 夜雨聆风
夜雨聆风





告别越聊越傻!openclaw无损上下文引擎 (LCM)技术实战全解——6大典型场景 从核心原理到生产级实战调优
在上一篇文章中,我们完整复盘了
lossless-claw从安装到验证的全过程。然而,安装插件只是第一步——真正让 LCM 在各类生产场景中发挥最大价值,关键在于针对不同使用场景进行精细化的参数调优:本文聚焦这一核心需求,从插件架构本质出发,系统梳理 LCM 的核心参数体系,并给出涵盖日常协作、编程开发、学术研究、低成本运行、多Agent协作、企业级部署六大典型场景的完整生产级配置方案。
一、插件本质:理解 LCM 是如何“接管”上下文的
在深入配置之前,需要先明确lossless-claw在OpenClaw生态系统中的定位。它不是通过外部工具调用或旁路注入来实现记忆增强的,而是直接替换了OpenClaw内置的上下文引擎,本质上是对 AI 的“记忆中枢”进行了一次底层升级。
下面这张图展示了Lossless Claw (LCM)的核心逻辑架构,从消息进入到上下文组装的全链路。
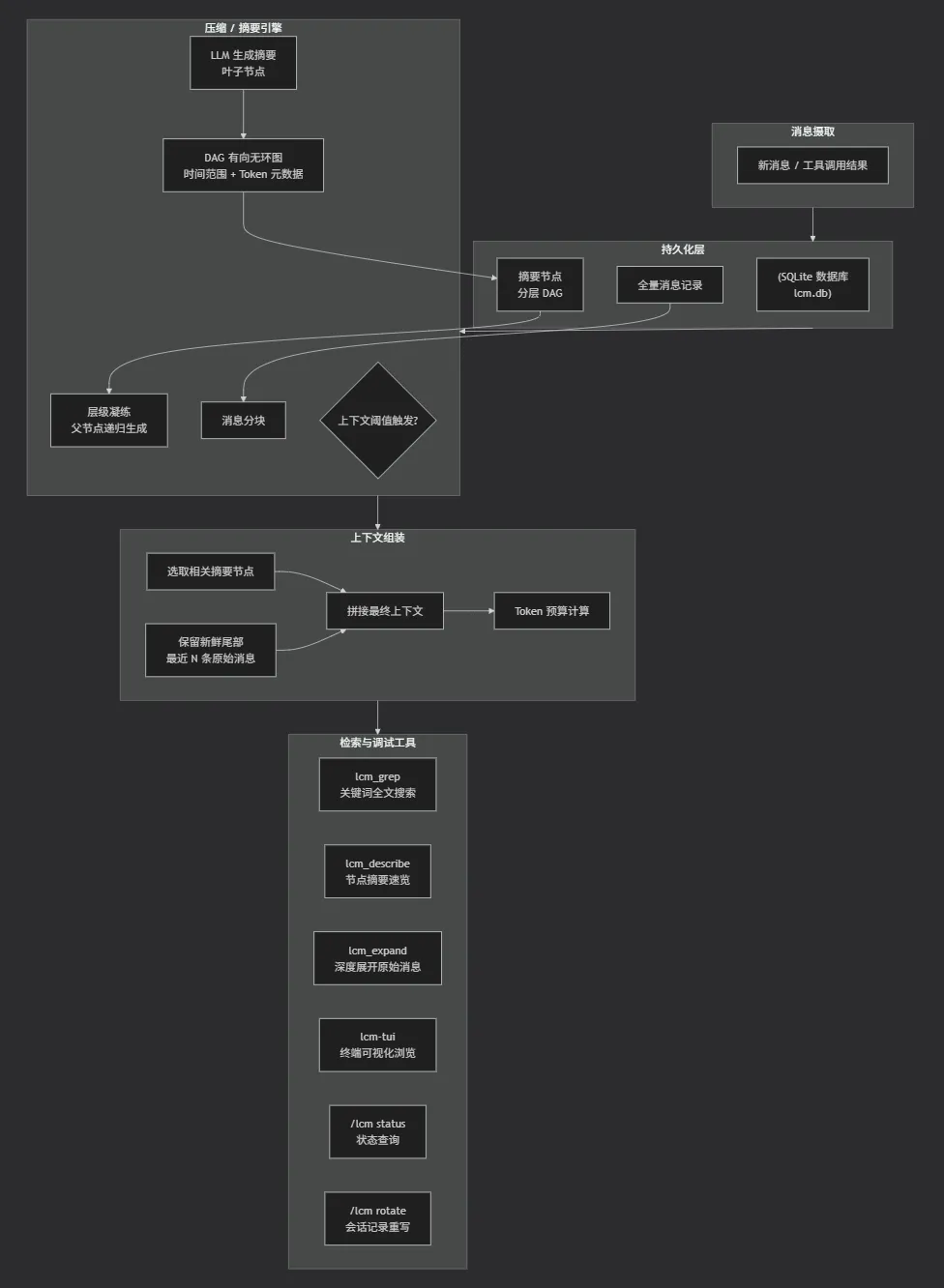
🗺️ 架构解读
-
消息摄取:每一条对话消息首先进入 LCM。
-
持久化层:信息全量写入 SQLite,并组织为分层 DAG 摘要树。树中节点包含时间范围、Token 数、后代数及可追溯到原文的引用。
-
压缩引擎:当上下文水位达到 contextThreshold 时触发。将旧消息分块交给 LLM 生成叶子摘要;叶子节点数过多时会再次凝练成更高层节点,形成金字塔式的摘要体系。
-
上下文组装:每次模型调用前,LCM 根据 Token 预算从 DAG 中选取最相关的摘要节点,与最近 N 条原始消息(新鲜尾部) 拼接成完整上下文。
-
检索工具:提供 lcm_grep (关键词搜索)、lcm_describe (节点速览)、lcm_expand (追溯原始消息) 等工具,让 AI 或用户主动挖掘历史细节。
这种架构让 LCM 既保留了完整对话记录,又能高效管理 Token 消耗,是解决“失忆”与“上下文溢出”的关键设计。
二、核心参数全景
以下参数均基于 lossless-claw 0.9.1 版本。
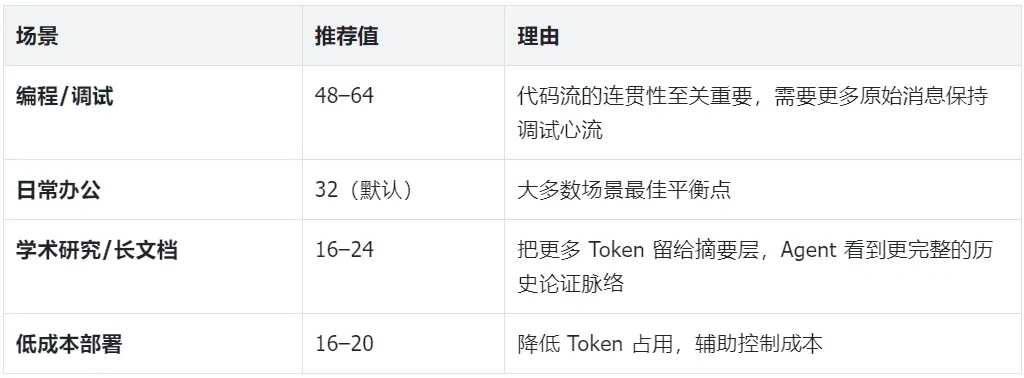
2.1 freshTailCount —— 短期记忆保护区
JSON 配置默认值:32;环境变量LCM_FRESH_TAIL_COUNT 默认值:20。环境变量优先级更高。
作用:保护最近 N 条原始消息不被压缩。即使上下文窗口被占满触发压缩,也绝不会碰这 N 条消息,确保 Agent 始终能”看清”最近的对话流。
调优指导:
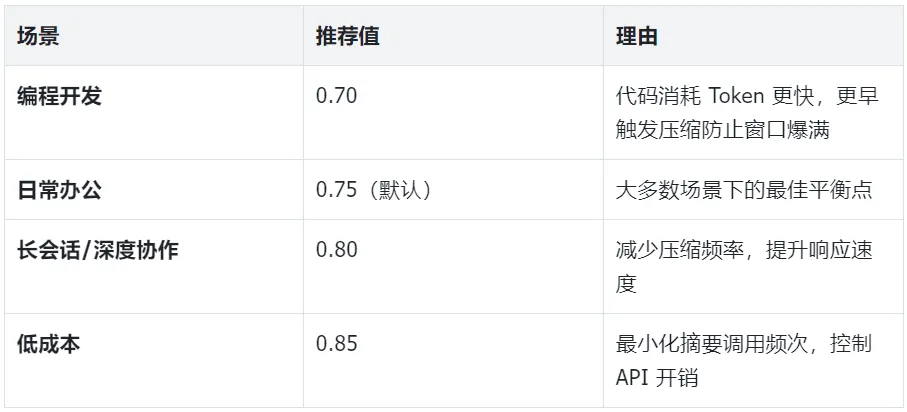
2.2 contextThreshold —— 压缩触发水位线
默认值:0.75
