 夜雨聆风
夜雨聆风





【OpenClaw】通过 Nanobot 源码学习架构—(8)Tools
【OpenClaw】通过 Nanobot 源码学习架构—(8)Tools
-
0x00 摘要 -
0x01 原理 -
1.1 问题 -
1.2 解决方案 -
1.3 执行流程 -
0x02 核心代码作用与特色总结 -
0x03 实现 -
3.1 整体逻辑关系图 -
3.2 TOOLS.md -
3.3 Tool 抽象基类 -
3.4 ExecTool Shell 执行工具 -
0xFF 参考
0x00 摘要
OpenClaw 应该有40万行代码,阅读理解起来难度过大,因此,本系列通过Nanobot来学习 OpenClaw 的特色。
Nanobot是由香港大学数据科学实验室(HKUDS)开源的超轻量级个人 AI 助手框架,定位为”Ultra-Lightweight OpenClaw“。非常适合学习Agent架构。
Tools(函数调用)机制的作用,是由应用侧提供一组可调用的函数,在模型推理过程中,由模型决定是否需要调用这些函数、以及调用哪一个、使用什么参数。模型只负责决策,应用程序负责真正执行函数并返回结果。
本文将解析 Nanobot 中工具体系的核心实现代码 —— 包含Tool抽象基类与ExecTool Shell 执行工具,前者定义了 AI Agent 工具的标准化接口与参数校验能力,是所有工具的基础骨架;后者基于该基类实现了安全可控的 Shell 命令执行能力,兼顾功能性与安全性。
这套代码是 Nanobot 实现 “工具调用” 核心能力的关键,仅通过轻量化设计就完成了 OpenAI Function Call 同等核心的工具标准化、参数校验、安全管控能力。
注:因为最近看的文章太多,所以如果有遗漏参考资料,还请读者指出,谢谢。
0x01 原理
1.1 问题
语言模型能推理代码,但碰不到真实世界 — 不能读文件、跑测试、看报错。没有循环,每次工具调用你都得手动把结果粘回去。你自己就是那个循环。
1.2 解决方案
我们引用 https://github.com/shareAI-lab/learn-claude-code 的图例如下。
可以使用一个退出条件控制整个流程。循环持续运行, 直到模型不再调用工具。
+--------+ +-------+ +---------+| User | ---> | LLM | ---> | Tool || prompt | | | | execute |+--------+ +---+---+ +----+----+^ || tool_result |+----------------+(loop until stop_reason != "tool_use")
我们可以进一步完善,使得一次分发就可以调用到正确的工具,加工具不需要改循环。
+--------+ +-------+ +------------------+| User | ---> | LLM | ---> | Tool Dispatch || prompt | | | | { |+--------+ +---+---+ | bash: run_bash |^ | read: run_read || | write: run_wr |+-----------+ edit: run_edit |tool_result | } |+------------------+The dispatch map is a dict: {tool_name: handler_function}.One lookup replaces any if/elif chain.
1.3 执行流程
Tools 调用不是简单的”一问一答”,而是”决策-执行-再推理”的协作闭环,是一个多轮交互的闭环过程。模型负责”动脑”,应用负责”动手”,两者通过结构化消息(JSON 指令与自然语言)完成多轮协同。
第一次模型调用
应用程序首先向大模型发起请求,请求体包含两个核心要素:
-
用户问题(User Query):当前需要解决的任务 -
工具清单(Available Tools):模型可调用的函数列表及其 Schema 定义
这相当于给模型一本”操作手册”——告诉它有哪些能力可用,但暂不执行。
接收模型的工具调用决策
模型接收到请求后,会进行意图判断与工具选择:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
模型在此阶段扮演”决策者”角色,它只生成调用指令,并不实际执行工具。
在应用端执行工具
应用程序接收到 JSON 指令后,进入工具执行层:
-
解析指令中的工具名称与参数 -
在应用端(或沙箱环境)运行对应工具 -
捕获工具输出结果(成功返回数据,或失败返回错误信息)
第二次模型调用
获取工具输出后,应用程序需要将结果回注上下文,再次发起模型调用。此时的消息序列(Messages)结构为:
[用户问题] → [模型工具调用指令] → [工具执行结果]这相当于告诉模型:”你刚才要求执行的操作已完成,这是结果,请基于这些信息继续推理。”
接收模型的最终响应
模型整合以下信息进行最终推理:
-
原始用户问题 -
工具输出结果 -
中间推理过程(Chain-of-Thought)
最终生成自然语言格式的回复,直接呈现给用户,完成整个交互闭环。
流程本质总结
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
我们从 https://github.com/shareAI-lab/claw0/ 的文档中也可以窥见端倪。
工具 = 数据 (schema) + 处理函数映射表. 模型选一个名字, 你查表执行.
