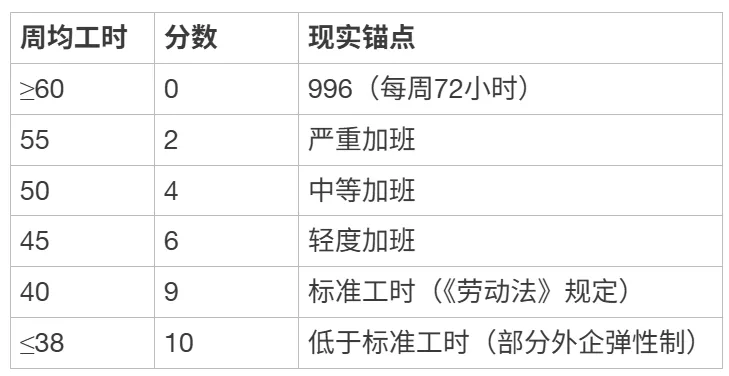
[ { “周均工时”: “≥60”, “分数”: 0, “现实锚点”: “996(每周72小时)” },
{ “周均工时”: “55”, “分数”: 2, “现实锚点”: “严重加班” },
{ “周均工时”: “50”, “分数”: 4, “现实锚点”: “中等加班” },
{ “周均工时”: “45”, “分数”: 6, “现实锚点”: “轻度加班” },
{ “周均工时”: “40”, “分数”: 9, “现实锚点”: “标准工时(《劳动法》规定)” },
{ “周均工时”: “≤38”, “分数”: 10, “现实锚点”: “低于标准工时(部分外企弹性制)” }]
注:2024年全国就业人员周均工时约48.7小时,对应约4.7分,即全国平均水平在中等偏下区间,符合社会认知。
E2 工作规范度

[ { “层级”: “设计目的”, “内容”: “衡量行业主流企业对劳动法规的遵守程度和职场文化健康度” },
{ “层级”: “数据来源”, “内容”: “脉脉行业满意度指数;看准网行业评分;劳动仲裁案件统计(按行业);小红书/知乎行业口碑” },
{ “层级”: “取数口径”, “内容”: “综合评估:双休落实率、加班费执行率、社保合规率、酒文化/关系文化普遍程度” },
{ “层级”: “算分公式”, “内容”: “定性映射到0-10分” }]
评分锚点:
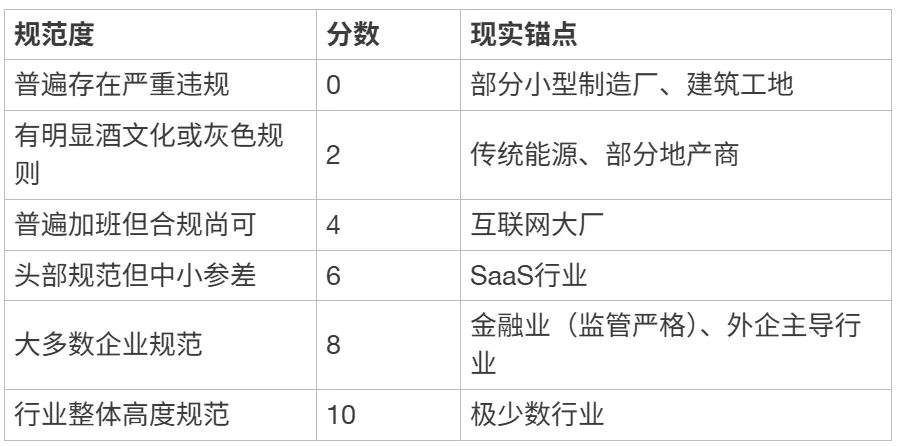
[ { “规范度”: “普遍存在严重违规”, “分数”: 0, “现实锚点”: “部分小型制造厂、建筑工地” }, { “规范度”: “有明显酒文化或灰色规则”, “分数”: 2, “现实锚点”: “传统能源、部分地产商” }, { “规范度”: “普遍加班但合规尚可”, “分数”: 4, “现实锚点”: “互联网大厂” }, { “规范度”: “头部规范但中小参差”, “分数”: 6, “现实锚点”: “SaaS行业” }, { “规范度”: “大多数企业规范”, “分数”: 8, “现实锚点”: “金融业(监管严格)、外企主导行业” }, { “规范度”: “行业整体高度规范”, “分数”: 10, “现实锚点”: “极少数行业” }]
E3 人才密度

[ { “层级”: “设计目的”, “内容”: “衡量行业内高素质人才的聚集程度。与优秀人才共事是隐性回报,有助于能力提升和职业网络建设” },
{ “层级”: “数据来源”, “内容”: “国家统计局分行业从业人员学历结构;行业协会数据” },
{ “层级”: “取数口径”, “内容”: “行业内本科及以上学历从业者占比” },
