夜雨聆风
夜雨聆风





【统计分析软件SPSS】55、比较数据集
链接:https://pan.baidu.com/s/15r0rLWkJlcecUvBPKZo_MQ?pwd=mnsj提取码:mnsj
由于微信公众号已发布文章的内容及排版顺序无法二次编辑,为了方便大家后续查阅、检索,同时便于我对内容进行补充更新与完善,我会将所有已发布的推文,在个人网站上以结构化文档的形式重新整理、归档。欢迎前往查看:
https://www.mizhushare.com/docs/
比较数据集功能主要用于将当前活动数据集与另一个已打开的数据集(或外部 .sav 文件)进行对比。它不仅能比较数据值,还能比较数据字典(如变量标签、值标签等)。主要用于:
-
数据录入校验:验证双盲录入的数据是否一致,快速定位录入错误。
-
数据版本对比:比较不同时期或不同版本的数据文件,找出差异。 -
属性检查:检查两个数据集的变量属性(如测量尺度、缺失值定义)是否一致。

-
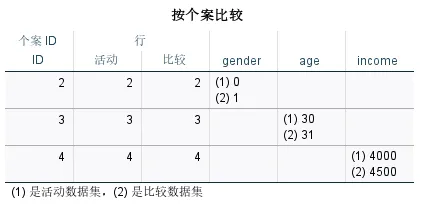
ID=2 的性别不同;
-
ID=3 的变量不同;
-
ID=4 的收入不同。
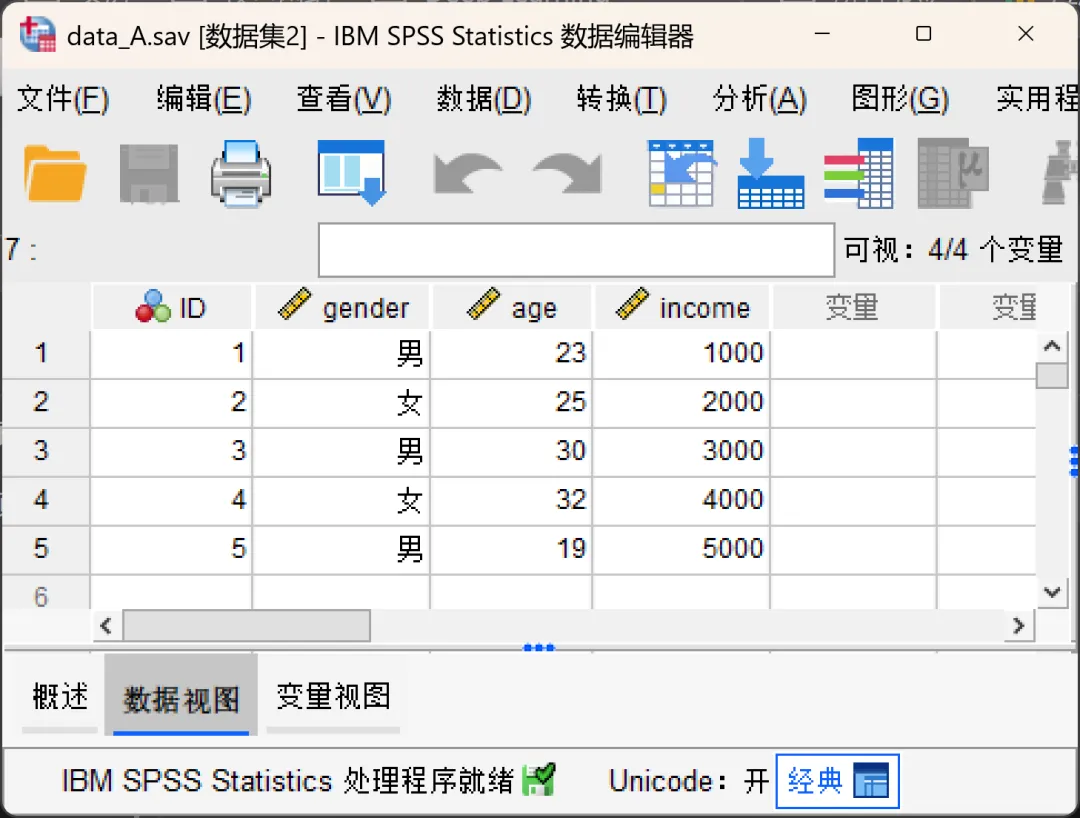
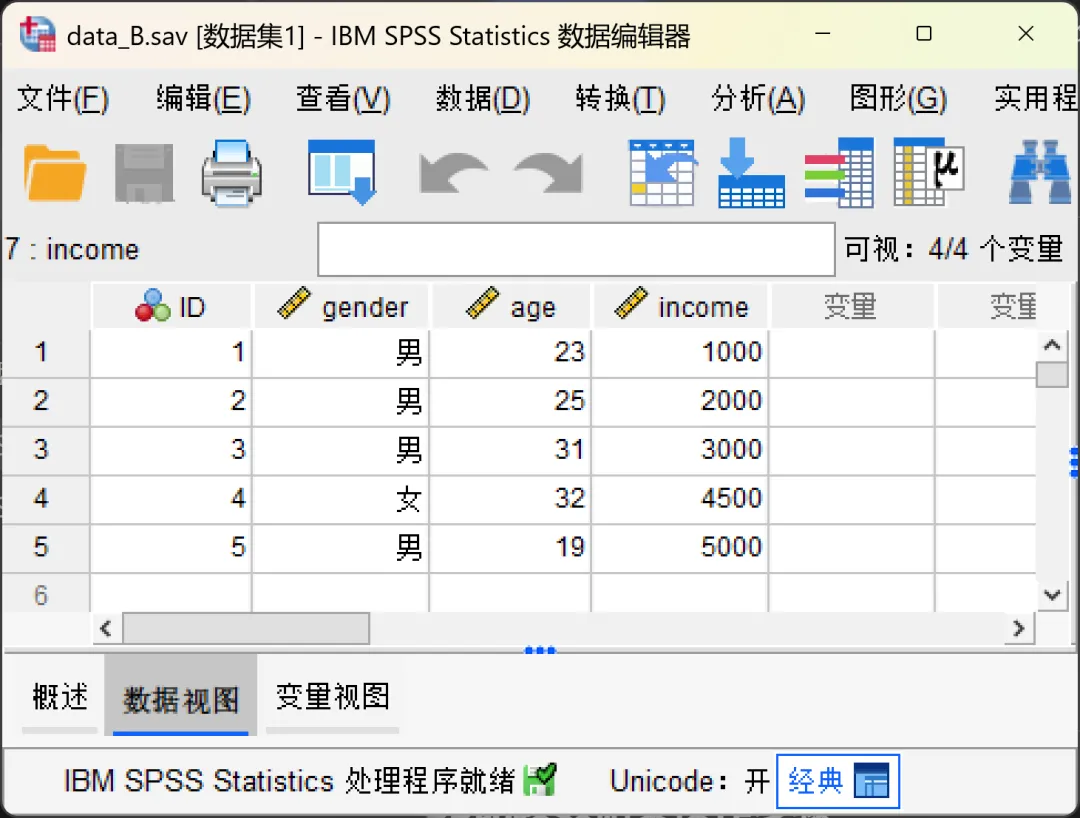
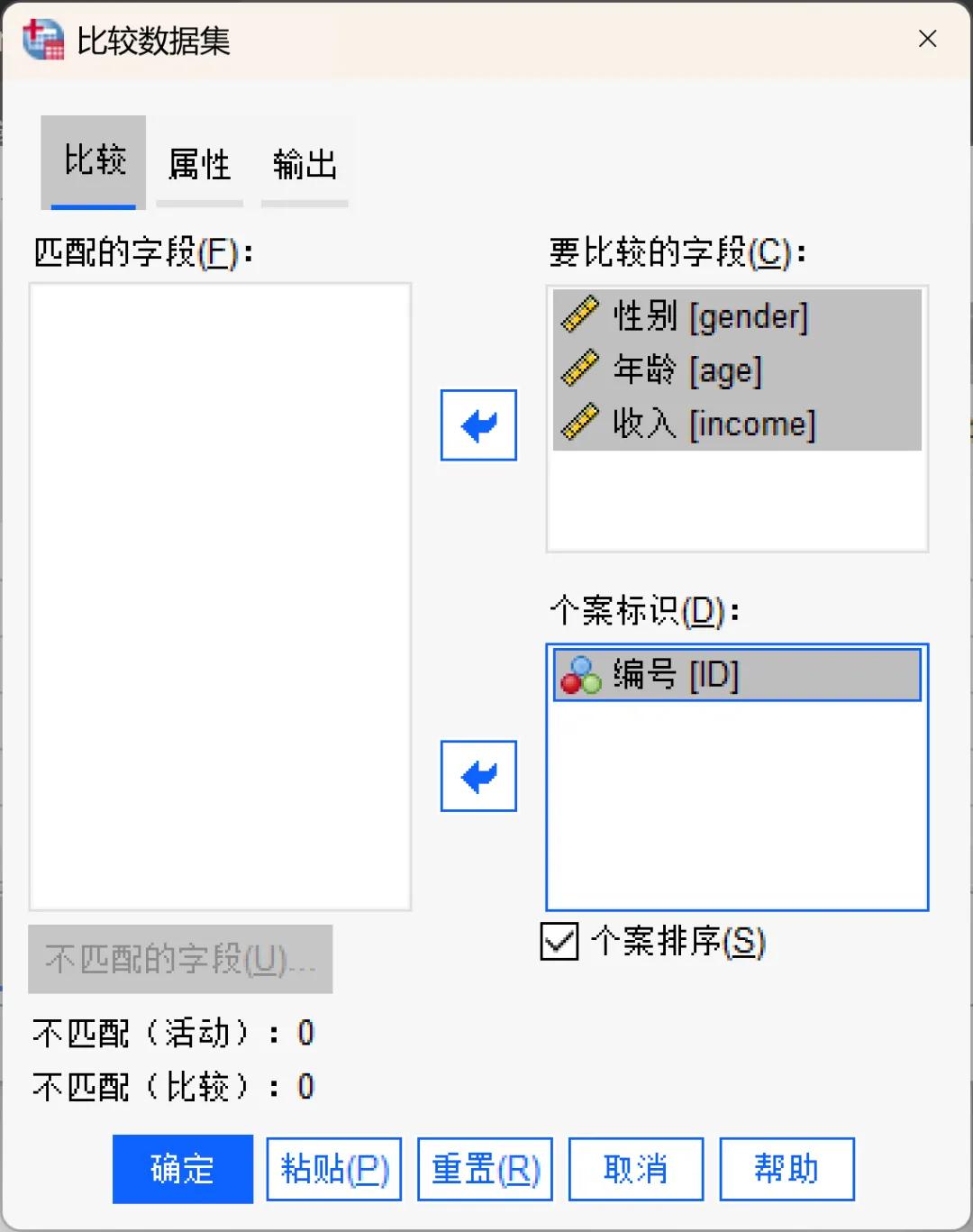
