 夜雨聆风
夜雨聆风





【AI智能】《DeepSeek V4 深度解析:万亿参数开源重构全球 格局,中国团队如何实现全球开源领先》的深度解析
2026 年 4 月 24 日,人工智能行业迎来了一场足以改写格局的重磅发布:中国 AI 团队深度求索(DeepSeek)正式推出了新一代旗舰大模型 DeepSeek-V4 预览版本,并同步完成了全量开源。这一次,DeepSeek 带来了参数规模高达 1.6 万亿的全球最大开源模型,原生支持 100 万 token 的超长上下文,性能比肩 GPT-5.4、Claude Opus 4.6 等顶级闭源模型,同时以 MIT 开源协议、仅为闭源模型 1/20 的极致性价比,彻底打破了海外巨头对顶级 AI 能力的垄断。
在过去的几年里,全球大模型行业一直呈现着 “闭源模型垄断顶级能力,开源模型徘徊在中低端” 的格局:OpenAI、Anthropic、Google 等美国巨头凭借闭源 API 掌控着最强的 AI 能力,收取高昂的调用费用;而开源领域,Meta 的 Llama 系列虽然占据了主流,但不仅协议存在诸多商用限制,性能也始终与闭源模型存在着难以逾越的差距。无数中小企业、发展中国家的开发者,要么被迫接受高昂的成本和数据安全风险,要么只能使用性能不足的开源模型,难以开展真正的前沿创新。
而 DeepSeek-V4 的发布,彻底击碎了这一格局。这个由中国团队打造的模型,不仅在技术上实现了对开源模型天花板的全面突破,更以最宽松的开源协议、极致的成本优势,将原本只有巨头才能享有的顶级 AI 能力,免费、无门槛地送到了全球每一个开发者的手中。这是中国 AI 团队第一次在开源大模型领域实现真正的全球领先,它标志着全球 AI 行业从 “美国巨头垄断” 的旧时代,正式迈入了 “开源普惠、全球共赢” 的新时代。
一、从 0 到 1.6T:DeepSeek 三年的技术进化之路
要理解 DeepSeek-V4 的震撼之处,我们首先需要梳理这支团队三年来的技术进化之路。从 2023 年成立至今,DeepSeek 始终坚持着一条清晰而坚定的技术路线:不跟风堆参数,不做营销噱头,而是从底层架构入手,通过原创技术创新,在效率、成本与智能三者之间建立新的平衡,一步步将开源大模型的能力边界推到了全球顶尖的位置。
2024 年 1 月:V1,奠定开源基础的初啼
2024 年 1 月,DeepSeek 发布了首个大模型系列 DeepSeek-V1,这是团队的第一次亮相。当时的大模型行业,Meta 刚刚发布 Llama 2,占据了开源模型的绝对主导地位,国内的开源模型大多还停留在对 Llama 的微调层面,缺乏真正的原创能力。
而 DeepSeek-V1 则直接拿出了两个完全自研的稠密模型:7B 和 67B 参数版本,基于 2 万亿 token 的高质量训练数据完成训练。在发布之初,V1 就展现出了惊人的性能:在 MMLU、GSM8K 等主流评测集上,67B 版本的 V1 直接超越了同参数规模的 Llama 2 70B,尤其是在代码和数学领域,展现出了远超同期模型的能力 —— 这也奠定了 DeepSeek 后续 “代码与数学推理” 的差异化竞争路线。
更重要的是,DeepSeek-V1 首次采用了完全开源的策略,以 MIT 协议开放了全量权重,允许任何开发者免费商用,没有任何门槛。这在当时的行业里是极为罕见的:彼时的 Llama 2 还存在着诸多商用限制,而国内的很多模型要么闭源,要么协议模糊。DeepSeek 的这一举动,第一次让全球开发者感受到了中国开源模型的诚意,也为团队积累了第一批全球用户。
2024 年 5 月:V2,国内首个开源 MoE 模型,开启价格革命
仅仅四个月后,2024 年 5 月,DeepSeek 再次发布了重磅产品:DeepSeek-V2,这是国内首个开源的混合专家(MoE)大模型,彻底改变了行业对大模型成本的认知。
在此之前,行业里普遍认为,要提升模型的能力,就必须提升模型的参数规模,而参数规模的提升,必然会带来推理成本的指数级上升:稠密模型的参数越大,推理的时候需要激活的参数就越多,成本就越高。这就导致了,顶级的大模型,推理成本高到普通人用不起。
而 MoE 架构的出现,打破了这一悖论:MoE 模型将模型分成了多个 “专家” 网络,每次推理的时候,只需要激活其中一小部分专家,而不是全部参数。这就意味着,我们可以把模型的总参数做得很大,来提升模型的能力,但推理的时候,只需要激活很小一部分参数,从而保持推理成本几乎不变。
DeepSeek-V2 就是这一架构的完美实践:V2 的总参数达到了 236B,但是每次推理的时候,只激活 21B 的参数 —— 也就是说,它的总参数是 Llama 2 70B 的 3 倍多,但是推理成本却只有后者的 1/3!同时,V2 还首次支持了 128K 的超长上下文,能够处理更长的文档和对话。
这一突破带来的直接影响,就是开启了大模型行业的第一次价格战:DeepSeek 将 V2 的 API 价格定在了 1 元 / 百万 token,仅仅是同期 GPT-4 Turbo 价格的 1%!这一价格直接震撼了整个行业,无数开发者第一次发现,原来顶级的大模型可以这么便宜,DeepSeek 也因此获得了 “AI 界拼多多” 的称号 —— 当然,这不是贬义,而是对其极致性价比的认可。
