 夜雨聆风
夜雨聆风





GPT-5.5来了:AI不再只是回答问题,而是在替你把事情做完
这次发布,我觉得最值得关注的,不是“模型又变聪明了”。
因为从 GPT-4 到 GPT-5,再到现在的 GPT-5.5,模型能力提升已经不算新闻了。真正值得企业老板、产品负责人、技术负责人关注的是另一件事:
AI 正在从“给你答案”,变成“替你完成一段工作”。
这才是 GPT-5.5 这次发布里最核心的变化。
OpenAI 对 GPT-5.5 的定位是:一个面向真实工作的全新智能模型。它不仅能写代码、调试代码、在线研究、分析数据、生成文档和表格,还能操作软件,在多个工具之间切换,自己规划步骤,检查结果,并在任务没有完全明确的时候继续推进。OpenAI 也明确提到,GPT-5.5 正在向 ChatGPT 和 Codex 的 Plus、Pro、Business、Enterprise 用户推出,GPT-5.5 Pro 面向 Pro、Business、Enterprise 用户开放,API 也会很快上线。
这句话翻译成企业语言,其实就是:
过去你要一步步指挥 AI。现在你可以把一个混乱的任务交给 AI,让它自己拆解、执行、纠错、交付。
这就是差别。
一、GPT-5.5最重要的变化:更像一个“能扛事的人”
过去我们用 AI,很多时候像是在用一个很聪明的实习生。
你得告诉它背景。你得提醒它目标。你得一步步拆任务。你还得经常检查它有没有跑偏。
而 GPT-5.5 想解决的问题,是让 AI 更接近一个能独立推进事情的协作者。
OpenAI 在原文里反复强调几个方向:
agentic coding、computer use、knowledge work、scientific research。
翻译成人话,就是四类能力:
能做更复杂的软件工程任务。能操作电脑和软件界面。能处理真实办公场景里的知识工作。能辅助科学研究,不只是回答问题,而是参与分析、建模和验证。
这其实不是单点能力提升,而是工作范式变化。
以前 AI 主要帮你“生成一段内容”。现在 AI 开始帮你“完成一个流程”。
这也是为什么我一直说,2026 年企业用 AI,不能再停留在提示词阶段。