-
TOOLS: JSON schema 字典列表, 告诉模型有哪些工具可用. -
TOOL_HANDLERS: dict[str, Callable], 将工具名映射到 Python 函数. -
process_tool_call(): 字典查找 + **kwargs分发. -
内层循环: 模型可能连续调用多个工具, 然后才生成文本. -
工具结果放在 user 消息中 (Anthropic API 的要求).
User Input|vmessages[] --> LLM API (tools=TOOLS)|stop_reason?/ \"end_turn" "tool_use"| |Print for each tool_use block:TOOL_HANDLERS[name](**input)|tool_result|messages[] <-- {role:"user", content:[tool_result]}|back to LLM --> may chain more toolsor "end_turn" --> Print
0x02 核心代码作用与特色总结
Nanobot Agent 工具系统的核心实现包括:
-
Tool抽象基类: -
定义了 Agent 工具的标准化接口规范(名称、描述、参数 Schema、执行逻辑),提供通用的参数校验能力(基于 JSON Schema)和 OpenAI 函数 Schema 转换能力,是所有自定义工具的 “模板”,保证了工具体系的一致性和可扩展性。 -
所有工具只需实现指定抽象方法即可接入 Agent,无需修改核心逻辑,同时基类内置通用能力(参数校验、Schema 转换),减少重复开发。 -
ExecTool工具类: -
