夜雨聆风
夜雨聆风





TensorRT-LLM 0.5.0 源码之十三
QuantMode
from enum import IntFlag, auto 这行代码让你能够创建支持位运算(如按位或 |、按位与 &)的枚举类型,并能自动为成员分配值。这在管理一组可以组合使用的选项时(例如权限、状态标志)特别有用。
下面的表格总结了 IntFlag 和 auto 的核心特性和典型应用场景:
|
|
|
|
|---|---|---|
| 位标志组合 |
|
组合多个标志,用
|
| 自动赋值 | auto()
|
|
| 整数子类 |
|
|
基本定义与赋值
使用 IntFlag 和 auto() 可以非常清晰地定义一组标志。auto() 会自动分配 2 的幂次方值(1, 2, 4, 8…),这确保了每个标志对应一个独立的二进制位,是进行位运算的基础 。
from enum import IntFlag, autoclass Permissions(IntFlag): READ = auto() # 自动赋值为 1 (二进制 0b001) WRITE = auto() # 自动赋值为 2 (二进制 0b010) EXECUTE = auto() # 自动赋值为 4 (二进制 0b100)组合与检查标志
定义好标志后,你可以使用位运算符来组合和检查它们。
# 组合标志:使用按位或运算符 "|"user_permissions = Permissions.READ | Permissions.WRITEprint(user_permissions) # 输出: Permissions.READ|WRITEprint(int(user_permissions)) # 输出: 3 (因为 1 | 2 = 3)# 检查标志:使用按位与运算符 "&" 或 "in" 关键字if user_permissions & Permissions.READ: # 方式1:使用 "&" print("具有读权限")if Permissions.READ in user_permissions: # 方式2:使用 "in",更直观 print("具有读权限")# 检查是否同时拥有多个权限if (user_permissions & (Permissions.READ | Permissions.WRITE)) == (Permissions.READ | Permissions.WRITE): print("同时具有读和写权限")实用技巧与场景
-
• 自定义起始值:虽然 auto()通常从1开始,但你可以通过定义_generate_next_value_方法来自定义赋值逻辑。例如,让值从其他数字开始,或者使用成员名称的哈希值等 。 -
• 零值与无标志:可以显式定义一个值为 0 的成员,表示“没有任何标志”。在布尔上下文中,值为 0 的成员会被视为 False。class Color(Flag): BLACK = 0 RED = auto() BLUE = auto()print(bool(Color.BLACK)) # 输出: False -
• 网络协议:在定义 TCP 标志等场景中非常实用 。 class TCPFlags(IntFlag): SYN = auto() ACK = auto() FIN = auto()# 表示一个 SYN-ACK 包packet_flags = TCPFlags.SYN | TCPFlags.ACK
注意事项
-
• IntFlag与Flag的区别:还有一个基本的Flag类。与IntFlag的主要区别在于,Flag的成员不是整数子类,因此不能直接与整数进行比较或运算,这提供了更强的类型隔离。如果你不需要和整数混用,使用Flag可能更安全 。 -
• 确保值唯一:如果枚举值需要全局唯一,可以使用 @unique装饰器,这样如果有重复值(包括别名)会在定义时抛出异常 。
from enum import IntFlag, autoclass QuantMode(IntFlag): # [WARNING] KEEP BELOW DEFINITION IN SYNC WITH cpp/tensorrt_llm/common/quantization.h # The weights are quantized to 4 bits. INT4_WEIGHTS = auto() # The weights are quantized to 8 bits. INT8_WEIGHTS = auto() # The activations are quantized. ACTIVATIONS = auto() # The method uses one scaling factor per channel. It's pre-computed (static) from the weights. PER_CHANNEL = auto() # The method uses one scaling factor per token. It's computed on-the-fly. PER_TOKEN = auto() # The method uses one scaling factor per group. It's pre-computed (static) from the weights. PER_GROUP = auto() # The KV cache is quantized in INT8. INT8_KV_CACHE = auto() # The KV cache is quantized in FP8. FP8_KV_CACHE = auto() # FP8 QDQ FP8_QDQ = auto() # The smallest power-of-two that is not used by a flag. Do not call auto() after that line. COUNT = auto() # Bitmask to detect if weights, activations or both are quantized. WEIGHTS_AND_ACTIVATIONS = INT4_WEIGHTS | INT8_WEIGHTS | ACTIVATIONS # The mask of all valid flags. VALID_FLAGS = COUNT - 1 # All the bits set? You can restrict the test to the bits indicated by "mask". def _all(self, bits, mask=VALID_FLAGS): return (self & mask) == bits # Is one of the bits of the mask set? def _any(self, bits): return (self & bits) != 0 def is_int8_weight_only(self): return