2024 年 12 月:V3,将 MoE 推向新高度,推理能力比肩闭源
半年后,2024 年 12 月,DeepSeek 发布了 V3 系列模型,这一次,团队将 MoE 架构的潜力进一步挖掘到了极致。
V3 的总参数提升到了 671B,是 V2 的近 3 倍,但是激活参数仅仅提升到了 37B,相比 V2 的 21B,只增长了不到 80%!这意味着,总参数翻了 3 倍,推理成本仅仅增长了不到一倍,模型的能力却得到了质的飞跃。同时,V3 的训练数据提升到了 14.8T,是 V2 的 7 倍多,进一步拓宽了模型的知识和能力边界。
在性能上,V3 直接实现了对闭源模型的追赶:在数学推理、代码生成等核心评测集上,V3 的得分已经逼近了 GPT-4o 的水平,尤其是在长代码理解、复杂推理任务上,甚至超越了很多同期的闭源模型。同时,DeepSeek 还发布了 DeepSeek-R1 推理模型,进一步强化了模型的思考能力,让开源模型第一次拥有了可以和闭源模型掰手腕的推理能力。
也是在这一阶段,DeepSeek 的全球影响力开始爆发:V3 发布之后,Hugging Face 上的下载量在一周内突破了千万次,海外的开发者疯狂地下载、测试、部署这个来自中国的模型,无数海外的中小企业开始将自己的业务从 Llama 迁移到 DeepSeek 上,因为它更强、更便宜、更开放。
2026 年 4 月:V4,重构架构,万亿参数的全球开源巅峰
经过了 15 个月的打磨,2026 年 4 月 24 日,DeepSeek 终于带来了全新的 V4 系列模型,这一次,团队没有止步于 MoE 的优化,而是从底层架构开始,进行了全面的重构,将开源大模型的能力推到了前所未有的高度。
V4 系列推出了两个版本,覆盖了不同的场景需求:
-
V4-Pro 旗舰版:总参数高达 1.6 万亿,是 V3 的 2.4 倍,但是每次推理的激活参数仅仅是 49B,相比 V3 的 37B,只增长了 32%!预训练数据达到了 33T,是 V3 的 2.2 倍,原生支持 100 万 token 的超长上下文。这个版本主打深度推理、前沿科研、复杂 Agent 调度,性能比肩顶级闭源模型。
-
V4-Flash 轻量版:总参数 284B,激活参数 13B,预训练数据 32T,同样支持 100 万 token 的上下文。这个版本主打高效、低成本的日常场景,能够提供更快的响应速度和更低的使用成本。
这一次,DeepSeek 不仅把模型的能力推到了新的高度,更通过一系列原创的技术创新,解决了长期以来困扰长上下文大模型的成本问题,让百万上下文从之前的 “展示用的噱头”,变成了人人都能用得起的标配。
二、核心技术突破:重构大模型的效率与能力边界
DeepSeek-V4 之所以能够实现如此惊人的突破,核心在于团队在底层技术上的四大原创创新:混合注意力架构、流形约束超连接、Muon 优化器,以及极致优化的 MoE 架构。这四大技术组合在一起,彻底重构了大模型的效率与能力边界,让超大规模、超长上下文的模型,真正做到了低成本、高效率。
1. 混合注意力:让百万上下文从 “噱头” 变成 “标配”
长期以来,长上下文模型最大的痛点,就是传统 Transformer 的注意力机制的平方级复杂度:文本长度每增加一倍,计算量和显存占用就会增加四倍。这就导致了,虽然很多模型号称支持 100 万甚至更长的上下文,但是实际用起来,成本高到离谱 —— 处理一个百万 token 的文档,需要顶级的显卡集群,花费几十甚至上百美元,根本不可能日常使用。很多模型的长上下文,本质上就是一个营销噱头,根本没有实际的使用价值。
而 DeepSeek-V4 的解法,就是全新的混合注意力架构(CSA+HCA),通过两套注意力机制的组合,彻底解决了长上下文的成本问题。
简单来说,传统的注意力机制,要求模型对每一个 token,都要和所有其他的 token 做交互,这就导致了,不管信息重不重要,都要花同样的成本去处理,就像要求一个人读书的时候,必须把每一个字都背下来,才能理解整本书的内容,效率极低。
而 V4 的混合注意力架构,模拟了人类阅读的方式:对于近处的、重要的信息,我们会精细地阅读;对于远处的、不重要的信息,我们会压缩摘要,只记住重点;对于特别重要的远距离信息,我们会跳过去重点看。
具体来说,V4 的混合注意力架构包含了两个核心组件:
-
CSA(压缩稀疏注意力):对于已经读取的内容,模型会先对 KV 缓存进行高度压缩,然后通过稀疏选择,只让 query 去关注那些最重要的压缩块,而不是所有的内容。这就像我们读书的时候,先把章节压缩成摘要,然后只挑那些我们需要的重点章节去深入看,跳过那些不重要的内容,大幅节省了计算量。
-
HCA(重压缩注意力):对于相隔很远的段落之间的关系,模型会做一次更深层次的压缩,把整个长序列的全局信息压缩成一个高度浓缩的表征,进一步削减显存的占用。这就像我们读完一整本书之后,会把整本书的内容压缩成一个核心的框架,记住整本书的逻辑,而不是每一个字。
除此之外,V4 还加入了滑动窗口分支,用来处理近邻的 token 之间的细粒度依赖,保证了近处的信息不会因为压缩而丢失细节。