点击顶部菜单栏的【数据→比较数据集】,在打开的对话框进行相应设置。
-
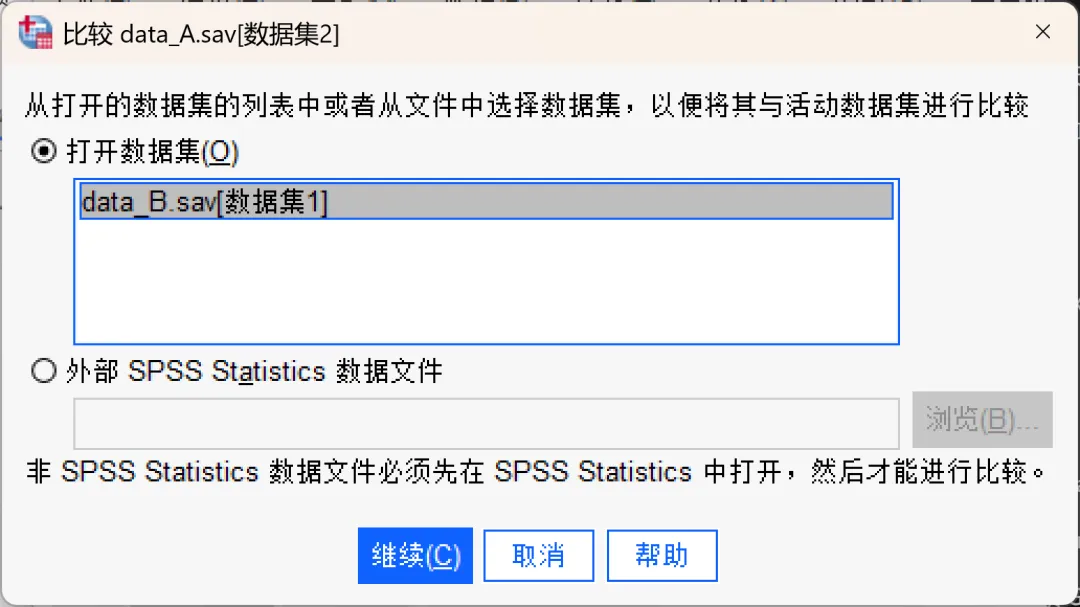
选择想要与活动数据集进行比较的数据集或数据文件。
-
比较选项卡:
匹配的字段:显示在两个数据集中名称相同且基本类型(字符串或数值)也相同的字段列表。
-
不匹配的字段:点击「不匹配的字段」按钮,在弹出的对话框中会显示两个数据集中未匹配的字段(变量)列表。未匹配的字段是指在其中一个数据集中缺失,或者在两个文件中基本类型(字符串或数值)不一致的字段。这些未匹配的字段将被排除在两个数据集的比较之外。
-
要比较的字段:对两个数据集的比较仅基于所选的一个或多个要比较的字段(变量)。
-
