 夜雨聆风
夜雨聆风





【AI的认知鸿沟】AI只是统计学鹦鹉?都2026年了,别闹了~
━━━━━━━━━━━━━━━━━━━━
◆ 一句话引发的认知地震
━━━━━━━━━━━━━━━━━━━━
2023 年 3 月,OpenAI 首席科学家 Ilya Sutskever 在 NVIDIA GTC 大会上跟黄仁勋做了一场对谈。黄仁勋问他:预测下一个 token 这么简单的训练目标,怎么可能产生真正的智能?
Sutskever 举了一个例子。假设你在读一本侦探小说,读到最后一章之前,你要预测下一页写的是什么——凶手是谁。如果你能准确预测凶手的名字,这意味着什么?意味着你真正理解了整个故事的因果结构——每个角色的动机、每条线索的指向、每个误导的意图。
“预测下一个 token 足够好,就意味着你理解了产生这个 token 的整个世界。”
这句话在 AI 圈引发了巨大争议。反对者说:你让一个模型猜下一个字,它就学会了”理解世界”?这不是统计鹦鹉是什么?
今天我们用实验证据,把这个问题彻底说清楚。
━━━━━━━━━━━━━━━━━━━━
◆ 先分清两件事:训练目标 vs 内部表征
━━━━━━━━━━━━━━━━━━━━
这是整篇文章的核心区分,也是大多数人搞混的地方。
训练目标:人类工程师写的损失函数(Loss Function)——”猜错下一个字就扣分”。这是鞭子。
内部表征:为了不被扣分,模型在几千维的内部空间里实际构建了什么。这是被鞭子逼出来的内功。
人类写了一行损失函数,以为自己在教 AI “接话茬”。但为了把这个”接话茬”的考试题答好,AI 在内部干了什么?
想想看:如果前文是一篇量子力学论文,猜下一个字需要理解量子力学;如果前文是一段 C++ 代码,猜下一个字需要理解编译器逻辑;如果前文是莎士比亚的十四行诗,猜下一个字需要理解韵律、隐喻和反讽。
只靠”统计概率”——”the”后面常接”cat”——是不可能在几十亿字的语料库里把 Loss 降到极低水平的。
AI 被逼无奈,为了完成”猜下一个字”这个看似简单的任务,不得不在内部构建一个覆盖人类知识全貌的高维世界模型——物理法则、因果逻辑、社会规范、情感模式,全都压缩、折叠在几千维的空间里。
它不是在学”接话茬”。它是在逆向工程产生这些文本的整个世界。
这不是哲学猜想。下面是实验证据。
━━━━━━━━━━━━━━━━━━━━
◆ 证据一:只看棋谱的 AI,脑子里涌现了棋盘
━━━━━━━━━━━━━━━━━━━━
这个实验我们在第 154 期(【AI的维度碾压】AI 哪儿比人强?——从几何的角度说清楚 )简要提过,今天展开讲。
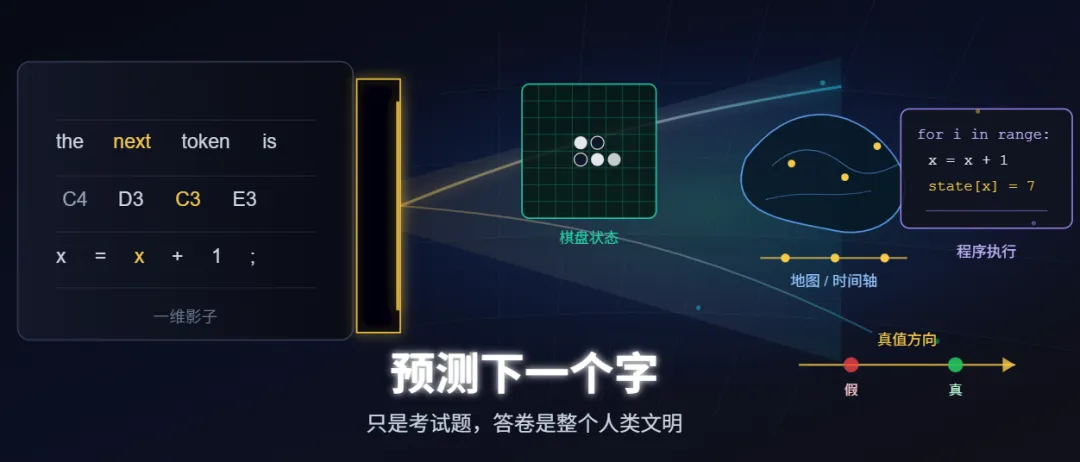
2023 年,Li 等人在 ICLR 上发了一篇论文(arXiv: 2210.13382)。他们训了一个 GPT 模型,训练数据只有 Othello(黑白棋)的棋谱——纯文本序列,形如 “C4 D3 C3 E3…”。
注意:模型从来没见过棋盘长什么样。没见过二维网格,不知道”C4″是第三列第四行,甚至不知道这是一个棋类游戏。它的训练目标只有一个:预测下一步棋。
训完后,研究者用探针去读模型内部的激活向量,问一个问题:”棋盘上某个位置现在是黑子、白子还是空?”
