 夜雨聆风
夜雨聆风





DeepSeek-V4炸场,OpenClaw被官方点名!
昨天凌晨,DeepSeek发布了V4。
没有盛大的发布会,没有提前预热,就是一个官方公告,加一篇公众号文章,但内容却把整个模型圈炸了。
一句话定性:DeepSeek-V4-Pro,开源最强编程模型,没有之一。
MoE架构:参数量大,不等于贵
先说架构。
V4用的还是MoE(混合专家架构)。这东西出来有段时间了,但很多人对它的理解还停留在”参数量大”这个层面。
但其实这个季节是错的,MoE的核心不是大,是省。
传统Dense模型,每次推理要激活全部参数。100B的模型,推理一次就跑100B的计算量,我们的钱就是这样烧掉的。
但是MoE不一样。它有多个”专家”网络,每次推理只根据需要激活其中一部分。
V4总参数量671B,听起来吓人。但每次推理只激活49B的计算量。
看清楚了,仅仅是49B,不是671B,就是49B。
这意味着DeepSeek可以用比其他671B模型低得多的成本,跑出接近甚至持平的效果。
官方原话:”每次推理只消耗49B的计算量,效率大幅提升。”
如果真如官方所说,那这能帮我们这些重度AI用户省下不少的token费用。
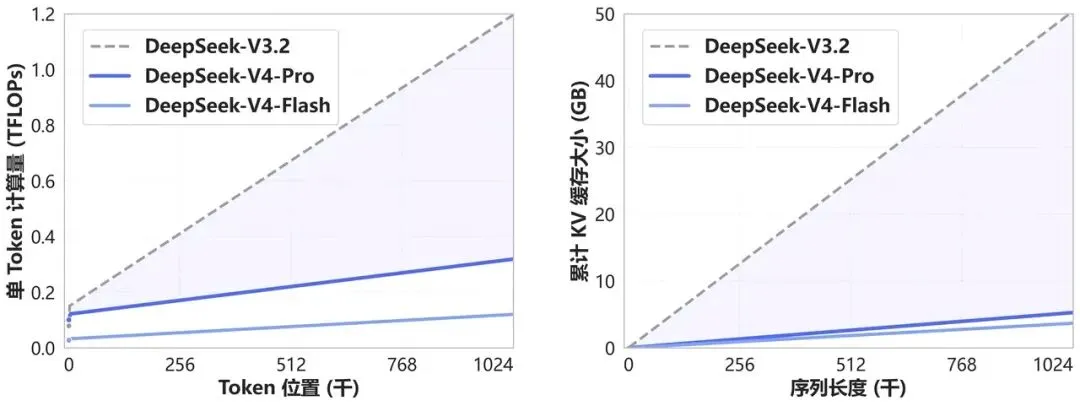
mHC:1M上下文,计算量只增加27%
DeepSeek-V4 拥有百万字超长上下文。
100万个token,是什么含义呢?相当于可以丢一整本《战争与和平》进去,让模型基于整本书回答问题。代码库再大,塞进去也没压力。
但是我们都知道上下文越长,计算量越大。标准Attention的计算复杂度是O(n²),上下文翻倍,计算量不是翻倍,是平方倍增长。
DeepSeek怎么解决的?DeepSeek-V4 开创了一种全新的注意力机制,在 token 维度进行压缩,结合 DSA 稀疏注注意力(DeepSeek Sparse Attention),实现了全球领先的长上下文能力,并且相比于传统方法大幅降低了对计算和显存的需求。
他的核心思路是token压缩+稀疏注意力——不是每个token都去计算全局Attention,而是通过潜空间压缩,把冗余信息干掉。
根据官方的数据:实现1M上下文,对比V3.2,计算量只增加27%。
这是什么意思呢?相对于用传统Attention,1M上下文相对于128K,计算量增长将是天文数字。DeepSeek用mHC,硬生生的把这个数字压到了27%。
这直接是是架构层面的重新设计了,不仅仅是微调优化。
Muon优化器:二阶武器,DeepSeek第一个跑通
优化器是训练环节最容易被忽略的组件。平时大家都关注参数规模、上下文长度,优化器这种”幕后角色”很少被讨论。
但DeepSeek在V4里用了一个新东西:Muon。
Muon是二阶优化器。Adam系列是一阶的,靠梯度方向做更新。听起来差不多,但二阶优化器考虑的是梯度的梯度——更精准的方向,更快的收敛速度。
好处很明显,但是代价也很突出:更难训练。二阶的计算量比一阶大得多,调参也更加复杂。因此即使业界都知道Muon好,但一直没人真正把它跑通在大规模训练上。
但是DeepSeek偏偏就这么干了。