作用:当上下文占用达到窗口的此比例时,LCM 自动触发后台压缩,将旧消息分块摘要。留出 25% 的空间为模型回复预留 token。
2.3 incrementalMaxDepth —— 增量压缩深度
默认值:-1
作用:每次触发增量压缩时,一次递归凝练几层摘要。-1 表示无限递归,让 LCM 自动管理深度。所有场景均推荐设置 -1。
2.4 summaryModel —— 摘要生成模型
默认值:跟随主会话模型(不配置时摘要成本可能高出 100 倍)。
作用:指定 LCM 后台压缩时使用的独立模型。摘要不需要强大推理能力,只需要忠实度、速度和低成本。配置格式为 provider/model,例如 “anthropic/claude-haiku-4-5” 或 “siliconflow/Qwen/Qwen3-8B”。
2.5 expansionModel —— 深度检索展开模型
有效。用于指定 lcm_expand_query 子代理的模型覆盖。展开任务对速度敏感,推荐使用轻量快速模型,如 “openai/gpt-4o-mini” 或 “anthropic/claude-haiku-4-5″。不建议使用大型推理模型。
2.6 largeFileTokenThreshold —— 大文件外置化阈值
默认值:25000(tokens)。当消息中的文件超过此 Token 数时,LCM 会将其外置存储,避免单文件撑满上下文。可酌情调高到 40000–50000。
2.7 dbPath —— 数据库存储路径
默认值:~/.openclaw/lcm.db。如需迁移数据,先复制数据库再更新此路径。
2.8 ignoreSessionPatterns —— 会话排除模式
通过 glob 模式指定完全不存储、不压缩的会话。推荐 [“agent:*:cron:**”]。
2.9 statelessSessionPatterns —— 无状态只读会话
指定可读取 LCM 历史但不写入的会话,适合子 Agent 调用。推荐 [“agent:*:subagent:**”]。
三、典型场景配置方案
理解每个参数的含义之后,接下来是关键的一步:如何针对不同的使用场景,将这些参数组合成最优配置?以下针对六大典型场景,逐一给出推荐的参数方案和调优思路。
3.1 场景一:日常办公协作
场景特征:对话以中等长度为主,通常在 100~300 轮之间。每天可能切换不同主题,但每个主题的对话深度有限。用户对响应速度有较高要求,不希望因压缩产生明显延迟。Token 成本敏感,不希望造成不必要的额外开支。
配置要点与目标:追求快速响应和较低 Token 消耗,freshTailCount 保持较高值,摘要触发延迟适度。
"lossless-claw": {"enabled": true,"config": {"freshTailCount": 48,"contextThreshold": 0.75,"incrementalMaxDepth": -1,"summaryModel": "anthropic/claude-haiku-4-5","expansionModel": "openai/gpt-4o-mini","ignoreSessionPatterns": ["agent:*:cron:**"]}}