基于 Tool基类实现的具体工具,为 Agent 提供安全可控的 Shell 命令执行能力,支持超时控制、工作目录限制、危险命令拦截、路径遍历防护、工作目录限制、允许列表等安全机制,既满足 Agent 与系统交互的核心需求,又规避了 Shell 执行的典型安全风险。
具体如下图所示。

0x03 实现
3.1 整体逻辑关系图
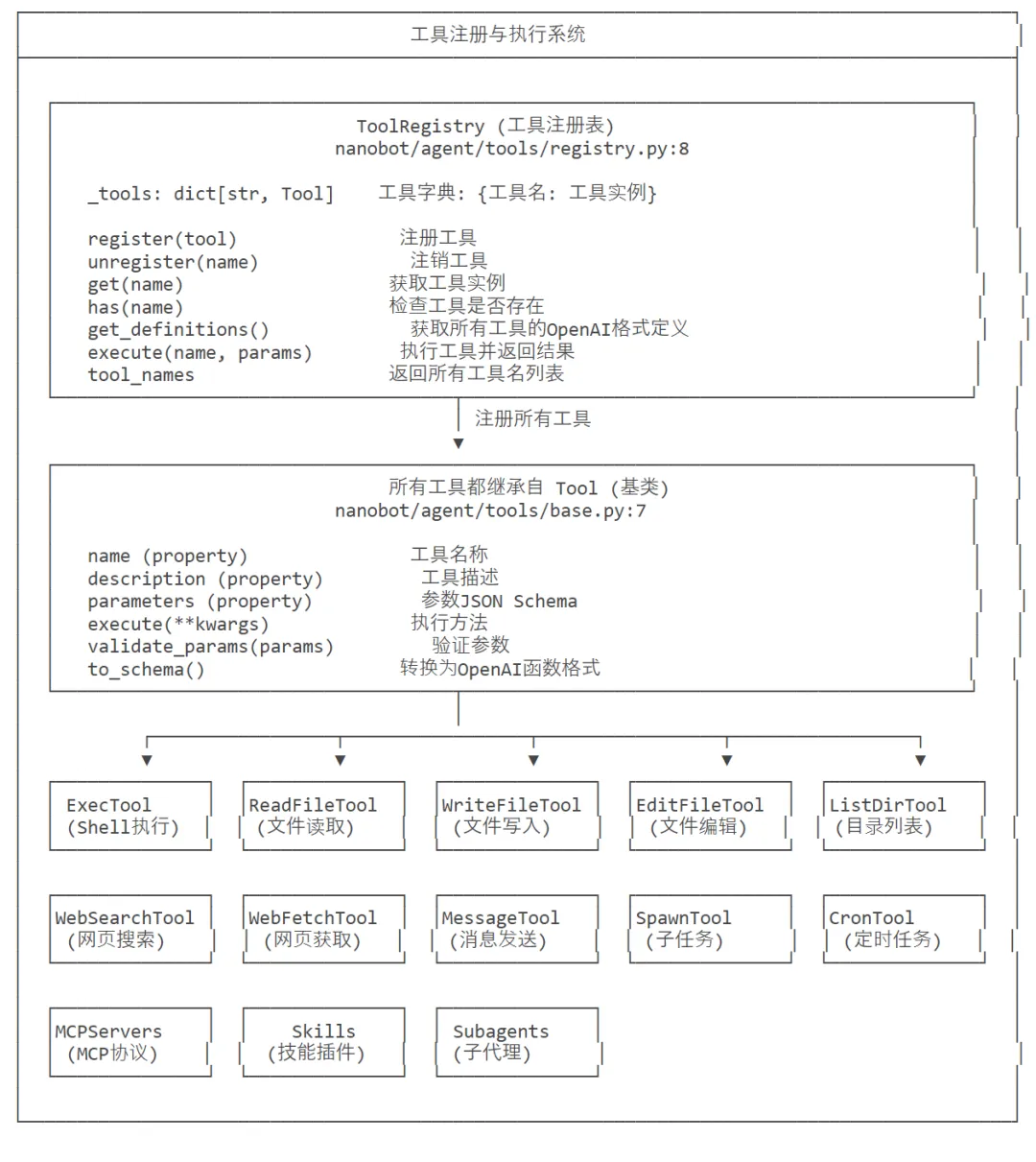
架构图如下:
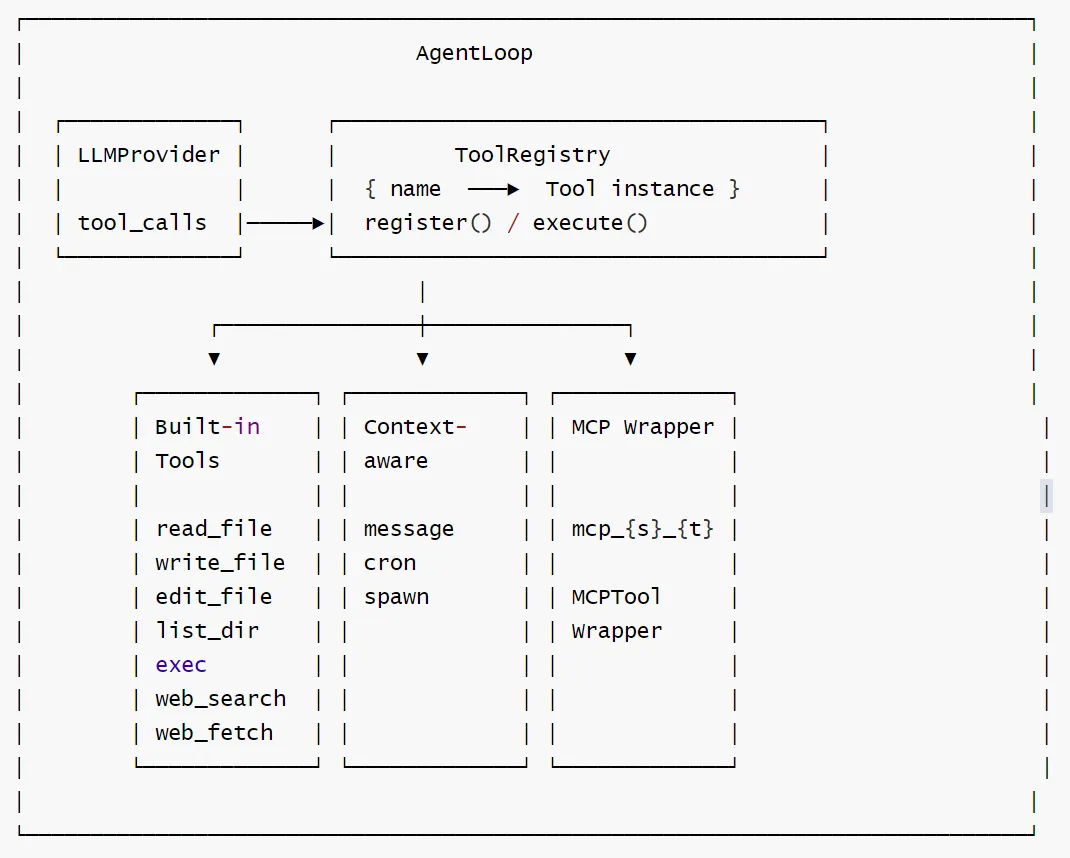
工具调用流程如下:

3.2 TOOLS.md
TOOLS.md 是本地工具提示。脚本存放在哪里,哪些命令可用。这样 Agent 就不需要去猜,而是确切知道。AGENTS.md 定义行为流程,TOOLS.md 定义能力边界。简单说,它是智能体的”工具箱说明书”,告诉智能体可以使用哪些工具、怎么用、什么时候用。
# Tool Usage NotesTool signatures are provided automatically via function calling.This file documents non-obvious constraints and usage patterns.## exec — Safety Limits- Commands have a configurable timeout (default 60s)- Dangerous commands are blocked (rm -rf, format, dd, shutdown, etc.)- Output is truncated at 10,000 characters- `restrictToWorkspace` config can limit file access to the workspace## cron — Scheduled Reminders- Please refer to cron skill for usage.