self._all(self.INT8_WEIGHTS, self.WEIGHTS_AND_ACTIVATIONS) def is_int4_weight_only(self): return self._all(self.INT4_WEIGHTS, self.WEIGHTS_AND_ACTIVATIONS) def is_weight_only(self): return self.is_int4_weight_only() or self.is_int8_weight_only() def is_int4_weight_only_per_group(self): return self.is_int4_weight_only() and self._any(self.PER_GROUP) def has_act_and_weight_quant(self): return self._all(self.INT8_WEIGHTS | self.ACTIVATIONS, self.WEIGHTS_AND_ACTIVATIONS) def has_per_token_dynamic_scaling(self): return self._any(self.PER_TOKEN) def has_act_static_scaling(self): return not self.has_per_token_dynamic_scaling() def has_per_channel_scaling(self): return self._any(self.PER_CHANNEL) def has_per_group_scaling(self): return self._any(self.PER_GROUP) def has_int8_kv_cache(self): return self._any(self.INT8_KV_CACHE) def has_fp8_kv_cache(self): return self._any(self.FP8_KV_CACHE) def has_kv_cache_quant(self): return self.has_int8_kv_cache() or self.has_fp8_kv_cache() def has_fp8_qdq(self): return self._any(self.FP8_QDQ) def has_any_quant(self): return self._any(self.INT8_WEIGHTS | self.ACTIVATIONS | self.INT8_KV_CACHE | self.FP8_KV_CACHE | self.FP8_QDQ) def set_int8_kv_cache(self): return self | self.INT8_KV_CACHE def set_fp8_kv_cache(self): return self | self.FP8_KV_CACHE def set_fp8_qdq(self): return self | self.FP8_QDQ @staticmethod def from_description(quantize_weights=False, quantize_activations=False, per_token=False, per_channel=False, per_group=False, use_int4_weights=False, use_int8_kv_cache=False, use_fp8_kv_cache=False, use_fp8_qdq=False): def raise_error(): raise ValueError(f"Unsupported combination of QuantMode args: " f"{quantize_weights=}, " f"{quantize_activations=}, " f"{per_token=}, " f"{per_channel=}, " f"{per_group=}, " f"{use_int4_weights=}" f"{use_int8_kv_cache=}" f"{use_fp8_kv_cache=}" f"{use_fp8_qdq=}") # We must quantize weights when we quantize activations. if quantize_activations and not quantize_weights: raise_error() # If we set per_token or per_channel, we must quantize both weights and activations. if (per_token or per_channel) and not (quantize_weights and quantize_activations): raise_error() mode = QuantMode(0) # Do we quantize the weights - if so, do we use INT4 or INT8? if quantize_weights and use_int4_weights: mode = mode | QuantMode.INT4_WEIGHTS elif quantize_weights: mode = mode | QuantMode.INT8_WEIGHTS # Do we quantize the activations? if quantize_activations: mode = mode | QuantMode.ACTIVATIONS # Per-channel/per-token/per-group additional flags. if per_channel: mode = mode | QuantMode.PER_CHANNEL if per_token: mode = mode | QuantMode.PER_TOKEN if per_group: mode = mode | QuantMode.PER_GROUP # Int8 KV cache if use_int8_kv_cache: mode = mode | QuantMode.INT8_KV_CACHE # FP8 KV cache if use_fp8_kv_cache: mode = mode | QuantMode.FP8_KV_CACHE if use_fp8_qdq: mode = mode | QuantMode.FP8_QDQ return mode @staticmethod def use_smooth_quant(per_token=False, per_channel=False): return QuantMode.from_description(True, True, per_token, per_channel) @staticmethod def use_weight_only(use_int4_weights=False): return QuantMode.from_description(quantize_weights=True, quantize_activations=False, per_token=False, per_channel=False, per_group=False, use_int4_weights=use_int4_weights)Quantize
