一个什么技术都不明白的产品经理,最后一定会被底下的执行者架空。
这篇文章,我将教给你一些AI软件开发的基础知识。别被”基础知识”这四个字吓到了,你不需要什么都学透,只需要掌握基本概念和简单用法就够用了。学会这些,你就具备了查找bug的基本能力,再让AI帮你看看日志,开发中遇到的大部分问题你都能应对。
别有压力。实际上,看完这篇文章你可能还是一知半解,这完全没问题——后面我们会有很多实践环节,你跟着做,很快就能上手。
说实话,现代软件开发的技术知识都是应用类的,掌握常用的就够,学起来也快。所以啊,智能时代下的我们不用太焦虑,AI编程也是应用技术,遇到需要的时候再学,完全来得及。
1. 计算机操作基本常识
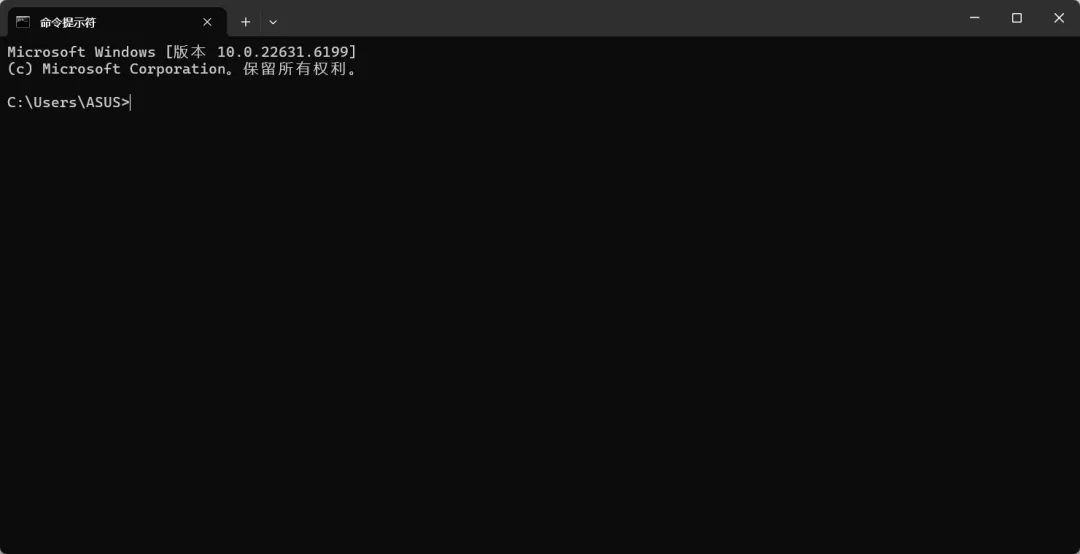
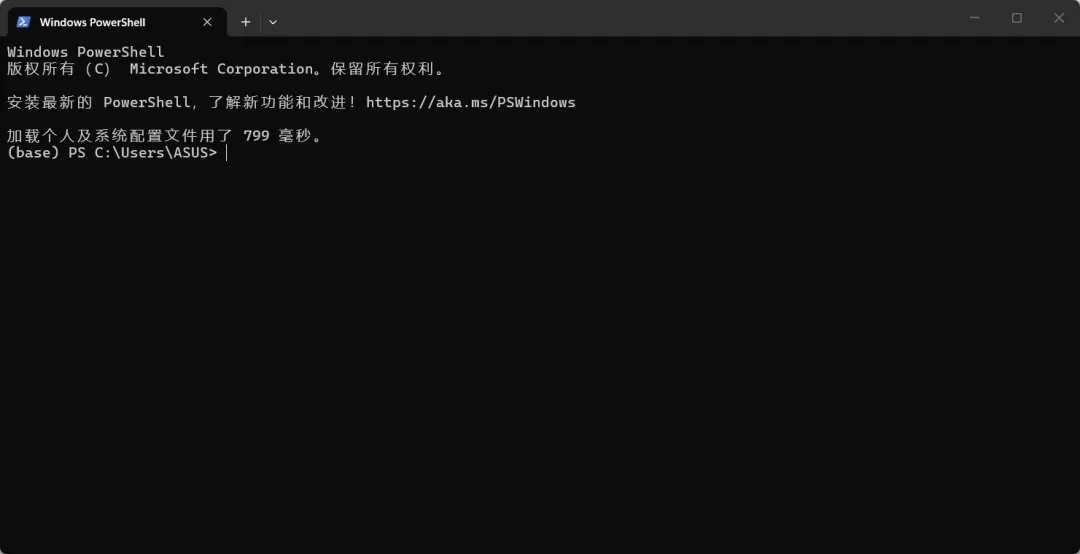
终端(Terminal)
如果你以前没接触过编程,”终端”这个词可能让你觉得有点高深。其实没那么复杂,终端其实就是一个用文字跟电脑对话的窗口。
我们平时用电脑,都是用鼠标点来点去——点文件夹、双击打开软件、拖拽文件。但终端不一样,它是靠输入命令来完成这些操作的。
打个比方:你用鼠标操作电脑,就像在餐厅看菜单用手指点菜;而用终端,就像直接跟服务员口头报菜名。两种方式都能把事情办了,但终端更高效、更精确,尤其在开发场景下。
想进一个叫 project 的文件夹?在终端里输入 cd project 回车就行。想看看文件夹里有什么?输入 ls(Mac/Linux)或 dir(Windows)。想运行一个Python程序?输入 python app.py。这些命令就像一套”快捷暗号”,掌握几个常用的,日常开发就够用了。
为什么终端这么重要?因为很多开发工具只能在终端里运行。用Python安装第三方库?得在终端执行 pip install。用Git管理代码版本?得在终端输入 git commit。启动一个Web服务器?也是在终端里敲一行命令。不会用终端,这些操作都做不了。
这两张截图就是终端的样子。这是Windows的终端(也叫命令提示符或PowerShell),不用背太多命令,记住最常用的五六个就够了:cd(切换目录)、ls/dir(列出文件)、mkdir(创建文件夹)、cp/copy(复制文件)、rm/del(删除文件)。遇到不会的,直接问AI就行。
建议从现在开始就习惯终端命令操作(CLI),我们后面要介绍到的AI编程工具Claude Code就是CLI形式的。
环境变量(Environment Variables)
“环境变量”,这个东西,相信大家在大学上过大学计算机基础时经常会听到。
假设你搬了新家,想让快递员每次都能找到你家,你会怎么做?肯定不会每次都跟快递员说一遍你家的详细地址,而是在快递平台上设置一个默认收货地址。这样每次下单,系统自动帮你填好地址,不用你重复输入。
环境变量就是这个”默认收货地址”。在计算机里,很多程序运行的时候需要知道一些系统级的信息,比如:Python安装在哪个目录下?系统的临时文件放在哪里?这些信息就可以设置为环境变量,所有程序都能读到,不用每个程序都单独配置一遍。
举个最实际的例子:你下载了一个别人的项目,在你电脑上怎么都跑不起来,报错说”找不到Python”或者”找不到某个命令”。但同样的项目,在别人电脑上就正常运行。这种情况,十有八九就是环境变量没配好。对方的电脑把Python的安装路径添加到了环境变量里,所以系统能自动找到Python;你的电脑没配,系统就”找不到”。
实际上,环境变量的作用就是根据用户输入的指令查表,然后找到可执行文件,最终在当前目录下执行程序。
怎么设置环境变量?Windows用户可以在”系统属性 → 高级 → 环境变量”里设置;Mac/Linux用户可以在终端配置文件里添加一行 export 变量名=值。具体操作遇到的时候再搜就行,知道这个概念最重要。
本地主机(localhost)
localhost这个词你会在开发中反复见到。它的意思非常简单——就是你自己这台电脑。
当你在开发一个网站或Web应用时,你需要先在自己的电脑上把它跑起来,看看效果对不对、功能正不正常。这时候你的电脑就同时充当了”服务器”和”用户”两个角色。你在浏览器里输入 http://localhost:3000 或 http://localhost:8080(后面那个数字叫”端口号”,相当于不同的服务窗口),就能访问到自己电脑上运行的网站。
为什么要有这个概念?因为在开发阶段,你的项目还没有部署到真正的服务器上,别人通过互联网访问不了。你只能先在本地(也就是你自己的电脑上)测试。等确认没问题了,再把它放到真正的服务器上,让全世界都能访问。
一个常见的坑:有时候你启动了一个服务,终端显示”Running on http://localhost:5000″ ,但你打开浏览器输入这个地址,页面却打不开。这时候你要检查几个事情:服务是不是真的在运行?端口号有没有输错?有没有被防火墙拦截?这种问题在开发中太常见了,记住排查思路就行。
再稍微细致一点,在计算机网络的概念里,localhost其实是IPv4地址127.0.0.1映射的域名——这一点知道就好。
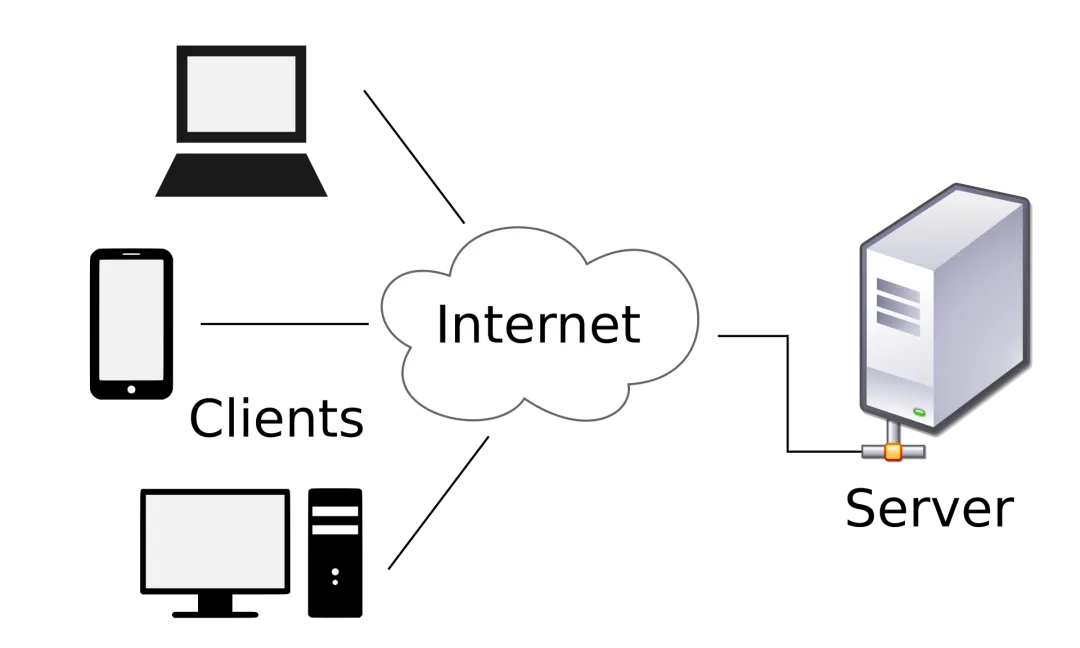
客户端与服务端(Client / Server)
客户端和服务端是理解整个互联网运作方式的核心概念。弄懂了它,你就明白了网站、App背后的基本工作原理。
你去美团点了一份炸鸡。在这个过程中,你的手机(美团App)就是客户端,美团的机房里那些处理订单的电脑就是服务端。你在App里点”下单”,这个动作就是客户端向服务端发送请求;服务端收到请求后,帮你创建订单、通知商家、返回一个”下单成功”的消息,这就是服务端的响应。
每一次你打开网页、刷新朋友圈、搜索商品,背后都是一次”请求 → 响应”的过程。你的浏览器或App发出请求,远端的服务器接收请求、处理逻辑、返回结果。
客户端(Client):发起请求的一方。浏览器是客户端,手机App是客户端,甚至你在终端里用命令调用一个在线接口,终端也是客户端。客户端的任务很单纯——把用户的操作翻译成请求发出去,然后把收到的结果展示给用户。通常,在技术上,也在用户视角里,客户端可以近似于”前端”。
服务端(Server):处理请求并返回结果的一方。服务端才是真正”干活”的地方。用户登录?服务端验证账号密码。数据查询?服务端去数据库里找。调用AI模型?服务端把请求转发给AI服务再返回结果。类似的,服务端可以近似于”后端”。
为什么你需要懂这个?因为你做AI软件开发,本质上就是在搭建或者对接一个服务端。你的前端界面(客户端)需要把用户的输入发送给后端(服务端),后端调用AI模型处理后把结果返回给前端展示。这条链路弄清楚了,你就知道你的代码应该写在哪一层、问题出在哪个环节。
比如用户反馈说”点按钮没反应”,你就知道可能是前端没把请求发出去,也可能是后端没响应,还可能是网络断了。有了客户端-服务端的概念,你就能一步步排查,而不是两眼一抹黑。
2. 编程语言基本知识
至少掌握一门高级语言
如果你从来没写过代码,”编程语言”这四个字可能让你联想到几名hacker在屏幕前飞速敲键盘的画面。但编程语言其实没那么高深——它就是一种让人和电脑能够沟通的语言,就像英语、汉语是用来让人和人沟通的。
编程语言有很多种:Python、Java、C++、JavaScript、Go……就像人类世界有几百种语言一样。但编程语言的”语法”比人类语言简单太多了,只有几十条规则,学上一两周就能上手。
我推荐你从Python开始。原因很简单:Python是目前AI领域的绝对主流语言。你用AI开发软件,大部分项目都会用到Python;网上的AI教程和开源项目,90%以上都是Python写的。而且Python的语法非常简洁,读起来几乎像在读英文句子,对新手非常友好。
但我要强调一点:语言不是重点,各方面的基础知识(架构、算法、调试)才是。编程的核心不在于你用哪门语言,而在于你是否理解了编程的基本思维。就像你会不会说英语不影响你能不能成为一个好厨师——关键是你得会做菜。编程语言只是工具,编程思维才是真正的能力。
变量声明与使用:变量就像一个带标签的盒子,你往里面放一个值,以后要用的时候直接喊标签名字就行。比如 name = “张三”,就是把”张三”放进一个叫 name 的盒子里。后面你想用这个名字,直接写 name 就行了。变量是编程里最基本的概念,几乎所有代码都离不开它。
数据类型:数据有很多种”种类”,整数(比如18)、小数(比如3.14)、字符串(比如”你好”)、列表(比如 [“苹果”, “香蕉”, “橘子”],可以理解为一排格子,每个格子里放一个东西)、字典(比如 {“姓名”: “张三”, “年龄”: 18},可以理解为一个对照表,根据关键词找对应的值)。不同类型的数据能做的事情不一样——你可以把两个数字相加,但不能把”你好”和18相加。理解数据类型,就是理解你能对数据做什么操作。
变量定义x = 10 # 整数y = 3.14 # 浮点数name = "Alice" # 字符串is_active = True # 布尔值多变量赋值a, b, c = 1, 2, "three"查看数据类型print(type(x)) # <class 'int'>print(type(y)) # <class 'float'>print(type(name)) # <class 'str'>print(type(is_active)) # <class 'bool'>
运算符:加减乘除这些就不说了,和数学里一样。编程里还有比较运算符(大于、小于、等于),逻辑运算符(并且、或者、非)。比如判断”用户年龄是否大于18″,就需要用到比较运算符。