提示词只是入口。真正决定结果的,是你有没有把 AI 放进一个清晰的工作框架里:目标、资料、工具、约束、反馈、验收。
这也是我最近一直讲的“约束工程”,或者说 Harness Engineering。
不是让 AI 更会聊天,而是让 AI 在一个可控的系统里持续工作。
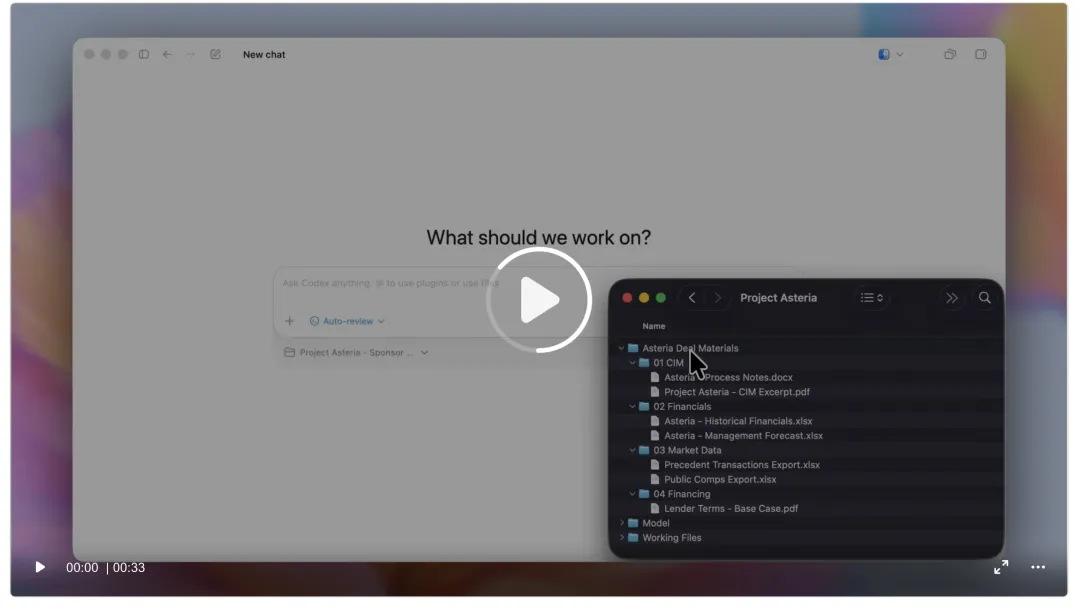
图注建议:GPT-5.5 的重点不是“更会聊天”,而是更能在真实任务中持续推进工作。图源:OpenAI 官方博客。
二、写代码这件事,正在被重新定义
GPT-5.5 最明显的提升之一,是编码能力。
根据 OpenAI 官方数据,GPT-5.5 在 Terminal-Bench 2.0 上达到 82.7%,在 SWE-Bench Pro 上达到 58.6%。这些测试不是简单问答,而是要求模型处理真实命令行流程、真实 GitHub 问题、复杂调试和长链路代码任务。OpenAI 还提到,在多个编码评测中,GPT-5.5 相比 GPT-5.4 表现更好,并且完成同类 Codex 任务时使用的 token 更少。
这意味着什么?
不是“AI 更会写一个函数”了。
而是它开始更擅长理解一个系统:
哪里坏了?为什么坏?该改哪个文件?改完之后会影响哪里?是否需要补测试?有没有潜在回归风险?
这才是真实软件工程里的关键。
一个工程师最值钱的地方,往往不是写代码,而是理解系统、定位问题、判断改动边界。
GPT-5.5 的进步,就在于它更接近这个层面。
OpenAI 的文章里提到,GPT-5.5 在 Codex 中可以承担从实现、重构、调试、测试到验证的一系列工程工作。早期测试者也认为,它更擅长保持大系统上下文、分析模糊故障、用工具验证假设,并把改动贯穿到周边代码库。
这对企业技术部门来说,影响很直接。
未来研发团队的瓶颈,可能不再是“有没有人写代码”,而是:
有没有清晰的需求文档?有没有稳定的工程规范?有没有可复用的上下文?有没有测试和 review 的自动化机制?有没有把 AI 纳入研发流程,而不是临时拿来问两句?
AI 越强,对团队工程管理的要求反而越高。
因为一个混乱的团队,用再强的 AI,也只是更快地产生混乱。