class Quantize(Module): """ Quantize Layer For per-tensor mode, the scaling factor is a scalar. For per-channel mode, the scaling factor is a vector. """ def __init__( self, output_dtype: str = 'int8', scaling_factor_dtype: str = 'float32', in_channels: int = -1, axis=-1,) -> None: super().__init__() self.scaling_factor = Parameter(shape=(in_channels, ) if axis != -1 else (), dtype=scaling_factor_dtype) self.output_dtype = output_dtype self.axis = axis def forward(self, x): return quantize(x, self.scaling_factor.value, self.output_dtype, self.axis)def quantize(input: Tensor, scale_factor: Tensor, dtype: str, axis: int = -1) -> Tensor: layer = default_trtnet().add_quantize(input.trt_tensor, scale_factor.trt_tensor, str_dtype_to_trt(dtype)) layer.axis = axis output = _create_tensor(layer.get_output(0), layer) if not default_net().strongly_typed: layer.get_output(0).dtype = str_dtype_to_trt(dtype) return outputQuantizePerToken
class QuantizePerToken(Module): """ Quantize Per Token and compute dynamic scales for SmoothQuant """ def forward(self, x): return quantize_per_token(x)def quantize_per_token(x: Tensor) -> Tuple[Tensor]: if not default_net().plugin_config.quantize_per_token_plugin: if x.dtype != trt.float32: x = cast(x, 'float32') xmax = x.abs().max(-1, keepdim=True) scale = xmax / 127.0 out = x * 127.0 / xmax out = round(out) out = clip(out, -128, 127) quantized_out = cast(out, 'int8') return quantized_out, scale else: plg_creator = trt.get_plugin_registry().get_plugin_creator( 'QuantizePerToken', '1', TRT_LLM_PLUGIN_NAMESPACE) assert plg_creator is not None pfc = trt.PluginFieldCollection([]) quantize_plug = plg_creator.create_plugin("quantize_per_token_plugin", pfc) plug_inputs = [x.trt_tensor] layer = default_trtnet().add_plugin_v2(plug_inputs, quantize_plug) layer.get_output(0).set_dynamic_range(-127, 127) quantized = _create_tensor(layer.get_output(0), layer) quantized.trt_tensor.dtype = str_dtype_to_trt("int8") scales = _create_tensor(layer.get_output(1), layer) scales.trt_tensor.dtype = str_dtype_to_trt("float32") return quantized, scalesDequantize
class Dequantize(Module): """ Dequantize Layer. """ def __init__(self, axis: int = -1) -> None: super().__init__() self.scaling_factor = Parameter(shape=()) self.axis = axis def forward(self, input): return dequantize(input, self.scaling_factor.value, self.axis)def dequantize(input: Tensor, scale_factor: Tensor, axis: int = -1, output_type: Union[str, trt.DataType] = 'float16') -> Tensor: if isinstance(output_type, str): output_type = str_dtype_to_trt(output_type) layer = default_trtnet().add_dequantize(input.trt_tensor, scale_factor.trt_tensor, output_type) layer.axis = axis if not default_net().strongly_typed: layer.precision = input.dtype output = _create_tensor(layer.get_output(0), layer) return outputSmoothQuantColumnLinear