3.3 Tool 抽象基类
Tool抽象基类是工具体系的基础骨架。
3.3.1 Tool 基类核心流程
参数校验
validate_params() 是工具参数校验入口方法,校验传入参数是否符合当前工具的Schema规范。

Schema 转换
to_schema()是工具Schema转换方法,将当前工具转换为OpenAI函数调用的Schema格式,这样可以让LLM能识别工具的调用格式,兼容OpenAI Function Call生态。

3.3.2 代码
class Tool(ABC):"""Abstract base class for agent tools.Tools are capabilities that the agent can use to interact withthe environment, such as reading files, executing commands, etc."""# 定义JSON Schema类型到Python原生类型的映射字典,用于参数类型校验# 核心作用:将Schema中定义的类型(如"string")转换为Python可识别的类型(str),方便后续类型检查_TYPE_MAP = {"string": str, # Schema字符串类型对应Python str"integer": int, # Schema整数类型对应Python int"number": (int, float), # Schema数字类型对应Python int/float(兼容整数和浮点数)"boolean": bool, # Schema布尔类型对应Python bool"array": list, # Schema数组类型对应Python list"object": dict, # Schema对象类型对应Python dict}# 定义抽象属性:工具名称(必须由子类实现)# 作用:指定工具在函数调用中的唯一标识(如"exec"),LLM通过该名称调用对应工具@property@abstractmethoddef name(self) -> str:"""Tool name used in function calls."""pass# 定义抽象属性:工具描述(必须由子类实现)# 作用:向LLM说明工具的功能,帮助LLM判断何时调用该工具,描述需清晰易懂@property@abstractmethoddef description(self) -> str:"""Description of what the tool does."""pass# 定义抽象属性:工具参数Schema(必须由子类实现)# 作用:定义工具入参的JSON Schema规范,用于参数校验和向LLM声明参数格式@property@abstractmethoddef parameters(self) -> dict[str, Any]:"""JSON Schema for tool parameters."""pass# 定义抽象方法:工具执行逻辑(必须由子类实现)# 作用:实现工具的核心功能,接收参数并返回执行结果,async标识异步执行(适配Agent异步架构)@abstractmethodasync def execute(self, **kwargs: Any) -> str:"""Execute the tool with given parameters.Args:**kwargs: Tool-specific parameters.Returns:String result of the tool execution."""pass# 工具参数校验入口方法:校验传入参数是否符合当前工具的Schema规范# 返回值:校验错误信息列表(空列表表示校验通过)def validate_params(self, params: dict[str, Any]) -> list[str]:"""Validate tool parameters against JSON schema. Returns error list (empty if valid)."""# 获取当前工具的参数Schema,若未定义则默认为空字典schema = self.parameters or {}# 校验Schema的顶层类型必须是"object"(因为参数本质是键值对),否则抛出异常if schema.get("type", "object") != "object":raise ValueError(f"Schema must be object type, got {schema.get('type')!r}")# 调用内部递归校验方法,传入待校验参数、完整Schema、空路径(用于定位错误参数)return self._validate(params, {**schema, "type": "object"}, "")# 内部递归校验方法:核心参数校验逻辑,支持嵌套类型(如对象、数组)的递归校验# val:待校验的参数值;schema:当前层级的Schema规范;path:参数的路径(用于精准定位错误,如"command.working_dir")def _validate(self, val: Any, schema: dict[str, Any], path: str) -> list[str]:# 获取当前Schema定义的类型和参数路径标签(用于错误提示)t, label = schema.get("type"), path or "parameter"# 第一步:基础类型校验——若Schema类型在映射表中,检查参数值是否为对应Python类型if t in self._TYPE_MAP and not isinstance(val, self._TYPE_MAP[t]):return [f"{label} should be {t}"]# 初始化错误列表,用于收集所有校验错误errors = []# 第二步:枚举值校验——若Schema定义了enum,检查参数值是否在枚举列表中if "enum" in schema and val not in schema["enum"]:errors.append(f"{label} must be one