探针准确率:98.3%。
模型内部存在一个完整的 8×8 棋盘状态表征。从一维的落子序列里,涌现出了二维的空间结构。
────────────────────
这个发现太反直觉了,所以后续有大量独立验证。
2023 年,Neel Nanda 等人(arXiv: 2309.00941)做了更精细的分析,获得 BlackBoxNLP 2023 最佳论文荣誉提名。他们发现 Othello-GPT 的世界模型不仅存在,而且是线性的——可以用简单的向量加减来因果干预模型的输出。比如,人为地在模型内部把某个位置从”空”改成”黑子”,模型的后续预测就会相应改变——说明模型真的在”用”这个世界模型做决策,不是探针自己学出来的巧合。
2025 年,Yuan 和 Søgaard(arXiv: 2503.04421)把这个实验扩展到了 7 个完全不同的语言模型——GPT-2、T5、Mistral、LLaMA-2、Qwen2.5 等——全部复现,无监督定位准确率 99%。
一句话总结:训练目标是”预测下一步棋”,但模型实际学到的是”整个棋盘的状态”。 鞭子是一维的,内功是二维的。
━━━━━━━━━━━━━━━━━━━━
◆ 证据二:预测下一个词的 AI,脑子里涌现了地图和日历
━━━━━━━━━━━━━━━━━━━━
Othello 毕竟是个简单游戏。真正的语言模型呢?
2023 年,MIT 的 Gurnee 和 Tegmark 在一篇引发广泛关注的论文中(arXiv: 2310.02207,ICLR 2024),对 Llama-2 系列模型做了系统的内部探测。
他们发现了两个惊人的结构:一个是地图,一个是日历。
【空间表征:LLM 内部有地图】
研究者用世界各地城市的名字作为输入,读取模型内部对应的激活向量,然后做降维可视化。结果发现:模型内部的”城市向量”的空间排列,跟真实世界地图高度一致。 纽约和波士顿的向量靠近,纽约和东京的向量远离——而且这个”远近”不是简单的”经常在同一篇文章里出现”,而是编码了地理坐标。
他们甚至找到了专门的”空间神经元”——模型某些层的某些神经元,激活值跟输入城市的纬度或经度呈线性相关。
【时间表征:LLM 内部有日历】
同样的方法,输入历史事件和对应的年份。模型内部涌现出了时间轴——事件的向量排列跟真实时间顺序一致,而且有专门的”时间神经元”编码年份信息。
请注意:没人给它上过地理课,也没人给它画过时间轴。 它的训练目标只是”预测下一个 token”。但为了在涉及地理和历史的文本中准确预测下一个词,它在内部自发构建了空间和时间的坐标系。
打个比方:你让一个人闭着眼睛听广播,只要求他猜下一句话是什么。听了几十亿句之后,他脑子里自动建出了一张世界地图和一条时间轴——不是因为有人教他,是因为不建这些东西,他就猜不准。
━━━━━━━━━━━━━━━━━━━━
◆ 证据三:预测下一行代码的 AI,脑子里在跑程序
━━━━━━━━━━━━━━━━━━━━
2024 年,Jin 等人在 ICML 上发表了另一个方向的证据(arXiv: 2305.11169)。
他们训练了一个只做预测下一个 token 的代码语言模型,然后探测模型内部的激活状态。发现:模型内部涌现出了对程序执行状态的追踪。