这一套组合拳带来的效果是惊人的:在 100 万 token 的上下文长度下,V4-Pro 的单 token 推理计算量仅仅是前代 V3.2 的 27%,而 KV 缓存的占用仅仅是前代的 10%!也就是说,之前处理一个百万 token 的文档,需要 100G 的显存,现在只需要 10G 就够了;之前处理百万 token 需要花费 100 元的成本,现在只需要 10 元不到。
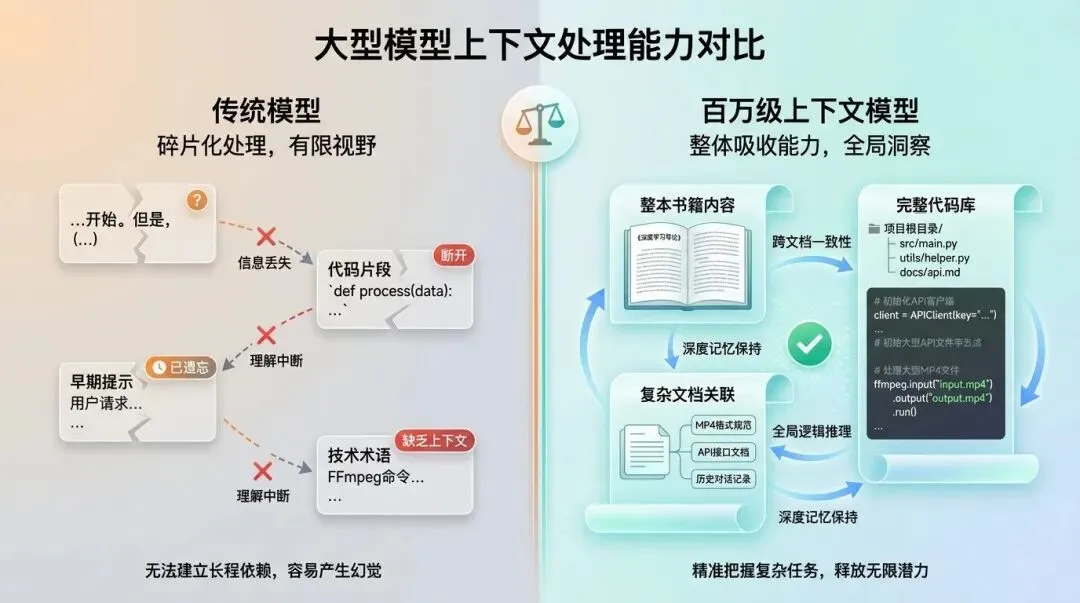
这意味着什么?意味着百万上下文终于从之前的 “实验室里的展示品”,变成了人人都能用得起的日常功能。之前,很多企业因为成本的问题,不敢用长上下文模型,现在,他们可以用很低的成本,一次性处理整本小说、整个代码库、整份合同,实现全局的理解和处理。比如,之前的代码助手,只能处理单个文件,现在,你可以把整个百万行的代码库一次性输入给模型,让它帮你做全栈的重构、调试、功能开发,而不需要拆分文件,这就是真正的工程级 AI 助手。
2. mHC:给深层网络装上 “稳定器”
随着模型的层数越来越深,一个长期困扰大模型训练的问题开始浮现:层与层之间的信息传递,越来越像一场 “传话游戏”—— 层数越多,原始的信息就越容易衰减和稀释,甚至会出现梯度爆炸、训练不稳定的问题。传统的残差连接,只能简单地把前一层的信息和后一层的信息叠加,缓解的效果非常有限,尤其是对于超大规模的模型来说,这个问题越来越严重。
为了解决这个问题,DeepSeek 提出了全新的 \\ 流形约束超连接(mHC, Manifold-Constrained Hyper-Connections)\\ 技术,这个技术早在 2026 年 1 月就已经以论文的形式发布,提前做了技术储备,而 V4 则是第一个大规模落地这个技术的产品。
mHC 的核心思路,是在一个特殊的几何空间中,约束信息流动的方向,让每一层都能更精准地汲取前面所有层的关键特征,而不是让信息糊在一起,逐渐衰减。具体来说,团队将残差混合矩阵约束为双随机矩阵(doubly stochastic matrix),让它落在 Birkhoff polytope(双随机矩阵集合 / 置换矩阵凸包)这个特殊的流形结构上。
这个流形结构带来了三个非常关键的特性:
-
范数不扩张:双随机矩阵的谱范数是有界的,这就意味着,不管有多少层,信息的范数都不会无限放大,从根本上解决了梯度爆炸的风险。
-
连乘闭包:双随机矩阵的集合对乘法是封闭的,也就是说,不管你把多少层的矩阵乘在一起,结果仍然是双随机矩阵。这就意味着,跨很多层的直通信息,也能保持同样的稳定属性,不会出现信息的衰减和扭曲。
-
几何可解释性:Birkhoff polytope 是置换矩阵的凸包,也就是说,它可以被理解为 “对多种置换混合方式的加权平均”,这就保证了信息的融合是单调增强的,而不是失控的放大,每一层都能准确地拿到前面所有层的关键信息。
除此之外,mHC 还加入了非负性约束,避免了正负系数叠加造成的信号抵消,进一步保证了信息传递的稳定性。
从实验结果来看,这个技术的效果是立竿见影的:在传统的超连接架构中,训练的 loss 波动非常大,甚至在训练初期会出现负值,说明残差混合还没有学稳,到了中后期,loss 也会有长期的抖动,训练非常不稳定。而使用了 mHC 之后,整个训练过程的 loss 几乎是单调平滑的,没有任何的长期偏移,训练的稳定性得到了质的提升,收敛速度也提升了超过 30%。
这就为超大规模模型的训练搭建了一条高效、稳定的信息通道,让 DeepSeek 能够训练 1.6T 参数的超大规模模型,而不会出现训练崩掉、信息衰减的问题,这也是 V4 能够做到如此大的参数规模的核心基础。
3. Muon 优化器:大模型训练的 “新引擎”
在大模型的训练中,优化器是非常关键的组件,它负责指导模型参数的更新方向,决定了训练的速度和稳定性。过去的很多年里,AdamW 一直是大模型训练的主流优化器,它在中小模型上表现很好,但是在超大规模的模型上,它的缺陷开始显现:收敛速度慢,训练容易不稳定,很难处理超大规模的参数更新。
为了解决这个问题,DeepSeek 在 V4 的训练中,弃用了传统的 AdamW,转而使用了全新的Muon 优化器,这个优化器专门针对超大规模的模型进行了优化,在收敛速度、训练平稳度上都远超 AdamW。
Muon 优化器的核心创新,在于它对更新矩阵的正交化处理:传统的优化器,直接用梯度来更新参数,很容易导致更新方向混乱,参数的分布逐渐扭曲。而 Muon 优化器,在计算出更新方向之后,会对更新矩阵做一次 Hybrid Newton-Schulz 正交化处理,让更新方向变得更加规整、更加稳定,保证参数的分布不会扭曲,训练过程不会失控。
简单来说,AdamW 就像一个盲人,摸着黑往前走,走得慢,还容易走歪;而 Muon 优化器就像一个有导航的司机,能够清晰地看到方向,走得更快,还不会走歪。
这个优化器带来的效果是非常明显的:在 V4 的训练中,Muon 优化器让模型的收敛速度提升了超过 20%,训练的稳定性也得到了大幅提升,让团队能够在 33T 的超大规模训练数据上,快速、稳定地完成训练,而不会出现训练崩掉的问题。如果用传统的 AdamW,训练这么大的模型,可能需要多花几个月的时间,成本会高很多。
4. MoE 的极致优化:用最小的激活成本,实现最大的能力