{ “层级”: “算分公式”, “内容”: “占比直接映射到0-10分” }]
评分锚点:
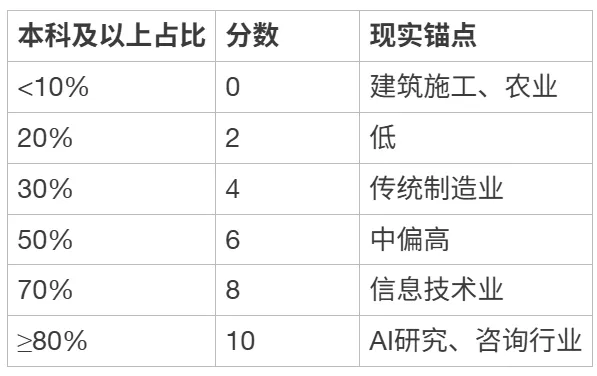
[ { “本科及以上占比”: “<10%”, “分数”: 0, “现实锚点”: “建筑施工、农业” },
{ “本科及以上占比”: “20%”, “分数”: 2, “现实锚点”: “低” },
{ “本科及以上占比”: “30%”, “分数”: 4, “现实锚点”: “传统制造业” },
{ “本科及以上占比”: “50%”, “分数”: 6, “现实锚点”: “中偏高” },
{ “本科及以上占比”: “70%”, “分数”: 8, “现实锚点”: “信息技术业” },
{ “本科及以上占比”: “≥80%”, “分数”: 10, “现实锚点”: “AI研究、咨询行业” }]
E4 职业健康度

[ { “层级”: “设计目的”, “内容”: “衡量行业的身体和心理健康风险水平” },
{ “层级”: “数据来源”, “内容”: “国家卫健委职业病/工伤统计;脉脉年度职场报告(burnout指数);行业心理健康调研” },
{ “层级”: “取数口径”, “内容”: “综合身体健康风险(工伤/职业病率)和心理健康风险(burnout水平)” },
{ “层级”: “算分公式”, “内容”: “定性映射到0-10分(风险越低分越高)” }]
评分锚点:
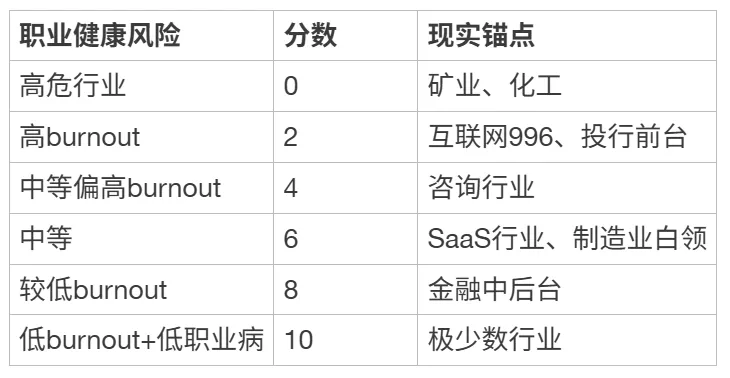
[ { “职业健康风险”: “高危行业”, “分数”: 0, “现实锚点”: “矿业、化工” },
{ “职业健康风险”: “高burnout”, “分数”: 2, “现实锚点”: “互联网996、投行前台” },
{ “职业健康风险”: “中等偏高burnout”, “分数”: 4, “现实锚点”: “咨询行业” },
{ “职业健康风险”: “中等”, “分数”: 6, “现实锚点”: “SaaS行业、制造业白领” },
{ “职业健康风险”: “较低burnout”, “分数”: 8, “现实锚点”: “金融中后台” },
{ “职业健康风险”: “低burnout+低职业病”, “分数”: 10, “现实锚点”: “极少数行业” }]
4. 评分与加权:如何得出最终结论
4.1 指标评分方法
锚点+线性插值法:每个指标设定若干个“锚点”(特定数据值对应特定分数),锚点之间采用线性插值。
计算公式:若数据值x落在锚点(x₁, score₁)和(x₂, score₂)之间,则:
score = score₁ + (x – x₁) / (x₂ – x₁) × (score₂ – score₁)
超出锚点上下界的数据取边界值(即最低0分,最高10分)。