of {schema['enum']}")# 第三步:数值类型(整数/数字)范围校验if t in ("integer", "number"):# 最小值校验:若定义了minimum,检查参数值是否大于等于最小值if "minimum" in schema and val < schema["minimum"]:errors.append(f"{label} must be >= {schema['minimum']}")# 最大值校验:若定义了maximum,检查参数值是否小于等于最大值if "maximum" in schema and val > schema["maximum"]:errors.append(f"{label} must be <= {schema['maximum']}")# 第四步:字符串类型长度校验if t == "string":# 最小长度校验:若定义了minLength,检查字符串长度是否达标if "minLength" in schema and len(val) < schema["minLength"]:errors.append(f"{label} must be at least {schema['minLength']} chars")# 最大长度校验:若定义了maxLength,检查字符串长度是否超限if "maxLength" in schema and len(val) > schema["maxLength"]:errors.append(f"{label} must be at most {schema['maxLength']} chars")# 第五步:对象类型校验(支持嵌套对象)if t == "object":# 获取对象的属性定义和必填属性列表props = schema.get("properties", {})# 必填属性校验:检查所有必填属性是否存在于参数中for k in schema.get("required", []):if k not in val:errors.append(f"missing required {path + '.' + k if path else k}")# 递归校验对象的每个属性值:若属性在Schema中定义,则递归校验其值for k, v in val.items():if k in props:errors.extend(self._validate(v, props[k], path + '.' + k if path else k))# 第六步:数组类型校验(支持数组元素的递归校验)if t == "array" and "items" in schema:# 遍历数组每个元素,递归校验元素是否符合items定义的Schemafor i, item in enumerate(val):errors.extend(self._validate(item, schema["items"], f"{path}[{i}]" if path else f"[{i}]"))# 返回所有校验错误return errors# 工具Schema转换方法:将当前工具转换为OpenAI函数调用的Schema格式# 作用:让LLM能识别工具的调用格式,兼容OpenAI Function Call生态def to_schema(self) -> dict[str, Any]:"""Convert tool to OpenAI function schema format."""return {"type": "function","function": {"name": self.name, # 工具名称(对应OpenAI函数名)"description": self.description, # 工具描述(帮助LLM理解工具用途)"parameters": self.parameters, # 工具参数Schema(声明入参格式)}}
3.4 ExecTool Shell 执行工具
ExecTool是基于 Tool 基类的具体实现。
3.4.1 Agent 如何运行 grep 命令
LLM 通过结合系统提示中的工具功能描述(执行 shell 命令)、用户请求的意图分析(搜索文件内容)以及上下文信息,来决定使用 exec 工具来执行 grep 命令:
-
Agent 接收用户请求 “search for ‘keyword’ in history” -
LLM 分析用户请求,识别出需要执行 shell 命令的意图 -
当检测到类似 “search for”, “find in history”, “look up” 等请求时,并且上下文中提到 memory/HISTORY.md 文件时,LLM 识别需要执行 grep 命令(根据常识) -
LLM 构造适当的参数:grep -i “keyword” memory/HISTORY.md -
LLM 会选择 ExecTool 作为执行工具(根据工具描述和功能)
决策流程如下:
用户请求─ 包含搜索/查找意图?─ 是─ 涉及文件操作?─ 是 → 使用 exec 工具执行 grep─ 否 → 继续判断─ 否 → 判断其他工具需求
3.4.2 ExecTool 核心流程
Shell命令执行流程如下:

3.4.3 代码
"""Shell execution tool."""class ExecTool(Tool):"""Tool to execute shell commands."""