 夜雨聆风
夜雨聆风





AI 工具为什么越来越贵?Google 新 TPU 透露了一个底层答案
以后你用 AI 工具,最先抱怨的可能不是“它不聪明”。
而是:
怎么高级功能又要加钱?
怎么 Agent 跑一次要等这么久?
怎么一开始免费,后来就开始限次数?
这些表面上是产品体验,往底下看,其实都是算力账单。
Google 这次发布第八代 TPU,我觉得真正值得看的,不是又多了两颗芯片,而是一个更大的变化:
接下来 AI 公司拼的,不只是有没有最强芯片,而是会不会把不同的活,分给不同的机器。
以前大家聊 AI 算力,很容易聊成一件事:谁更猛。
谁训练大模型更快,谁能堆更多卡,谁能让模型参数继续往上走。
但 Agent 真的跑起来以后,这个问题会变得更像一家公司怎么排班。
有人适合接电话。
有人适合盯项目。
有人适合做高强度研发。
你不能把所有活都丢给同一个人,除非你钱很多,而且不怕效率低。
AI 现在也开始遇到这个问题。
真正变的,不是芯片,而是 AI 的工作方式
普通聊天模型,是一问一答。
你问一句,它回一句。中间就算很复杂,外面看起来也还是一次请求、一次回答。
但 Agent 不一样。
Agent 要做的事情更像一个小员工:
-
先理解任务 -
再拆步骤 -
中间调用工具 -
看结果对不对 -
不对就改 -
改完还要继续跑
这就麻烦了。
因为它不再是一次性回答,而是一串连续动作。
一次 Agent 任务背后,可能有十几次模型调用,几十次工具交互,还会把历史结果反复塞回上下文里。
以前你以为自己只是让 AI “帮我做个东西”。
账单系统看到的可能是:这个人放出了一只小耗电兽。
所以到了 Agent 时代,算力问题不只是“模型够不够聪明”。
它还会变成:
什么任务要快?
什么任务要省?
什么任务要能长时间稳定跑?
什么任务值得动用最强的机器?
这才是 Google 这次新 TPU 背后更有意思的地方。

Google 这次不是在讲一颗芯片
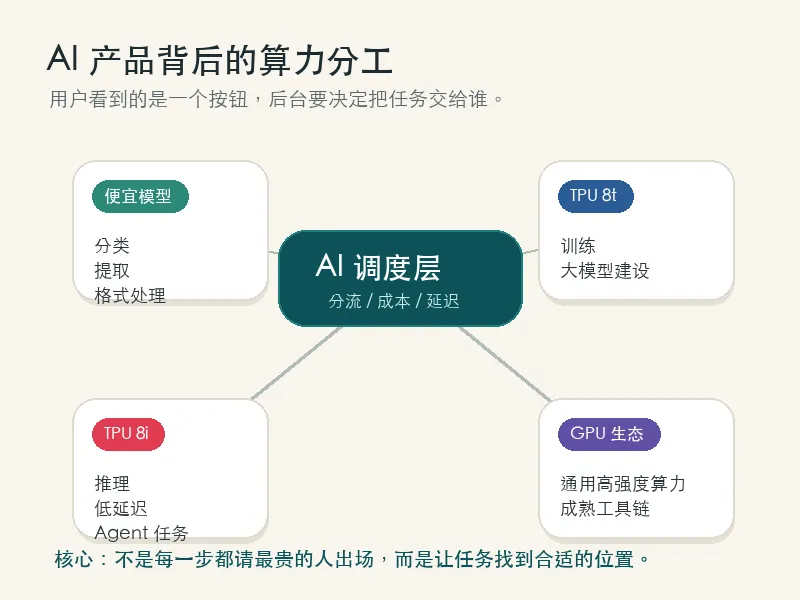
Google 官方这次把第八代 TPU 拆成了两个方向:TPU 8t 和 TPU 8i。
官方说法里,TPU 8t 更偏训练,TPU 8i 更偏推理和面向 Agent 工作负载。
这里不用陷进参数里。
你可以先把它理解成一个很简单的分工:
有的机器负责“把 AI 训练出来”,有的机器负责“让 AI 在真实产品里干活”。
这两件事不是一回事。
训练像造人。
推理像上班。
过去大家更爱聊造人,因为大模型训练听起来更宏大,更像军备竞赛。
但真正接近用户的,是上班那一段。
你打开一个 AI 写作工具,让它帮你改稿。
你打开一个编程 Agent,让它读文件、改代码、跑测试。
你让一个企业助手查数据、写报告、补表格、发邮件。
这些都不是模型实验室里的展示动作,而是每天会重复发生的生产动作。
生产动作一多,问题就变了。
它不只是要强,还要便宜、稳定、可调度。
这就像公司招人。
你当然希望每个人都很厉害,但如果所有杂活都让首席科学家干,公司很快就会破产。
AI 公司也一样。
如果所有请求都默认丢给最贵、最强、最耗资源的算力,产品迟早会变成一个看起来很聪明、实际上没人敢大规模用的奢侈品。