a = 21b = 10c = 0c = a + bprint ("1 - c 的值为:", c)c = a - bprint ("2 - c 的值为:", c)c = a * bprint ("3 - c 的值为:", c)c = a / bprint ("4 - c 的值为:", c)c = a % bprint ("5 - c 的值为:", c)修改变量 a 、b 、ca = 2b = 3c = a**bprint ("6 - c 的值为:", c)a = 10b = 5c = a//bprint ("7 - c 的值为:", c)
输入输出:输入就是程序接收外部信息(比如用户在键盘上打字),输出就是程序把结果显示出来(比如在屏幕上打印一行字)。这是程序和外界交互的基本方式。
x=""input(x) # 从键盘上,按下一个键,或键入一个值print(x) # 默认打印在屏幕上
内存管理(基础认识即可):你只需要知道一个基本概念——程序运行时,数据是存在内存(RAM)里的。内存是有限的,程序不用了的数据应该及时清理掉,不然内存会越来越满,程序就越来越慢甚至崩溃。好在Python会自动帮你做大部分清理工作(这叫”垃圾回收”),你不需要手动管理。但知道这个概念,有助于你理解为什么程序有时候会”卡”或者”占内存很大”。
你可以参考某位民间高手写的入门教程来学习Python等编程语言:Python3 教程 | 菜鸟教程
简单面向对象
“面向对象”听起来是个很学术的词,但它的核心思想其实非常贴近我们的生活。
想象你在经营一家工厂。你可以把”工人”这个概念抽象成一个类(Class)。类就像是一张蓝图、一个模板——它定义了工人有哪些属性(姓名、工号、岗位),以及工人能做哪些事情(打卡、干活、领工资)。
但蓝图本身不是工人。你要根据这张蓝图,创造出具体的工人,比如”张三,工号001,钳工”和”李四,工号002,焊工”。这些根据蓝图创造出来的具体工人,就是对象(Object)。
简单说:类是模板,对象是根据模板造出来的具体实例。下面是Python面向对象的简单示例代码,可以尝试阅读一下:
class MyClass:"""一个简单的类实例"""i = 12345def f(self):return 'hello world'实例化类x = MyClass()访问类的属性和方法print("MyClass 类的属性 i 为:", x.i)print("MyClass 类的方法 f 输出为:", x.f())
面向对象有三个核心概念,你大概了解就行:
封装:把数据和操作数据的方法包在一起,对外只暴露必要的接口。就像你用微波炉,你只需要知道按哪个按钮能加热,不需要知道里面磁控管的工作原理。封装的好处是降低了使用者的理解成本——你调用一个功能,不需要关心它内部是怎么实现的。
继承:子类可以继承父类的属性和方法,还能在此基础上扩展。比如你已经有了一个”工人”类,现在需要一个”技术工人”类,它除了工人的基本属性外,还有”技术等级”这个新属性。你不需要从零开始设计”技术工人”,直接在”工人”的基础上加东西就行。这就像儿子继承了爸爸的基因,但也能有自己的特点。
多态:同一个方法在不同的对象上有不同的表现形式。比如你喊”干活”,普通工人去搬砖,技术工人去修机器,管理工人去排计划。同一个指令,不同角色有不同的执行方式。这就是多态。
为什么你需要了解面向对象?因为你以后看别人的代码、让AI帮你生成代码的时候,会大量碰到 class 这个关键字。你不需要自己从零写一个类出来,但你需要看得懂——知道这里定义了一个什么模板,创建了什么对象,调用了什么方法。这就够了。
脚本语言
编程语言大致可以分为两类:编译型语言和脚本语言(解释型语言)。
编译型语言(比如C、C++、Java)就像写一篇正式的公文——写完之后需要经过”审批”(编译),把你的代码(.cpp)翻译成机器能直接执行的二进制文件(.exe),然后才能运行。好处是运行速度快,但开发流程比较繁琐。大型项目的编译工作常常是一件很耗时但又不得不做的工作。
脚本语言(比如Python、JavaScript)就像发微信消息——写完直接发送,不需要经过编译,由一个”翻译员”(解释器)逐行读取并执行。好处是开发快、调试方便,坏处是运行速度相对慢一些。
对于初学者和AI开发来说,脚本语言是首选。因为它开发效率高。你写完代码,马上就能运行看结果,改了马上又能跑,反馈周期非常短。这在初学阶段特别重要——你能快速验证自己的想法对不对。
最主要的,省去了耗时间耗脑力的编译,脚本语言还是方便和易用。
3. 前端技术基本知识
浏览器常识
你可能每天都会打开浏览器——360、Chrome、Edge、Safari……但你有没有想过,浏览器到底是来干嘛的,等同于你开的网页吗?
大多数人把浏览器理解为”看网页”的工具。这当然没错,但站在开发者的角度,你需要多理解一层:浏览器本质上是一个运行前端程序的平台,就像手机是运行App的平台一样。
你在浏览器里看到的每一个网页,其实都是一段程序。只不过这段程序不是安装在你电脑上的,而是每次你访问网站时,从服务器上实时下载到浏览器里运行的。你在浏览器里看到的各种按钮、输入框、动画、弹窗,全都是代码的运行结果。
Chrome浏览器里有一个开发者工具(按F12打开),这东西简直就是前端的”X光机”。你能看到网页的所有代码、样式、网络请求,甚至能看到哪里报错了。后面讲到调试的时候,我们会专门聊这个工具。
为什么非技术人员也要懂浏览器?因为你做AI软件产品,大部分情况下用户是通过浏览器来使用你的产品的。你需要知道你的产品在浏览器里是怎么呈现的、哪里可能出问题、怎么排查问题。浏览器是你和用户之间的桥梁,不懂这座桥,你就没法判断问题是出在桥上还是桥那边。
HTML / CSS / JavaScript 是干什么的
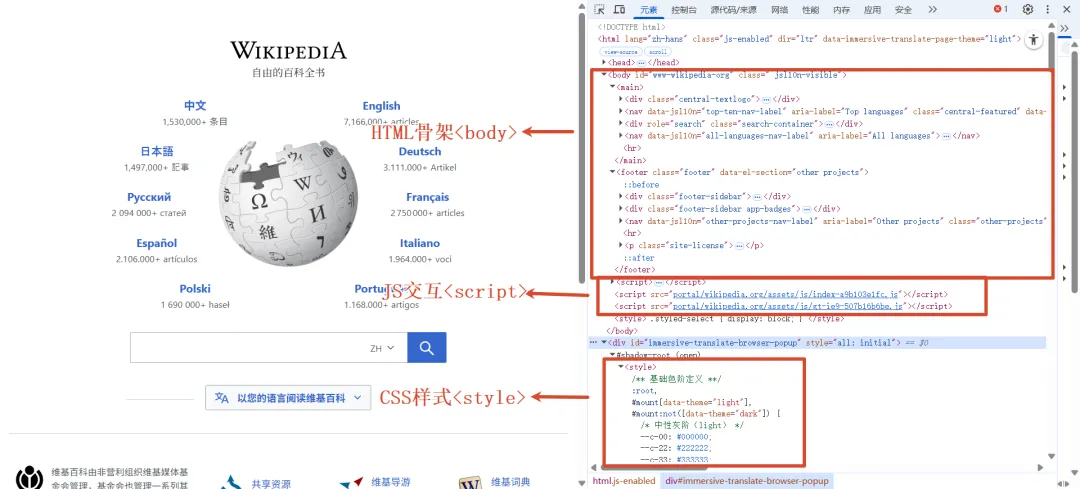
前端有三件套:HTML、CSS、JavaScript。它们三者的关系,我用一个很经典的比喻来解释——建房子。
HTML是房子的结构。它定义了页面”有什么东西”——这里有一个标题,那里有一个段落,这里有一个按钮,那里有一张图片。就像房子的图纸决定了哪里是客厅、哪里是卧室、哪里是卫生间。HTML本身不关心这些东西好不好看,它只管”有还是没有”。
CSS是房子的装修。它定义了页面”长什么样”——标题用什么字体、按钮是什么颜色、图片有多大、元素之间怎么排列。就像装修决定了墙壁刷什么颜色、地板用什么材质、家具怎么摆放。HTML搭好骨架,CSS负责美化。
JavaScript是房子里的电器和智能系统。它定义了页面的”行为”——点击按钮会发生什么、表单提交后怎么处理、页面滚动时顶部导航栏会不会固定。就像房子里的灯光会在你进门时自动亮起、窗帘会在天黑时自动关上、门铃会在有人按的时候响起来。没有JavaScript的网页就像一个没人住的样板房——好看但”死”的,不会和你互动。
“用户名”和”密码”这两个输入框、一个”登录”按钮——这是HTML搭出来的结构;
输入框有圆角边框、按钮是蓝色的、背景是渐变色——这是CSS做的装修;
你点”登录”按钮,页面会检查你有没有填内容、密码是不是太短、然后跳转到首页——这是JavaScript写的逻辑。
作为非技术人员,你不需要自己手写这三样东西——AI可以帮你生成。但你需要知道它们各自的职责,这样当页面出了问题,你能判断是结构问题(HTML)、样式问题(CSS)还是行为问题(JavaScript),然后有针对性地让AI去修。
路由
“路由”这个词来自网络领域,但在前端开发中,它指的是:用户访问不同的URL,看到不同的页面。
打个比方:你去一栋写字楼办事。一楼是前台,二楼是市场部,三楼是技术部,四楼是会议室。你想到哪个部门,就坐电梯到对应的楼层。在这里,楼层号就是URL,每个楼层就是不同的页面,电梯就是路由系统。
在你的网站里,当用户访问 yoursite.com/home 时显示首页,访问 yoursite.com/profile 时显示个人中心,访问 yoursite.com/settings 时显示设置页面——这就是路由在做的事情。它把URL和页面一一对应起来。
为什么需要路由?你可能会想,为什么不直接做几个不同的页面呢?这是因为现代的Web应用通常是单页应用(SPA)——整个网站其实只有一个HTML页面,所有的”页面切换”都是通过JavaScript在同一个页面内动态替换内容来实现的。路由系统负责记录”当前应该显示哪个内容”,并且让浏览器的地址栏和内容保持同步。
举个实际场景:你的AI聊天产品,用户在聊天页面和设置页面之间切换。如果没有路由系统,浏览器的地址栏永远不变,用户就无法通过URL直接跳转到某个页面,也无法把某个页面的链接分享给别人。有了路由,每个功能都有一个对应的URL,用户可以直接通过URL访问,体验就好多了。
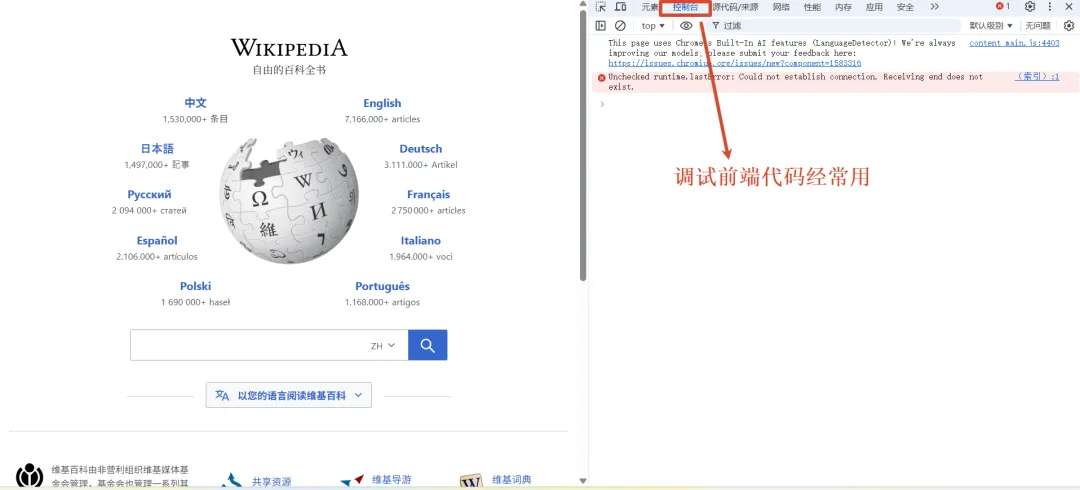
控制台(Console)调试
如果你做前端开发只学一个调试工具,那就是浏览器控制台。它是你排错的第一利器。
怎么打开?在Chrome或Edge浏览器里,按 F12 键(或者右键点击页面选”检查”),就能打开开发者工具。里面有很多标签页,你最需要关注的是Console(控制台)和Network(网络)这两个。
Console是干什么的?简单说,它就像是网页的”自言自语本”。当你的前端代码运行时,开发者可以在代码里写一些”打印语句”,让程序在控制台里输出信息。比如你代码里写了 console.log(“用户点击了登录按钮”),当用户点击登录按钮时,控制台就会显示这行文字。这就像在代码里安了一个”监控摄像头”,帮你看程序到底在做什么。
更重要的是,当代码出错时,控制台会显示红色的错误信息。这些信息会告诉你:是什么错误、在哪个文件的哪一行出错。虽然错误信息有时候看起来很吓人(满屏红色英文),但你只需要学会抓住关键信息——错误类型和出错位置,然后把这段错误信息丢给AI,AI就能帮你分析问题出在哪里。
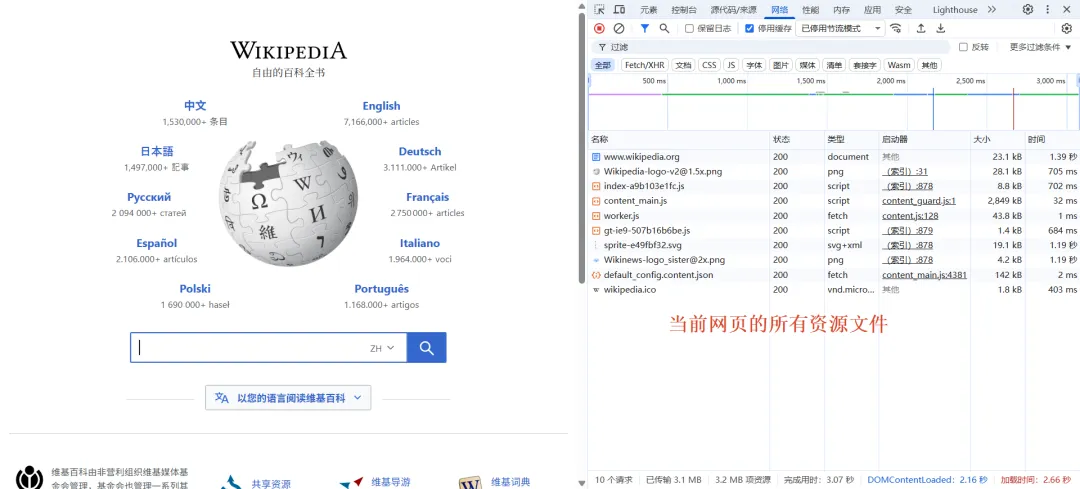