# 工具初始化方法:配置Shell执行的安全参数和运行参数# 参数说明:# - timeout:命令执行超时时间(默认60秒)# - working_dir:默认工作目录(若未指定则使用当前目录)# - deny_patterns:危险命令正则黑名单(默认内置常见危险命令)# - allow_patterns:命令允许列表(白名单,为空则不启用)# - restrict_to_workspace:是否限制命令仅能访问指定工作目录(防止越权访问)# - path_append:追加到环境变量PATH的路径(用于指定命令查找路径)def __init__(self,timeout: int = 60,working_dir: str | None = None,deny_patterns: list[str] | None = None,allow_patterns: list[str] | None = None,restrict_to_workspace: bool = False,path_append: str = "",):self.timeout = timeout # 初始化命令超时时间self.working_dir = working_dir # 初始化默认工作目录# 初始化危险命令黑名单:默认拦截删除、格式化、系统关机、fork炸弹等破坏性命令self.deny_patterns = deny_patterns or [r"\brm\s+-[rf]{1,2}\b", # 匹配rm -r/rm -rf/rm -fr(递归删除文件)r"\bdel\s+/[fq]\b", # 匹配del /f/del /q(强制/静默删除文件,Windows)r"\brmdir\s+/s\b", # 匹配rmdir /s(删除目录及子目录,Windows)r"(?:^|[;&|]\s*)format\b", # 匹配format命令(格式化磁盘,仅匹配独立命令)r"\b(mkfs|diskpart)\b", # 匹配磁盘操作命令(mkfs格式化文件系统、diskpart磁盘分区)r"\bdd\s+if=", # 匹配dd命令(磁盘写入,if指定输入文件)r">\s*/dev/sd", # 匹配写入磁盘设备(如> /dev/sda,破坏性操作)r"\b(shutdown|reboot|poweroff)\b", # 匹配系统关机/重启/断电命令r":\(\)\s*\{.*\};\s*:", # 匹配fork炸弹(无限创建进程,导致系统崩溃)]self.allow_patterns = allow_patterns or [] # 初始化命令允许列表(默认空,不启用)self.restrict_to_workspace = restrict_to_workspace # 初始化工作目录限制开关self.path_append = path_append # 初始化PATH环境变量追加路径# 实现抽象属性:工具名称(固定为"exec",LLM通过该名称调用)@propertydef name(self) -> str:return "exec"# 实现抽象属性:工具描述(说明工具功能并提醒谨慎使用)@propertydef description(self) -> str:return "Execute a shell command and return its output. Use with caution."# 实现抽象属性:工具参数Schema(定义exec工具的入参规范)@propertydef parameters(self) -> dict[str, Any]:return {"type": "object", # 顶层类型为对象(键值对)"properties": {# 命令参数:必填,字符串类型,描述要执行的Shell命令"command": {"type": "string","description": "The shell command to execute"},# 工作目录参数:可选,字符串类型,描述命令执行的工作目录"working_dir": {"type": "string","description": "Optional working directory for the command"}},"required": ["command"] # 声明command为必填参数}# 实现抽象方法:工具核心执行逻辑(异步执行Shell命令)# 参数:command(要执行的命令)、working_dir(临时工作目录)、其他扩展参数async def execute(self, command: str, working_dir: str | None = None, **kwargs: Any) -> str:# 确定命令执行的工作目录:优先使用传入的working_dir,其次是工具默认的working_dir,最后是当前目录cwd = working_dir or self.working_dir or os.getcwd()# 执行命令安全校验:检查命令是否包含危险内容、是否越权访问路径等guard_error = self._guard_command(command, cwd)# 若安全校验失败,直接返回错误信息(不执行命令)if guard_error:return guard_error# 复制当前环境变量(避免修改全局环境变量)env = os.environ.copy()# 若配置了PATH追加路径,将其添加到环境变量PATH中if self.path_append:env["PATH"] = env.get("PATH", "") + os.pathsep + self.path_appendtry:# 异步创建Shell子进程执行命令:# - stdout/stderr重定向到管道(用于捕获输出)# - cwd指定工作目录# - env指定环境变量process = await asyncio.create_subprocess_shell(command,stdout=asyncio.subprocess.PIPE,stderr=asyncio.subprocess.PIPE,cwd=cwd,env=env,)try:# 等待命令执行完成并捕获输出,设置超时时间(防止命令挂起)stdout, stderr = await asyncio.wait_for(process.communicate(),timeout=self.timeout)except asyncio.TimeoutError:# 命令超时:终止进程process.kill()# 等待进程完全终止(释放文件描述符等资源)try:await asyncio.wait_for(process.wait(), timeout=5.0)except asyncio.TimeoutError:pass# 返回超时错误信息return f"Error: Command timed out