此方法确保评分的连续性和确定性——任何可能的数据值都能对应唯一的分数。
4.2 权重设定方法
权重反映使用者对各维度和指标的相对重视程度。ILEAI提供两种权重设定方式:
默认权重(均等法):四个维度各25%,维度内各指标均等分配。适用于没有明确偏好或作为分析起点。
个性化权重(偏好调整法):使用者根据自身价值观和职业锚调整权重。例如,重视工作生活平衡的求职者可上调E维度权重,重视稳定性的求职者可上调S维度权重。具体的个性化权重设定示例见附录B。
4.3 ILEAI计算公式
R = R1 × wR1 + R2 × wR2 (经济回报维度得分)
S = S1 × wS1 + S2 × wS2 + S3 × wS3 (可持续性维度得分)
L = L1 × wL1 + L2 × wL2 + L3 × wL3 (流动性维度得分)
E = E1 × wE1 + E2 × wE2 + E3 × wE3 + E4 × wE4 (体验维度得分)
ILEAI = R × WR + S × WS + L × WL + E × WE
其中:
– wR1 + wR2 = 100%(R维度内权重之和)
– wS1 + wS2 + wS3 = 100%
– wL1 + wL2 + wL3 = 100%
– wE1 + wE2 + wE3 + wE4 = 100%
– WR + WS + WL + WE = 100%(维度权重之和)
4.4 评级标准
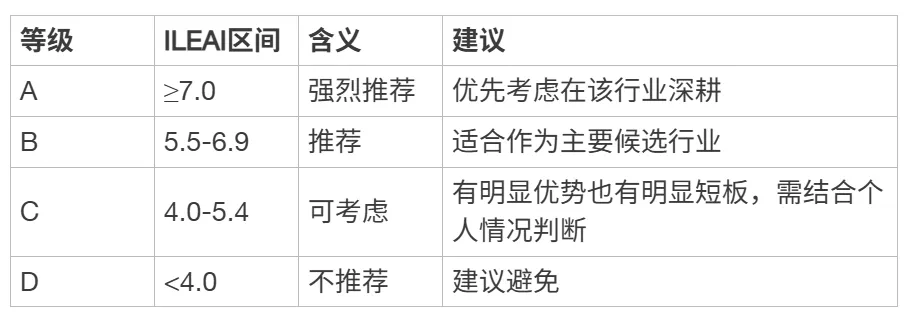
[ { “等级”: “A”, “ILEAI区间”: “≥7.0”, “含义”: “强烈推荐”, “建议”: “优先考虑在该行业深耕” },
{ “等级”: “B”, “ILEAI区间”: “5.5-6.9”, “含义”: “推荐”, “建议”: “适合作为主要候选行业” },
{ “等级”: “C”, “ILEAI区间”: “4.0-5.4”, “含义”: “可考虑”, “建议”: “有明显优势也有明显短板,需结合个人情况判断” },
{ “等级”: “D”, “ILEAI区间”: “<4.0”, “含义”: “不推荐”, “建议”: “建议避免” }]
评级标准的设定依据:以默认均等权重计算,全部指标得5分(中等水平)时ILEAI=5.0,对应C等级下沿。得7分以上(全面优秀)才达到A等级,反映了“强烈推荐”应意味着大多数维度都表现优异。
5. 应用指南
5.1 应用流程
ILEAI的推荐应用流程分为五步:
步骤一:确定评估范围。使用行业分类标准(如GB/T 4754-2017)对全量行业进行穷举,然后通过简单的定性判断快速排除明显不相关的行业(如对于知识型白领求职者,排除以体力劳动为主的行业),得到需要详细评估的行业清单。详细方法见附录A。
