 夜雨聆风
夜雨聆风





UCL 等 | AISTATS 2026 | 神经算子拆分学物理项
来源:https://arxiv.org/abs/2602.23113
作者:Vignesh Gopakumar, Ander Gray, Daniel Giles, Lorenzo Zanisi, Matt J. Kusner, Timo Betcke, Stanislas Pamela, Marc Peter Deisenroth
机构:UCL Centre for Artificial Intelligence,UK Atomic Energy Authority,École Polytechnique(LIX),Polytechnique Montréal 与 Mila
一、问题背景与动机
偏微分方程(PDE)是流体力学、传热与聚变模拟等问题的数学骨架,传统谱方法或有限元在分辨率与长时间积分上代价极高。神经算子(Neural Operator)作为离散无关的替代模型,能把求解成本压低多个数量级,但主流监督训练往往直接学习从初值到解的映射,不显式嵌入方程结构,分布外(OOD)泛化差;自回归 rollout 还把时间步长固定死在训练用的 dt 上,长时间外推误差累积明显。另一类做法是用神经 ODE 学整体空间算子 d u/dt,时间连续一些,但 rhs 仍是「一锅端」的黑箱,多个物理过程抢同一套参数,容易出现谱偏置与可解释性不足。本文问的是:能否像经典数值格式那样,把方程拆成若干物理算子,只让网络去学「该它学」的非线性项,而把线性微分算子交给固定的差分卷积?
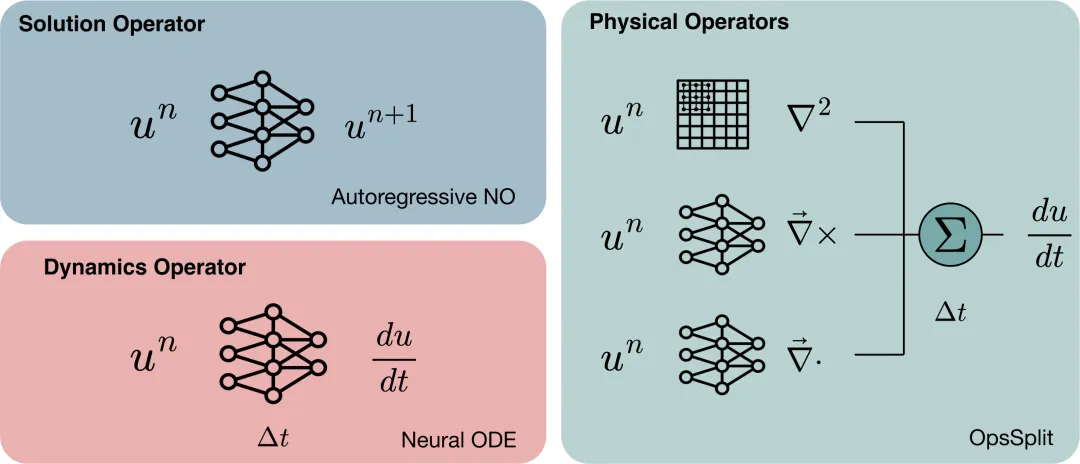
二、核心方法
论文提出 OpsSplit:用算子分裂(operator splitting)把 PDE 右端写成若干线性项与非线性项之和;非线性物理算子各自由一个神经算子(专家)近似,线性算子用有限差分模板卷积(FD)硬编码;整体写成神经 ODE,rhs 是这些算子的加权和,再用标准 ODE 积分器(如显式 Euler 或 Runge-Kutta)做连续时间推进。训练目标是对单步或多步 rollout 做相对 LP 损失(与真值场的相对误差范数),数据来自谱求解器生成的 Navier-Stokes 轨迹。
2.1 与自回归解算子、整体动力学神经 ODE 的对比
自回归方法学的是 u^n 到 u^{n+1} 的解算子,离散时间、结构隐式。整体神经 ODE 学的是 d u/dt = f_theta(u),但 f 不分解物理过程。OpsSplit 把 f 拆成「FD 线性块 + NO 非线性块」的 MoE 组合,预测格式与 PDE 分项一致,相当于把物理约束写进前向结构而不是仅靠损失惩罚。
2.2 不可压 Navier-Stokes 上的具体拆分
二维不可压方程在周期边界下,动量方程的非线性对流(并耦合压力 Poisson 效应)交给一个对流神经算子 NO_conv,粘性扩散 Laplacian 用固定差分核的 FD 近似;动量方程写成 d v/dt = -NO_conv(v) + nu FD(v),nu 为运动粘度。场变量与方程系数做线性归一化到 [-1,1],保持量纲一致。
2.3 实验设置要点