关键决策说明:
-
freshTailCount: 48:较社区默认的 32 更高,确保当前主题的对话流始终保持在视野中,减少因压缩而导致的对当前对话流的干扰。
-
summaryModel: “claude-3-5-haiku”:使用便宜、快速的独立摘要模型,大幅降低摘要产生的额外 API 开销。
3.2 场景二:编程与代码开发
场景特征:对话密度极高,涉及大量代码片段、技术术语和上下文引用。Agent 需要随时回溯早期的设计决策、变量命名约定、错误调试记录。当前对话的精确性远比历史全貌更重要。
配置要点与目标:需要较大的 freshTailCount 以保证当前代码上下文完整,同时压缩触发阈值稍低以防止窗口溢出(因为代码通常占 Token 更多)。
"lossless-claw": {"enabled": true,"config": {"freshTailCount": 64,"contextThreshold": 0.70,"incrementalMaxDepth": -1,"largeFileTokenThreshold": 40000,"summaryModel": "openai/gpt-4o-mini","expansionModel": "openai/gpt-4o-mini","ignoreSessionPatterns": ["agent:*:cron:**"],"statelessSessionPatterns": ["agent:*:subagent:**"]}}
关键决策说明:
-
freshTailCount: 64:恢复到源码的默认值,为 Agent 提供最充裕的当前代码上下文,确保连贯理解和调试。
-
contextThreshold: 0.70:代码通常占 Token 更多,因此将触发阈值略微调低,为模型回复留出更多空间。
-
largeFileTokenThreshold : 40000 tokens:容纳完整的代码库片段或转储日志,避免大文件被过早外置化而丢失关联上下文。
-
statelessSessionPatterns : [“agent:*:subagent:**”]:编程场景中主 Agent 经常调用子 Agent 执行检查或测试,子调用产生的临时会话如果全部写入 LCM 数据库会造成严重污染,设为只读模式既能保留追溯能力,又不影响主数据库的健康度。
-
summaryModel: openai/gpt-4o-mini:代码场景下该模型对技术术语的保留能力足够,且月度成本极低。
3.3 场景三:超长文档与学术分析
场景特征:对话可能持续数天甚至数周,涉及长篇幅文献、会议纪要、调研报告。Agent 需要从海量历史信息中精准检索出特定段落、数据点和引文。Token 窗口紧张,需要更多空间给摘要层。