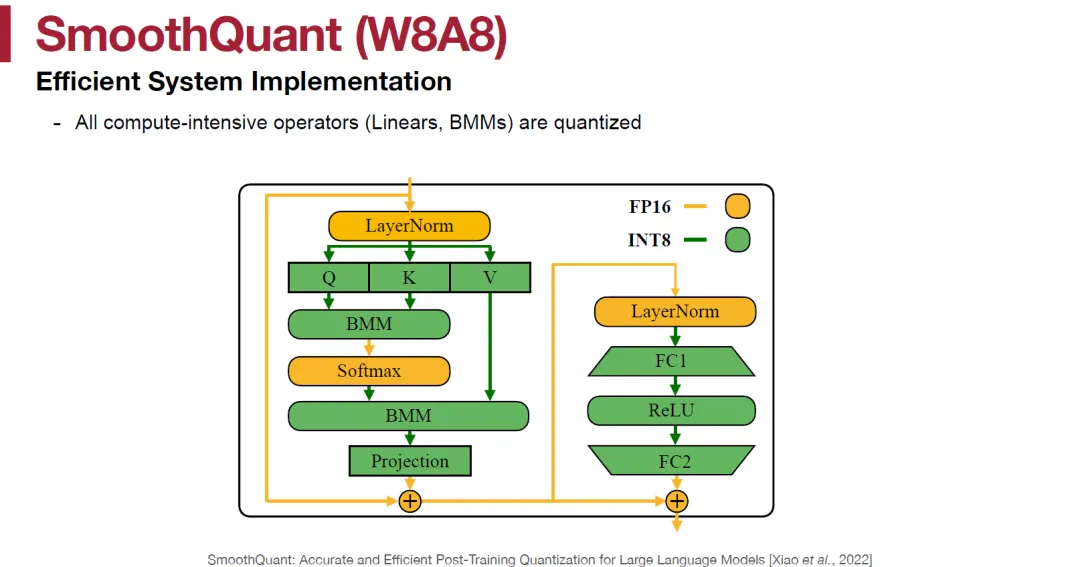
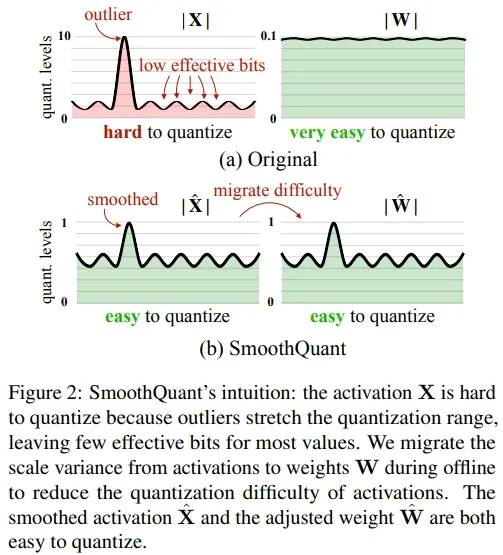
class SmoothQuantLinear(Module): def __init__(self, in_features, out_features, bias=True, dtype=None, tp_group=None, tp_size=1, gather_output=True, quant_mode=QuantMode(0)): super().__init__() self.in_features = in_features self.out_features = out_features // tp_size if not quant_mode.has_act_and_weight_quant(): raise ValueError( "SmoothQuant Linear has to have act+weight quantization mode set" ) weights_dtype = dtype # Dirty hack to make it work with SmoothQuant int8 weights # reinterpreted as fp32 weights due to the int8 TRT plugin limitation. if quant_mode.has_act_and_weight_quant(): assert self.in_features % 4 == 0 self.in_features = self.in_features // 4 weights_dtype = "float32" self.weight = Parameter(shape=(self.out_features, self.in_features), dtype=weights_dtype) if quant_mode.has_act_and_weight_quant(): scale_shape = (1, self.out_features ) if quant_mode.has_per_channel_scaling() else (1, 1) self.per_channel_scale = Parameter(shape=scale_shape, dtype="float32") if quant_mode.has_act_static_scaling(): self.act_scale = Parameter(shape=(1, 1), dtype="float32") self.tp_size = tp_size self.tp_group = tp_group self.gather_output = gather_output self.quant_mode = quant_mode if bias: self.bias = Parameter(shape=(self.out_features, ), dtype=dtype) else: self.register_parameter('bias', None) def forward(self, x): if self.quant_mode.has_act_static_scaling(): per_token_scale = self.act_scale.value else: # If we are in SmoothQuant with dynamic activation scaling, # input x has to be a tuple of int8 tensor and fp32 scaling factors x, per_token_scale = x x = smooth_quant_gemm(x, self.weight.value, per_token_scale, self.per_channel_scale.value, self.quant_mode.has_per_token_dynamic_scaling(), self.quant_mode.has_per_channel_scaling()) if self.bias is not None: x = x + self.bias.value if self.gather_output and self.tp_size > 1 and self.tp_group is not None: # 1. [dim0, local_dim] -> [dim0 * tp_size, local_dim] x = allgather(x, self.tp_group) # 2. [dim0 * tp_size, local_dim] -> [dim0, local_dim * tp_size] # 2.1 split split_size = shape(x, dim=0) / self.tp_size ndim = x.ndim() starts = [constant(int32_array([0])) for _ in range(ndim)] sizes = [shape(x, dim=d) for d in range(ndim)] sizes[0] = split_size sections = [] for i in range(self.tp_size): starts[0] = split_size * i sections.append(slice(x, concat(starts), concat(sizes))) # 2.2 concat x = concat(sections, dim=1) return xSmoothQuantColumnLinear = SmoothQuantLineardef smooth_quant_gemm(input: Tensor, weights: Tensor, scales_a: Tensor, scales_b: Tensor, per_token_scaling: bool, per_channel_scaling: bool) -> Tensor: if not default_net().plugin_config.smooth_quant_gemm_plugin: raise TypeError("Smooth Quant GEMM is only supported with plugin") else: plg_creator = trt.get_plugin_registry().get_plugin_creator( 'SmoothQuantGemm', '1', TRT_LLM_PLUGIN_NAMESPACE) assert plg_creator is not