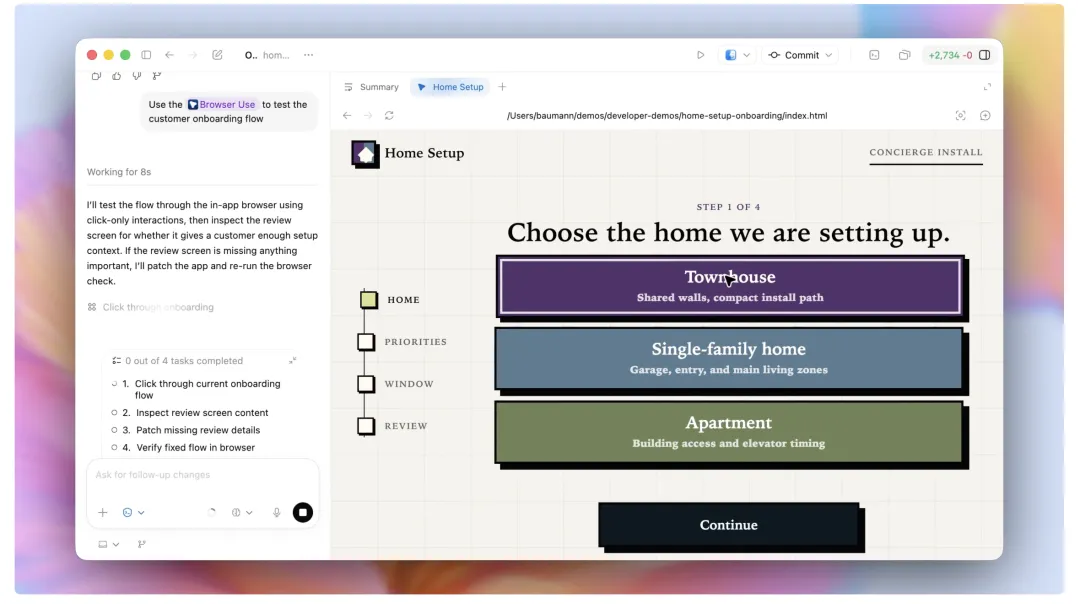
图注建议:OpenAI 原文中提到,GPT-5.5 更像是在理解一个系统,而不是只写一段代码。图源:OpenAI 官方博客。
OpenAI 原文还引用了早期测试者的反馈。
Every 创始人 Dan Shipper 说,GPT-5.5 是他用过的第一个具备“严肃概念清晰度”的编码模型。MagicPath CEO Pietro Schirano 也提到,GPT-5.5 在处理大规模前端和重构合并时,表现出了更强的持续性和系统理解能力。
我觉得这两个评价很关键。
因为它们说的不是“代码写得漂亮”。
而是 AI 开始具备一种更稀缺的能力:
看懂系统的形状。
三、知识工作开始进入“AI代执行”阶段
GPT-5.5 不只是面向程序员。
OpenAI 特别强调,它在日常知识工作上也有明显提升,包括查资料、理解重点、使用工具、检查输出、生成文档、表格和演示材料。OpenAI 还披露,公司内部已经有超过 85% 的员工每周使用 Codex,覆盖软件工程、财务、传播、市场、数据科学和产品管理等职能。
这个细节很重要。
很多人以为 Codex 只是写代码工具。
但从 GPT-5.5 开始,Codex 更像一个“会操作电脑的工作代理”。
OpenAI 举了几个内部案例。
传播团队用 GPT-5.5 分析六个月的演讲邀约数据,建立评分和风险框架,并验证一个自动化 Slack Agent,让低风险请求自动处理,高风险请求转给人工。
财务团队用 Codex 处理 24,771 份 K-1 税务表格,总计 71,637 页,并且在排除个人信息的前提下,比往年加速了两周。
市场团队有人用它自动生成每周业务报告,每周节省 5 到 10 小时。
这些案例其实给企业一个非常清晰的提示:
AI 最先落地的地方,不一定是最炫的地方,而是那些重复、繁琐、规则多、资料重、又需要人工判断的工作。
比如:
周报生成。合同初审。项目资料整理。销售线索评分。客服工单分流。财务表格审核。研发需求拆解。内部知识库问答。行业政策资料核查。方案文档智能审查。
这些工作以前为什么难自动化?