配置要点与目标:freshTailCount 较小以给摘要层腾出空间,压缩批次较大以适配长文档的“块”特征。
"lossless-claw": {"enabled": true,"config": {"freshTailCount": 16,"contextThreshold": 0.70,"incrementalMaxDepth": -1,"largeFileTokenThreshold": 25000,"summaryModel": "anthropic/claude-haiku-4-5","expansionModel": "anthropic/claude-haiku-4-5","ignoreSessionPatterns": ["agent:*:cron:**"]}}
关键决策说明:
-
freshTailCount: 16:学术场景下,“看清完整论证脉络”远比“记住最近几句对话”更重要。freshTailCount 大幅降低至 16,腾出可观的 token 空间供高阶摘要层使用,使 Agent 能在一次上下文窗口中承载几周甚至几个月的讨论全貌。
-
contextThreshold: 0.70:与编程场景相同,为模型的回复预留更多生成空间。
-
clargeFileTokenThreshold : 25000:因为单篇论文或文献通常在 25000 tokens 以内
-
摘要和展开模型均选择 claude-haiku-4-5,看重其对复杂逻辑关系的忠实凝练能力,对于学术论证的保真度至关重要。ignoreSessionPatterns 仅排除定时任务,保留所有研究讨论的完整存档,以备日后引用和复盘。
整体策略倾斜于“历史深度覆盖”而非“当下交互速度”,让 LCM 成为一位真正能陪你读论文、做综述的“第二大脑”。
3.4 场景四:低成本/ 个人自托管部署
场景特征:使用免费或极低成本的模型 API,Token 预算非常有限。但仍希望获得 LCM 的无损上下文能力。需要在摘要质量和成本之间找到最优平衡点。
配置要点与目标:用最便宜的模型做摘要(甚至本地免费模型),尽可能减少摘要 Token 消耗。
"lossless-claw": {"enabled": true,"config": {"freshTailCount": 16,"contextThreshold": 0.85,"incrementalMaxDepth": -1,"summaryModel": "GLM-4.7-Flash","expansionModel": "deepseek/deepseek-chat","ignoreSessionPatterns": ["agent:*:cron:**", "agent:*:test:**"]}}
关键决策说明:
-
freshTailCount: 16:直接降低整体上下文常驻 token 量。
-