个案标识:个案标识字段(即个案 ID)用于唯一确定数据集中的每一条记录。若指定了多个字段作为个案 ID,则这些字段的唯一值组合将共同标识一个个案。如果未指定任何个案 ID 字段,系统将默认采用基于行号顺序的比对模式。如果指定了个案 ID 字段,为了确保比对的准确性,需勾选 「个案排序」选项,系统将自动在比对前对两个数据集按个案 ID 进行重新排序。
-
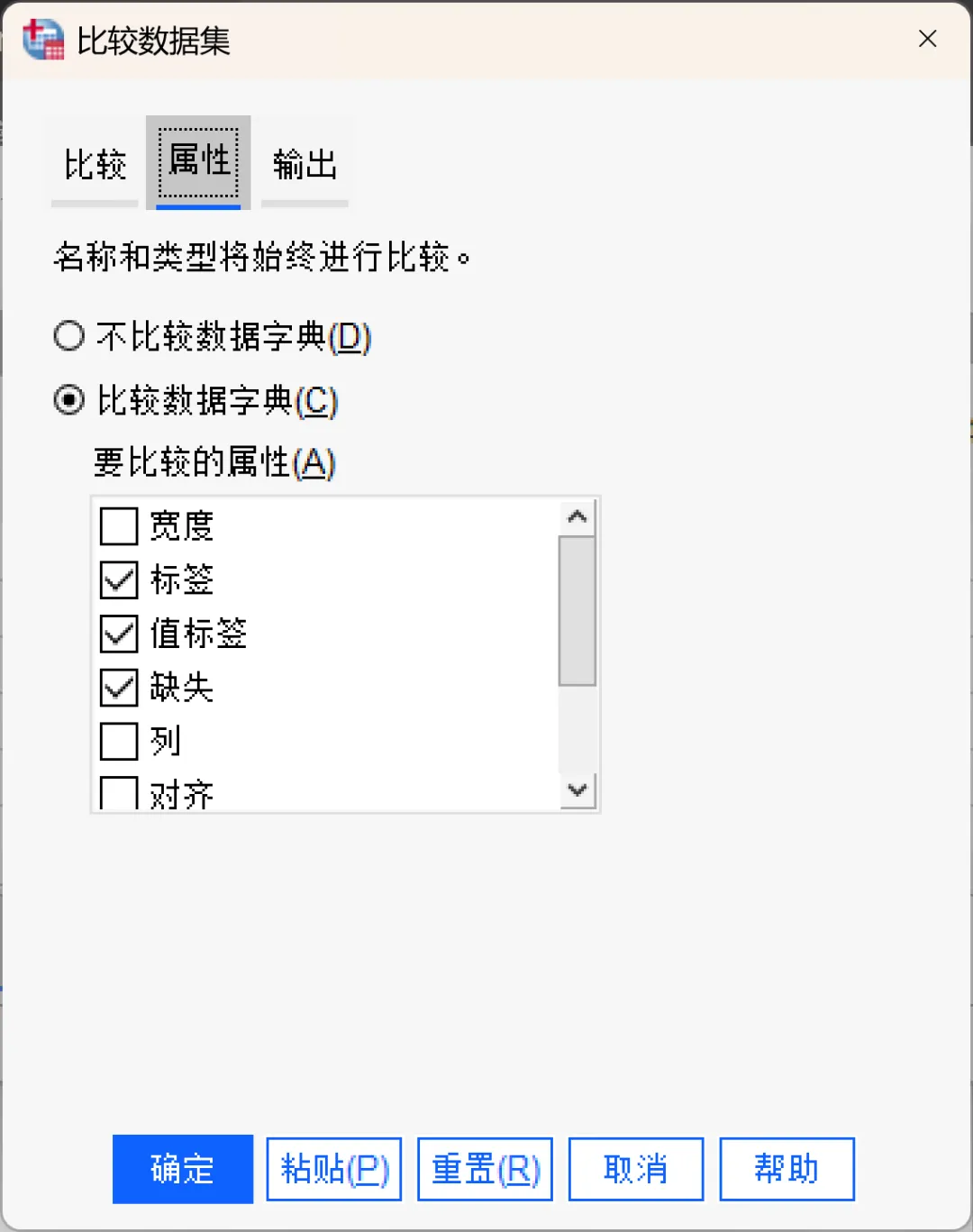
属性选项卡:
默认情况下,仅比较数据值,而不会比较字段属性(数据字典属性)。如需比较字段属性,勾选「比较数据字典」选项,在列表中选择想要比较的属性即可。
-
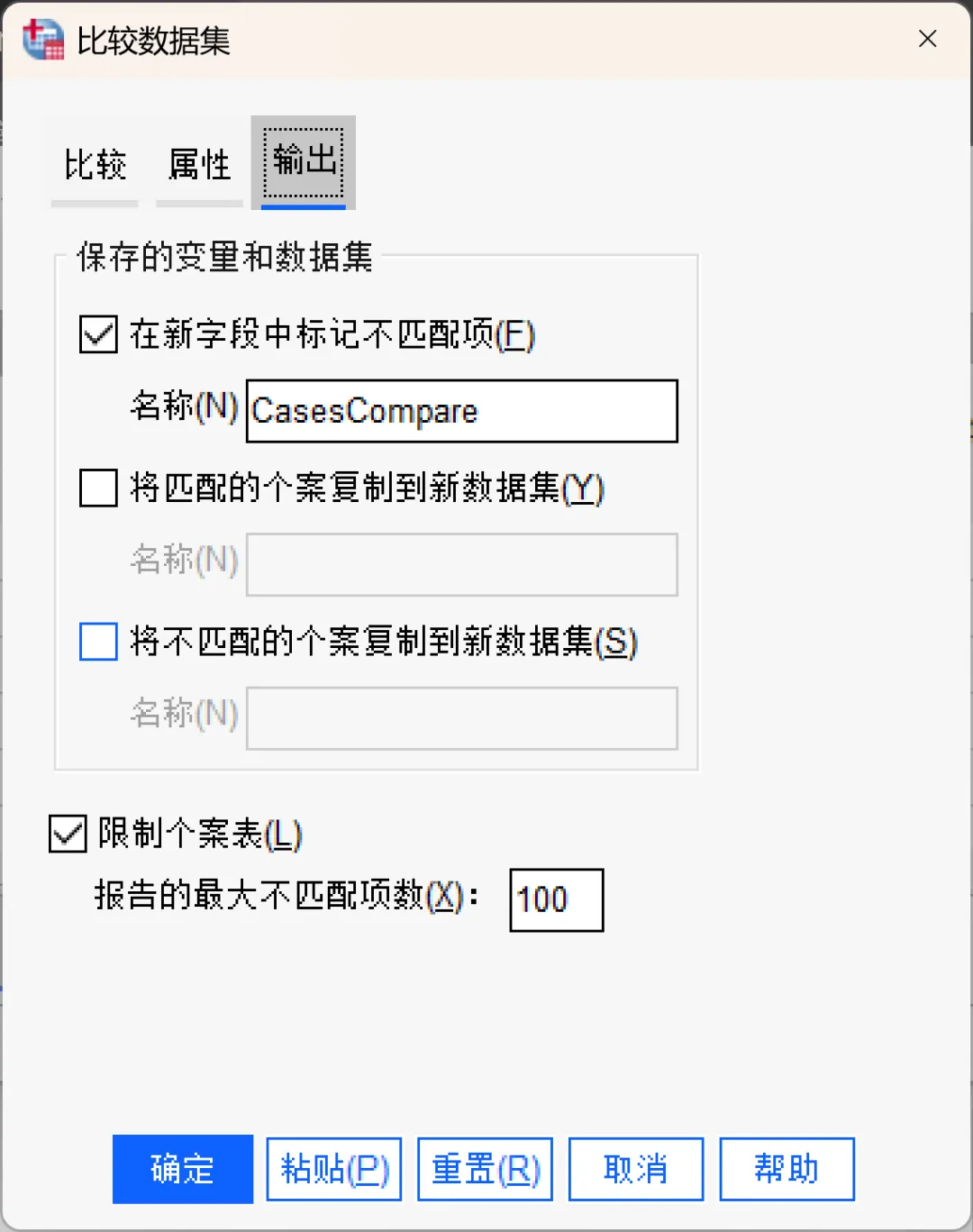