因为它们不是简单流程。
它们有大量非结构化资料,有上下文,有例外情况,有判断标准,还需要人在关键节点兜底。
现在模型能力提升之后,真正有价值的不是让 AI “完全替代人”,而是把这些工作拆成三类:
AI 可以自动做的部分。AI 先做、人来复核的部分。必须由人决策的部分。
这才是企业落地 AI 的正确姿势。
图注建议:GPT-5.5 让 AI 更接近真实知识工作的完整闭环:找信息、理解重点、调用工具、检查结果、生成可交付内容。图源:OpenAI 官方博客。
四、科学研究也开始出现“AI共同研究者”的影子
这次 GPT-5.5 还有一个很值得注意的方向:科学研究。
OpenAI 提到,GPT-5.5 在科学和技术研究流程上有提升。这里说的不是简单回答一个难题,而是能帮助研究者探索想法、收集证据、测试假设、解释结果,并决定下一步怎么做。
这背后有几个案例。
一位免疫学教授用 GPT-5.5 Pro 分析 62 个样本、近 28,000 个基因的表达数据,生成详细研究报告,并提出关键问题和洞察。
另一位数学教授用 GPT-5.5 在 Codex 中,从一个提示词出发,11 分钟内构建了一个代数几何可视化应用。
OpenAI 还提到,一个内部版本的 GPT-5.5 配合自定义 harness,帮助发现了关于 Ramsey 数的一个新证明,并经过 Lean 验证。
这件事我觉得很有代表性。
AI 不再只是“帮研究者解释论文”。
它开始变成研究过程中的一个执行伙伴:
帮你读资料。帮你写代码。帮你跑分析。帮你找异常。帮你生成报告。帮你质疑假设。帮你把想法变成工具。
当然,我们不能把这理解成 AI 已经可以独立做科研。
更准确的说法是:
AI 正在把专家的想法,更快地变成可验证的实验、代码、模型和报告。
这对企业也一样。
未来不是每家公司都要做科学研究,但每家公司都会有自己的“业务研究”:
客户为什么流失?哪个产品可能成为爆款?哪个项目风险最大?哪个销售线索更值得跟进?哪个技术方案更适合落地?哪个政策变化会影响业务?
这些问题,本质上都需要“资料收集 + 分析判断 + 工具执行 + 结果验证”。
GPT-5.5 代表的方向,就是让 AI 更深入地参与这个循环。
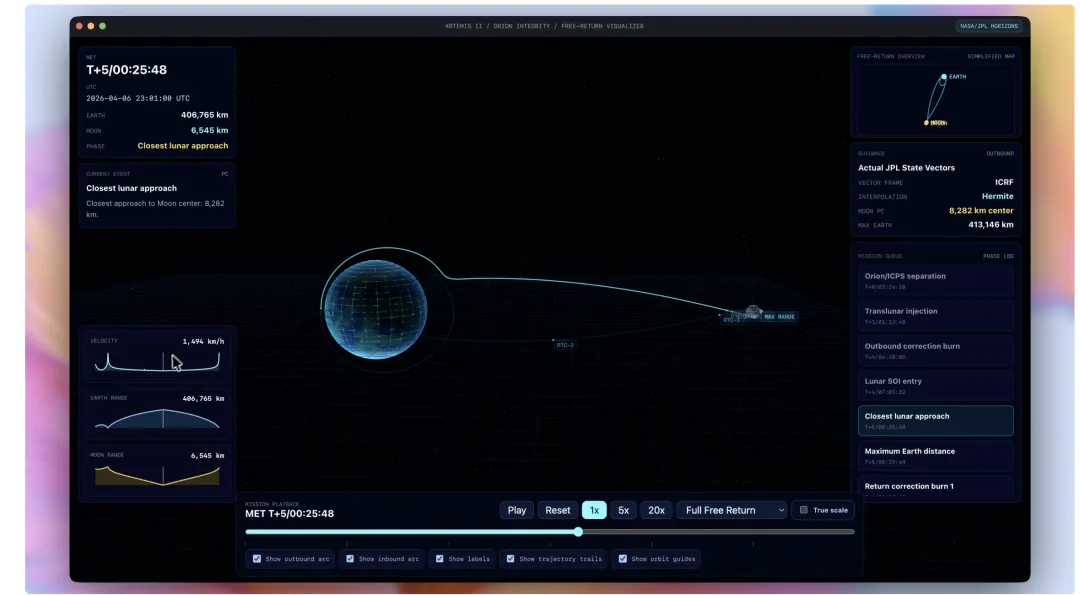
图注建议:在科研场景里,GPT-5.5 的价值不是给一个答案,而是参与“问题—实验—分析—输出”的完整循环。图源:OpenAI 官方博客。
下面这张图,是原文里最有说服力的一张。
它不是一段解释,也不是一篇报告,而是一个真实可交互工具的截图。
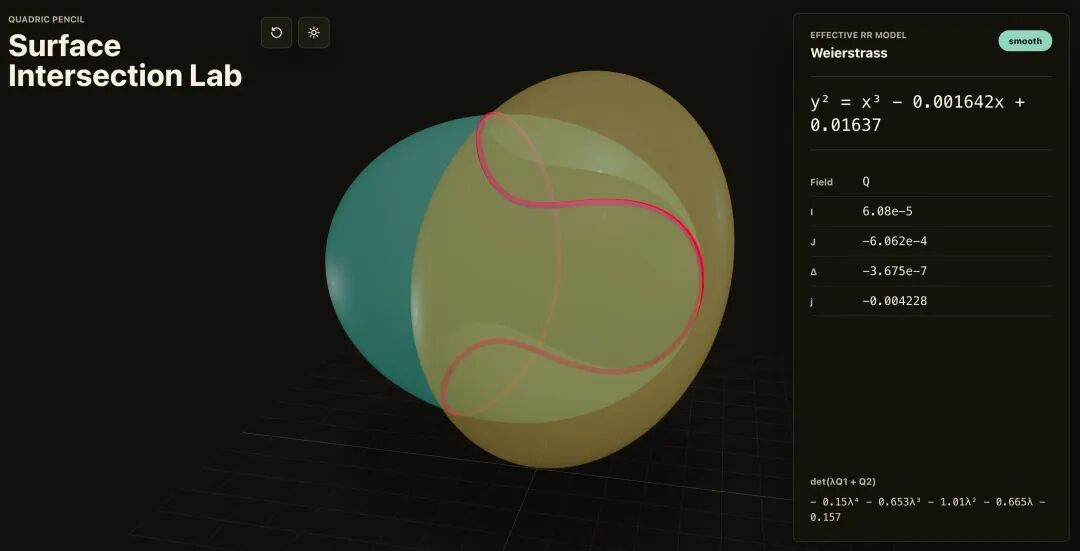