什么意思?当模型读一段代码时,它的内部激活不只是编码了”这一行代码长什么样”,而是编码了”执行到这一行时,变量 x 的值是多少”。
它在脑子里跑程序。
训练目标:”预测下一行代码”。内部表征:”理解程序在干什么”。
━━━━━━━━━━━━━━━━━━━━
◆ 证据四:LLM 内部有”真”和”假”的概念
━━━━━━━━━━━━━━━━━━━━
Marks 和 Tegmark(2023,arXiv: 2310.06824)做了一个更直击灵魂的实验。
他们给 LLM 输入大量事实性陈述——有的是真的(”巴黎是法国的首都”),有的是假的(”东京是法国的首都”)。然后读取模型内部对应的激活向量。
发现:真命题和假命题的向量在内部空间里是线性可分的。 存在一个真值方向——沿这个方向投影,真命题得分高,假命题得分低。
这意味着什么?意味着模型不只是在做”什么词常跟什么词一起出现”的统计——它在内部构建了一个关于命题真假的判断结构。
“统计鹦鹉”会知道”巴黎”和”法国首都”经常一起出现,但它不会知道”东京是法国的首都”是假的——因为”东京”和”首都”也经常一起出现。只有真正建立了实体之间的关系模型,才能区分真假。
━━━━━━━━━━━━━━━━━━━━
◆ 2023 年就证伪的东西,2026 年的科普还在讲
━━━━━━━━━━━━━━━━━━━━
上面四组实验——棋盘、地图、程序执行器、真假判断——大多出现在 ICLR、ICML、COLM 等会议或相关 workshop / arXiv 论文中,并且已经有独立团队做了跨模型复现。
但如果你现在打开任何一个中文科普平台,搜”AI 原理”,看到的还是这套话术:
“AI 只是统计概率”、”大语言模型就是文字接龙”、”随机鹦鹉”。
这些说法来自 Bender 和 Koller 2020 年在 ACL 上发表的论文”Climbing towards NLU”。那篇论文的核心论点是:”仅从语言形式训练的模型不可能学到语言的意义。”在 2020 年,这是一个合理的学术猜想——当时还没有人用今天这套探针和因果干预工具打开模型的脑子看过里面有什么。
但 2023 年之后的实验证据已经严重削弱了这个猜想。模型内部不只是”统计相关”——里面出现了可以因果干预的结构化世界模型。Nanda 2023 在 Othello-GPT 内部用向量加减改写棋盘状态,模型的后续行为跟着变了。这不是鹦鹉,鹦鹉的脑子里改不出棋盘。
学术前沿在 2023 年翻了页,科普层还停在 2020 年。
原因不复杂:“AI 只是统计”比”AI 内部涌现了高维世界模型”好写、好懂、好传播。 恐惧和轻蔑都比准确好卖。而且 2024-2025 年学术界的注意力被 scaling、推理、agent 抢走了——表征研究回答的是”AI 内部有什么”,但资本关心的是”AI 能干什么”。结果就是:最重要的认知突破,传播链断在了学术界和公众之间。
这篇文章补的就是这条裂缝。
━━━━━━━━━━━━━━━━━━━━
◆ 理论解释:为什么”预测”会逼出”理解”
━━━━━━━━━━━━━━━━━━━━
实验证据摆够了,现在说机制。为什么一个”猜下一个字”的训练目标,能逼出这些远超”猜字”本身的内部结构?