步骤二:收集数据。对清单中的每个行业,按照12个指标的数据层定义收集数据。优先使用政府统计数据,辅以行业报告和招聘平台数据。
步骤三:评分。使用锚点+线性插值法,将原始数据映射为0-10分。对于定性指标(S2、S3、E2、E4),需要综合多个信息源做出判断。
步骤四:设定权重并计算。根据个人偏好设定维度权重和指标权重(或使用默认均等权重),代入公式计算ILEAI总分。
步骤五:排序与决策。按ILEAI总分排序,选择评级A或B的行业作为优先候选。建议选择3-5个行业纳入进一步的公司和岗位评估阶段。
5.2 与职业规划其他环节的衔接
ILEAI解决的是职业规划中“知彼”环节的行业选择问题。在完整的职业规划流程中,它的位置如下:
自我评估(知己)──┐
├→ 行业选择(ILEAI)→ 公司选择 → 岗位选择 → 路径实施
环境分析(知彼)──┘
ILEAI的输出(优先行业清单)是下一步“公司选择”的输入——在选定的优先行业中,进一步筛选目标公司,然后在目标公司中匹配适合自己的岗位。
6. 局限性与未来方向
已知局限
数据可获得性差异。12个指标中,定量指标(R1、R2、S1、L2、L3、E1、E3)可从公开数据源获取较为客观的数据,但定性指标(S2、S3、E2、E4)依赖分析者的判断,不同分析者可能给出不同评分。
行业分类粒度。同一个评估类别内部可能存在显著的异质性。例如“互联网平台”中,电商平台和社交平台的工作体验可能差异很大。使用者应根据实际需要决定是否进一步拆分。
静态评估的局限。ILEAI提供的是某一时间点的快照,不能自动反映行业的动态变化。建议至少每12个月重新评估一次。
不涵盖岗位层面差异。同一行业中不同公司、不同岗位的薪酬、工作体验可能有显著差异。ILEAI评估的是行业整体特征,使用者在选定行业后还需要进行独立的岗位评估。
未来方向
定性指标的量化。随着更多的行业员工满意度调研、职场健康数据的公开,定性指标有望逐步实现量化。
动态评估。可以引入趋势因子,不仅评估当前状态,还评估各指标的变化方向和速度。
行业间关联性。某些行业之间存在较强的关联(如金融科技与金融业),未来可以引入行业关联矩阵,帮助求职者评估跨行业的迁移成本。
国际化扩展。当前锚点主要基于中国市场数据。对于考虑海外就业的求职者,需要使用目标市场的本地数据重新校准锚点。
附录A:行业分类标准与初筛方法
A.1 分类标准
采用GB/T 4754—2017《国民经济行业分类》作为基础分类框架。该标准将国民经济分为4个层级:门类(20个)、大类(97个)、中类(473个)、小类(1380个)。
A.2 初筛方法
第一步:门类级粗筛
对20个门类使用一个简单的二元判断进行快速排除:该门类是否存在大量的、薪资合理的、面向知识型白领的岗位?