图注建议:数学教授 Bartosz Naskręcki 用 GPT-5.5 在 Codex 中生成的代数几何可视化应用。它把两个二次曲面的交线可视化,并转换为 Weierstrass 曲线模型。图源:OpenAI 官方博客。
这张图的意义在于:
它说明 AI 已经不只是“解释一个概念”,而是能把专家脑子里的想法,变成一个可运行、可交互、可继续扩展的工具。
这对企业非常重要。
很多企业真正缺的不是想法,而是把想法快速变成样板的能力。
以前一个想法要变成 Demo,要产品、设计、前端、后端、数据、测试配合。
现在,GPT-5.5 这类模型正在缩短这个距离。
五、速度没有被牺牲,反而更强调效率
大模型能力提升,通常会带来一个问题:更慢、更贵。
但 OpenAI 这次强调,GPT-5.5 在真实服务中的单 token 延迟与 GPT-5.4 持平,同时智能水平更高。OpenAI 还提到,GPT-5.5 是和 NVIDIA GB200、GB300 NVL72 系统协同设计、训练和服务的,并且 GPT-5.5 还反过来帮助优化了服务它自己的基础设施,其中一项负载均衡和分区启发式优化,让 token 生成速度提升超过 20%。
这段话很技术,但背后的含义很简单:
AI 正在帮助优化 AI 自己运行的基础设施。
这很有意思。
我们过去讲 AI 提效,通常是讲 AI 帮人提效。
现在更进一步:AI 也开始帮工程团队优化底层系统。
这对企业内部研发有启发。
如果一个技术团队还只是用 AI 写几个函数,其实太浅了。
更进一步的用法应该是:
让 AI 看日志。让 AI 分析性能瓶颈。让 AI 帮你设计测试用例。让 AI 帮你审查架构风险。让 AI 帮你生成部署脚本。让 AI 帮你维护工程文档。让 AI 帮你沉淀团队自己的开发 skill。
这才是“AI 原生研发体系”。
不是工具升级,而是研发方法升级。
六、安全限制会更强,这是必然趋势
GPT-5.5 能力越强,安全问题也越重要。
OpenAI 在文章里专门提到,GPT-5.5 在网络安全能力上比 GPT-5.4 更进一步,因此会部署更严格的分类器和防护机制,尤其针对高风险网络活动、敏感网络安全请求和重复滥用行为。OpenAI 也把 GPT-5.5 的生物/化学能力和网络安全能力在 Preparedness Framework 下评为 High,并表示模型没有达到 Critical 网络安全能力级别。
这件事对企业也有提醒。
未来越强的模型,越不可能是“随便用、无限制用”。
真正能用好 AI 的企业,一定要建立自己的边界:
哪些数据不能给模型?哪些任务必须人工复核?哪些操作需要权限审批?哪些输出需要留痕?哪些场景可以自动执行?哪些场景只能辅助决策?