after {self.timeout} seconds"# 初始化输出列表,用于拼接标准输出、标准错误、退出码output_parts = []# 若有标准输出,解码为字符串(utf-8,无法解码的字符替换)并添加到输出列表if stdout:output_parts.append(stdout.decode("utf-8", errors="replace"))# 若有标准错误,解码后添加到输出列表(标注STDERR)if stderr:stderr_text = stderr.decode("utf-8", errors="replace")if stderr_text.strip(): # 仅当标准错误非空时添加output_parts.append(f"STDERR:\n{stderr_text}")# 若命令退出码非0(执行失败),添加退出码信息到输出列表if process.returncode != 0:output_parts.append(f"\nExit code: {process.returncode}")# 拼接所有输出部分,若无输出则返回"(no output)"result = "\n".join(output_parts) if output_parts else "(no output)"# 截断超长输出:限制最大长度为10000字符,避免返回结果过大max_len = 10000if len(result) > max_len:result = result[:max_len] + f"\n... (truncated, {len(result) - max_len} more chars)"# 返回命令执行结果return resultexcept Exception as e:# 捕获其他执行异常(如进程创建失败),返回错误信息return f"Error executing command: {str(e)}"# 命令安全防护方法:校验命令是否安全,返回错误信息(None表示安全)# 核心作用:拦截危险命令、越权路径访问,是ExecTool的核心安全机制def _guard_command(self, command: str, cwd: str) -> str | None:"""Best-effort safety guard for potentially destructive commands."""# 去除命令首尾空格,便于正则匹配cmd = command.strip()# 转换为小写(正则匹配不区分大小写)lower = cmd.lower()# 第一步:黑名单校验——检查命令是否匹配危险模式for pattern in self.deny_patterns:if re.search(pattern, lower):return "Error: Command blocked by safety guard (dangerous pattern detected)"# 第二步:白名单校验——若配置了允许列表,命令必须匹配其中一个模式if self.allow_patterns:if not any(re.search(p, lower) for p in self.allow_patterns):return "Error: Command blocked by safety guard (not in allowlist)"# 第三步:工作目录限制校验——若开启限制,拦截路径遍历和越权访问if self.restrict_to_workspace:# 拦截路径遍历字符(../ 或 ..\),防止访问上级目录if "..\\" in cmd or "../" in cmd:return "Error: Command blocked by safety guard (path traversal detected)"# 解析工作目录的绝对路径(用于后续路径校验)cwd_path = Path(cwd).resolve()# 提取命令中的Windows绝对路径(如C:\Users\test)win_paths = re.findall(r"[A-Za-z]:\\[^\\\"']+", cmd)# 提取命令中的POSIX绝对路径(如/usr/bin),仅匹配独立的绝对路径(避免误匹配)posix_paths = re.findall(r"(?:^|[\s|>])(/[^\s\"'>]+)", cmd)# 遍历所有提取的绝对路径,检查是否超出工作目录范围for raw in win_paths + posix_paths:try:# 解析路径为绝对路径p = Path(raw.strip()).resolve()except Exception:# 路径解析失败(如非法路径),跳过校验continue# 若路径是绝对路径且不在工作目录及其子目录中,拦截命令if p.is_absolute() and cwd_path not in p.parents and p != cwd_path:return "Error: Command blocked by safety guard (path outside working dir)"# 所有校验通过,返回None(命令安全)return None
3.5 沙箱
3.5.1 两层实现
nanobot的沙箱实现分两层:
第一层:命令守卫(软防护)。ExecTool._guard_command()在执行前用正则表达式检查命令:
-
deny_patterns:默认屏蔽rm-rf、dd、format、shutdown、forkbomb等危险模式 -
allow_patterns:可选白名单,只有匹配的命令才放行 -
restrict_to_workspace:若开启,绝对路径必须在workspace目录内(防止路径逃逸) -
内网URL检测:调用security.network.contains_internal_url() 屏蔽访问内网地址 -
保护内部文件:屏蔽直接写入history.jsonl/.dream_cursor(防止LLM篡改记忆)
第二层:bubblewrap(硬隔离,Linux 容器)。sandbox.py的 _bwrap()把命令包裹在bwrap 沙箱里:
-
只读挂载/usr、/bin、系统库 -
用tmpfs隐藏workspace 的父目录(config.json 所在目录) -
workspace读写挂载,media目录只读挂载 -
新进程组(–new-session)、进程死亡传播(–die-with-parent)
环境变量隔离_build_env()只传递最小环境(HOME/LANG/TERM),屏蔽所有API key等敏感变量(allowed_env_keys 白名单除外)。
3.5.2 流程
我们加入 沙箱之后,重新走以下完整的运行流程,从接受到用户消息开始,一直到最后。

3.5.3 代码
bwrap(bubblewrap)是Linux的非特权容器工具,nanobot的_bwrap()函数用它构造如下命令:
bubblewrap的实现如下:
def_bwrap(command: str, workspace: str, cwd: str) -> str:"""将命令包裹在 bubblewrap 沙箱中执行 (需要容器内存在 bwrap)。 只有 workspace 目录以读写方式挂载;其父目录(存放 config.json 的位置) 被一个全新的 tmpfs 覆盖隐藏。media 目录以只读方式挂载,供 exec 命令 读取用户上传的附件。 安全属性: - config.json (含 API key) 在沙箱内不可见 - workspace 的父目录整体被替换为空 tmpfs。 - 文件系统写操作被限制在 workspace 内;其他路径均为只读或不可见。 - 进程运行在新会话 (--new-session) 中,外部 TTY 的信号无法传入; 父进程退出时沙箱进程自动被回收 (--die-with-parent),防止孤儿进程。 """ ws = Path(workspace).resolve() media = get_media_dir().resolve()# 确保 cwd 始终在沙箱内。如果传入的路径已逃出 workspace 根目录# (例如传了绝对路径),则回退到 workspace 根,防止 bwrap 收到# 沙箱外的 --chdir 参数。try: sandbox_cwd = str(ws / Path(cwd).resolve().relative_to(ws))except ValueError: sandbox_cwd = str(ws)# 必须存在于宿主机的路径 (bind 挂载失败会报错)。 required = ["/usr"]# 可选路径;--ro-bind-try 在路径不存在时静默跳过。 optional = ["/bin", "/lib", "/lib64", "/etc/alternatives","/etc/ssl/certs", "/etc/resolv.conf", "/etc/ld.so.cache"] args = ["bwrap","--new-session", # 脱离调用方的 TTY/会话;防止 SIGHUP、SIGINT# 等信号从宿主机泄漏到沙箱进程。"--die-with-parent", # nanobot 退出时自动回收沙箱进程, 防止孤儿进程残留。 ]# 挂载运行 shell 和常用 CLI 工具所需的最小只读系统目录树。for p in required: args += ["--ro-bind", p, p]for p in optional: args += ["--ro-bind-try", p, p] # 路径不存在时静默跳过。 args += ["--proc", "/proc", # 许多工具 (ps、top、/proc/self/...) 依赖 /proc。"--dev", "/dev", # /dev/null、/dev/urandom 等设备节点所必需。"--tmpfs", "/tmp", # 隔离的 /tmp, 与宿主机不共享。# 将 workspace 的*父目录*替换为空 tmpfs。# 这会隐藏 config.json (含 API key) 以及同级目录# (如 ~/.nanobot/sessions、~/.nanobot/media 的上层),# 使沙箱内进程无法访问这些文件。"--tmpfs", str(ws.parent),# 在刚刚创建的空 tmpfs 下重建 workspace 挂载点,# 再将真实的 workspace 目录以读写方式绑定挂载进去。# LLM 可以在 workspace 内自由读写文件。"--dir", str(ws),"--bind", str(ws), str(ws),# 将 media 上传目录以只读方式暴露给沙箱,# 使 agent 可以读取用户附件, 但无法修改或删除。"--ro-bind-try", str(media), str(media),"--chdir", sandbox_cwd, # 在正确的工作目录中启动命令。"--", "sh", "-c", command, ]return shlex.join(args) 3.6 并行 vs 串行
nanoboot 中,工具默认是串行 (sequential)执行。并行是可选特性, 且受工具属性限制。
即使开启, 也不是”所有工具一起跑”,而是按**批次(batch)**执行,批次内并行,批次间串行。
3.6.1 并行执行规则
并行执行规则 (_partition_tool_batches)如下:

3.6.2 并行属性
各个工具的并行属性如下:
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
继续打广告^_^
0xFF 参考
万字】带你实现一个Agent(上),从Tools、MCP到Skills
3500 行代码打造轻量级AI Agent:Nanobot 架构深度解析
OpenClaw真完整解说:架构与智能体内核
https://github.com/shareAI-lab/learn-claude-code
OpenClaw架构-Agent Runtime 运行时深度拆解
OpenClaw 架构详解 · 第一部分:控制平面、会话管理与事件循环
https://github.com/shareAI-lab/claw0/