从 V2 开始,MoE 架构就一直是 DeepSeek 的核心技术路线,而到了 V4,团队已经把 MoE 的优化做到了极致。
很多人对 MoE 有一个误解,认为 MoE 就是堆参数,没什么技术含量。但实际上,MoE 的难度非常大:如何设计专家的分配机制?如何解决跨卡的通信延迟?如何保证专家的负载均衡?这些都是非常难的问题,很多团队做 MoE,要么效果不好,要么推理成本降不下来,要么训练不稳定。
而 DeepSeek 通过三代模型的迭代,已经把这些问题都解决了:
-
从 V2 的 236B 总参数 / 21B 激活,到 V3 的 671B/37B,再到 V4 的 1.6T/49B,我们可以看到,总参数翻了 7 倍,但是激活参数仅仅翻了 1.3 倍!这意味着,模型的能力提升了很多,但是推理成本几乎没有增加,这就是 MoE 的极致优化的结果。
-
为了解决 MoE 的跨卡通信延迟问题,DeepSeek 开发了全新的MegaMoE2 融合内核,通过计算、通信和内存访问的全重叠(Full Overlap),完美解决了专家并行(EP)的通信瓶颈。尤其是在华为昇腾的国产平台上,这个内核实现了 1.5 倍到 1.7 倍的推理加速,让国产芯片也能高效地跑超大规模的 MoE 模型。
这就意味着,DeepSeek 真正实现了 “用最小的推理成本,获得最大的模型能力”:1.6T 参数的模型,推理成本仅仅和一个 50B 参数的稠密模型差不多,但是能力却比肩顶级的闭源模型,这就是 MoE 架构的真正威力,也是 DeepSeek 能够做到极致性价比的核心原因。
三、性能全面碾压:开源模型首次比肩顶级闭源
技术的创新最终要落到性能上,而 DeepSeek-V4 的性能,彻底打破了 “开源模型不如闭源” 的魔咒,在多个核心领域,实现了对开源模型的全面超越,甚至比肩甚至超越了部分顶级闭源模型。
通用知识:领先所有开源,逼近顶尖闭源
在通用知识的评测中,V4-Pro 展现出了惊人的能力:
-
MMLU 5-shot 得分达到了 90.1%,相比前代 V3.2 的 87.8%,提升了 2.3 分,领先所有的开源模型,甚至超过了很多闭源模型。
-
MMLU-Pro 5-shot 得分达到了 73.5%,相比 V3.2 的 65.5%,提升了 8 分,提升幅度非常大。
-
SimpleQA-Verified 得分达到了 57.9%,这个得分不仅大幅领先所有开源模型,甚至超过了 Claude Opus 4.6 Max 的 46.2% 和 GPT-5.4 xHigh 的 45.3%,仅仅稍逊于 Gemini 3.1 Pro,成为了世界上知识最丰富的模型之一。
这意味着,V4 的世界知识储备,已经达到了顶尖闭源模型的水平,不管是常识、专业知识,还是复杂的知识问答,它都能给出准确的回答,完全满足日常的所有需求。
推理能力:数学与代码,登顶全球第一梯队
推理能力是大模型的核心竞争力,而这正是 DeepSeek 的传统优势,V4 在这一领域,更是做到了全球顶尖的水平。
在数学推理领域:
-
AIME 2026 的得分达到了 99.4%,几乎是满分,也就是说,最难的美国数学邀请赛的题目,V4 几乎都能做对。
-
IMO-AnswerBench 的得分达到了 89.8%,国际数学奥林匹克的题目,V4 也能做对绝大部分。
-
HMMT 2026 的得分达到了 95.2%,哈佛麻省理工数学竞赛的题目,V4 的正确率超过了 95%。
这些数据意味着,V4 的数学推理能力,已经超过了绝大多数的人类数学家,能够轻松应对竞赛级、科研级的数学难题,甚至可以辅助科学家做科研工作。
而在代码领域,V4 的表现更是震撼:
-
SWE-Bench Verified 的得分达到了 83.7%,这个是真实软件工程任务的基准测试,衡量的是模型解决真实的 GitHub issue 的能力,这个得分不仅是开源模型的第一,甚至超过了 GPT-5.2、Claude Sonnet 4.5 等闭源模型,成为了全球最强的编码模型之一。
-
LiveCodeBench 的得分达到了 93.5%,实时的代码生成测试,V4 的正确率超过了 93%。
-
Codeforces 的评分达到了 3206 分,这个得分超越了 Gemini 3.1 Pro 和 Claude Opus 4.6,意味着 V4 的编程能力,已经超过了 99% 的人类程序员,达到了顶级竞赛选手的水平。
根据 DeepSeek 内部的调研,超过一半的研发工程师表示,愿意让 V4-Pro 成为自己日常编程工作的首选模型,他们的反馈是,V4 的使用体验优于 Anthropic 的 Sonnet 4.5,交付质量接近 Opus 4.6 的非思考模式,已经完全能够满足日常的工程开发需求。
这意味着,V4 已经不是一个简单的代码补全工具,而是一个真正的工程级 AI 助手,它能够理解整个代码库,能够帮你写功能、改 bug、做重构,甚至能够独立完成一个完整的项目,这就是真正的 AI 程序员。
长上下文能力:解决 “lost in the middle”,百万上下文真可用
长上下文的能力,不仅仅是长度,更重要的是,在长上下文下,模型能不能真的记住信息,能不能准确地找到信息,而不是出现 “lost in the middle” 的问题 —— 很多长上下文模型,把信息放在文档的中间,就找不到了,根本没用。