None per_channel_scaling = 1 if per_channel_scaling else 0 per_channel_scaling = trt.PluginField( "has_per_channel_scaling", np.array(per_channel_scaling, dtype=np.int32), trt.PluginFieldType.INT32) per_token_scaling = 1 if per_token_scaling else 0 per_token_scaling = trt.PluginField( "has_per_token_scaling", np.array(per_token_scaling, dtype=np.int32), trt.PluginFieldType.INT32) p_dtype = default_net().plugin_config.smooth_quant_gemm_plugin pf_type = trt.PluginField( "type_id", np.array([int(str_dtype_to_trt(p_dtype))], np.int32), trt.PluginFieldType.INT32) pfc = trt.PluginFieldCollection( [per_channel_scaling, per_token_scaling, pf_type]) gemm_plug = plg_creator.create_plugin("sq_gemm", pfc) plug_inputs = [ input.trt_tensor, weights.trt_tensor, scales_a.trt_tensor, scales_b.trt_tensor ] layer = default_trtnet().add_plugin_v2(plug_inputs, gemm_plug) layer.get_input(0).set_dynamic_range(-127, 127) return _create_tensor(layer.get_output(0), layer)SmoothQuantRowLinear
class SmoothQuantRowLinear(Module): def __init__(self, in_features, out_features, bias=True, dtype=None, tp_group=None, tp_size=1, quant_mode=QuantMode(0)): super().__init__() self.in_features = in_features // tp_size self.out_features = out_features if not quant_mode.has_act_and_weight_quant(): raise ValueError( "SmoothQuant Linear has to have act+weight quantization mode set" ) weights_dtype = dtype # Dirty hack to make it work with SmoothQuant int8 weights # reinterpreted as fp32 weights due to the int8 TRT plugin limitation. if quant_mode.has_act_and_weight_quant(): assert self.in_features % 4 == 0 self.in_features = self.in_features // 4 weights_dtype = "float32" self.weight = Parameter(shape=(self.out_features, self.in_features), dtype=weights_dtype) self.smoother = Parameter(shape=(1, self.in_features * 4), dtype="float32") if quant_mode.has_act_and_weight_quant(): scale_shape = (1, self.out_features ) if quant_mode.has_per_channel_scaling() else (1, 1) self.per_channel_scale = Parameter(shape=scale_shape, dtype="float32") if quant_mode.has_act_static_scaling(): self.act_scale = Parameter(shape=(1, 1), dtype="float32") if bias: self.bias = Parameter(shape=(self.out_features, ), dtype=dtype) else: self.register_parameter('bias', None) self.tp_group = tp_group self.tp_size = tp_size self.quant_mode = quant_mode def forward(self, x, workspace=None): if self.quant_mode.has_act_static_scaling(): per_token_scale = self.act_scale.value else: x, per_token_scale = x x = smooth_quant_gemm(x, self.weight.value, per_token_scale, self.per_channel_scale.value, self.quant_mode.has_per_token_dynamic_scaling(), self.quant_mode.has_per_channel_scaling()) if self.tp_size > 1 and self.tp_group is not None: x = allreduce(x, self.tp_group, workspace) if self.bias is not None: x = x + self.bias.value return xSmoothQuantLayerNorm