输出选项卡:
默认情况下,比较数据集功能会在活动数据集中创建一个新字段来标识不匹配项,并生成一个表格,列出前100个不匹配项的详细信息。可以在该选项卡更改输出选项。
-
在新字段中标记不匹配项:在活动数据集中创建一个新字段来标识不匹配项。新字段的值为1表示存在差异;值为0表示所有值都相同;值为-1表示活动数据集中存在,但在另一个数据集中不存在的个案(记录)。
-
将匹配的个案复制到新数据集:勾选后将创建一个新数据集,其中仅包含在另一个数据集中有匹配值的活动数据集个案(记录)。
-
将不匹配的个案复制到新数据集:勾选后将创建一个新数据集,其中仅包含在另一个数据集中有不同值的活动数据集个案(记录)。
-
限制个案表:对于存在于活动数据集中,也存在于另一个数据集且基本类型(数值或字符串)相同的个案(记录),输出表格会提供每个个案的不匹配值详细信息。默认情况下,该表格仅限于前100个不匹配项,可以指定其他数值,或取消勾选此项以包含所有不匹配项。

对比完成后,SPSS会在输出窗口和活动数据集同时呈现结果。
-
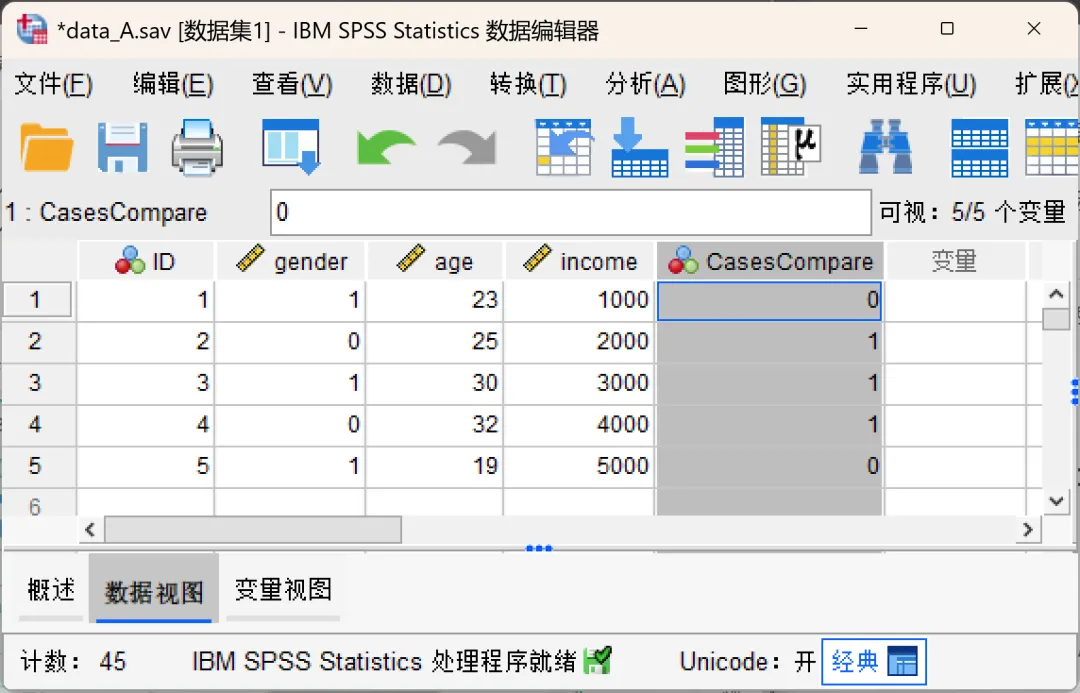
数据集内的标识变量:
活动数据集中会增一个标识变量(默认名为CasesCompare),数值为1的个案就是存在差异的个案,本次示例中ID2、ID3、ID4对应的标识变量为1,精准定位存在差异的个案。
-
输出窗口详细差异报告:
比较摘要表格展示了参与比对的两个数据集的基本信息。

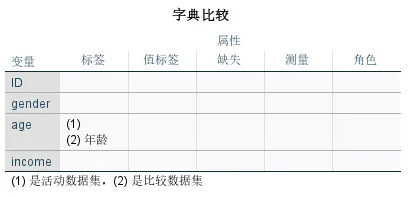
字典比较表格展示了两个数据集中变量的对比结果。该表仅在「属性」选项卡中勾选「比较数据字典」时才会出现。若无差异则显示空白,有差异会标注具体不同点(如 age 的标签不同)。
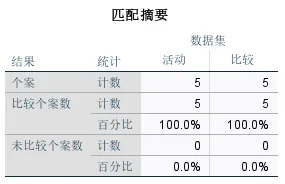
匹配摘要表格展示了成功匹配的个案数量及比例。
不匹配(按个案排列)表格从“个案维度”汇总有多少条记录存在不匹配。

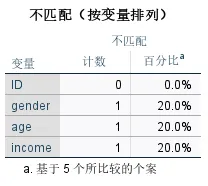
不匹配(按变量排列)表格从“变量维度”统计每个字段出现不匹配的次数和比例。
按个案比较表格逐条列出所有存在不匹配的个案及其具体差异值。