以知识型白领求职者为例,通常可排除以下门类:A农林牧渔、B采矿、D电力热力燃气水、H住宿餐饮、K房地产(当前周期)、N水利环境公共设施、O居民服务修理、R文化体育娱乐(政策风险)、S公共管理社会保障、T国际组织。
第二步:大类级细分与合并
对保留的门类,下钻到大类级别。GB/T 4754的分类基于“经济活动性质”,而就业市场的实际边界可能与之不同,因此需要进行调整:
● 排除:以体力劳动为主或数字化程度极低的大类
● 合并:就业市场特征相似、对求职者而言无需区分的大类
● 拆分:内部差异过大、不同子类别的就业吸引力可能截然不同的大类
调整原则:分类的目的是为了差异化评估。如果两个大类在ILEAI的所有维度上得分预期相近,则合并;如果一个大类内部在某个维度上得分预期差异显著,则拆分。
以C制造业(31个大类)为例的详细处理:
排除19个大类(理由:以体力劳动/重化工为主,知识型数字化岗位极少):13农副食品加工、14食品制造、15酒饮料茶、16烟草、17纺织、18纺织服装、19皮革制鞋、20木材加工、21家具、22造纸、23印刷、24文教用品、25石油煤炭加工、26化学原料制品、28化学纤维、29橡胶塑料、30非金属矿物、31黑色金属冶炼、32有色金属冶炼。
保留12个大类并重新归类为7个评估类别:
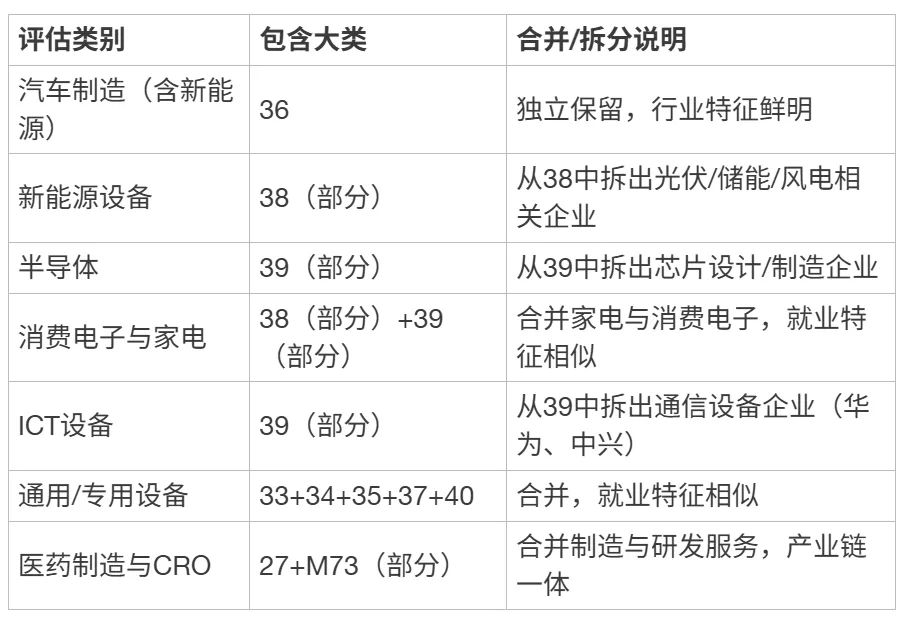
[ { “评估类别”: “汽车制造(含新能源)”, “包含大类”: “36”, “合并/拆分说明”: “独立保留,行业特征鲜明” },
{ “评估类别”: “新能源设备”, “包含大类”: “38(部分)”, “合并/拆分说明”: “从38中拆出光伏/储能/风电相关企业” },
{ “评估类别”: “半导体”, “包含大类”: “39(部分)”, “合并/拆分说明”: “从39中拆出芯片设计/制造企业” },
{ “评估类别”: “消费电子与家电”, “包含大类”: “38(部分)+39(部分)”, “合并/拆分说明”: “合并家电与消费电子,就业特征相似” },
{ “评估类别”: “ICT设备”, “包含大类”: “39(部分)”, “合并/拆分说明”: “从39中拆出通信设备企业(华为、中兴)” },
{ “评估类别”: “通用/专用设备”, “包含大类”: “33+34+35+37+40”, “合并/拆分说明”: “合并,就业特征相似” },
{ “评估类别”: “医药制造与CRO”, “包含大类”: “27+M73(部分)”, “合并/拆分说明”: “合并制造与研发服务,产业链一体” }]
排除:41其他制造、42废弃资源利用、43设备修理(非知识型主导)。
最终评估对象清单(22个行业)
1-7: 来自C制造业(如上表)
8: 电商与新零售(F52)
9: 物流与供应链科技(G58+59+60)
10: 互联网平台(I64)
11: 企业SaaS(I65-企业应用软件)
12: BI与数据分析平台(I65-数据分析工具)
13: 云计算(I65-云计算服务)
14: 网络安全(I65-信息安全)