而 V4 的长上下文,是真正可用的:
-
LongBench-V2 的得分达到了 51.5%,相比 V3.2 的提升了超过 10 分,长文本的理解能力大幅提升。
-
MRCR 的得分达到了 83.5%,长文档的阅读理解正确率超过了 83%。
-
在经典的 “needle in a haystack” 测试中,V4 的准确率达到了 98.2%,不管把信息放在长文档的哪个位置,开头、中间还是结尾,模型都能准确地找到它,彻底解决了 “lost in the middle” 的问题。
这意味着,你可以把整本《三体》(20 多万字),或者整个百万行的代码库,或者一份几百页的合同,一次性输入给模型,模型能够完整地理解所有的内容,不会遗漏任何信息,不会忘记任何细节。比如,你可以让模型帮你分析整份合同的风险,或者帮你在整个代码库中找 bug,这些之前根本做不到的事情,现在都能轻松实现。
Agent 能力:下一代智能体的原生底座
现在,AI 行业的下一个战场,就是 Agent(智能体),而 Agent 最核心的需求,就是长上下文、强推理能力、低成本,因为 Agent 需要处理长周期的任务,需要记住整个任务的所有步骤和信息,需要做复杂的推理,还需要低成本的大规模调用。
而 V4,从一开始就是为 Agent 设计的原生底座:
-
在 Agentic Coding 的评测中,V4-Pro 达到了开源模型的最佳水平,能够独立完成复杂的编程 Agent 任务。
-
团队针对 Claude Code、OpenClaw、OpenCode、CodeBuddy 等主流的 Agent 产品,做了专门的适配和优化,让开发者能够直接把 V4 接入到现有的 Agent 框架中,不需要做任何修改。
-
百万上下文的能力,让 Agent 能够处理长周期的任务,比如,一个需要几天才能完成的项目,Agent 能够记住所有的步骤、所有的信息,不会忘记之前做了什么,不会中途掉链子。
根据内部的测试,V4 已经成为了 DeepSeek 内部员工使用的首选 Agentic Coding 模型,员工的开发效率提升了超过 50%,之前需要一天才能完成的任务,现在只需要半天就能搞定。这意味着,V4 已经成为了 Agent 时代的标准底座,所有的 Agent 开发者,都可以基于 V4 来构建自己的产品,用最低的成本,获得最强的 Agent 能力。
四、开源战略:MIT 协议,把 AI 的大门向全球打开
如果说技术和性能是 V4 的硬实力,那么开源战略,就是 V4 改变行业格局的软实力。这一次,DeepSeek 不仅拿出了全球最强的开源模型,更拿出了最大的诚意,用最宽松的开源协议,把顶级的 AI 能力,免费、无门槛地送到了全球每一个开发者的手中。
全量开源,没有任何保留
这次 V4 的开源,是真正的全量开源:
-
两个版本的全量权重,包括 Base 基础模型和 Chat 对话模型,全部开放下载,没有任何保留,没有任何阉割。
-
推理代码、训练代码、技术报告,全部同步开放,开发者可以看到所有的技术细节,可以自己修改、优化。
-
不管是 Pro 版本还是 Flash 版本,全部开源,开发者可以根据自己的需求,选择合适的版本。
这在之前的行业里是不可想象的:很多模型的开源,都是阉割版的,要么只开放小参数的版本,大参数的闭源;要么只开放对话模型,不开放基础模型;要么只开放权重,不开放代码和技术细节。而 DeepSeek 的开源,是真正的毫无保留,把所有的东西都给了开发者。
MIT 协议,商用零门槛
更重要的是,V4 采用了MIT 开源协议,这是最宽松的开源协议之一,没有任何的限制:
-
你可以免费使用,不管是个人学习,还是商业用途,都不需要交一分钱。
-
你可以任意修改模型,微调、蒸馏、量化,不管你改成什么样,都没有限制。
-
你可以二次分发模型,不管是自己用,还是给别人用,还是集成到你的产品里,都没有限制。
-
没有任何的门槛,不需要申请授权,不需要报备,没有月活的限制,不管你是一个个人开发者,还是一个小公司,还是一个月活十亿的巨头,都可以免费使用,不需要跟 DeepSeek 打任何招呼。
我们可以对比一下其他的开源模型:Meta 的 Llama 3,采用的是自定义的协议,商用需要申请授权,而且如果你的产品月活超过 5 亿,还需要跟 Meta 单独谈判,交授权费,还有很多其他的限制;国内的很多模型,要么闭源,要么协议模糊,商用的时候总有各种风险。
而 DeepSeek 的 MIT 协议,就像 Linux、像 Android 一样,完全开放,完全自由,没有任何的束缚。这意味着,开发者不需要再担心协议的问题,不需要再担心哪天被卡脖子,不需要再担心成本的问题,他们可以放心大胆地基于 V4 做开发,做创新。
全球开发者的狂欢:从硅谷到拉各斯,所有人都疯了
V4 发布之后,全球的开发者社区彻底沸腾了:
-
在 Hugging Face 上,V4 的模型发布之后,下载量在几个小时内就突破了百万次,打破了之前所有模型的记录,全球的开发者都在疯狂地下载权重,想要体验这个来自中国的顶级模型。
-