contextThreshold: 0.85:则将压缩触发推到窗口真正快满的时刻,大幅减少摘要 API 调用频次,从源头控制成本。
-
summaryModel: “GLM-4.7-Flash”:中文极佳且免费。
-
ignoreSessionPatterns : [“agent:*:cron:**”, “agent:*:test:**”]:额外排除了测试会话,进一步避免无价值的 API 消耗。
这套配置牺牲了一定的交互流畅度和摘要保真度,但在预算极度有限的个人或学生场景下,仍然能保留 LCM 的核心无损记忆能力,实现了“花最少的钱,存最多的历史”这一目标。
3.5 场景五:多 Agent 交互
场景特征:OpenClaw 网关下同时运行多个 Agent,每个 Agent 有独立的工作区、记忆和会话。需要通过统一的 LCM 配置保证所有 Agent 都具备无损上下文能力,确保不同 Agent 之间的会话数据互不干扰,并对无价值的后台系统会话(如定时任务)进行过滤。
配置要点与目标:一个 lossless-claw 插件实例通过其内部机制自动处理多 Agent 场景(即一个网关下只需安装和配置一次),重点是配置过滤规则,排除子 Agent 调用和定时任务等系统会话。
"lossless-claw": {"enabled": true,"config": {"freshTailCount": 32,"contextThreshold": 0.75,"incrementalMaxDepth": -1,"summaryModel": "anthropic/claude-haiku-4-5","expansionModel": "openai/gpt-4o-mini","ignoreSessionPatterns": ["agent:*:cron:**","agent:*:healthcheck:**"],"statelessSessionPatterns": ["agent:*:subagent:**"]}}
关键决策说明:
-
多 Agent 环境下的最大隐患是系统内部会话(定时任务、健康检查、主 Agent 调用子 Agent)会急剧膨胀LCM 数据库,不仅拖慢检索速度,还可能导致真正的业务对话被淹没。因此,ignoreSessionPatterns 排除了 cron 和 healthcheck 会话。
-
statelessSessionPatterns则让所有子 Agent 调用进入只读模式——子 Agent 可以检索父会话的历史上下文以辅助任务执行,但完成任务后产生的临时对话不会被写回 LCM 数据库,保持了主数据库的清洁。
-
freshTailCount和contextThreshold保持默认值,因为各 Agent 的对话长度差异很大,通用值在大多数情况下表现稳定。摘要和展开模型分开配置,兼顾质量与成本。这套策略的核心价值在于“隔离而非禁止”,既保障了系统运维可观测性,又防止内部噪音污染记忆库。