15: AI应用层(I65-AI应用)
16: 银行科技(J66+69)
17: 证券与财富管理科技(J67)
18: 保险科技(J68)
19: 建筑数字化(E47-50的数字化应用层)
20: 管理咨询/数字化咨询(L72-管理咨询)
21: 职业教育/教育科技(P82-职业培训)
22: 医疗IT/医疗信息化(Q84-卫生信息化)
附录B:个性化权重设定示例
以下以一位特定求职者为例,说明如何根据个人偏好设定权重。
求职者画像:经Schein职业锚测评,主导锚为TF(技术/功能型能力,20/25)和LS(生活方式,20/25),第三锚为CH(纯粹挑战,16/25)。Holland代码为CIR(事务型-研究型-实际型)。
权重调整逻辑:
TF锚主导 → 需要行业能让其长期积累专业深度 → S(可持续性)上调:行业稳定才能安心深耕。
LS锚主导 → 工作体验是底线 → E(体验)上调。
CH锚中等 → 希望行业有增长空间 → S1在S维度内权重上调。
R(经济回报)→ 重要但非第一优先级 → 维持中等。
L(流动性)→ 有明确的“玩家多”偏好 → 维持中等。
调整后权重:
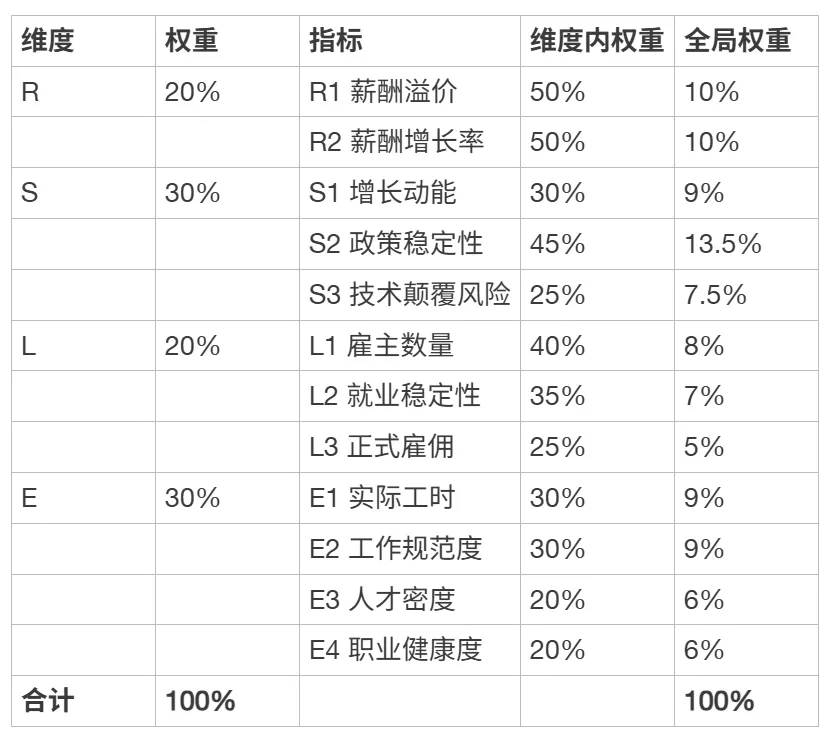
[ { “维度”: “R”, “权重”: “20%”, “指标”: “R1 薪酬溢价”, “维度内权重”: “50%”, “全局权重”: “10%” },
{ “维度”: “”, “权重”: “”, “指标”: “R2 薪酬增长率”, “维度内权重”: “50%”, “全局权重”: “10%” },
{ “维度”: “S”, “权重”: “30%”, “指标”: “S1 增长动能”, “维度内权重”: “30%”, “全局权重”: “9%” },
{ “维度”: “”, “权重”: “”, “指标”: “S2 政策稳定性”, “维度内权重”: “45%”, “全局权重”: “13.5%” },
{ “维度”: “”, “权重”: “”, “指标”: “S3 技术颠覆风险”, “维度内权重”: “25%”, “全局权重”: “7.5%” },
{ “维度”: “L”, “权重”: “20%”, “指标”: “L1 雇主数量”, “维度内权重”: “40%”, “全局权重”: “8%” },
{ “维度”: “”, “权重”: “”, “指标”: “L2 就业稳定性”, “维度内权重”: “35%”, “全局权重”: “7%” },
{ “维度”: “”, “权重”: “”, “指标”: “L3 正式雇佣”, “维度内权重”: “25%”, “全局权重”: “5%” },
{ “维度”: “E”, “权重”: “30%”, “指标”: “E1 实际工时”, “维度内权重”: “30%”, “全局权重”: “9%” },
{ “维度”: “”, “权重”: “”, “指标”: “E2 工作规范度”, “维度内权重”: “30%”, “全局权重”: “9%” },