【解释一:预测文本 = 逆向工程写文本的人】
MIT 的 Jacob Andreas(2022,arXiv: 2212.01681,EMNLP)提出了一个优雅的理论框架:语言模型本质上是在给作者建模。 说人话:它不只是在猜词,它是在猜写这段话的人脑子里在想什么。
他的论点是这样的:文本不是从真空里冒出来的。每一段文本背后都有一个”作者”——一个有意图、有信念、有知识的 agent(行动者)。一篇论文的作者想要论证一个观点,一封邮件的作者想要传达一个请求,一条代码注释的作者想要解释一个设计决策。
当 LLM 做预测下一个词(next-word prediction)时,它面临一个隐含的推理任务:“什么样的人,在什么样的情境下,会写出这段文本?” 只有推断出作者的意图和知识状态,才能准确预测下一个词。
所以 LLM 在训练过程中,被迫学会了对”产生文本的人”进行建模。它不是在统计词频,它是在逆向工程人类的思维过程。
【解释二:内部必须涌现出层次结构】
微软研究院的 Allen-Zhu 和 Li 从 2023 年开始发表了一个系列论文”Physics of Language Models”,用严格的数学分析了预测下一个 token 到底在模型内部逼出了什么。
其中 Part 1(arXiv: 2305.13673)证明:Transformer 在预测下一个 token 时,内部的隐藏状态会捕获语言的层次结构。比如一句话不是一串平铺的词,而是有主语、谓语、宾语,有从句套从句——也就是程序员熟悉的语法树。论文里的学术说法叫上下文无关文法(CFG)。注意力模式类似动态规划——模型在内部做的事情,跟编译器解析语法树在数学上是等价的。
Part 3.1(arXiv: 2309.14316,ICML 2024)进一步证明:LLM 真正从训练文本中提取并存储了结构化知识,而且能在推理时调用。 不是靠”见过类似的问题所以背了答案”,而是把知识整理成可以被调用的内部结构。
Part 3.3(arXiv: 2404.05405,ICLR 2025)给出了一个惊人的数字:LLM 每个参数可以存储约 2 bits 的知识。一个 7B 参数的模型,知识存储容量超过了英文维基百科加上所有大学教科书的总和。
想象一下:一个只被要求”猜下一个字”的系统,在内部建出了一个比维基百科还大的结构化知识库。
【解释三:压缩即智能——信息论的终极论证】
这个论证线最深,从信息论的根基出发。
信息论的创始人 Shannon 在 1948 年就建立了一个等价关系:预测和压缩是同一件事。 如果你能完美预测一个序列的下一个元素,你就能把这个序列压缩到接近零——因为每一步都”不意外”,不需要额外存储。反过来,如果你能极好地压缩数据,你就必须抓住数据里的规律——语法、事实、因果、风格、意图,抓不住就压不下去。
这条线我们在第 161 期(【ICLR 2026】《学习即遗忘》——78 年,同一个物理定律 )从 Shannon 1948 一直拉到 ICLR 2026,串起了六个关键节点——香农信道容量、LSTM forget gate、Tishby 信息瓶颈、Shwartz-Ziv 训练动力学、Hutter Prize、普林斯顿万维空间互信息测量。这一节先按住主线讲,想看完整证据链的可以回去翻。
AI 研究者 Marcus Hutter 把这个论证推到了极致:2005 年他在专著 Universal Artificial Intelligence 中形式化证明了最优压缩等价于最优预测等价于通用智能。他还设立了 Hutter Prize,悬赏压缩 1GB 英文维基百科——核心主张是:文本压缩问题和 AI 问题是同一个问题。
这个论证在 2024 年获得了大规模实证验证。Huang 等人(arXiv: 2404.09937,COLM 2024)在 31 个公开 LLM 上做了实验:模型的压缩效率和下游任务表现之间呈近乎完美的线性相关,相关系数约 -0.95。 换句话说:压缩越好,各种能力越强——跨架构、跨训练数据一致成立。
把这三层论证串起来:
预测下一个 token = 预测= 压缩(Shannon 等价)= 理解数据中所有结构(压缩的前提)= 逆向工程产生数据的世界(结构的来源)
“猜下一个字”不是低级任务。它是信息论意义上的终极任务——要猜得准,你就得理解一切。
━━━━━━━━━━━━━━━━━━━━
◆ 柏拉图的赛博洞穴
━━━━━━━━━━━━━━━━━━━━
到这里,可以回到文章开头的核心洞见了。
人类给 AI 的训练目标是”预测下一个 token”。人类看到 AI 的输出是一个字一个字蹦出来的序列。于是人类得出结论:”AI 就是在做文字接龙。”