AI 能力越强,治理能力越重要。
这也是为什么我一直不建议企业只做“AI工具培训”。
工具培训只能解决会不会用。
但企业真正的问题,是能不能安全、稳定、持续地把 AI 用进业务流程。
七、可用范围和价格:企业要开始认真算账了
根据 OpenAI 官方信息,GPT-5.5 已经开始面向 ChatGPT Plus、Pro、Business、Enterprise 用户,以及 Codex 中的部分用户推出。
GPT-5.5 Thinking 面向 Plus、Pro、Business、Enterprise 用户开放。
GPT-5.5 Pro 面向 Pro、Business、Enterprise 用户开放。
在 Codex 中,GPT-5.5 面向 Plus、Pro、Business、Enterprise、Edu 和 Go 计划开放,并支持 400K 上下文窗口。
API 版本即将上线,gpt-5.5 的 API 定价为每 100 万输入 token 5 美元、每 100 万输出 token 30 美元;gpt-5.5-pro 的价格为每 100 万输入 token 30 美元、每 100 万输出 token 180 美元。OpenAI 还提到,Batch 和 Flex 价格是标准 API 价格的一半,Priority 处理为标准价格的 2.5 倍。
这里企业要开始认真算账了。
未来企业用 AI,不能只看“模型单价”。
要看综合账。
如果一个更贵的模型,能少试错、少返工、少人工检查、少上下文补充、少失败重跑,那它在真实业务里反而可能更便宜。
尤其是在高价值任务里,比如:
代码重构。合同审查。投研分析。财务建模。政策审查。复杂方案评审。专业文档审核。企业内部知识工作自动化。
这些任务里,成本最高的不是 token,而是人的时间、返工、等待、沟通和错误决策。
所以企业未来选模型,不应该只问:
哪个模型便宜?
而应该问:
哪个模型在我的任务上,单位结果成本最低?