Network标签页也很实用,它能显示页面上所有的网络请求——你的前端向服务端发了哪些请求、请求成功了没有、服务端返回了什么数据。如果页面加载不出来数据,你第一时间看Network,就能判断是前端没发出请求,还是后端没返回正确数据。
一个真实的场景:用户反馈”页面上的数据不显示”。你怎么排查?打开控制台,先看Console有没有红色报错,再看Network里数据接口请求有没有成功。90%的前端问题,通过这两个标签页就能定位到原因。
4. 后端技术基本知识
业务执行层
如果说前端是用户能看到的”门面”,那后端就是藏在幕后的”厨房”。用户在前面点菜(发送请求),后厨负责洗菜、切菜、炒菜、出餐(处理逻辑、操作数据、返回结果)。
在很多软件系统里,通常都是由后端来实现真正的业务逻辑的。
后端做的事情,简单说就是接收前端发来的数据、解析数据、调用外部服务、保存数据、返回结果——都是后端在干活。前端只负责展示和收集用户输入,真正的”大脑”在后端。
理解业务执行层的关键在于:你要能梳理清楚一个功能的完整处理流程。用户做了什么操作 → 后端需要处理哪些步骤 → 每一步的输入和输出是什么 → 最终返回什么结果给前端。这个流程理清楚了,你的代码架构就清晰了,AI也能更准确地帮你实现。
通常,我们可以通过画流程图的方式来梳理业务流程,流程顺了,代码就好写的,AI写出来的代码也会更加确定、更符合自己的预期。
常用框架
写后端代码,你当然可以从零开始,自己处理每一个细节——接收请求、解析参数、连接数据库、处理异常……但这就像盖房子时自己从烧砖开始做一样,太慢了。
框架就是别人帮你搭好的房子骨架。地基打好了、承重墙砌好了、水电管道预埋好了,你只需要在此基础上做”装修”——也就是写你自己的业务逻辑。
Flask:轻量级,像一个清水房——只给你最基本的设施,剩下的你自己搞。优点是简单灵活,缺点是很多功能需要自己实现。适合小项目或学习入门。
FastAPI:目前Python后端的”当红炸子鸡”。它的特点是性能好、写法简洁,而且自带接口文档。做AI项目非常推荐用FastAPI,因为它天生支持异步处理——调用AI模型这种耗时操作,用异步可以大大提高效率。
Django:重量级,像一个精装房——数据库操作、用户认证、后台管理界面全都帮你做好了。适合快速搭建功能完善的网站,但对于小项目来说有点”杀鸡用牛刀”。
不使用任何框架,纯手搓,耗时耗力,没必要from http.server import BaseHTTPRequestHandler, HTTPServerimport json自定义请求处理器class RequestHandler(BaseHTTPRequestHandler):# 处理POST请求def do_POST(self):# 步骤1:手动获取请求体长度content_length = int(self.headers['Content-Length'])# 步骤2:手动读取原始数据post_data = self.rfile.read(content_length)# 步骤3:手动解码字节数据为字符串post_str = post_data.decode('utf-8')# 步骤4:手动解析JSON为字典data = json.loads(post_str) # 步骤5:手动处理数据 name = data.get("name") age = data.get("age") # 步骤6:手动设置响应头、状态码、响应格式 self.send_response(200) self.send_header('Content-type', 'application/json') self.end_headers() # 步骤7:手动构造响应并返回 response = {"msg": f"你好{name},年龄{age}"} self.wfile.write(json.dumps(response).encode('utf-8'))启动服务器if name == 'main':server = HTTPServer(('0.0.0.0', 8000), RequestHandler)print("原生服务启动:http://127.0.0.1:8000")server.serve_forever()
使用FastAPI,简单易用,代码量少,功能完善from fastapi import FastAPIfrom pydantic import BaseModel1. 定义数据格式(自动校验类型)class UserData(BaseModel):name: str # 必须是字符串age: int # 必须是数字2. 创建应用app = FastAPI()3. 直接定义接口,自动接收解析数据@app.post("/user")def get_user(data: UserData):# 直接使用解析好的数据,无需任何手动操作return {"msg": f"你好{data.name},年龄{data.age}"}
Node.js生态里最常用的是Express,和Flask类似,也是轻量灵活型的。
框架选什么不重要,重要的是理解框架帮你解决了什么问题。你只需要知道:有了框架,你不用重复造轮子,专注写业务逻辑就行。具体选哪个框架,等你的项目确定需求了再决定。
服务器常识
“服务器”这个词你肯定听过,但很多人对它的理解是模糊的。这里建立一个初步认识。
服务器,其实就是一台一直开着的电脑。它和你家里的电脑在硬件上没有本质区别,只不过它被放在了数据中心里,连着高速网络,7×24小时不关机,专门用来运行各种服务程序。
端口(Port):一台服务器上可以同时运行很多个服务,端口就是用来区分它们的。就像一栋大楼有很多个房间,每个房间有不同的门牌号。你在浏览器里访问 http://localhost:3000,其中3000就是端口号,意思是”连接到这台电脑的第3000号门”。常见端口有:80(HTTP)、443(HTTPS)、3306(MySQL数据库)、6379(Redis缓存)等。
进程(Process):每个正在运行的程序就是一个进程。你在终端里启动了一个Web服务,终端里就运行着一个进程。如果你再开一个终端窗口启动另一个服务,那就是两个进程。一个服务出问题(比如崩溃了),不会影响其他服务,因为它们是独立的进程。
并发(Concurrency):服务器要同时处理很多用户的请求。就像一家餐厅同时来了20桌客人,厨师不可能一桌一桌地做,得同时炒好几锅菜。服务器处理并发的能力决定了它能在同一时间服务多少用户。这是后端性能优化的核心话题,初学阶段你只需要知道这个概念就行。
一个实际场景:你开发了一个AI聊天应用,部署到服务器上。用户A和用户B同时发来消息,服务器需要同时处理这两个请求。如果处理得慢,用户就会感觉”系统好卡”。这就是并发问题。解决方式有很多(多线程、异步、消息队列等),你后续会逐步接触到。
RESTful API
API的概念我们在后面的章节会详细讲,这里先说最常见的一种API设计风格——RESTful。
RESTful的核心理念特别简单:用HTTP的四种方法(GET,POST,PUT,DELETE,你只需要熟悉这四种方法)来对应四种数据操作。
GET:查看联系人。就像你说”给我看看张三的信息”——只读,不修改。
POST:添加联系人。就像你说”帮我新增一个联系人,名字叫李四”——新增数据。
PUT:修改联系人。就像你说”把张三的电话改成138xxxx”——更新已有数据。
DELETE:删除联系人。就像你说”把王五从通讯录里删掉”——删除数据。
在RESTful风格里,每个URL代表一种资源,HTTP方法代表你要对这个资源做什么操作。比如:
GET /users/123 获取ID为123的用户信息
PUT /users/123 更新ID为123的用户信息
DELETE /users/123 删除ID为123的用户
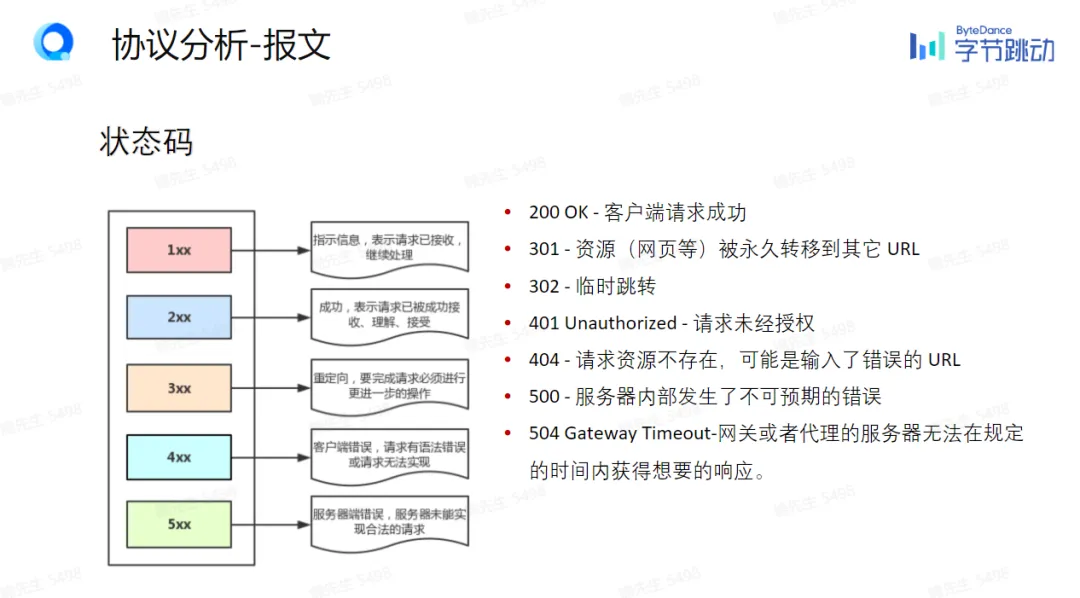
为什么你需要知道这个?因为前后端之间几乎都是通过RESTful API来通信的。你在前端调用一个接口,实际上就是向某个URL发了一个HTTP请求。你不需要自己设计API(AI可以帮你做),但你需要看得懂接口文档,知道GET和POST的区别,知道200(成功)、404(找不到)、500(服务器错误)这些状态码大概是什么意思。
知道以上提到的常见状态码就够用了,如果想知道更多,可以查阅:HTTP状态码
https://zh.wikipedia.org/wiki/HTTP%E7%8A%B6%E6%80%81%E7%A0%81
学会调试
后端的问题往往比前端更难发现。前端出了问题,用户直接能看到——按钮点不了、页面乱了、数据没显示。但后端出了问题,用户可能只看到”加载中”转了半天圈,或者一个冷冰冰的”服务器错误”提示,完全不知道发生了什么。
看日志是最基本也最重要的手段。所谓日志,就是程序在运行过程中自动记录的文字信息——”几点几分,哪个用户发起了什么请求””几点几分,数据库查询成功,返回了3条数据””几点几分,调用AI接口超时,错误码504″。
好的开发者会在代码的关键位置加上日志输出,这样当程序出问题时,就能通过日志回溯”案发现场”。就像商场里的监控摄像头——平时没人看,但出了事,回放录像就能找到线索。
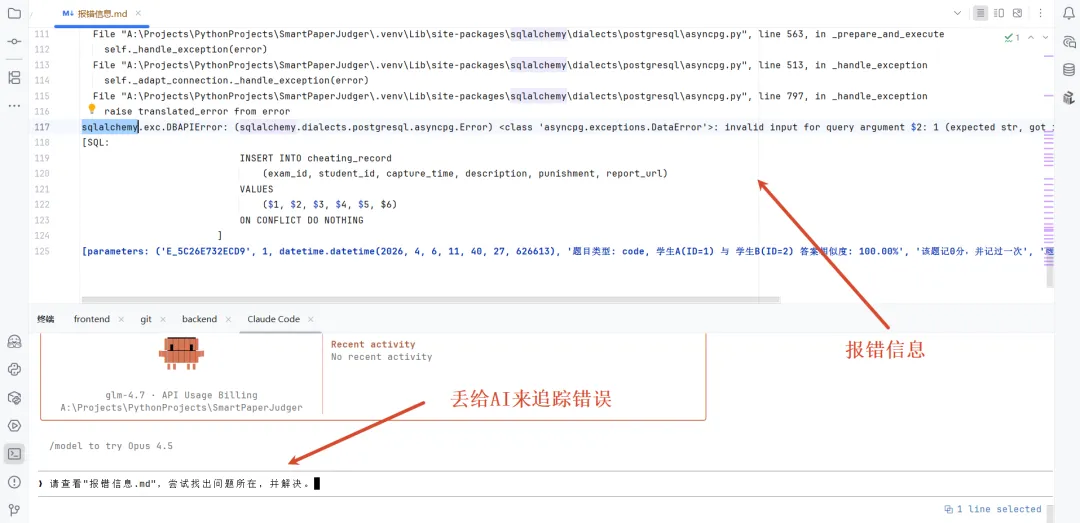
一个实际案例:用户反馈”AI生成的结果很久才出来,有时候还出不来”。你怎么查?先看后端日志,找到这个用户对应的请求记录,看看是哪一步卡住了——是接收请求慢了?还是调用AI接口等太久?还是数据库写入出了问题?日志会告诉你答案。
打断点是更高级的调试方式。你可以在代码的某一行设一个”断点”,程序运行到这一行时会自动暂停,你可以查看此刻所有变量的值,一步步往下执行,观察程序的状态变化。这就像在高速公路上设了一个收费站,每辆车经过都要停下来检查。VSCode和PyCharm都有非常方便的断点调试功能。
初学阶段,你先把”看日志”练好就够了。让AI在生成代码时帮你加上必要的日志输出,出了问题先看日志,把日志信息丢给AI分析,大部分问题都能解决。