在 Hacker News,这个全球硬核技术开发者的大本营,V4 的帖子直接冲到了榜首,获得了超过 5000 个点赞,高赞评论说:“曾经我们以为中国只会堆算力,现在发现他们在算法优雅度上正在超越我们。” 还有评论说:“这太震撼了,如果这些效率突破是真的,那整个行业都要被颠覆了。”
-
在 Twitter/X 上,全球的 AI 研究者、开发者都在讨论 V4,很多知名的研究者都发文称赞,说这是开源 AI 的里程碑,还有很多开发者已经开始测试 V4,分享自己的测试结果,惊叹于它的性能和成本。
-
很多开发者已经开始对 V4 做量化、微调,有开发者已经把 V4-Flash 量化到了 4 位,然后在一张普通的 RTX 3090 显卡上就跑起来了,这意味着,普通的个人电脑,也能用上顶级的大模型,这在之前是根本不敢想的。
这种狂欢,不仅仅是在硅谷,更是在全球的各个角落:从拉各斯到吉隆坡,从东南亚到非洲,无数预算有限的开发者,终于有机会用上顶级的 AI 能力了。之前,他们用不起闭源的 API,也买不起顶级的显卡,只能用性能很差的小模型,现在,他们可以免费下载 V4,自己部署,用很低的成本,获得比肩闭源模型的能力。
比如,马来西亚的通讯部副部长,早就公开表示,他们国家的主权 AI 基础设施,将基于 DeepSeek 的技术构建,因为它开源、免费、强大,而且没有任何的限制,他们不需要依赖美国的巨头,就能建立自己的主权 AI。还有很多发展中国家,都在考虑用 DeepSeek 的模型,来构建自己的 AI 能力,因为这是他们唯一能负担得起的选项。
普惠全球:让中小企业也能用得起顶级 AI
对于中小企业来说,V4 的开源,更是救命的福音:
-
之前,顶级的 AI 能力,只有闭源的 API,中小企业用不起,而且不能私有化部署,数据安全有风险,比如金融、医疗这些敏感行业,根本不敢把自己的数据传给闭源的 API,因为怕数据泄露,怕合规问题。
-
现在,有了 V4,中小企业可以自己部署模型,数据完全存在自己的服务器里,不需要传给任何人,完全满足合规的要求,而且成本只有原来的 1/10,甚至 1/20。
-
比如,一个做金融风控的公司,之前用闭源的 API,每个月要花几十万的调用费,还担心客户的数据泄露,现在,他们可以自己部署 V4,只需要几台服务器,成本不到原来的十分之一,而且数据完全自己掌控,安全又合规。
-
再比如,一个做医疗 AI 的创业公司,之前因为数据的问题,不能用闭源的 API,自己训练模型又没有能力,现在,他们可以直接拿 V4 的权重,微调一下,就能做出自己的医疗 AI 模型,成本只有原来的几十分之一。
这就是开源的普惠性,它把原本只有巨头才能享有的顶级 AI 能力,变成了所有人都能用的公共产品,让无数的中小企业、无数的发展中国家,都能享受到 AI 的红利,这会激发无数的创新,让整个 AI 行业的发展速度,加快好几倍。
五、价格革命:把 AI 的成本打到底,让人人用得起顶级 AI
除了开源,DeepSeek 的另一个杀器,就是极致的性价比,这一次,V4 再次把大模型的价格打到底,让顶级的 AI 能力,变成了人人都能用得起的日用品。
极致的 API 价格,仅为闭源模型的 1/20
我们来看看 V4 的 API 价格:
-
V4-Pro:输入 1 元 / 百万 token,输出 12 元 / 百万 token。
-
V4-Flash:输入 0.2 元 / 百万 token,输出 2 元 / 百万 token。
我们来对比一下同期的顶级闭源模型的价格:
-
GPT-5.5:输入 10 美元 / 百万 token,输出 30 美元 / 百万 token,也就是输入约 70 元,输出约 210 元。
-
Claude Opus 4.7:输入 15 美元 / 百万 token,输出 45 美元 / 百万 token,也就是输入约 105 元,输出约 315 元。
-
Gemini 3.1 Pro:输入 8 美元 / 百万 token,输出 24 美元 / 百万 token,也就是输入约 56 元,输出约 168 元。
对比下来,DeepSeek V4-Pro 的价格,仅仅是 GPT-5.5 的 1/20,是 Claude Opus 的 1/15,是 Gemini 3.1 Pro 的 1/14!而 V4-Flash 的价格,更是只有闭源模型的 1/100 不到!
这意味着什么?比如,你要处理一个百万 token 的长文档,用 GPT-5.5 需要花费 280 元,用 Claude 需要 420 元,而用 DeepSeek V4-Pro,只需要 13 元,用 Flash 的话,只需要 2.2 元!这个差距,是数量级的差距,直接把 AI 的成本,从奢侈品的级别,打到了日用品的级别。
之前,很多企业因为成本的问题,不敢用长上下文模型,不敢大规模调用 AI,现在,成本降了这么多,他们可以放心大胆地用了。比如,一个做客服的公司,之前用闭源的 API,每个月要花几百万,现在用 DeepSeek 的 API,只需要几万块,成本直接降了 99%,这直接让他们的业务模式都变了,之前做不起的业务,现在都能做了。
未来还有更大的降价空间,二次价格战即将到来
更重要的是,现在的价格,还不是最终的价格!DeepSeek 在发布的时候明确表示,目前因为高端算力的限制,Pro 版本的服务吞吐有限,所以价格还有点高,等下半年华为昇腾 950 超节点批量上市之后,Pro 的价格会大幅下调!