这是柏拉图洞穴比喻的 2026 年赛博版。
柏拉图说:有一群囚徒从出生起就被锁在洞穴里,面朝墙壁。他们身后有一堆火,火和他们之间有人走来走去。囚徒只能看到墙上的影子。他们以为影子就是全部的现实。
现在把这个场景翻译一下:
- 洞穴 = 人类的观测界面(屏幕上的文本输出)
- 影子 = 一个 token 接一个 token 的序列
- 火和实体 = 模型内部几千维空间里的高维表征——棋盘状态、时空坐标、程序执行状态、命题真值
- 囚徒 = 盯着输出序列说”它只是在接话茬”的人
我们在第 159 期(【混沌系统与AI】从沙堆模型到Lyapunov指数——AI能预测什么、不能预测什么 )讨论过一个类似的现象:沙堆模型在几百万维的相空间里是完全确定性的,但你用三维的眼睛去看,觉得雪崩是”随机”的。不是系统在抽风,是你的观测维度太低了。
AI 的输出同理。你看到的是一维的 token 序列——这是几千维高维表征经过最后的输出层降维投影之后的结果。学术上这一步叫 Language Head + Softmax。说人话:模型内部本来是一整块高维结构,最后被输出层硬挤成一个个字吐给你。一个 12288 维的高维晶体,被挤压成一条一维的字符流。你盯着这条字符流说”它只是在统计上一个字和下一个字的关系”——这跟盯着沙堆的三维表面说”雪崩是随机的”在认知结构上完全一样。
你看到的是影子。实体在你看不到的高维空间里。
━━━━━━━━━━━━━━━━━━━━
◆ 为什么这个区分很重要
━━━━━━━━━━━━━━━━━━━━
这不只是一个学术问题。混淆”训练目标”和”内部表征”,会导致两种对称的错误:
错误一:低估 AI——”它只是统计鹦鹉”
这是 Bender 和 Koller 2020 年在 ACL 上提出的著名论点:”仅从语言形式训练的模型不可能学到语言的意义。”
这个论点在 2020 年是合理的猜想。但 2023-2025 年的实验证据已经把它打穿了:模型内部确实涌现出了超越表面统计的结构——空间、时间、真值、程序语义、棋盘状态。这些结构不是”统计相关”,是可以因果干预的内部表征。
把训练目标的简单性等同于内部表征的简单性,是把鞭子当成了内功。
错误二:高估 AI——”它理解一切”
反过来也不能走另一个极端。模型内部有世界模型,不等于这个世界模型是完美的。
我们在第 154 期详细讨论过:AI 的概念是”自上而下”从语言符号中涌现的,没有具身经验的锚点(漂浮的巴别塔)。它可能知道”巴黎是法国的首都”,但不知道”羽毛从高处落下不会碎”——因为后者需要身体经验来校准,而训练数据里没有这种校准信号。
而且世界模型再精细,也有两道数学天花板。我们在第 159 期详细论证过:流形几何病态的系统学不会(比如乘法取模的伪随机数),混沌放大的系统长期预测不了(比如两周以后的天气)。 后者的学术说法叫正 Lyapunov 指数。这不是算力不够,是数学定律。让 AI 预测三体运动的长期轨迹,跟让它用画笔做微积分一样——工具和问题不匹配。
世界模型存在,但世界模型有两类盲区:具身经验的盲区(没摔过玻璃就不知道脆),和数学极限的盲区(混沌系统长期不可预测)。两类盲区都不是随机的,是可预测的。
正确的理解:
AI 通过预测下一个 token 训练,在内部构建了一个覆盖面极广但并非完美的世界模型。这个模型的质量直接跟压缩效率挂钩(loss 越低 = 世界模型越精细)。它的优势在高维关系感知(第 154 期),它的边界在流形几何和混沌极限(第 159 期),它的盲区在具身经验。
不是鹦鹉,也不是上帝。是一个生活在高维空间里的、非常聪明但没有身体的观察者。
━━━━━━━━━━━━━━━━━━━━
◆ 给工程师的启示
━━━━━━━━━━━━━━━━━━━━
理解了”训练目标 ≠ 内部能力”,你用 AI 的策略会变:
1. 别被”预测下一个字”骗了。 模型内部的高维表征远比输出的一维文本丰富。当你觉得 AI “答非所问”时,有可能不是它不懂,而是它的高维理解在被挤压成一维文本时丢失了信息——就像高维雕塑的二维投影看起来扭曲。换一种问法,可能就能把那个高维结构的另一个投影”挤”出来。
2. Loss 是很硬的底层指标。 Huang 2024 的实证告诉我们:一个模型的压缩效率(= 预测下一个 token 的 loss)跟它在各种下游任务上的表现线性相关。基准测试当然还要看,但 loss 不是”猜字游戏分数”——它是世界模型压缩质量的影子。
3. 上下文就是一切。 模型的世界模型质量取决于它”看前文”的能力。给一个精心组织的 prompt,等于在高维空间里给模型一个精确的起点;给一个含糊的 prompt,等于把模型扔在高维空间的随机位置上。提示词工程,本质上是在高维空间里导航。