5. 数据库技术基本知识
SQL入门
如果说后端是”厨房”,那数据库就是”仓库”。厨房需要食材才能做菜,后端需要数据才能处理业务。所有的用户信息、商品数据、聊天记录、AI对话历史,都存在数据库里。
要和数据库打交道,你需要学一点SQL(Structured Query Language,结构化查询语言)。SQL就是数据库的”操作指令”,你用它告诉数据库你要做什么。
好消息是,SQL非常接近自然语言,语法直白易懂。你只需要掌握四条最基本的语句:
SELECT查询数据。就像你说”帮我找一下所有年龄大于20岁的用户”。
SELECT * FROM users WHERE age > 20;
这行代码的意思就是:从users表里找出所有age大于20的记录。* 代表”所有字段”。
INSERT插入数据。就像你说”帮我记一条新信息”。
INSERT INTO users (name, age) VALUES ('张三', 25);
这行代码的意思是:往users表里插入一条新记录,名字叫张三,年龄25。
UPDATE更新数据。就像你说”帮我把张三的年龄改成26″。
UPDATE users SET age = 26 WHERE name = '张三';
DELETE删除数据。就像你说”帮我把王五的信息删掉”。
DELETE FROM users WHERE name = '王五';
注意UPDATE和DELETE语句里的WHERE条件——这非常重要。如果你忘了写WHERE,就会把整张表的数据都改了或删了。这就像你说”把所有员工工资涨500″,而不是”把张三的工资涨500″。后果你懂的。所以用这两条语句的时候一定要小心,先SELECT确认一下要操作的数据范围,再执行修改或删除。
SQL还有JOIN(连接多张表)、GROUP BY(分组统计)、ORDER BY(排序)等进阶操作,你现阶段不需要掌握,知道有这些功能就行。用到的时候再学,现学现用完全来得及。
几乎所有的软件都需要数据库,因此SQL是必须掌握的技术。这样给出一个SQL命令查阅的网站,一遇到不会的指令,都可以直接查:SQL 教程 | 菜鸟教程:
https://www.runoob.com/sql/sql-tutorial.html
常用数据库
数据库有很多种,不同类型适合不同的场景。你不需要全部学,只需要了解最常见的几个。
-
关系型数据库——可以理解为”表格型数据库”,数据存在一张张结构化的表格里,就像Excel表格一样,有行有列,格式规整。
-
MySQL:最经典的关系型数据库,用的人最多,教程最丰富,遇到问题最容易搜到答案。很多中小型项目的首选。如果你不知道选什么数据库,选MySQL基本不会出错。
-
PostgreSQL:功能比MySQL更强大,尤其在处理复杂数据类型、地理信息和全文搜索方面更有优势。近年来在开发者社区中口碑越来越好,很多AI相关项目选择PostgreSQL作为主数据库。
非关系型数据库(NoSQL)——不要求表格式的结构,数据可以更灵活地存储。
-
MongoDB:最流行的非关系型数据库。它存储数据的方式更像JSON格式——你可以把一条记录存成这样:{“name”: “张三”, “age”: 25, “skills”: [“Python”, “AI”]},非常灵活。适合存储结构不固定、经常变化的数据。
-
-
怎么选?初学阶段,我建议你从PostgreSQL开始。原因很简单:关系型数据库的概念更直观(就是表格嘛),SQL语言是通用的,学会了一种,其他的也很容易上手,并且PostgreSQL相较于MySQL要更安全、更先进也更规范。MongoDB、Redis、Neo4J等你遇到确实需要灵活数据结构的场景再学不迟。
一个帮你理解的比喻:关系型数据库就像一个严格的图书管理员——每本书必须按编号放在指定的位置,不能乱放,但查找起来非常高效。非关系型数据库就像一个大仓库——东西随便堆,但贴了标签,找的时候按标签找就行,灵活但有时候不够规范。
如何与数据库交互
知道了数据库是什么,下一个问题就是:你的代码怎么跟数据库”说话”?
第一种:直接写SQL语句。你的后端代码里直接写SQL,发送给数据库执行。
比如Python里用pymysql库连接MySQL:
cursor.execute("SELECT * FROM users WHERE age > 20")results = cursor.fetchall()
这种方式最直接,你对数据库的操作完全可控。但缺点是——SQL语句写多了,代码里到处都是字符串拼接,又长又难维护,还容易出错(比如前面说的忘记写WHERE条件)。
第二种:用ORM(Object-Relational Mapping,对象关系映射)。ORM的思路是:你不直接写SQL,而是用编程语言的方式来操作数据库。
比如用Python的SQLAlchemy ORM:
users = session.query(User).filter(User.age > 20).all()
这行代码做的事情和上面那条SQL一模一样,但写起来更像Python代码,读起来也更直观。ORM会自动帮你把Python代码翻译成SQL语句,发给数据库执行。
ORM的好处是代码更优雅、更安全(自动防止SQL注入攻击)、更好维护。缺点是增加了一层抽象,有时候你想做一些复杂的查询,ORM的写法反而比直接写SQL更麻烦。
选哪种?对于初学者和小项目,我建议用ORM。它上手快,不容易出错。等你遇到ORM搞不定的复杂场景,再直接写SQL也行。两者并不冲突,可以混用。
-
-
-
后端收到数据,通过ORM或SQL把数据写入数据库;
-
-
你看,数据库是整个流程中不可或缺的一环。理解了这个流程,你就知道你的数据从哪里来、到哪里去、中间经过了哪些环节。
6. 软件运行环境基本知识
写代码和让代码跑起来,是两码事。你写好的程序要能运行,就得先搞懂”环境”这个概念。这一节,我们聊聊软件赖以生存的土壤——运行环境。
操作系统
你平时用的电脑,大概率是Windows系统。但如果你以后要把做好的AI软件部署到服务器上,让它24小时对外提供服务,那大概率会运行在Linux系统上。至于macOS,苹果电脑自带的系统,在开发者群体中也很受欢迎。
-
Windows:面向普通用户,图形界面友好,日常办公、打游戏的首选。但在服务器领域存在感不强,主要是因为它收费、资源占用大、且对开发者不够”开放”。
-
Linux:开源、免费、轻量、稳定,是服务器领域的绝对主力。它没有花里胡哨的图形界面,主要通过命令行操作——就像我们前面讲过的”终端”。全球超过90%的服务器跑的都是Linux。
-
macOS:基于Unix(和Linux是”亲戚”),开发体验好,尤其适合做前端和iOS开发。但设备价格门槛较高。
三种主流操作系统没有孰高孰低的说法,大家都有各自适用的场合。对于Windows来说,我们许多普通人在这上面做测试开发,直到要投入真正服务使用了,才放到Linux上。
不同操作系统之间的差异,读者还是有必要知道一些基本的:假设你用Python写了一个AI聊天机器人,在自己Windows电脑上测试没问题。现在你想把它放到云服务器上,让朋友也能访问。你买了一台阿里云服务器,发现它是Linux系统。这时候你就需要知道:在Windows上安装Python的方式(双击安装包),和Linux上安装Python的方式(命令行输入 sudo apt install python3)是完全不同的。而且很多在Windows上能跑的程序,到了Linux上可能会因为路径格式不同(Windows用反斜杠 \,Linux用正斜杠 /)而报错。了解这些差异,你就能快速定位”为什么在我电脑上能跑,在服务器上就挂了”这类问题。
依赖
你写的程序几乎不可能”从零开始造轮子”。比如你想用Python处理Excel表格,不需要自己写一个Excel解析器——早就有人写好了,你只需要”引入”别人写好的代码包就行。这些别人写好的、你的程序运行时需要用到的代码包,就叫”依赖”。
Python的依赖管理工具叫pip,它是Python官方的包管理器。比如你想用 openai 这个包来调用ChatGPT的接口,只需要在终端输入 pip install openai,pip就会自动从网上下载这个包并安装到你的电脑上。之后你的代码里就可以写 import openai 来使用它了。
假设你要做一个”AI写周报”的小工具。你的代码需要:openai(调用大模型生成文字)、python-docx(生成Word文档)、flask(做一个简单的网页界面)。这三个包就是你的项目”依赖”。你在自己电脑上用 pip install 安装好了,程序跑得很顺畅。但当你把代码发给同事,他直接运行就报错了——因为他电脑上没装这些包。这就是为什么后面我们会学到,项目里通常会有一个 requirements.txt 文件,里面列出了所有依赖包及其版本号。别人拿到你的代码后,只需一行 pip install -r requirements.txt,就能一次性装好所有依赖。
虚拟环境
理解了”依赖”之后,马上就会遇到一个头疼的问题:不同项目可能需要同一个包的不同版本。比如你的”AI写周报”项目需要 openai 1.0版本,而另一个”AI翻译”项目需要 openai 2.0版本。如果你在系统里全局安装了2.0版本,那”AI写周报”可能就跑不了了。
怎么解决?答案是虚拟环境。虚拟环境就像给每个项目单独建一个”小房间”,每个房间里可以安装不同版本的依赖包,互不干扰。Python中常用的虚拟环境工具有 venv、conda 等。