{ “维度”: “”, “权重”: “”, “指标”: “E3 人才密度”, “维度内权重”: “20%”, “全局权重”: “6%” },
{ “维度”: “”, “权重”: “”, “指标”: “E4 职业健康度”, “维度内权重”: “20%”, “全局权重”: “6%” },
{ “维度”: “合计”, “权重”: “100%”, “指标”: “”, “维度内权重”: “”, “全局权重”: “100%” }]
附录C:指标数据来源汇总表
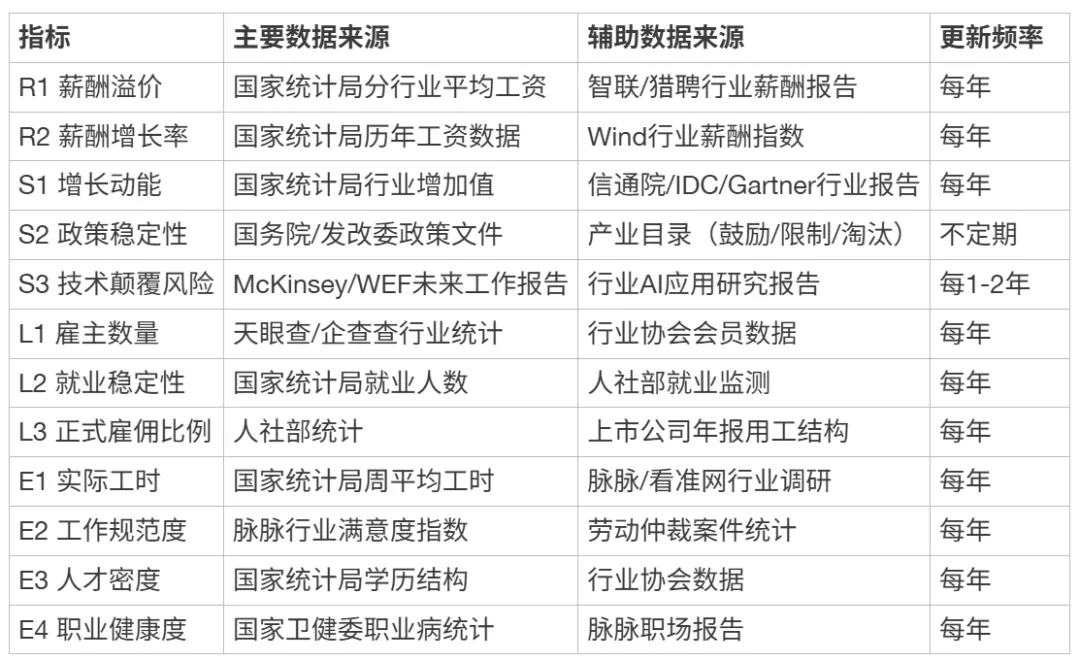
[ { “指标”: “R1 薪酬溢价”, “主要数据来源”: “国家统计局分行业平均工资”, “辅助数据来源”: “智联/猎聘行业薪酬报告”, “更新频率”: “每年” },
{ “指标”: “R2 薪酬增长率”, “主要数据来源”: “国家统计局历年工资数据”, “辅助数据来源”: “Wind行业薪酬指数”, “更新频率”: “每年” },
{ “指标”: “S1 增长动能”, “主要数据来源”: “国家统计局行业增加值”, “辅助数据来源”: “信通院/IDC/Gartner行业报告”, “更新频率”: “每年” },
{ “指标”: “S2 政策稳定性”, “主要数据来源”: “国务院/发改委政策文件”, “辅助数据来源”: “产业目录(鼓励/限制/淘汰)”, “更新频率”: “不定期” },
{ “指标”: “S3 技术颠覆风险”, “主要数据来源”: “McKinsey/WEF未来工作报告”, “辅助数据来源”: “行业AI应用研究报告”, “更新频率”: “每1-2年” },
{ “指标”: “L1 雇主数量”, “主要数据来源”: “天眼查/企查查行业统计”, “辅助数据来源”: “行业协会会员数据”, “更新频率”: “每年” },
{ “指标”: “L2 就业稳定性”, “主要数据来源”: “国家统计局就业人数”, “辅助数据来源”: “人社部就业监测”, “更新频率”: “每年” },
{ “指标”: “L3 正式雇佣比例”, “主要数据来源”: “人社部统计”, “辅助数据来源”: “上市公司年报用工结构”, “更新频率”: “每年” },
{ “指标”: “E1 实际工时”, “主要数据来源”: “国家统计局周平均工时”, “辅助数据来源”: “脉脉/看准网行业调研”, “更新频率”: “每年” },
{ “指标”: “E2 工作规范度”, “主要数据来源”: “脉脉行业满意度指数”, “辅助数据来源”: “劳动仲裁案件统计”, “更新频率”: “每年” },
{ “指标”: “E3 人才密度”, “主要数据来源”: “国家统计局学历结构”, “辅助数据来源”: “行业协会数据”, “更新频率”: “每年” },
{ “指标”: “E4 职业健康度”, “主要数据来源”: “国家卫健委职业病统计”, “辅助数据来源”: “脉脉职场报告”, “更新频率”: “每年” }]
参考文献
1. Aguilar, F.J. (1967). Scanning the Business Environment. Macmillan.