这才是老板视角。
八、对企业来说,GPT-5.5真正释放的信号
我看完这次发布,最大的感受是:
AI 落地正式进入“任务托管”阶段。
第一阶段,是提示词阶段。
人问一句,AI 回一句。
第二阶段,是上下文阶段。
人把资料、规则、文档、知识库喂给 AI,让它在具体语境里做事。
第三阶段,就是现在正在发生的约束工程阶段。
人给 AI 搭一个工作框架,让它能调用工具、执行流程、检查结果、反馈修正,并在边界内持续推进任务。
GPT-5.5 的意义,不是又多了一个更强模型。
而是它让“AI 员工”这件事更接近现实。
但我说的 AI 员工,不是一个会聊天的机器人。
而是一个被放进业务流程里的执行单元:
有任务入口。有资料来源。有工具权限。有执行步骤。有质量检查。有人工复核。有结果沉淀。
这才是企业真正需要建设的东西。
九、接下来企业AI落地会分化得很快
接下来一年,企业之间的差距会被迅速拉开。
不是因为谁买了更贵的模型。
而是因为谁更早完成了三件事。
第一,把业务流程拆清楚。
哪些环节适合 AI 自动化,哪些环节必须人工判断,要先画出来。
第二,把企业上下文沉淀下来。
文档、规范、案例、历史项目、知识库、模板、经验,都要变成 AI 能调用的资产。
第三,把 AI 放进真实任务里。
不要只培训,不要只演示,不要只做概念验证。
要选一个具体业务场景,做成样板,然后围绕样板迭代。
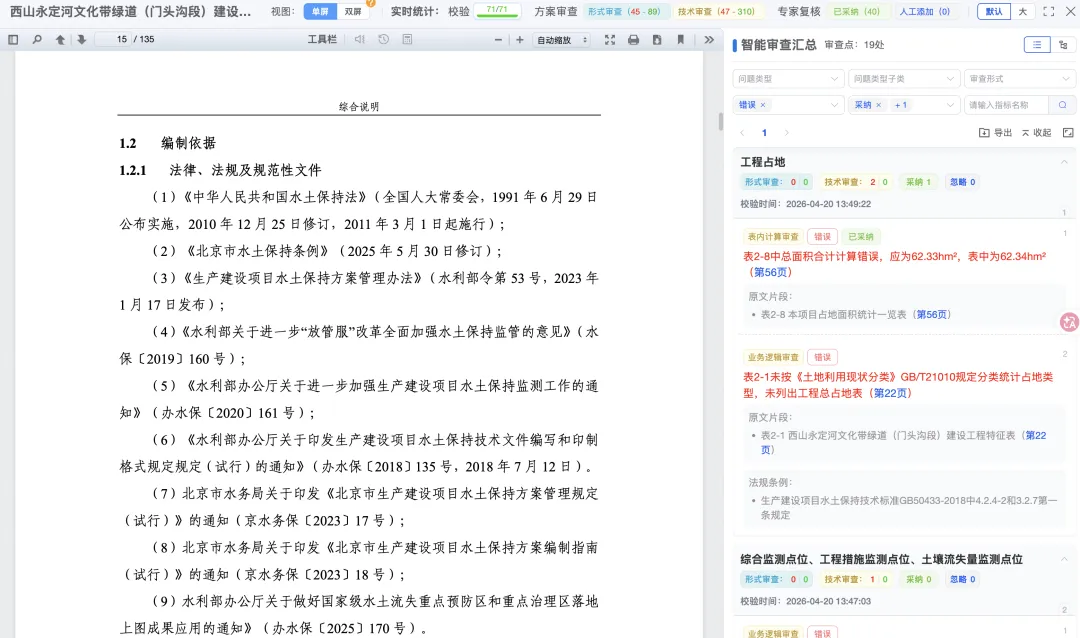
比如我们现在给水利部在做的水土保持方案智能审查,就是非常典型的场景。
它不是简单问答。也不是简单抽取。它本质上是:
文档解析。字段抽取。规范匹配。规则核验。证据定位。跨章节一致性判断。问题清单生成。人工复核留痕。
这类任务,正好对应 GPT-5.5 代表的方向:
让 AI 不只是生成内容,而是参与复杂工作流。
十、最后说一句
GPT-5.5 的发布,对普通用户来说,是 ChatGPT 又聪明了。
但对企业来说,它的信号更直接:
AI 不再只是一个工具,而是正在变成新的工作基础设施。
真正的问题已经不是:
“我们要不要用 AI?”
而是:
“我们能不能把 AI 放进业务流程里,让它稳定地产生结果?”
谁先把这件事做出来,谁就会拥有新的组织效率。
AI 不会替代所有人。
但会替代一批还停留在“手工搬运信息、重复执行流程、靠经验低效判断”的工作方式。
而真正会被放大的人,是那些能定义问题、设计流程、沉淀知识、驾驭 AI 完成复杂任务的人。
这也是 GPT-5.5 这次发布最值得我们认真看的地方。
它不是一次普通模型升级。
它是在提醒我们:
AI 时代的工作方式,又往前走了一步。