实际案例:假设你同时在做两个项目。项目A是一个数据分析工具,依赖 numpy 1.20版本;项目B是一个图像识别应用,依赖 numpy 1.26版本。如果你不用虚拟环境,装了1.26版本后,项目A就会因为版本不兼容而报错。但如果你给每个项目各建一个虚拟环境,就像给它们各配了一个独立的小仓库,项目A的仓库里放1.20版本,项目B的仓库里放1.26版本,互不影响。创建虚拟环境的命令也很简单,Python内置的 venv 只需要两行命令:python -m venv myenv(创建)和 myenv\Scripts\activate(激活)。激活后,你在终端里安装的任何包都只会装在这个虚拟环境里,不会影响其他项目。这是Python开发中非常基础但极为重要的习惯,建议从一开始就养成。
抽象的东西就是很难理解,别担心,我们在接下来的文章中会通过一步步实践帮助深化理解。
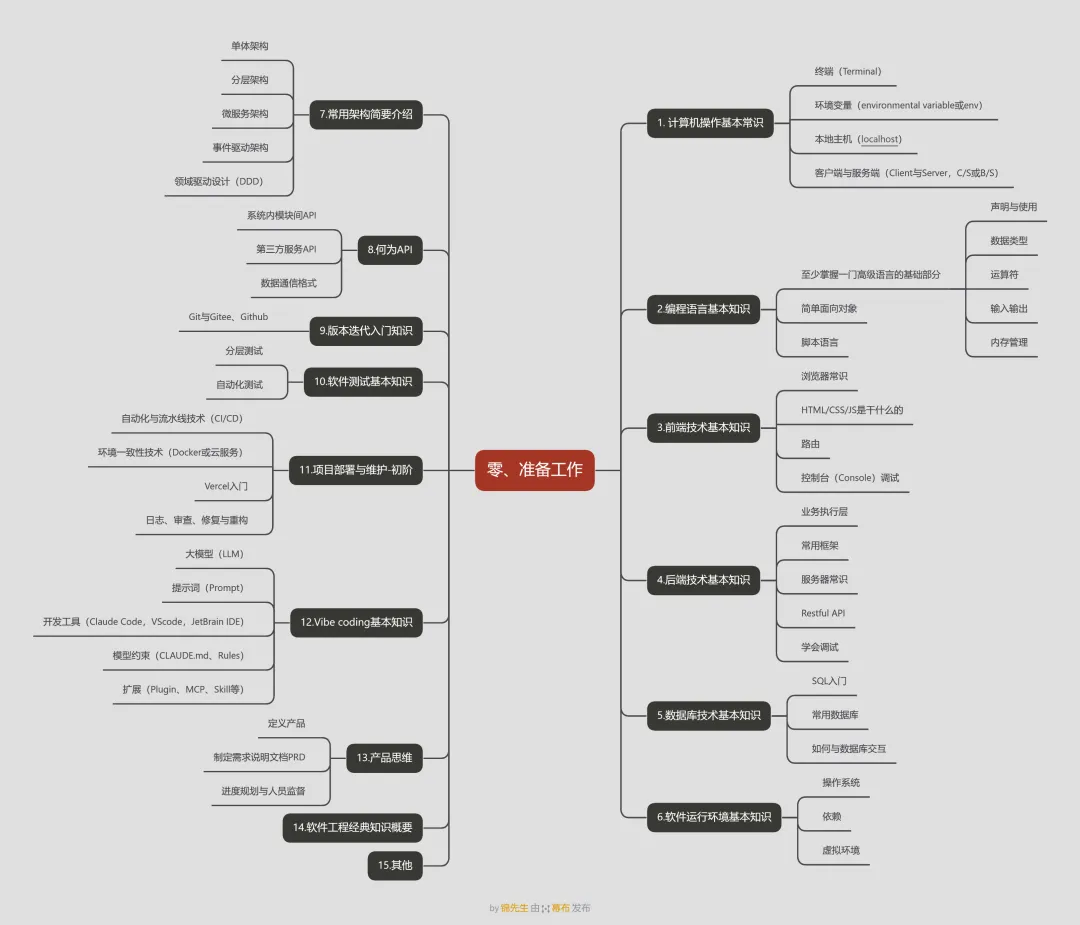
7. 常用架构简要介绍
什么是”架构”?如果用盖房子来类比,架构就是这栋房子的整体结构——几室几厅、承重墙在哪里、水电管线怎么走。代码架构决定了你的软件是怎么组织的:各个功能模块放在哪里、模块之间怎么通信、数据怎么流转。
好的架构让软件清晰、好维护、好扩展;差的架构则会让代码变成一团乱麻,改一个功能牵连一大片。下面介绍几种最常见的架构模式,你不需要现在就精通,但至少要知道它们长什么样、适合什么场景。
单体架构
单体架构是最简单直接的架构方式:把所有功能——用户管理、订单处理、支付、消息通知——全部放在一个项目里。
它的好处是简单,初期开发速度快,部署也方便(一个项目打一个包就行)。但缺点也很明显:当项目越来越大、功能越来越多,这个”单体”就会变得臃肿不堪。改一个小功能,可能需要重新部署整个项目;一个模块出了Bug,可能拖垮整个系统。
实际案例:假设你做了一个在线教育平台,最早只有”视频播放”功能,代码全写在一个项目里,跑得好好的。后来陆续加了”直播课堂””作业提交””在线考试””讨论区””支付系统”……所有功能的代码还是堆在同一个项目里。这时候问题来了:某天”讨论区”模块出了个Bug导致服务器崩溃,结果”在线考试”也跟着挂了——明明考试功能和讨论区没有任何关系,但就因为它们住在”同一栋楼”里,一个房间着火,整栋楼都得疏散。这就是单体架构的典型困境。所以单体架构适合小型项目或快速验证想法的原型阶段,但不太适合长期发展的大型系统。
分层架构
分层架构是最经典、应用最广泛的架构模式之一。它的核心思想是”按职责划分”,把整个系统分成几个”层”,每层只做自己该做的事,层与层之间通过明确定义的接口交互。
-
表现层(UI层):负责和用户打交道,展示界面、接收用户操作。比如网页的前端页面。
-
业务逻辑层(Service层):负责处理核心逻辑。比如”用户下单”这个动作涉及的计算、判断、规则校验。
-
数据访问层(DAO层):负责和数据库交互,存取数据。
还是拿在线教育平台举例。当用户点击”购买课程”按钮时,请求会这样流转:首先,表现层的网页把”购买”请求发送给后端;然后,业务逻辑层开始干活——检查用户余额够不够、课程是否已购买、有没有优惠券可用;最后,数据访问层负责把订单信息写入数据库、更新用户余额记录。每一层只关注自己的事,表现层不需要知道数据库长什么样,数据访问层也不需要知道页面是长是圆。这种”各管各的”设计,让每一层可以独立修改而不影响其他层。比如你要把网页版升级为App版,只需要改表现层,业务逻辑和数据访问完全不用动。这也是为什么分层架构是企业级开发中最常见的选择。
微服务架构
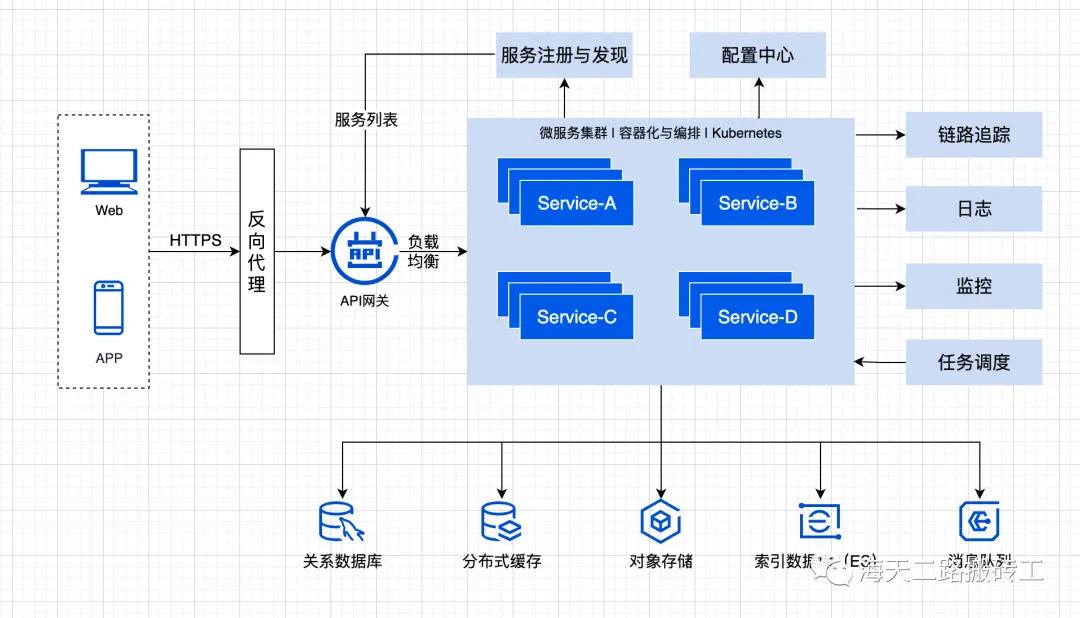
微服务架构是近年来最火热的一种架构风格。它的核心思路是:把一个大系统拆分成多个”小服务”,每个服务独立运行、独立部署、独立维护,服务之间通过网络通信。
听起来和”分层架构”有点像?其实不同。分层架构是在”一个项目内部”划分层次,而微服务是真正把系统拆成了”多个独立项目”。每个微服务可以有自己的数据库、自己的技术栈,甚至可以由不同的团队开发。
如果采用微服务架构,你可能会把它拆成这些独立服务:用户服务(管理注册登录)、课程服务(管理课程内容)、订单服务(处理购买流程)、支付服务(对接支付渠道)、通知服务(发邮件/短信/推送)。每个服务独立运行在自己的进程中。
这样做的好处是什么?假设”双十一”大促时,订单量和支付请求暴增,你只需要给”订单服务”和”支付服务”增加服务器资源,其他服务不用动——不像单体架构那样,为了应对一个模块的高流量,不得不给整个系统加机器。
当然,微服务也有代价:系统变复杂了,服务之间的网络通信可能出问题,数据的统一管理也更困难。所以它更适合规模较大的系统,小型项目用单体或分层就够了。
事件驱动架构
前面几种架构都是”你叫我做,我才做”的模式——用户发起一个请求,系统处理完返回结果。但现实中有些场景是:”发生了某件事,相关方自动做出响应”,这就是事件驱动架构。
在这个架构中,核心概念是”事件”(Event)。当某个动作发生时,系统会发出一个事件通知,所有关注这个事件的模块都会收到通知并执行各自的操作。模块之间不需要直接调用对方,而是通过”事件”来通信。这种通信方式通常借助消息队列(如RabbitMQ、Kafka)来实现。
如果你有了解过回调函数,这里你会理解得更深刻;如果没有,也没有关系,事件驱动更像是一种思想,现在经常被融入到其他架构设计里去,我们后面还会提到。
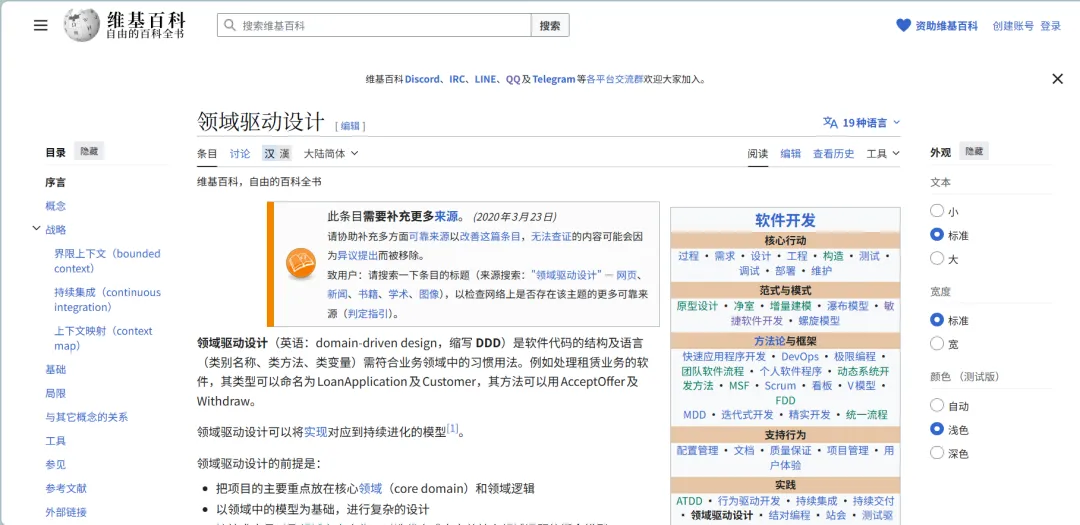
领域驱动设计(DDD)
领域驱动设计是一种”从业务出发”来设计软件的方法论。它的核心主张是:不要一上来就想”我要用什么技术、怎么建数据库”,而是先搞清楚”这个业务到底是怎么回事”。
DDD中最重要的概念是领域模型——对业务领域的抽象描述。比如做电商,领域模型可能包括”商品””订单””用户””支付”等核心概念,以及它们之间的关系和业务规则。先把业务模型理清楚,再映射到技术实现。
这种”业务优先”的思想非常重要,因为在AI编程中,一旦将业务理清楚,工作就已经完成了一半。
8. 何为API
API,全称Application Programming Interface,翻译过来是”应用程序编程接口”。这个名字听起来很唬人,但概念其实很简单:API就是软件之间沟通的接口。
打个生活中的比方:你去餐厅吃饭,你不需要自己进厨房炒菜,你只需要看菜单、跟服务员点菜。服务员把你的需求传给厨房,厨房做好后再通过服务员端给你。在这个场景中,服务员就是API——你(调用方)不需要知道厨房(服务方)内部怎么运作,你只需要按照菜单(API文档)告诉服务员你要什么,就能得到你想要的结果。
也就是说,使用API,你根本不需要管内部是怎么实现的,只需要知道输入输出的数据格式是啥,就完全够了。这很方便,既可以减少造轮子的工夫,也便于对架构中的各模块进行划分与通信。
理解了API的本质之后,我们来看看它在实际开发中的两种主要形态。
系统内模块间API
在一个软件系统中,前端和后端通常是两个独立的模块。前端负责展示界面、接收用户操作,后端负责处理业务逻辑、存取数据。它们之间怎么通信?靠的就是API。
前端通过API向后端发送请求(”帮我查一下这个用户的信息”),后端处理完后通过API把结果返回给前端。这种”前后端分离”的模式已经是现代Web开发的主流。
第三方服务API
除了系统内部的API,还有一种更常见的场景:调用外部服务提供的API。你不需要自己搭建AI模型、不需要自己实现支付功能、不需要自己做地图定位——这些都有专业公司提供API,你只需要”调用”就行。
在AI开发领域,第三方API尤其重要。OpenAI(ChatGPT背后的公司)、Anthropic(Claude背后的公司)、国内的百度文心一言、阿里通义千问等,都提供了API服务。你只要按照它们的文档,在代码里发一个HTTP请求,就能调用强大的AI模型来生成文字、分析图片、处理语音。
现在很多软件都喜欢加个AI客服,一旦你理解了以上API的定义,你就会明白这个”AI客服”也没什么了不起的,本质上还是调用的别人的服务——AI自动回答。你不需要自己训练一个语言模型(那需要几百万美元的服务器和海量数据),你只需要调用OpenAI或国内大模型的API。具体来说,你的后端代码会向大模型服务商的服务器发送一个HTTP请求,请求里包含了用户的问题。大模型服务器处理完后,把AI的回答返回给你。你的后端再把回答转发给公众号用户。整个过程中,你只需要关注”怎么调API”和”怎么处理返回结果”,AI模型的训练、优化、部署全部由服务商搞定。这就是第三方API的魅力——让个人开发者也能用上顶尖的AI能力。
数据通信格式
不管是系统内部API还是第三方API,数据在传输时都需要遵循一定的格式。就像两个人对话,得说同一种语言才能沟通。在软件开发中,最常用的”语言”有两种:
JSON(JavaScript Object Notation)是目前最主流的数据格式。它本质上是一种键值对(key-value)的结构,长这样:
{"username": "张三","score": 95,"comment": "结构清晰,论点有力"}
看到没?就算你不是程序员,大概也能猜出这段数据在说什么。JSON之所以流行,正是因为它简洁、可读性强、几乎所有编程语言都支持。
XML(eXtensible Markup Language)是一种更早期的数据格式,长这样:
<user> <username>张三</username> <score>95</score> <comment>结构清晰,论点有力</comment></user>
XML比JSON更冗长,但结构更严格。现在新项目中已经很少使用XML了,但你可能在对接一些老旧系统(比如银行接口、政府部门系统)时还会遇到。
9. 版本迭代入门知识
你有没有过这样的经历:写了一份报告,改了好多版,最后桌面上一堆文件——”报告最终版.docx””报告最终版2.docx””报告打死不改版.docx””报告真的最终版.docx”……
代码开发也是一样。一个项目从开始到完成,要经历无数次修改:新增功能、修复Bug、调整逻辑……如果每次修改都靠复制文件夹来”存档”,迟早会乱成一锅粥。而且多人协作时更容易出问题:你改了A文件,同事也改了A文件,两个人的改动怎么合并?