Nvidia 还在涨,但 Google 要的是另一种控制权
同一时间,Nvidia 市值冲过 5 万亿美元,这个数字当然很夸张。
但这件事不适合只看成股价新闻。
更值得看的,是市场仍然在奖励 AI 算力中心。
谁掌握底层算力,谁就更接近 AI 产业的收费口。
这也是为什么 Google 一定要继续做 TPU。
不是因为它非要和 Nvidia 在所有场景里硬碰硬。
而是因为大厂越来越清楚一件事:
如果 AI 时代的核心成本都攥在别人手里,你的产品能力和价格空间都会被别人卡住。
这句话放在云厂商身上尤其明显。
云厂商卖的不只是服务器。
它卖的是一整套“让企业把 AI 跑起来”的能力。
当企业开始部署 Agent,云厂商就要回答三个问题:
第一,能不能跑得动。
第二,能不能跑得便宜。
第三,能不能针对不同任务做调度。
如果答案都要依赖外部芯片供应链,那这个生意就有点被动。
Google 做 TPU,本质上是在争一件事:
不要只卖 AI 应用层的门票,也要握住后台电闸。
对普通人来说,这会影响 AI 工具的价格和体验
这听起来像基础设施新闻,离普通用户很远。
其实不远。
你以后用到的 AI 工具,会越来越受底层算力分工影响。
为什么有些 Agent 很贵?
因为它不是回你一句话,而是在背后跑很多轮。
为什么有些功能只能给高级会员?
因为那部分调用真的贵,平台不可能无限补贴。
为什么有些 AI 工具一开始惊艳,后面开始限制次数?
因为展示 Demo 和承载真实用户,是两门生意。
Demo 只要好看。
产品要算账。
这也是今天这条新闻和我们普通人有关的地方。
AI 工具不可能永远只靠“更聪明”来竞争。
它迟早要进入更细的阶段:
-
哪些任务用便宜模型 -
哪些任务用强模型 -
哪些任务用专门芯片 -
哪些任务值得跑长流程 Agent -
哪些任务干脆不该自动化
表面上,这是 Google 发布 TPU。
往深一层看,这是 AI 公司在给未来的成本表重新分栏。
Agent 时代,拼的是“会不会分工”
这两年大家都在讲 Agent。
但 Agent 真正落地以后,第一批被放大的问题,未必是模型智力,而是成本和调度。
一个只会拼命调用最强模型的 Agent,看起来很高级。
但它可能也是最烧钱、最难商业化的 Agent。
真正成熟的 AI 系统,不会每一步都请最贵的人出场。
它会知道:
哪一步需要便宜模型先筛一遍。
哪一步需要专门芯片扛吞吐。
哪一步必须交给最强模型做判断。
哪一步应该直接停下来,让人类接手。
这就是算力分工。
Google 这次 TPU 更新,真正的信号就在这里。
AI 进入 Agent 时代后,底层竞争会从“拼肌肉”走向“拼分工”。
谁能把不同任务放到更合适的位置,谁就更有机会把 AI 从好看的 Demo,变成真的能长期跑的生产系统。
最后可能会发现,AI 时代最贵的不是模型聪明。
最贵的是你不知道该让哪台机器,在什么时候,干哪一件事。
所以以后你看到一个 AI 工具涨价、限次数、分会员档位,不要只理解成厂商想多收钱。
更深一层看,是 Agent 终于从演示视频走进真实产品。
真实产品不只要聪明,还要能算得过账。