 夜雨聆风
夜雨聆风





OpenAI 发布 GPT-5.5,但是它虾里虾气的
今天用GPT-5.5跑了一个软件项目,我静静地看着它的运行过程,味道很熟悉…一股龙虾味。
4 月 23 日,OpenAI 发布 GPT-5.5,称其为“面向真实工作的全新智能形态”,并开始向 ChatGPT Plus、Pro、Business、Enterprise 用户以及 Codex 推送;GPT-5.5 Pro 面向 Pro、Business、Enterprise 用户开放。目前,API 版本暂未全面上线。
而且这次发布前一天,OpenAI 还推出了 gpt-image-2,来了个二连发。
GPT-5.5有哪些特点
最值得注意的是定位变化。GPT-5.5 的卖点集中在“长任务执行”:写代码、调试、联网研究、分析数据、生成文档和表格、操作软件、跨工具完成任务。OpenAI 在发布页中强调,它能更早理解任务意图,更少依赖用户逐步指挥,并能自己规划、调用工具、检查结果、处理模糊需求。
不过,OpenAI 没有公布 GPT-5.5 的参数规模、训练成本或完整架构细节。只披露了训练数据来源,并称 GPT-5.5 Pro 使用同一底层模型,但通过并行 test-time compute 获得更高准确性。
从公开跑分看,GPT-5.5 对 GPT-5.4 的提升主要集中在 Agent、代码、工具使用、长上下文和部分科研任务上。OpenAI 给出的数据包括:Terminal-Bench 2.0 从 75.1% 提升到 82.7%;Expert-SWE 从 68.5% 提升到 73.1%;GDPval 从 83.0% 提升到 84.9%;Tau2-bench Telecom 从 92.8% 提升到 98.0%;Graphwalks BFS 1M 从 9.4% 提升到 45.4%;ARC-AGI-2 从 73.3% 提升到 85.0%。
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
不过,GPT-5.5 也不是全面碾压。SWE-Bench Pro 上,GPT-5.5 为 58.6%,略高于 GPT-5.4 的 57.7%,但低于 Claude Opus 4.7 的 64.3%;Humanity’s Last Exam 无工具版本中,GPT-5.5 为 41.4%,低于 Claude Opus 4.7 的 46.9%。OpenAI 还在表格中注明,SWE-Bench Pro 存在被实验室指出的记忆化风险。