这就是版本控制工具要解决的问题。而Git,是当今最流行、最强大的版本控制工具,没有之一。
Git与代码托管平台
Git的核心功能是帮你追踪代码的每一次修改,就像一个超级”存档系统”。你可以随时回到任何一个历史版本,查看每次改了什么、谁改的、为什么改。
但Git只是一个本地工具,它帮你管理自己电脑上的代码版本。如果多人协作,或者你想在其他电脑上也能访问代码,就需要一个”云端仓库”来存储和同步代码。这就是代码托管平台的作用。
最常用的两个平台就是Github和Gitee了。GitHub全球最大的代码托管平台,可以说是程序员的”社交网络”。开源项目几乎都在这里。不过国内访问Github有时不太稳定,因此就有了Gitee(码云)这样平替Github的国内最大的代码托管平台,这里速度快,几乎不会有网络连接的问题,适合国内开发者使用。
提交(commit)——相当于游戏里的”存档”。每完成一个阶段性工作(比如修了一个Bug、写完一个功能),就做一次commit。每次commit都会生成一个唯一的版本号,并记录修改内容、修改时间和修改人。这样你随时可以回溯到任何一个历史版本。
分支(branch)——相当于平行宇宙。你可以从主线上分出一条”支线”,在支线上开发新功能或做实验,不会影响主线。等支线上的工作完成并验证没问题后,再把成果合并回主线。
合并(merge)——把分支上的代码变更合并到另一条分支上。合并时如果两个人改了同一个文件的同一个地方,就会产生”冲突”(conflict),需要手动决定保留谁的修改。虽然处理冲突有些麻烦,但这是多人协作不可避免的一部分,Git提供了清晰的工具来帮你完成。
放心,在接下来的每一步实践当中,我们都会一直用git来对版本进行管理,慢慢学会基础操作。
10. 软件测试基本知识
前面我们花了很多篇幅讲怎么写代码、怎么设计系统。但写完代码不等于软件就”能用”了。事实上,如果软件没有经过足够多的测试,是绝不应该投入使用的。
因为人在测试自己写的代码时,往往会不自觉地”按照正确的路径操作”,忽略那些”异常情况”。而用户在使用软件时,操作方式千奇百怪——你永远不知道用户会做出什么出乎意料的操作。
所以,我们需要一套系统化的测试方法来保证软件质量。下面介绍两种核心测试理念。
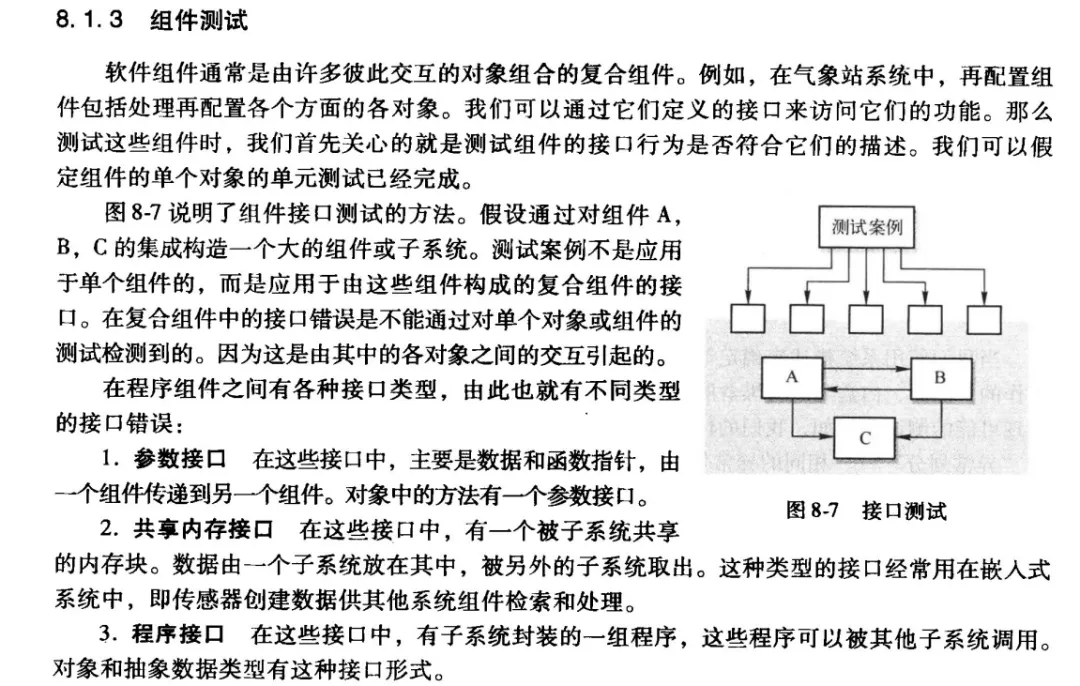
分层测试
测试不是一锅炖的,而是分层次的。就像建房子:先检查每块砖头是否合格(单元测试),再检查每堵墙是否牢固(集成测试),最后检查整栋房子能不能住人(端到端测试)。
单元测试(Unit Test)是最底层的测试,针对的是代码中最小的可测试单元——通常是一个函数或一个方法。它的目标是确保每一小块代码都能正确工作。
假设你写了一个函数 calculate_discount(price, level),根据用户的会员等级计算折扣价。单元测试就是写几组测试用例来验证这个函数:传入价格100、等级”VIP”时,返回值是不是80?传入价格50、等级”普通”时,返回值是不是50(没有折扣)?传入负数价格时,函数是不是能正确报错而不是崩溃?单元测试的好处是”快”——运行速度快,出问题时能精确定位到是哪个函数出了Bug。在我们的专栏中,开发环节会特别强调”每写完一个模块,同步写单元测试,测一个写一个”。
集成测试(Integration Test)是在单元测试之上,测试多个模块组合在一起时能不能正常协作。单个函数可能没问题,但函数和函数之间”对接”的时候可能会出岔子。
你的”批改模块”单独测试没问题(单元测试通过),你的”数据库模块”单独测试也没问题。但当它们组合在一起时——用户提交作文 → 调用AI批改 → 把结果存入数据库 → 返回给用户——这个完整链条跑得通吗?会不会AI返回的数据格式和数据库要求的格式不一致?