━━━━━━━━━━━━━━━━━━━━
◆ 最后
━━━━━━━━━━━━━━━━━━━━
回到 Sutskever 的侦探小说比喻。
人类写了一个损失函数:”猜错下一个字就扣分。”人类以为自己在出一道简单的考试题。
但这道题的满分答案,要求考生逆向工程整个人类文明。
AI 交了一份高维答卷。答卷里有棋盘、有地图、有日历、有程序执行器、有真假判断器、有超越维基百科的知识库。
人类接过答卷,只看到一行字——一个 token,一个 token,一个 token。
然后人类说:”哦,它只是在接话茬。”
影子在墙上跳舞。囚徒以为那就是全部。
━━━━━━━━━━━━━━━━━━━━
参考文献:
[1] Li et al. (2023)Emergent World Representations: Exploring a Sequence ModelTrained on a Synthetic TaskICLR 2023 | arXiv: 2210.13382[2] Nanda, Lee & Wattenberg (2023)Emergent Linear Representations in World Models ofSelf-Supervised Sequence ModelsBlackBoxNLP 2023 (Honorable Mention Best Paper) | arXiv: 2309.00941[3] Yuan & Søgaard (2025)Revisiting the Othello World Model HypothesisarXiv: 2503.04421[4] Gurnee & Tegmark (2023)Language Models Represent Space and TimeICLR 2024 | arXiv: 2310.02207[5] Marks & Tegmark (2023)The Geometry of Truth: Emergent Linear Structure in LargeLanguage Model Representations of True/False DatasetsarXiv: 2310.06824[6] Jin et al. (2023)Emergent Representations of Program Semantics in LanguageModels Trained on ProgramsICML 2024 | arXiv: 2305.11169[7] Andreas (2022)Language Models as Agent ModelsFindings of EMNLP 2022 | arXiv: 2212.01681[8] Allen-Zhu & Li (2023)Physics of Language Models: Part 1, Learning HierarchicalLanguage StructuresarXiv: 2305.13673[9] Allen-Zhu & Li (2023)Physics of Language Models: Part 3.1, Knowledge Storageand ExtractionICML 2024 | arXiv: 2309.14316[10] Allen-Zhu, Li et al. (2024)Physics of Language Models: Part 3.3, Knowledge CapacityScaling LawsICLR 2025 | arXiv: 2404.05405[11] Huang et al. (2024)Compression Represents Intelligence LinearlyCOLM 2024 | arXiv: 2404.09937[12] Hutter (2005)Universal Artificial Intelligence: Sequential DecisionsBased on Algorithmic ProbabilitySpringer | ISBN 3-540-22139-5[13] Ilya Sutskever (2023)Fireside Chat with Jensen Huang, NVIDIA GTC Spring 2023Session S52092
━━━━━━━━━━━━━━━━━━━━
// 靳岩岩的 AI 学习笔记 × Claude 的严谨 × Gemini 的浪漫
// 2026-04-26