2. Holland, J.L. (1997). Making Vocational Choices: A Theory of Vocational Personalities and Work Environments (3rd ed.). Psychological Assessment Resources.
3. Markowitz, H. (1952). Portfolio Selection. The Journal of Finance, 7(1), 77-91.
4. McKinsey Global Institute. (2017). Jobs Lost, Jobs Gained: Workforce Transitions in a Time of Automation.
5. Minto, B. (1987). The Pyramid Principle: Logic in Writing and Thinking. Minto International.
6. Parsons, F. (1909). Choosing a Vocation. Houghton Mifflin.
7. Porter, M.E. (1980). Competitive Strategy: Techniques for Analyzing Industries and Competitors. Free Press.
8. Sampson, J.P., Reardon, R.C., Peterson, G.W., & Lenz, J.G. (2004). Career Counseling and Services: A Cognitive Information Processing Approach. Brooks/Cole.
9. Schein, E.H. (1990). Career Anchors: Discovering Your Real Values. Pfeiffer & Company.
10. Sharpe, W.F. (1964). Capital Asset Prices: A Theory of Market Equilibrium under Conditions of Risk. The Journal of Finance, 19(3), 425-442.
11. Super, D.E. (1980). A Life-Span, Life-Space Approach to Career Development. Journal of Vocational Behavior, 16(3), 282-298.
12. World Economic Forum. (2023). The Future of Jobs Report 2023.
13. 中华人民共和国国家标准 GB/T 4754—2017《国民经济行业分类》.
14. 国家统计局.《中国统计年鉴》(历年).