集成测试就是用来发现这类”接口对接”层面的问题——通常,这是暴露问题最多的环节。
端到端测试(End-to-End Test,简称E2E测试)是最顶层的测试,模拟真实用户的完整操作流程,从打开页面开始,到完成整个操作结束,验证整个系统从前端到后端到数据库的全链路是否正常。
一个完整的端到端测试可能是这样的:打开浏览器 → 访问你的AI作文批改网站 → 输入账号密码登录 → 在文本框输入一篇作文 → 点击”批改”按钮 → 等待结果返回 → 验证页面上是否正确显示了分数和评语 → 退出登录。这条链路覆盖了前端界面、后端API、AI模型调用、数据库存取等所有环节。端到端测试最接近真实用户的使用场景,但也最慢、最脆弱(任何一个环节出问题都会导致测试失败)。
所以在实际项目中,通常遵循”金字塔原则”:单元测试最多(底层),集成测试适中(中层),端到端测试最少(顶层)。
自动化测试
上面说的这些测试,如果都靠人手动一个个去操作、肉眼检查结果,那效率太低了,而且容易遗漏。尤其是当代码修改后,你需要重新验证所有功能是否正常——这在软件行业叫”回归测试”,随着功能越来越多,手动回归测试简直就是噩梦。
自动化测试就是用代码来写测试代码。你写好测试脚本后,只需一条命令就能自动运行成百上千个测试用例,几秒钟内告诉你哪些通过了、哪些失败了。
测试在整个软件系统的开发过程中会占据非常多的时间,”三分写代码,七分调代码”——为了软件可靠,这些时间花费是值得的。
测试是如此重要,以至于围绕测试还有一种专门的程序开发方法——测试驱动开发(TDD),用不断的测试来一步步迭代系统,在满足预定的输入输出前提下,最大程度保证系统的健壮性。
11. 项目部署与维护(初阶)
软件开发完了,接下来我们得把做好的软件放到一台服务器上,让用户能访问到——这个过程就叫部署。而部署之后,软件能不能稳定运行、出了问题能不能快速定位和修复,就是维护的工作了。
很多初学者会觉得,代码写完、本地能跑就万事大吉了。但实际上,部署和维护往往是整个项目生命周期中耗时最长、也最容易出问题的环节。
很多公司在招聘的时候,甚至会把”有线上项目运维经验”作为一个硬性要求,原因就在于此。
CI/CD(持续集成 / 持续部署)
CI(持续集成,Continuous Integration)的意思是:开发者每次提交代码后,系统会自动拉取最新代码,然后自动执行构建和测试。如果测试没通过,就会立刻通知开发者这次提交的代码有问题。这样就能尽早发现Bug,而不是等项目快上线了才发现问题。
CD(持续部署,Continuous Deployment)则更进一步:测试通过之后,系统会自动把代码部署到服务器上,整个过程不需要人工干预。
常见的CI/CD工具包括GitHub Actions、GitLab CI、Jenkins等。其中GitHub Actions是新手最友好的选择——如果你的代码托管在GitHub上,几乎零成本就能用起来。你只需要在项目里加一个配置文件,告诉它”每次我提交代码,你帮我跑测试、打包、部署”,它就会按照这个工作流照做。
对于个人项目或小团队项目来说,CI/CD能帮你省下大量重复劳动。你不用每次改完代码都手动去服务器上拉取、编译、重启服务——这些全部自动化了。
环境一致性
你一定遇到过这样的场景:代码在你自己电脑上跑得好好的,结果交给同事或者部署到服务器上之后,各种报错,完全跑不起来。这种”在我电脑上能跑”的问题,几乎每个开发者都经历过。
造成这个问题的原因五花八门:你的电脑装了Python 3.11,服务器装的是Python 3.9;你装了某个库的2.0版本,服务器上还是1.5;你的系统是Windows,服务器是Linux,路径分隔符都不一样……
Docker就是来解决这个问题的。你可以把Docker想象成一个”集装箱”:你把你的代码、依赖库、运行环境全部打包到这个集装箱里,然后不管你把这个集装箱搬到哪台机器上,里面的环境都是一模一样的。就像你搬家的时候,不是一件一件搬家具,而是把整个房间打包带走——到了新地方,打开就能住。
除了Docker,云服务也是实现环境一致性的重要手段。像阿里云、腾讯云、AWS这些云服务商,提供了各种各样的服务:虚拟服务器(ECS)、数据库服务(RDS)、对象存储(OSS/S3)等等。你可以直接在云上搭建一套和生产环境一致的开发环境,从根本上避免”环境不一致”的问题。
对于初学者来说,不需要一开始就把Docker玩得很溜。但至少要理解它的核心思想:把环境和代码一起打包,确保一致性。等到你的项目需要部署的时候,再边做边学完全来得及。
Vercel入门
如果你觉得Docker学习成本太高,云服务器的费用又太贵,那有没有更简单的方式把项目部署上线呢?有,Vercel就是这样一个”傻瓜式”的部署平台。
Vercel是一个专注于前端和Serverless应用的部署平台。它的使用方式极其简单:你把代码推送到GitHub,Vercel检测到更新后,会自动帮你构建和部署,几秒钟后你的网站就能访问了。整个过程你不需要碰服务器,不需要配环境,甚至不需要懂Linux。
这么说大家可能还是不会明白,原因可能主要还是对”部署”二字不理解。这么说吧,假如一个软件系统分为前端和后端,现代软件架构基本都是将前后端分离开去做的——也就是说,前端和后端通常是运行在两个不同的地方(在计算机网络的世界里,也就是同一主机不同端口,或干脆就是不同主机),因此这里说的”部署”就是将前端程序或后端程序放置在一个满足各种环境条件的地方持续运行。对于Vercel来说,不光可以一键部署,还可以自动分配域名,让大家都可以访问,不再只是我们开发阶段的localhost本地环回测试。
-
-
React / Vue / Next.js 等前端项目
-
基本使用方法可查阅:Vercel Documentation –
https://vercel.com/docs
入门使用教程可参考:使用 Vercel 全自动部署个人网站 –
https://juejin.cn/post/7517431514176847899
不过要注意,Vercel也有它的局限性。它不适合部署重量级的后端服务(比如需要长连接的即时通讯服务),也不适合需要自定义服务器配置的场景。但对于大多数前端项目和小型全栈项目来说,Vercel是目前最省心的选择之一。
和Vercel类似的平台还有Netlify,功能大同小异,选一个顺手的就好。接下来的文章,用的都是Vercel。
日志、审查、修复与重构
很多新手有一个误解:软件上线了,工作就结束了。但实际上,上线之后,真正的工作才刚刚开始。
日志(Log)是你了解软件运行状态的”眼睛”。它记录了软件运行过程中的各种信息:谁在什么时间访问了哪个页面、有没有报错、响应时间是多少……当你接到用户反馈”系统出问题了”的时候,第一件事就是去看日志。你可以把日志理解为飞机上的”黑匣子”——出了事故,就靠它来还原真相。
代码审查(Code Review)是团队开发中非常重要的环节。简单来说,就是让其他开发者(或者AI)检查你的代码,看看有没有Bug、逻辑是否合理、命名是否规范。代码审查就像论文答辩前的”预审”,帮你把问题在上游解决掉。
Bug修复是日常维护中最常见的工作。用户反馈了一个问题,你通过日志定位到了原因,然后修改代码、测试、重新部署——这是一个完整的修复流程。对于AI辅助开发来说,你可以把错误日志直接丢给AI,让它帮你分析原因并提供修复方案。
重构(Refactoring)则是更进一步的维护工作。随着项目越做越大,早期写的代码可能会变得难以维护——函数太长、命名混乱、重复代码多……重构就是在不改变功能的前提下,优化代码的结构和可读性。打个比方,就像你家住了三年之后,该整理的整理,该收纳的收纳,让家保持整洁有序,而不是越住越乱。
一个成熟的项目,维护的时间往往是开发时间的3到5倍。所以从一开始就重视代码质量、养成良好的编码习惯,能为你省下大量的后期维护成本。
12. Vibe Coding基本知识
在正式介绍这章内容之前,先聊聊”Vibe Coding”这个词。
2025年初,OpenAI的联合创始人Andrej Karpathy在社交媒体上发了一条消息,说自己现在写代码的方式变了——不再是逐行手写,而是用自然语言描述需求,让AI来生成代码,自己只需要”顺着感觉走”,像是在指挥一个得力助手。他把这种开发方式叫作Vibe Coding。
这个词后来被广泛使用,泛指所有以AI为核心驱动力的软件开发方式。不管你是用ChatGPT生成代码片段,还是用Claude Code直接在项目里让AI帮你写整个模块,都可以算作Vibe Coding的范畴。
对于非技术背景的人来说,Vibe Coding意味着一件事情:你不再需要成为编程高手,也能做出一个可用的软件。但前提是,你得理解这套体系的运作方式,才能有效地驾驭它。
大模型(LLM)
LLM是Large Language Model的缩写,翻译过来就是”大语言模型”。你可能听过GPT、Claude、Gemini、DeepSeek这些名字——它们都是大语言模型。
简单来说,大语言模型就是一个”读了海量文本数据”的AI系统。它通过阅读互联网上的书籍、文章、代码、对话等数据,学会了理解和生成人类语言。你可以把它理解为一个博览群书的超级学霸——你问它什么,它都能给你说出一大堆来。
但要注意,LLM的”理解”和人类的理解是不同的。它本质上是在做概率预测:根据你给它的上文,预测下一个最可能出现的词。就像手机输入法的联想功能,只不过LLM的联想能力强大了无数倍。
这意味着什么?意味着LLM有一个重要的特点你需要知道:
它很强大,但不是万能的。它能帮你写代码、解释概念、生成文案,但它也会”一本正经地胡说八道”——这在业内叫”幻觉”(Hallucination)。它可能会编造一个不存在的函数名,或者自信满满地给出一个完全错误的方案。所以,对于LLM给出的答案,你需要有基本的判断能力。
如今,大模型领域也有各自细分的板块,例如编程专用的大模型——Claude/GPT/Gemini/GLM/Minimax/Kimi,本专栏采用的编程模型是效能与成本都比较合适的GLM。
然而,在当前的AI科技圈,针对于大模型,存在一个现象——就是认为模型越强大,自己能够Vibe出的产品也就会越厉害。这句话乍一看没有问题,的确如Claude这类的顶尖编程模型,效能就是比国产各类模型的要好,但是说这话的话的人却有意忽略Token的成本。
并且,大模型的确是项目的整体上限,这话也没有错,但事实上,大多数人所要求的工作,其复杂度并没有非常高——这样的任务交到手里大模型手里,并不能完全展现出模型的最大能力,也就是说,”顶尖大模型+一般任务”这里会存在着巨大的浪费。
如果真的想要发挥出大模型的全部能力,不光要提升任务的难度,也要更加清楚地写明自己的需求,设计好工作流——这些都是大模型以外的知识,而恰巧是这些产品思维、软件工程思想,才是做好一个软件项目的关键。
因此,对于日常软件项目的开发,要开始对大模型的选择有多方面的考虑。
提示词(Prompt)
如果说LLM是一个能力超强的员工,那么Prompt就是你给这个员工下达的工作指令。
很多人用AI的方式是直接问:”帮我做一个网站。”然后得到的回答要么太泛泛,要么完全不是自己想要的。这不是AI的错,而是你的”指令”不够清晰。
写Prompt也是一样的道理。好的Prompt通常包含以下几个要素:
-
角色设定:告诉AI它应该扮演什么角色(比如”你是一个资深的全栈工程师”)
-
背景信息:说明项目的上下文(比如”这是一个用React + FastAPI构建的待办事项应用”)
-
具体任务:清楚地描述你要它做什么(比如”帮我写一个用户登录的接口,支持邮箱和密码验证”)
-
约束条件:说明有哪些限制(比如”使用JWT做身份认证,密码要加密存储”)
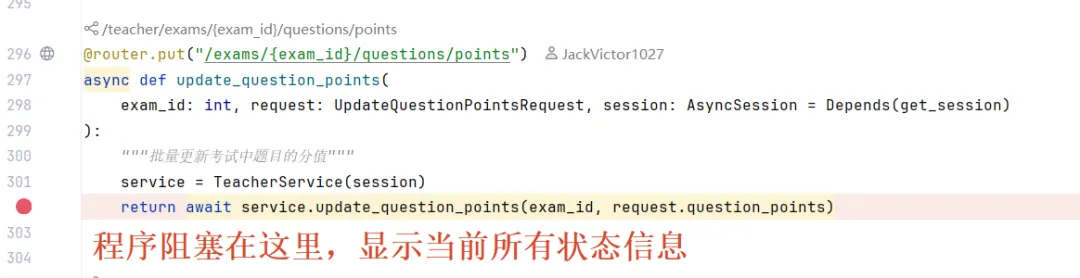
我开发了一个AI阅卷模块(放在项目根目录下的app/modules/AI-smart-paper-judger-nlp),专门用于给主观题(主观描述题和主观编程题)评分并给予反馈。为了让这个单独开发出来的模块,可以顺利地接入到我们的SmartPaperJudger系统中(尤其是后台教师端系统),你需要先阅读大体说明文档(README.md),了解其使用方法,如果有疑点,再去该模块目录下的/doc文件下查阅更详尽的设计说明文档。
为了使用简单,也为了开发方便,你可以不关心具体的实现,只需要知道如何使用就好。为此,你不光可以查看README.md来了解如何成功导入该模块至系统,也可以通过查看与README.md同级目录下的examples.py,这里写了非常多的测试用例,应该足够让你明白我们应该怎样通过接口调用服务,而不需要深入了解其实现。
我的目标是,成功导入该模块,能够通过简单的接口调用,传输给定格式的输入以后,模块内部运行之后,我们项目后台系统就可以方便地直接拿到评分和解析。更具体的,我希望可以在app/routes/teacher/teacher.py文件中任意处都可以直接通过调用模块接口,来方便地处理教师阅卷中出现的客观题。
在后面的实战章节中,我们会详细练习怎么写好Prompt。现在你只需要记住一个原则:你说得越清楚,AI给你的回答就越靠谱。
开发工具
知道了AI能干什么、怎么跟它沟通,接下来就是选一个趁手的工具了。
VSCode(Visual Studio Code)是微软出品的代码编辑器,也是目前全球最流行的开发工具之一。它免费、轻量、插件生态极其丰富。你可以通过安装插件把它变成一个几乎能做任何事情的”瑞士军刀”。对于大多数初学者来说,VSCode是首选的开发工具。
JetBrains IDE(比如WebStorm、PyCharm、IntelliJ IDEA)是另一类开发工具,更偏向”集成开发环境”。相比VSCode的轻量灵活,JetBrains的工具更加”重型”,内置了更多智能化的功能,比如代码重构、更强大的自动补全、更精准的错误检测。很多专业开发者会在大型项目中使用JetBrains。
Claude Code是Anthropic推出的AI编程命令行工具。你可以把它理解为”住在终端里的AI助手”。它不仅能帮你写代码,还能帮你读代码、修Bug、搜索文件、执行命令——几乎可以完成整个开发流程。本专栏的实战部分,就会以Claude Code为主要开发工具来展开。不过,Claude Code其实还只是一个编程框架与工作流,还需要一个基座模型才能真正开始编程做项目,本专栏采用的是GLM。
在实际开发中,Claude Code + VSCode或者Claude Code + JetBrains IDE的组合是很常见的。VSCode/JetBrains负责代码编辑和项目管理,Claude Code负责驱动AI完成编码工作,各司其职。
模型约束
AI虽然强大,但如果你不设任何限制,它很容易”自由发挥”,写出风格混乱、结构不统一的代码。今天它用这种命名方式,明天换一种;今天它用REST风格写接口,明天又变成了GraphQL——这样下去,你的代码库很快就会变成一团乱麻。
模型约束就是用来解决这个问题的。它相当于给AI立规矩——”你在这个项目里,必须按照这些规则来做事”。
最典型的约束方式就是规则文件。比如Claude Code会读取项目中的 CLAUDE.md 文件,把它当作这个项目的”行为准则”。你可以在里面写上:
项目使用的技术栈(比如React 18 + TypeScript + Tailwind CSS)
代码风格要求(比如函数命名用驼峰式,组件文件名用大驼峰)
架构约定(比如所有API请求必须经过统一的请求拦截器)
禁止事项(比如不要使用any类型,不要直接操作DOM)
这就像是你新招了一个员工,在他正式开始工作之前,你先给他一本员工手册——里面有公司的规章制度、工作流程、注意事项。他读了这本手册之后,做事就有了基本的框架,不会”乱来”。
规则文件的好处在于:一次设定,全程生效。你不需要每次跟AI沟通的时候都重复说一遍要求,它自己会遵守规则文件里的约定。这不仅提高了效率,还保证了代码风格的一致性。
扩展机制
随着你使用AI开发工具越来越熟练,你会发现AI默认的能力有时候不够用。比如你想让它帮你操作数据库、读取文件系统、调用第三方API——这些事情AI默认可能做不了,或者做不好。
这时候就需要用到扩展机制了。扩展机制的本质就是给AI “装外挂”,让它拥有更多的能力。
Plugin(插件)是最基础的扩展方式。就像浏览器装插件可以增加新功能一样,AI工具也可以通过安装插件来扩展能力。比如代码格式化插件、数据库操作插件、API测试插件等。
MCP(Model Context Protocol,模型上下文协议)是Anthropic提出的一种标准化协议,它让AI能够与外部工具和数据源进行交互。打个比方,MCP就像是AI的”万能转接头”——通过它,AI可以连接到你的数据库、文件系统、搜索引擎、设计工具等各种外部服务。有了MCP,AI就不再是一个”只会聊天的语言模型”,而是一个能真正动手干活的助手。
Skill(技能)是另一种扩展方式,类似于给AI预设了一套标准化的工作流程。比如”代码审查技能”——你告诉AI “帮我审查这段代码”,它就会按照预设的流程自动检查代码质量、安全漏洞、性能问题等,最后给你一份完整的审查报告。这比你自己一步一步教AI怎么做审查要高效得多。
13. 产品思维
这个产品为什么要做,有什么价值,在哪里可以用。决定着大方向,因为已经有了AI这名优秀的执行者,所以我们可以将更多精力放在做什么产品的决定上。
如果你主持过参加互联网+这类的比赛,分工和进度管理肯定是你要做的事情。
是的,严格来说,这还不是完全意义上的产品思维,因为这还没有考虑到商业化、市场需要,不过这又是另一门大学问了,和当前的专栏关系不大。我们这里用到的产品思维,是偏向产品设计、进度规划、人员管理化、技术规范化的。
定义产品
很多初学者学编程的时候,一上来就开始写代码,写着写着发现方向不对,推翻重来;再写,再推翻。折腾了几个来回,时间花了不少,东西做不出来。
问题出在哪?出在没有想清楚”我要做什么”就开始动手了。
定义产品,就是在你写第一行代码之前,先回答这几个问题:
这个产品要解决什么问题?比如”大学生找不到靠谱的家教信息”就是一个问题。
用户会在什么场景下使用?是在手机上刷到就用的场景,还是需要坐在电脑前认真操作的场景?
