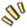夜雨聆风
夜雨聆风





让 AI 在后台 24 小时替你干活:8 个值得装机的开源 daemon
点击上方 前端Q,关注公众号
回复加群,加入前端Q技术交流群
上一篇聊 Codex 更新的时候,我说了一句话:”AI 正在从工具变成同事。”
有个读者留言问了一个很扎心的问题:
“同事是 24 小时在线的。Claude Code 关掉终端就没了,这也叫同事?”
我当时一愣,然后去把 GitHub 上 star 数最高的一批 AI 项目翻了一遍,发现一件很有意思的事:
真正火起来的 AI 开源项目,几乎全都是 daemon(守护进程)。
Ollama、llama.cpp、vLLM、n8n、AutoGPT、Open WebUI……这些你大概率听过的名字,本质都是”挂在那一直跑”的服务,不是”开一次用完就关”的工具。
这篇我把 8 个我觉得最值得装机的 AI daemon 盘一遍,所有 star 数都是我今天去 GitHub 现查的,保真。
先搞清楚:为什么 AI daemon 化是大势
AI daemon 的定义很简单:一个常驻后台、提供 API 或长连接、不需要你守在终端的 AI 服务。
为什么最近这个形态越来越火?三个原因。
第一,模型在本地跑起来了。 以前调 OpenAI,发个请求等个响应就完事。现在本地跑 Llama、Qwen、Gemma,你得有个东西管模型加载、显存分配、并发推理——这天然就是 daemon 的活。
第二,Agent 开始需要长期存活。 Codex 的 Automations 能跨天继续干活,Claude Code 社区在求 daemon 模式,OpenAI 刚出的 Superpowers 插件强调”subagent 能后台跑”。一次性对话不够用了,AI 需要”挂机干活”的能力。
第三,工作流越来越像流水线。 一个完整的 AI 任务现在经常长这样:用户输入 → 检索 → 推理 → 工具调用 → 审核 → 输出。这条链路上每一段都是一个可以独立部署的 daemon。
按职能,现在的 AI daemon 基本分三层:
下面一个一个说。
推理层:让模型跑起来的那几个家伙
▎1. Ollama(169.7k stars)
如果你只想装一个 AI daemon,装它就对了。
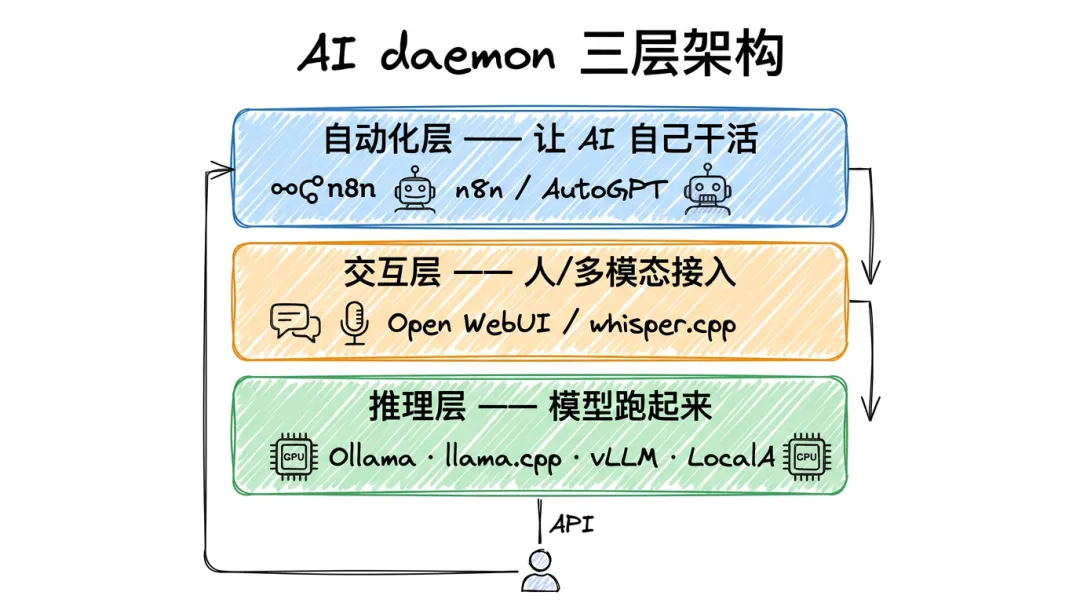
一行命令安装,ollama run llama3.2 就能把模型跑起来,默认暴露 http://localhost:11434 这个 API,OpenAI 格式兼容。
定位:最易用的本地 LLM daemon,主打”开箱即用”。
核心优势:
ollama pull、ollama list)适合场景:个人开发者本地跑模型、小团队内网部署、Prototype 快速验证。
小坑:性能没做到极致,高并发场景还是得上 vLLM。
▎2. llama.cpp / llama-server(105.8k stars)
这是 Ollama 底层用的推理引擎,但它自己也提供 llama-server 这个 daemon。
定位:纯 C++ 推理引擎,强调轻量和极致性能。
核心优势:
适合场景:部署到资源受限的机器(树莓派、低配 VPS)、嵌入到其他程序里、追求极致启动速度。
小坑:模型管理、权限、多租户这些事都得自己搞,不像 Ollama 开箱即用。
▎3. vLLM(77.8k stars)
如果你要做生产环境的推理服务,这是默认答案。
定位:高吞吐、内存高效的 LLM 推理 daemon,主打”大规模生产服务”。
核心优势:
适合场景:对外提供推理服务、高并发 API、做付费 AI 产品的推理后端。
小坑:吃显存多,部署复杂,不适合本地玩票。
▎4. LocalAI(45.7k stars)
定位:OpenAI API 的 drop-in 替代,一个 daemon 接管文本、图像、音频、向量全部能力。
核心优势:
base_url 就能切过去适合场景:已经写好了基于 OpenAI 的代码,想迁到本地不想改业务逻辑。
小坑:生态没 Ollama 大,配置项比 Ollama 多一些。
交互层:怎么把人和多模态接进来
▎5. Open WebUI(133.5k stars)
一个自托管的 ChatGPT 风格界面,装完 Ollama 接下来就装它。
定位:本地 AI 对话 UI daemon。
核心优势:
适合场景:家里/公司内部搭一个自己的 ChatGPT、给不懂命令行的同事/家人用本地模型。
小坑:前端功能多了之后略重,低配机器首屏稍慢。
▎6. whisper.cpp(48.9k stars)
OpenAI Whisper 的 C++ 移植版本,带 whisper-server。
定位:本地语音识别 daemon。
核心优势:
适合场景:本地语音笔记、直播字幕、播客转录、隐私敏感的语音数据处理。
小坑:中文转录效果比英文略弱,长音频要配 VAD 切片。
自动化层:让 AI 自己把事串起来
▎7. n8n(185.2k stars)
虽然 n8n 本来是个工作流平台,但它现在的 AI 节点和集成能力已经让它变成事实上的 AI 自动化 daemon。
定位:带 AI 能力的工作流自动化 daemon。
核心优势:
适合场景:把 AI 和现有业务系统粘起来(比如”收到新邮件就让 AI 分类并写进 Notion”)。
小坑:可视化流程复杂到一定程度,不如直接写代码舒服。
▎8. AutoGPT(183.7k stars)
自主 Agent daemon 的鼻祖,现在已经演化成了一个比较完整的 Agent 平台。
定位:自主执行任务的 AI Agent daemon。
核心优势:
适合场景:需要 AI 长期、自动地重复执行某类任务(比如每天爬一批资讯、做竞品监控、自动回复邮件)。
小坑:真正跑”完全自主”的 Agent 还是容易跑飞,生产环境建议配合前面系列里讲过的 Guardrail。
六种场景怎么选
光看盘点容易晕,给几个我实际在用的组合方案:
场景 1:我只想在本地跑个模型玩
一个就够。ollama run qwen2.5 完事。
场景 2:我想在家搭一个自己的 ChatGPT
Ollama 跑模型,Open WebUI 提供 UI,Docker Compose 一把梭。
场景 3:我要做一个对外付费的 AI 产品后端
vLLM 抗并发,上面套一层自己的业务逻辑和计费。
场景 4:我要把现有 SaaS 系统加上 AI 能力
用 n8n 把”数据流 + AI 调用 + 触发下游动作”串起来,不用写一行后端代码。
场景 5:我要让 AI 自己定时/持续干活
重点是”任务能被调度”这件事,AutoGPT 和 n8n 各有优势。
场景 6:我要处理语音/多模态
三层拼成一个完整的语音 → 文本 → 智能处理流水线。
聊聊我的判断
把这 8 个项目盘完,我最大的感受是:AI 正在从”开一次用一次”的工具形态,变成”挂在那一直跑”的服务形态。
这个变化比”模型变强”对开发者的影响更大。
因为一旦 AI 变成 daemon,就意味着:
Codex 搞 Automations、Claude Code 社区求 daemon 模式、OpenAI Superpowers 强调”subagent 能后台跑”——全都是在走这条路。
对前端开发者来说,最大的启发是:你熟悉的那套”前后端分离”思维,完全可以平移到 AI 上。
前端还是前端,但后端那个”业务服务”现在多了一个兄弟叫”AI 服务”。你不需要学会训模型,你需要学会怎么把一个 AI daemon 接入你的系统、怎么给它限流、怎么看它的日志、怎么做降级。
这才是未来两年前端工程师真正要补的课。
如果你从这 8 个里只让我推荐一个装机,我会说:先装 Ollama。把本地模型跑起来之后,你会自然而然地想要 Open WebUI,想要 whisper.cpp,想要 n8n——整个技能树就开始自己长出来了。
参考
(本文所有 star 数据截至 2026 年 4 月 16 日,直接来自 GitHub 仓库页面)

往期推荐