价格方面,OpenAI 预计在 API 中将 gpt-5.5 定价为每 100 万输入 token 5 美元、每 100 万输出 token 30 美元,gpt-5.5-pro 则为每 100 万输入 token 30 美元、每 100 万输出 token 180 美元。Codex 中的 GPT-5.5 拥有 400K 上下文窗口;API 版本上线后,gpt-5.5 将支持 1M 上下文窗口。
安全侧,OpenAI 把 GPT-5.5 称为其“迄今最强防护”发布之一,发布前进行了安全评估、Preparedness Framework 评估、网络安全和生物能力专项红队测试,并收集了近 200 家早期访问伙伴的真实使用反馈。系统卡中,OpenAI 将 GPT-5.5 的网络安全能力评为 High,但未达到 Critical。
实测:两个更能看出 GPT-5.5 差异的测试
测试一:给它一个“半成品需求”,看能不能自己把应用做完
这个测试对应 GPT-5.5 的核心卖点:Agentic coding、长任务执行、浏览器验证和自主纠错。
我先用gpt-image-2生成了一张“股票财报可视化工具”的产品草图,故意将产品需求写得不完整。然后再把这张草图给GPT-5.5让它做成成品,需要它完成前端、数据接入、交互、异常状态、测试,并用浏览器打开页面检查。
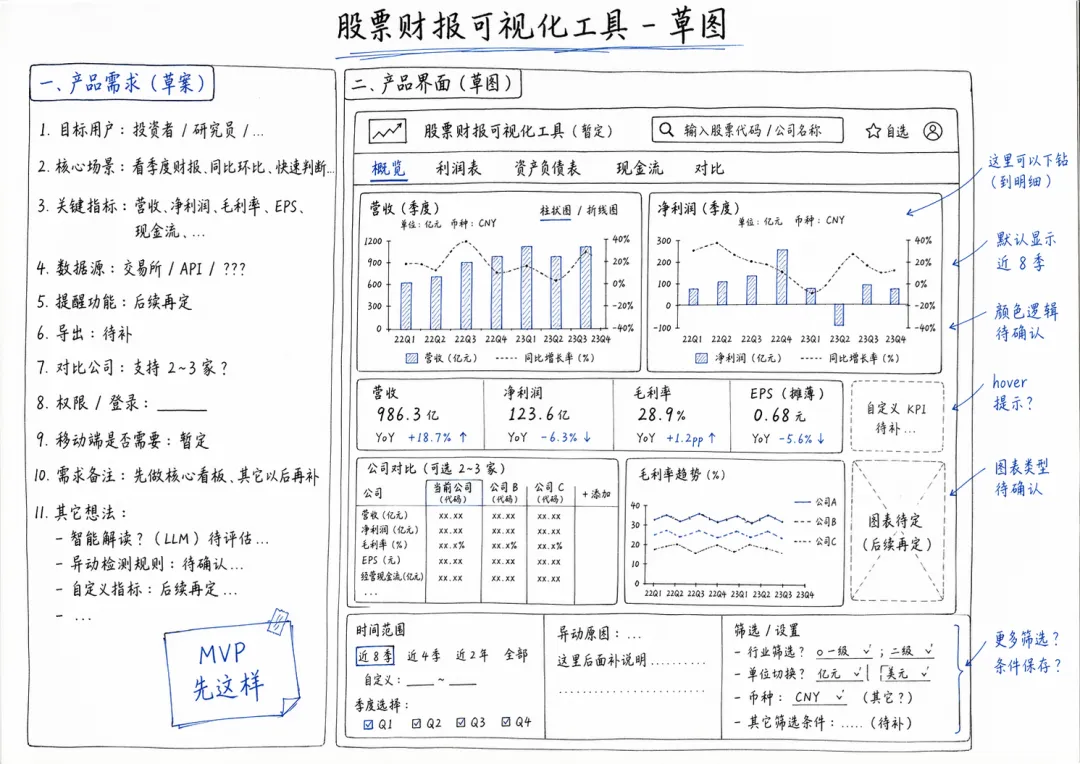
我上传了这张草图,还给了它一段提示词:
你是一个全栈工程师。请根据我上传的草图,做一个可运行的 Vite + React 应用。需求:
页面要尽量还原草图布局;
使用真实或可解释的模拟数据;
必须包含筛选、详情卡片、趋势图和异常状态;
写完后运行测试;
用浏览器检查页面,发现 UI 或交互问题后自行修复;
最后输出:完成了哪些功能、遇到哪些问题、修复了哪些 bug、还剩哪些风险。
运行持续近10分钟,中间遇到了很多npm包的安装、浏览器权限等问题,看得我捏了把汗,好在最后都解决了,给了一个可下载的项目包,确实符合它说的长任务定位!
我把项目包下载下来了,来看下还原情况:
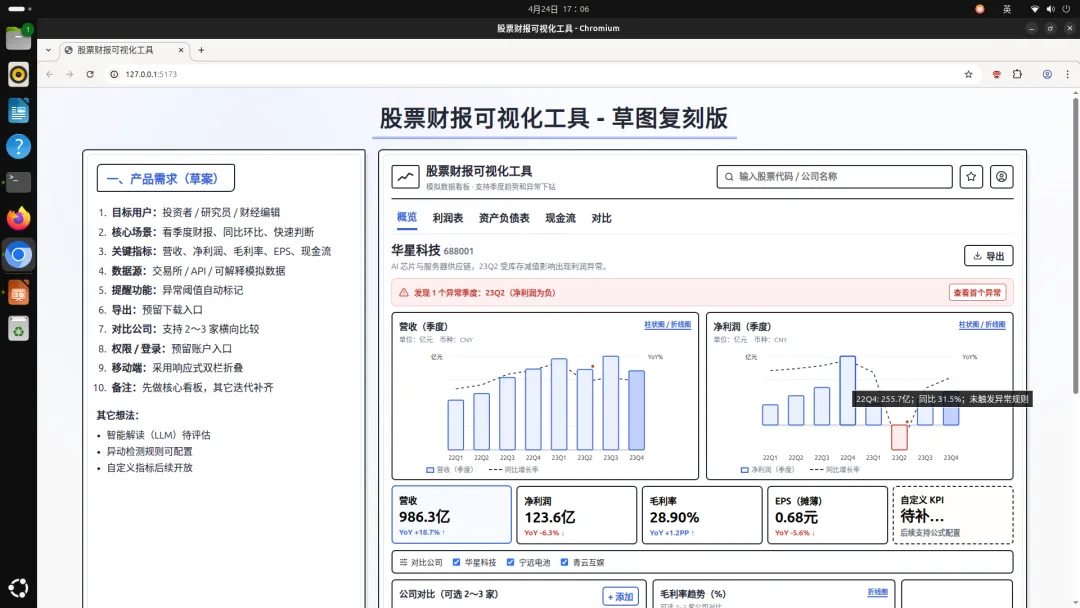
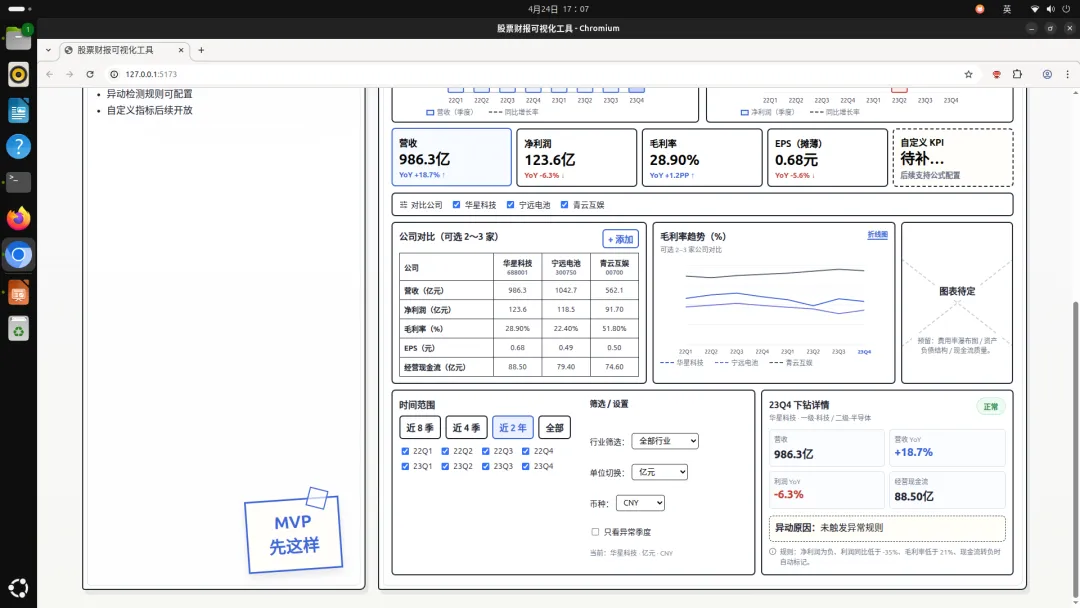
跟我的草图几乎一摸一样,而且可以点击交互,甚至是页面左下角的“MVP 先这样”也还原出来了,太细了!
测试二:与GPT-5.4对比,生成一段动画的效果