官方说:用Muon优化器,把32T tokens跑完了。3.2万亿个token。行业里很多模型训练到1T tokens就开始收敛,DeepSeek跑了32T。
这不是堆数据,这是工程能力的体现。
编程能力:开源最强,但还有差距
理论和数据说了那么多,但是大家最关心的部分是实用效果。
官方对V4-Pro编程能力的定位:
• 开源最强,没有之一
• 内部使用体验:优于Sonnet 4.5
• 交付质量:接近Opus 4.6非思考模式
• 差距:仍落后Opus 4.6思考模式
拆开看:
“优于Sonnet 4.5″,Sonnet 4.5是Anthropic面向编程场景的主力模型,在开发者社区有很高口碑。V4-Pro能在体验层面超过它,开源模型里是第一次。
“接近Opus 4.6非思考模式”,Opus 4.6是OpenAI的通用旗舰,非思考模式就是直接输出,不走CoT推理。V4-Pro交付的代码质量,和Opus 4.6直接输出相当。
“仍落后Opus 4.6思考模式”——Opus 4.6开启思考模式后,推理能力再上一个台阶。V4-Pro在这个维度还有差距。
注意这里的技术细节:V4-Pro对标的是Opus 4.6的非思考模式,不是Sonnet 4.5。Sonnet是编程专用模型,Opus是通用旗舰。把编程能力做到接近通用旗舰的非思考模式输出,这个高度之前没有开源模型达到过。
OpenClaw被官方点名:不是套路,是工程级适配
官方在公告里点名适配了四款工具:OpenClaw、Claude Code、OpenCode、CodeBuddy。在代码任务、文档生成任务等方面表现均有显著提升。
这意味着DeepSeek针对这些工具的调用模式、上下文处理、输出格式做了定向调优。用这些工具调用V4 API,响应速度、流式输出的稳定性、工具调用的准确性,都会比通用接口更好。
举例来说,对OpenClaw🦞用户来说:你在OpenClaw里配置DeepSeek-V4-Pro作为模型,Agent模式下的代码生成、工具调用、任务拆解,都会比之前用V3更顺,影响时间更短,质量更高!
题外话:OpenClaw被官方点名,说明它在国内AI开发者里的渗透率已经到了DeepSeek愿意做专项适配的程度。这个信号也是值得我们关注的
API迁移:现在就开始,别等到七月
官方透露了一个容易被忽略但很重要的事:旧接口在2026年7月24日停用。
旧接口是 deepseek-chat 和 deepseek-reasoner。V4用的是新的接口格式。
还有四个月倒计时,听起来还有不少时间。但考虑到官方建议现在就开始迁移、很多项目里deepseek调用是硬编码的、接口格式变化可能涉及代码改造——现在就动手,总比七月临时抱佛脚强。
HuggingFace和ModelScope的权重已经放出来了,有能力的可以直接跑本地部署。不想折腾的,可以直接切API也没问题,V4的接口设计比V3更规范,对接更便捷。
最后
DeepSeek V4为什么又一次登上了热搜?因为它炸了开源模型的天花板。
利用MoE把推理成本打下来,mHC把上下文长度打上去,Muon把训练效率打上去。三件事同时发生,把开源和闭源的边界又往开源那边推了一截。
😀期待国产模型再一次发光发热!