3.6 场景六:企业级部署
场景特征:面向多客户或多业务线的生产级部署,对数据可追溯性、审计合规有严格要求。需要完整的对话历史存档,不能有任何信息丢失。可能需要与企业现有的日志系统对接。
"lossless-claw": {"enabled": true,"config": {"freshTailCount": 32,"contextThreshold": 0.75,"incrementalMaxDepth": -1,"summaryModel": "anthropic/claude-haiku-4-5","expansionModel": "anthropic/claude-haiku-4-5","dbPath": "/data/openclaw/lcm-prod.db","ignoreSessionPatterns": []}}
关键决策说明:
-
企业级部署最核心的要求是“零丢失”——任何一条对话记录都不能被自动删除,以应对审计合规。因此 ignoreSessionPatterns 被显式置空,确保所有会话均被完整归档。
-
dbPath指向独立数据盘,便于定期备份和异地容灾。
-
摘要和展开模型统一选择 claude-haiku-4-5,以摘要保真度和稳定性为第一优先级,成本次之。
-
freshTailCount和contextThreshold保持默认值,因为企业场景下对话类型多样,通用配置普适性最好。这套方案将 LCM 从“技术工具”升级为“合规基础设施”,让企业放心地为客户提供基于 AI 的长期服务,任何决策都可被追溯到原始对话记录。
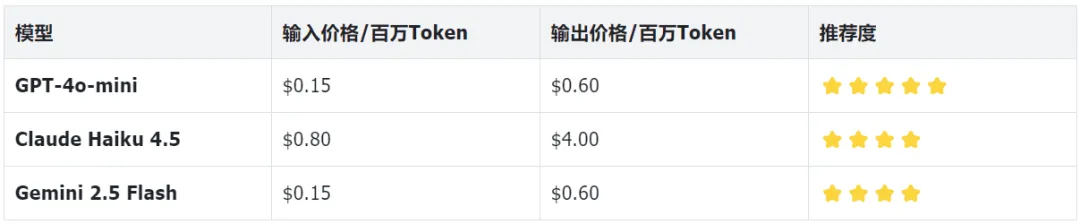
四、模型选型专题
4.1 国际通用摘要模型推荐
4.2 中文摘要模型高性价比方案
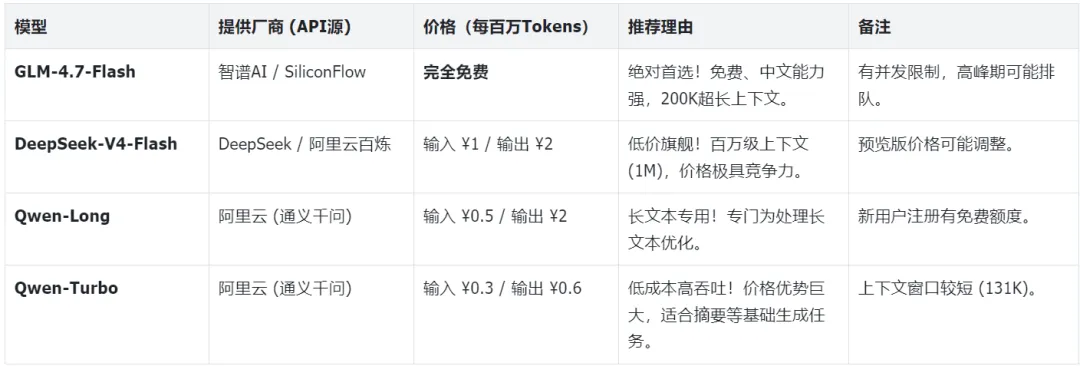
4.3 深度检索展开模型选型
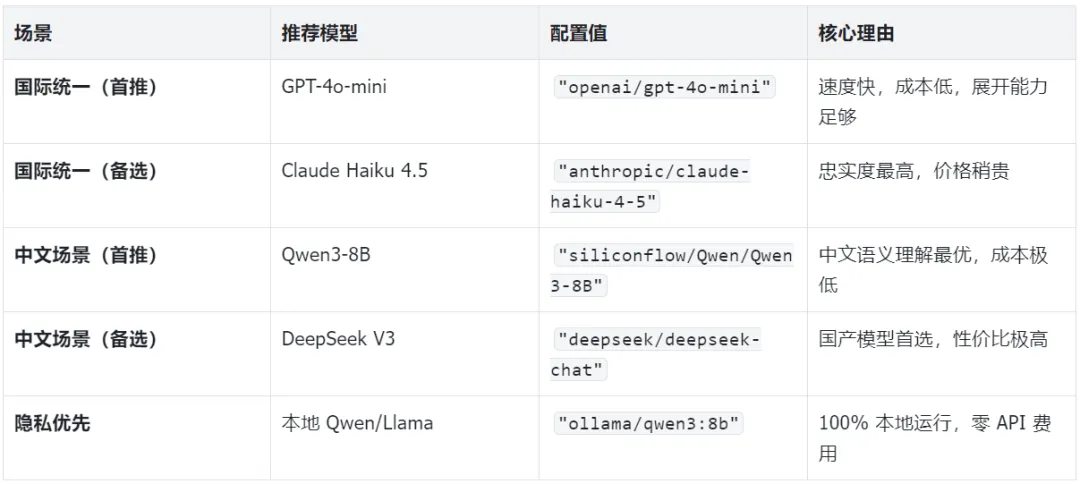
价格时效性声明:大模型 API 价格处于快速变动期,以上价格均为2026年4月数据,最终请以各厂商官网为准。
五、中文增强版:lossless-claw-enhanced
如果主要使用中文,强烈推荐使用 lossless-claw-enhanced。该版本修复了 CJK 文本的 token 估算偏低问题(准确度提升最高 6 倍),同时整合了上游 bug 修复。安装方式:
git clone https://github.com/win4r/lossless-claw-enhanced.git
openclaw plugins install –link ./lossless-claw-enhanced
配置参数与标准 LCM 完全兼容,仅需将 contextEngine 插槽指向 “lossless-claw-enhanced” 即可。
六、生产级注意事项与监控方案
6.1 数据库增长与管理