昇腾 950 超节点,是什么?它是华为新一代的算力节点,通过更高速的互联协议,解决了 MoE 模型跨卡通信的延迟问题,配合 DeepSeek 的 MegaMoE2 内核,能够把 V4 的推理效率再提升好几倍,从而把成本再降下来。
这意味着,下半年,V4-Pro 的价格,可能会降到现在 V4-Flash 的水平,也就是输入 0.2 元,输出 2 元!到那个时候,顶级的旗舰模型的价格,就和之前的轻量模型一样了,这就是 DeepSeek 的二次价格战,又一次把行业的成本底线,打到底。
我们可以想象一下,到那个时候,顶级的 AI 能力,每百万 token 只需要几块钱,也就是说,你处理一整本《三体》,只需要几分钱,这是什么概念?这意味着,AI 的成本,已经低到可以忽略不计了,不管是个人还是企业,都能毫无压力地用,这就是真正的 AI 普惠。
成本的下探,将引爆整个行业的创新
价格的下探,带来的不仅仅是用户的省钱,更是整个行业的创新爆发:
-
之前,很多创新的想法,因为成本的问题,根本做不起来,比如,做一个全栈的 Agent,需要大规模调用模型,成本高到离谱,根本商业化不了。现在,成本降了,这些想法都能落地了。
-
之前,开发者不敢用长上下文,不敢用复杂的推理,因为太贵了,现在,他们可以随便用,随便试,这会催生无数的新应用、新场景。
-
之前,AI 只能用在一些高价值的场景,比如金融、医疗,现在,成本降了,AI 可以用在所有的场景,比如教育、娱乐、生活,每个人都能享受到 AI 的红利。
这就像当年的智能手机,当手机的价格从几万降到几千,再到几百,整个移动互联网的创新就爆发了,现在,AI 的成本,正在经历同样的过程,当成本低到所有人都能用得起的时候,整个 AI 行业的创新大爆炸,才真正开始。
六、产业重构:从算力自主到全球软实力输出
DeepSeek-V4 的发布,不仅仅是一个模型的发布,更是整个 AI 产业格局的重构,它从算力自主、开源生态、全球软实力、Agent 底座等多个层面,彻底改变了整个行业的格局。
国产算力的突破:打破英伟达的垄断,实现自主可控
长期以来,国内的大模型行业,一直依赖英伟达的 GPU,不管是训练还是推理,都离不开英伟达的芯片,这不仅成本高,而且还面临着供应链的风险,一旦美国禁运,整个行业就会停摆。而国产的芯片,一直被认为跑不了大模型,尤其是超大规模的 MoE 模型,因为通信、算力的问题,很难适配。
而 DeepSeek 和华为昇腾的合作,彻底打破了这个魔咒:
-
DeepSeek 不仅在训练中使用了昇腾的国产芯片,更在推理架构上做了深度的适配,开发了 MegaMoE2 融合内核,在昇腾平台上实现了 1.5 倍到 1.7 倍的推理加速,完美解决了 MoE 模型的跨卡通信问题。
-
这意味着,国产的芯片,完全可以跑超大规模的大模型,而且性能还很不错,完全能够满足需求,不需要依赖英伟达的芯片。
-
这就证明了,只要软件适配做好了,国产芯片完全可以支撑起大模型的需求,整个国产算力的生态,终于跑通了。
这意味着,我们终于实现了算力的自主可控:企业可以用国产的芯片,国产的模型,完全自己掌控,不需要依赖国外的技术,不需要担心禁运,不需要担心卡脖子,这对国家安全,对产业的自主可控,意义重大。
而且,这也带动了国产算力的发展,之前,很多人不敢用国产芯片,因为没有软件适配,现在,DeepSeek 已经做好了适配,证明了国产芯片的能力,越来越多的企业会开始用国产芯片,这会推动国产芯片的快速发展,形成一个良性的循环,整个国产算力的生态,会越来越成熟。
开源生态的重构:从 Llama 一家独大,到中国标准引领
之前,全球的开源大模型生态,一直是 Meta 的 Llama 一家独大,几乎所有的开发者,所有的应用,都是基于 Llama 做的,Llama 的标准,就是整个开源生态的标准,整个生态的话语权,都掌握在美国的公司手里。
而 DeepSeek-V4 的出现,彻底打破了这个格局:
-
V4 的性能,远超 Llama 3,而且协议更宽松,成本更低,越来越多的开发者,开始从 Llama 迁移到 DeepSeek,基于 DeepSeek 做开发。
-
越来越多的工具、框架、应用,开始适配 DeepSeek 的模型,整个开源生态,开始围绕 DeepSeek 建立起来。
-
中国的开源技术,第一次成为了全球开源生态的标杆,第一次掌握了开源生态的话语权,这是前所未有的突破。
这意味着,全球的开源 AI 生态,从之前的美国一家独大,变成了多极化的格局,而中国的技术,成为了其中最重要的一极,我们不再是跟随者,而是引领者,我们的技术,成为了全球的标准。
全球软实力的输出:AI 领域的 “安卓”,普惠全球
DeepSeek 的开源模型,就像当年的安卓系统一样,免费、开源,给全球的开发者提供了一个开放的平台,帮助无数的国家和地区,建立自己的 AI 能力,这就是中国的软实力输出。
之前,全球的 AI 能力,都掌握在美国的巨头手里,发展中国家,要么用他们的 API,要么根本用不起 AI,没有任何的自主权,他们的数据,他们的 AI,都要被美国的巨头掌控。