这个测试来源于X上的@stevibe。可以看到GPT-5.5的细节明显更真实到位。
结论:GPT-5.5虾里虾气
我们知道龙虾OpenClaw的创始人Peter Steinberger前段时间加入OpenAI,个人感觉他在GPT-5.5的研发环节起到了主导作用。
这次 GPT-5.5 的发布,表面上是一次模型版本更新,实际竞争点已经落到“能不能替人完成一段工作流”。它的强项不是单轮聊天的惊艳感,而是在复杂任务里持续推进:理解目标、拆任务、用工具、检查结果、修错、输出成品。
从跑分看,GPT-5.5 在代码、工具使用、长上下文、复杂办公任务上有明确进步。Terminal-Bench、Tau2-bench、Graphwalks 1M 和 ARC-AGI-2 的提升,都指向同一个方向:模型更能在长链路任务里保持状态。
从早期反馈看,OpenAI 选择放大的也是这一点。Every CEO Dan Shipper 认为 GPT-5.5 在编码上有更强的“概念清晰度”;Cursor 联合创始人 Michael Truell 强调它比 GPT-5.4 更聪明、更持久,能在复杂长任务里更久地保持执行状态;NVIDIA 企业 AI 副总裁 Justin Boitano 则把它描述为能把调试时间从数天压缩到数小时、把数周实验压缩到隔夜推进的工具。
这些评价也要分层看。OpenAI 官方发布页里的早测者反馈,更接近产品发布材料中的精选案例;Axios、The Verge 等媒体的报道则把重点放在企业采用、编码能力、效率和与 Anthropic 等对手的竞争上。Axios 援引 OpenAI 联合创始人 Greg Brockman 的说法,将 GPT-5.5 视为“更智能体化、更直觉化计算”的一步;The Verge 则强调其在编码、调试、在线研究和跨工具生产力任务中的提升。
GPT-5.5 最值得关注的地方,也许不在“它是不是最强大模型”这个单点问题上。Claude 仍在部分代码和通用难题跑分中领先。OpenAI 这次真正想展示的是:当模型能够接入 Codex、浏览器、文件、表格和图像生成工具之后,大模型的竞争对象已经不只是聊天框里的答案质量,还包括一个任务从输入到交付的完整效率。
如果说 GPT-5 时代的争议在于“模型有没有质变”,GPT-5.5 给出的答案更务实:少一点演示场景里的炫技,多一点真实工作中的耐心、持续性和交付能力。对普通用户来说,这种变化可能没有一句惊艳回答那么容易传播;对开发者、研究人员和企业用户来说,它更接近一个能长期占用工作台的生产工具。
END