LCM 的 SQLite 数据库(lcm.db)是所有对话记录和摘要节点的存储容器。它会随着使用持续增长,虽然总体增速可控,但在长期运行中仍需关注。建议:
定期检查数据库大小:关注 ~/.openclaw/agents//lcm/lcm.db 的文件大小。
执行 VACUUM 回收碎片空间:当数据库增长明显(例如超过 500MB),可以在 OpenClaw 停止或数据库空闲时,使用 sqlite3 lcm.db “VACUUM;” 命令来回收空间。
配合 session.maintenance 自动清理:在 OpenClaw 的全局配置中合理设置 session.maintenance.pruneAfter 和 maxEntries,配合 LCM 的 autoPurge: true,当源会话文件被清理时,LCM 也会自动删除对应的数据库条目。
6.2 摘要质量监控
摘要质量直接决定了 LCM 的回溯准确率。建议定期通过以下方式抽查摘要质量:使用 lcm-tui 命令行工具浏览 DAG 结构,检查摘要节点是否准确概括了对应消息块的核心内容。如果发现摘要质量较低,可以尝试切换到更强的摘要模型,或调整 maxChunkTokens 以减少单个摘要块的粒度。
6.3 已知兼容性注意事项
Claude Sonnet 4 可能存在已知配合问题,建议优先使用 GPT-5、Gemini Flash 3.1 或 DeepSeek 等模型以获得最佳兼容性。
已存在的旧会话不能直接切换引擎。要让 LCM 生效,需要使用 /new 开启全新会话。
Node.js 需要 22+ 版本,且强烈建议确认 SQLite FTS5 编译选项可用,否则全文检索会降级。
七、总结:LCM 是生产级 Agent 的必备基础设施
本文从参数本质出发,针对六大典型场景给出了完整的配置方案,覆盖了从日常办公到企业级部署的全场景需求。回顾整套方案,核心思路可以浓缩为以下原则:
-
独立摘要模型是关键降本手段:不要让主对话模型做摘要工作,用最便宜的模型处理压缩。
-
freshTailCount 是场景差异化的核心参数:根据场景对“当前连贯性”与“历史覆盖度”的权衡,选择合适的值。
-
无限深度是长期记忆的保障:incrementalMaxDepth: -1 是社区公认的最佳实践。
-
autoPurge + pruneHeartbeatOk 是保持数据库清洁的组合拳:日常和编程场景务必开启。
-
环境变量便于快速调参,JSON 配置用于固化生产方案:两者配合使用,效率最佳。
无论是个人开发者、专业程序员、学术研究者,还是企业 IT 管理员,都可以通过选择适合自己的配置方案,让 OpenClaw Agent 从“一个会遗忘的短期对话工具”升级为“一位永不忘事的长期 AI 搭档”。LCM 已不是“要不要装”的问题——在长对话场景下,它是 Agent 稳定运行的基础设施。
——感谢阅读真实经历,真诚分享关注我,一个只分享 AI 实战记录的人类