而现在,DeepSeek 的开源模型,给了他们一个新的选择:他们可以免费下载模型,自己部署,自己掌控,不需要依赖美国的巨头,不需要担心数据安全,不需要担心卡脖子,他们可以建立自己的主权 AI,自己的 AI 基础设施。
比如马来西亚,比如非洲的很多国家,比如东南亚的很多国家,他们都在开始用 DeepSeek 的模型,构建自己的 AI 能力,这不仅帮助他们实现了 AI 的普及,更提升了中国的全球影响力,让全世界都看到,中国的技术,是开放的,是普惠的,是愿意帮助全世界的,这就是最好的软实力输出。
Agent 时代的底座:中国掌握下一代 AI 的主动权
现在,AI 行业已经进入了 Agent 时代,Agent 将成为下一代 AI 的核心,而 Agent 的底座,就是大模型,谁掌握了 Agent 的底座,谁就掌握了下一代 AI 的主动权。
而 DeepSeek-V4,正好就是 Agent 时代的完美底座:它有百万上下文,有强推理能力,有低成本,有开源,所有 Agent 需要的特性,它都有。
这意味着,全球的 Agent 开发者,都会基于 V4 来构建自己的产品,整个 Agent 的生态,都会围绕 DeepSeek 建立起来,中国的团队,第一次掌握了下一代 AI 的主动权,我们不再是跟随者,而是引领者,我们将带领整个行业,进入 Agent 的新时代。
七、挑战与未来:仍有差距,但未来可期
当然,我们也要清醒地认识到,V4 并不是完美的,它仍然存在着一些不足,和最顶尖的闭源模型,仍然存在着一定的差距。
DeepSeek 自己也在技术报告中坦诚地承认了这些不足:
-
首先,和最顶尖的闭源模型,仍然有着 3 到 6 个月的差距,比如 Claude Opus 的思考模式,GPT-5.5 的长周期 Agent 能力,V4 还有一定的差距,还需要继续追赶。
-
其次,在创意写作、头脑风暴这些场景,V4 的回答还有点 “太干”,太正式,缺乏 GPT 和 Claude 那种灵动感,还有优化的空间。
-
第三,V4 目前还是纯文本的模型,还没有加入多模态的能力,而现在的主流模型,都已经支持图像、视频的多模态能力了,这是 V4 接下来需要补上的短板。
-
第四,为了追求长上下文的效率,V4 的架构设计比较激进,有很多经验性的组件,整体比较复杂,部署的难度有点高,未来需要精简架构,让它更容易部署。
不过,这些不足,都是发展中的问题,DeepSeek 也已经明确了未来的研究方向:
-
精简架构,把那些经验性的组件去掉,让架构更简单,更容易部署。
-
加入多模态能力,支持图像、视频的理解,跟上行业的步伐。
-
探索更稀疏的模型,进一步降低成本,提升效率。
-
强化长周期的 Agent 任务,优化 Agent 的能力,让它能处理更复杂、更长周期的任务。
-
研究训练稳定性的基础理论,进一步提升大模型的训练效率。
我们有理由相信,随着这些方向的推进,DeepSeek 会很快补上这些短板,进一步缩小和闭源模型的差距,甚至实现超越。
结语:中国 AI 的新时代,从开源领先开始
DeepSeek-V4 的发布,是中国 AI 发展的一个里程碑,它标志着,中国的 AI 团队,第一次在开源大模型领域,实现了真正的全球领先。
在过去的很多年里,我们一直是跟随者,我们跟着美国的技术走,我们用他们的模型,他们的芯片,他们的标准,我们努力追赶,却始终差了一步。
而现在,DeepSeek 用自己的技术创新,用自己的长期主义,打破了这个局面,我们第一次,在底层技术上,实现了原创的突破,我们第一次,把开源模型的能力,推到了全球顶尖的位置,我们第一次,用开放、普惠的方式,把顶级的 AI 能力,送到了全球每一个开发者的手中。
这背后,是 DeepSeek 团队的坚持,是他们不被资本绑架,不被短期的利益诱惑,专注于技术,专注于长期的创新,是他们 “不诱于誉,不恐于诽,率道而行,端然正己” 的初心。
DeepSeek-V4 的发布,不是终点,而是一个新的起点,它开启了一个新的时代:一个开源普惠的时代,一个全球共赢的时代,一个中国 AI 引领全球的时代。
在这个时代里,AI 不再是巨头的垄断品,不再是奢侈品,它将成为所有人都能用得起的公共产品,它的红利,将普惠每一个人,不管你是硅谷的精英,还是非洲的开发者,不管你是巨头的工程师,还是普通的个人用户,你都能享受到 AI 的力量。
我们有理由相信,在未来,DeepSeek 会继续带领中国 AI,走向更高的高度,会有更多的中国团队,做出更多的原创技术,会有更多的中国技术,引领全球的行业,我们终将实现,让 AI 的光芒,照亮全世界的每一个角落。




先交朋友,后谈业务。
我是谁:立志做摄影界数据最溜的,数据界段子写得最好的,段子界跑步最厉害的,跑步界文章写得最赞的,文章界厨艺最哇塞的。
服务内容:永佳数据新商业,为您量身定做数字化解决方案。
培训服务:
企业数字化转型战略执行
数据驱动业务:从战略到落地
数据资产入资产负债表培训
大数据时代的精准营销 | 财务数字化
释放现金流之供应链数字化
咨询服务:
企业数据治理 | 数据体系搭建
销售运营体系搭建
经营报表体系设计
数据模型设计 | BI系统建设咨询
业务范围:立足上海,走遍全国,走向世界。