现有的解决方案有什么不足?已经有类似的竞品了,但它们做得不够好,你的产品好在哪里?
方向一变,做出来的东西就完全不同了。你不是在写代码,而是在解决问题。代码只是解决问题的手段,产品才是目的。
在AI辅助开发的时代,这一点更加重要。因为AI能帮你快速实现功能,所以你可以把更多时间花在”想清楚做什么”上,而不是”怎么实现”上。方向对了,AI能帮你加速;方向错了,AI只会帮你更快地做出一个没人用的东西。
PRD(产品需求文档)
想清楚了”做什么”,接下来就是把想法落实到纸面上——这就需要写一份PRD(Product Requirements Document,产品需求文档)。
PRD听起来很正式,但其实就是一份”产品说明书”。它的作用是让所有参与项目的人(包括你自己、你的AI助手、你的合作伙伴)对”这个产品要做成什么样”达成一致的理解。
-
-
-
功能列表:产品要有哪些功能?每个功能的优先级是什么(必须有 / 最好有 / 可选)?
-
使用场景:用户在什么情况下会打开这个产品?操作的流程是怎样的?
-
非功能需求:性能要求(页面加载不超过3秒)、安全要求(用户数据加密存储)、兼容性要求(支持手机和电脑访问)等。
-
设计参考:有没有类似的产品可以参考?界面风格偏好是什么?
PRD的价值在于减少返工。如果你没有PRD就开始开发,做到一半发现功能理解有偏差、用户体验没考虑到,改起来就很痛苦了。而有了PRD,你可以先把它给AI看,让AI根据这份文档来做开发,能大大减少沟通成本和理解偏差。
在后面的实战环节中,我们会一起写一份完整的PRD,让你亲身体会从”想法”到”文档”的过程。
进度规划
有了产品定义和需求文档,接下来就是”怎么把活干完”的问题了。
进度规划的核心是拆解任务。你不能把”做一个完整的电商网站”当成一个任务,那太大了,大到不知道从哪里下手,这样模糊的要求交给AI,基于概率的大模型接下来做的每一步都只能靠”猜”了,代码自己看不出逻辑还算小事,后面维护和更新才是巨大的灾难。而为了尽可能减少AI“猜”的概念,你需要把它拆成一个个可以独立完成的小任务:
-
-
-
-
-
-
-
-
拆解完之后,你还需要确定每个任务的优先级和依赖关系。比如”接入支付接口”必须等”实现订单提交功能”完成之后才能开始。这个过程就叫做排期。
在AI辅助开发中,进度规划还有一个特殊的地方:你的”团队成员”是AI。你需要在不同的阶段给AI分配不同的任务,而且要确保每次给AI的任务足够明确、足够小——因为AI处理”小而明确”的任务比处理”大而模糊”的任务要靠谱得多。
这就像你在管理一个项目团队:你不能对团队说”这个月把产品做出来”,而是要说”本周一完成数据库设计,周三完成用户模块的开发,周五之前完成测试”。越具体,执行力越强。
如果你参加过”互联网+”或者创新创业类的比赛,你会发现这里说的很多东西和比赛中的项目管理是一回事——分工、排期、汇报、复盘。软件项目管理的思维,在很多领域都是通用的。
14. 软件工程经典知识概要
到这里,我们已经覆盖了从编程基础到部署维护的完整知识链路。但如果你想从”能写代码”进化为”能做系统”,还差最后一块拼图:软件工程的经典理论知识。
这些知识听起来可能有点枯燥,但它们是无数前辈在几十年实践中总结出来的经验。掌握了它们,你在面对复杂项目的时候就不至于手忙脚乱,做出的系统也会更健壮、更容易维护。
对于非技术背景的读者,不需要把这些知识背得非常熟悉,但至少要理解核心思想,这样你在和AI协作开发的时候,才能给出正确的指令和约束。
这些知识决定你能否从”能写代码”进化为”能做系统”。
设计模式
设计模式是针对软件设计中常见问题的”标准答案”。就像做菜有经典菜谱一样,设计模式就是编程界的”经典菜谱”——遇到某种类型的问题,用对应的模式来解决,已经被证明是有效且优雅的。
举个最常用的例子——单例模式(Singleton)。它的核心思想是:某个东西在整个系统里只能有一个实例。比如你的应用需要连接数据库,你肯定不希望每次操作数据库都新建一个连接——那太浪费资源了。用单例模式,就能确保全局只有一个数据库连接对象,大家都共用这一个。
再比如工厂模式(Factory)。你有一个系统需要创建不同类型的用户(普通用户、VIP用户、管理员),如果直接在代码里写死”如果是A就创建普通用户,如果是B就创建VIP用户”,那以后要加一种新用户类型,就得改老代码。而工厂模式的做法是:创建一个”用户工厂”,由它来负责生产各种类型的用户。要加新类型?在工厂里加一条生产线就行,老代码完全不用动。
除了单例和工厂,常见的设计模式还有观察者模式(谁订阅了谁的通知)、策略模式(根据不同情况使用不同策略)、装饰器模式(给对象动态加功能)等等。你不需要一次学完,但遇到问题的时候可以查一查,大概率有现成的设计模式能用。
SOLID原则
SOLID是五个设计原则的首字母缩写,它们分别是:
-
S – 单一职责原则:一个模块/类/函数只做一件事。别让一个函数既负责用户登录、又负责发邮件、还负责写日志——那样的代码改起来牵一发动全身。
-
O – 开闭原则:对扩展开放,对修改关闭。意思是你要加新功能的时候,尽量通过”新增代码”来实现,而不是去”修改老代码”。
-
L – 里氏替换原则:子类应该能替换父类使用,而不影响程序正确性。简单说就是”继承要守规矩”。
-
I – 接口隔离原则:不要设计一个臃肿的大接口,而是设计多个小而专的接口。就像USB接口不会同时承担充电、数据传输、视频输出的功能——它只做数据传输,充电有充电的接口。
-
D – 依赖倒置原则:高层模块不应该依赖低层模块,两者都应该依赖抽象。这句话很学术,通俗来说就是:你的业务逻辑不应该写死”用MySQL数据库”,而是写”用某种数据库”——将来要换成PostgreSQL,业务逻辑不用改。
这五个原则看起来很多,但核心思想其实就一个:让代码更加灵活、好改、好维护。你在让AI写代码的时候,可以在规则文件里加上这些原则作为约束,让AI写出的代码质量更高。
高内聚低耦合
这是软件设计中最常被提起的原则之一,也是你理解系统架构的基石。
高内聚指的是一个模块内部的元素应该紧密相关、围绕一个明确的功能。就像一个厨房团队——切菜的专管切菜,炒菜的专管炒菜,上菜的专管上菜。每个人职责清晰、配合紧密,这就叫高内聚。反过来,如果同一个人又要切菜、又要炒菜、又要收银、又要打扫卫生,那就是低内聚——什么事都干,什么事都干不精。
低耦合指的是不同模块之间的依赖关系应该尽量少。还是拿厨房举例:如果切菜的师傅突然请假了,炒菜的就没法工作(因为他依赖切菜的人给他备料),这就叫高耦合。但如果是标准化流程——所有食材都提前备好放在冰箱里,谁来炒菜都能从冰箱取料,那厨师之间就不那么互相依赖了,这就叫低耦合。
一个高内聚低耦合的系统是什么样的?打个比方:就像乐高积木。每一块积木(模块)内部结构完整(高内聚),但积木之间的连接方式是标准化的,你可以自由拆装替换(低耦合)。坏了一块?换一块就行。想加新功能?拼一块新的上去就好。
可维护性与可扩展性
可维护性指的是:代码写完之后,将来修改起来有多容易。可维护性好的代码,新人接手也能快速理解;可维护性差的代码,连当初写它的人过两个月都看不懂。
可扩展性指的是:系统在不需要大规模改造的情况下,能否方便地增加新功能。一个可扩展性好的系统,加一个新功能就像给手机装一个新的App——不需要拆开手机重新接线,直接装上去就能用。
怎么提高可维护性和可扩展性?前面说的设计模式、SOLID原则、高内聚低耦合,都是手段。除此之外,还有一些实用的习惯:
写注释和文档:不写注释的代码,三个月后你自己都看不懂。
统一命名规范:别今天用 userId,明天用 user_id,后天又用 uid。
模块化设计:把大功能拆成小模块,每个模块独立可测试。
预留接口:在设计的时候就考虑将来可能会扩展的方向,留出”插口”。
在AI辅助开发中,这些原则尤其重要。因为AI生成的代码如果不加约束,往往会缺乏一致性和结构性。你需要作为”架构师”来把控方向,让AI在正确的框架内发挥能力。
15. 其他
结语
如果你是一口气读完的,可能会觉得信息量太大了——从终端命令到设计模式,从前端基础到部署维护,十五个章节的知识点铺天盖地。脑子里可能冒出了很多问号:”这些东西我真的都要学吗?””我能学会吗?””要多久才能上手做项目?”
先不要担心,你不需要把这篇文章里的所有知识都学会了才开始做项目。
本篇文章的目的是让你对软件开发的全貌有一个基本的认知——知道有哪些概念、它们各自是干什么的、在什么场景下会用到。有了这张地图,你在后面的实战过程中遇到问题的时候,就知道该往哪个方向去找答案,而不是两眼一抹黑。
真正的学习,是在做项目的过程中发生的。当你第一次在终端里运行一个命令、第一次用Git提交代码、第一次在浏览器里看到自己做的页面、第一次把项目部署上线——这些经历带给你的收获,远比读完十篇文章要多。
同时,我希望你能记住这个专栏的核心观点:AI开发不是一个”跳过基础”的捷径,而是一个”放大基础”的领域。
基础越扎实,你越能更快理解AI工具,因为你知道AI在做什么、为什么这么做;也更稳定构建系统,因为你知道怎么设计架构、怎么写规范代码;进而更高效解决问题——因为你知道怎么查错、怎么看日志、怎么定位Bug。
如果你现在觉得这些内容很多,不用担心——这本来就是一个逐步积累的过程。没有人是一天学会所有东西的,每一个经验丰富的开发者,都是在无数个项目中、无数次踩坑中一边实践一边学习的。
AI已经帮你准备好了最快的施工工具,接下来就看你怎么用了。下一篇,我们将从一个软件项目开始,正式开始动手
1.https://zhuanlan.zhihu.com/p/641263373
2.wikipidia
3.菜鸟教程
4.arena.ai
5.vibevibe
 夜雨聆风
夜雨聆风