所有模型训练 250 个 epoch,Adam 初始学习率 0.001、每 50 步减半;在单卡 Nvidia H100 上,用约 100 条不同初值的仿真轨迹;每次反传前连续预测 5 步(rollout length=5)以平衡时间建模与显存;评测指标为归一化均方根误差 NRMSE(分母为真值 L2 范数加 1e-6),覆盖四类设置:同分布测试、仅时间外推(训练到 t=0.5,外推到 t=1.0)、OOD(训练未见的初值参数与粘度或可比热相关参数)、以及时间外推与 OOD 同时发生。架构上对比了 FNO、U-Net、ViT、UNO、CNO 等,在同一参数量级下比较三种部署:自回归解算子、Euler 步进的动力学神经 ODE(单网络 rhs)、以及 OpsSplit 物理算子学习。
三、实验结果
不可压情形下,OpsSplit 在多种骨干上同时压低测试误差与 OOD 误差,长时间 rollout 误差增长更慢;论文表格中 FNO 示例:同分布测试 NRMSE 从动力学神经 ODE 的约 0.0325 降到物理算子学习的约 0.0297,OOD 从约 0.1276 降到约 0.1160,OOD 加时间外推从约 0.3038 降到约 0.2185。ViT、CNO、U-Net 等多数设置里,物理算子列在 OOD 或组合最难设置上占优最频繁。可压 Navier-Stokes 上,OpsSplit 往往在 OOD 与 OOD+外推上最佳,但并非每个骨干的同分布测试都赢过「单网络动力学」基线:例如 FNO 上动力学版本在测试与纯时间外推 NRMSE 上更低(约 0.0245 对 0.0602,与约 0.0854 对 0.0959),而物理算子版本在 OOD(约 0.0573 对 0.0763)与 OOD+外推(约 0.0751 对 0.1185)更好,说明拆分带来的结构先验更利于跨参数泛化,但在分布内拟合上仍需与一体化 rhs 网络权衡。论文还展示学习到的对流算子与数值对流在可视化上的对照,并指出连续性方程残差在外推时,动力学神经 ODE 可能比自回归与 OpsSplit 更难保持。
四、值得关注的细节与局限性
算子分裂不是自动的:需要对方程与数值耦合有足够领域知识,不同分裂方式性能可以差很多,且几何守恒量不同时,不同分裂保留的不变量也不同,通用配方不存在。每块物理过程单独挂网络,多物理场时参数量与前向次数上升,可压算例里作者明确写到 OpsSplit 训练更慢,与多次估计各物理算子及 ODE 积分开销有关。当前实验以周期边界为主,复杂边界需借助填充或域迁移方面已有工作扩展。实现上还要为线性项仔细配置卷积模板,引入与传统离散化类似的近似误差。代码与补充材料见 https://github.com/gitvicky/NOs_for_POs 。
五、小结
OpsSplit 把「学解」或「学整体 rhs」改成「按物理项学分项算子 + 固定线性离散」,用神经 ODE 做时间闭合,在 Navier-Stokes 上改善了 OOD 与长时间外推,并保留模块化解释与跨方程微调(如从可压对流权重初始化不可压微调收敛更快)的潜力。代价是对 PDE 结构与分裂设计的依赖,以及积分与多专家前向带来的计算开销;是否采用应看目标是分布内精度还是跨参数稳健外推。
我们会持续跟踪AI + 物理仿真领域的最前沿顶尖进展。如果您对 AI 驱动的科学计算感兴趣,请关注本公众号,获取更多持续更新与深度解读。