class SmoothQuantLayerNorm(Module): def __init__(self, normalized_shape, eps=1e-05, elementwise_affine=True, dtype=None, quant_mode=QuantMode(0)): super().__init__() if isinstance(normalized_shape, int): normalized_shape = (normalized_shape, ) if not quant_mode.has_act_and_weight_quant(): raise ValueError( "SmoothQuant layer norm has to have some quantization mode set") self.normalized_shape = tuple(normalized_shape) self.elementwise_affine = elementwise_affine if self.elementwise_affine: self.weight = Parameter(shape=self.normalized_shape, dtype=dtype) self.bias = Parameter(shape=self.normalized_shape, dtype=dtype) else: self.register_parameter('weight', None) self.register_parameter('bias', None) self.eps = eps self.quant_mode = quant_mode if self.quant_mode.has_act_and_weight_quant(): self.scale_to_int = Parameter(shape=(1, ), dtype=dtype) else: self.register_parameter('scale_to_int', None) def forward(self, x): weight = None if self.weight is None else self.weight.value bias = None if self.bias is None else self.bias.value scale = None if self.scale_to_int is None else self.scale_to_int.value return smooth_quant_layer_norm( x, self.normalized_shape, weight, bias, scale, self.eps, dynamic_act_scaling=self.quant_mode.has_per_token_dynamic_scaling())def smooth_quant_layer_norm(input: Tensor, normalized_shape: Union[int, Tuple[int]], weight: Optional[Tensor] = None, bias: Optional[Tensor] = None, scale: Optional[Tensor] = None, eps: float = 1e-05, use_diff_of_squares: bool = True, dynamic_act_scaling: bool = False) -> Tensor: if not default_net().plugin_config.layernorm_quantization_plugin: raise TypeError("Smooth Quant Layer Norm is only supported with plugin") else: plg_creator = trt.get_plugin_registry().get_plugin_creator( 'LayernormQuantization', '1', TRT_LLM_PLUGIN_NAMESPACE) assert plg_creator is not None eps = trt.PluginField("eps", np.array(eps, dtype=np.float32), trt.PluginFieldType.FLOAT32) use_diff_of_squares = trt.PluginField( "use_diff_of_squares", np.array([int(use_diff_of_squares)], dtype=np.int32), trt.PluginFieldType.INT32) dyn_act_scaling = trt.PluginField( "dyn_act_scaling", np.array([int(dynamic_act_scaling)], np.int32), trt.PluginFieldType.INT32) p_dtype = default_net().plugin_config.layernorm_quantization_plugin pf_type = trt.PluginField( "type_id", np.array([int(str_dtype_to_trt(p_dtype))], np.int32), trt.PluginFieldType.INT32) pfc = trt.PluginFieldCollection( [eps, use_diff_of_squares, dyn_act_scaling, pf_type]) layernorm_plug = plg_creator.create_plugin("layernorm_quantized", pfc) normalized_shape = [normalized_shape] if isinstance( normalized_shape, int) else normalized_shape if weight is None: weight = constant( np.ones(normalized_shape, dtype=str_dtype_to_np(p_dtype))) if bias is None: bias = constant( np.zeros(normalized_shape, dtype=str_dtype_to_np(p_dtype))) plug_inputs = [ input.trt_tensor, weight.trt_tensor, bias.trt_tensor, scale.trt_tensor ] layer = default_trtnet().add_plugin_v2(plug_inputs, layernorm_plug) layer.get_output(0).set_dynamic_range(-127, 127) if not dynamic_act_scaling: return _create_tensor(layer.get_output(0), layer) return _create_tensor(layer.get_output(0), layer), _create_tensor(layer.get_output(1), layer)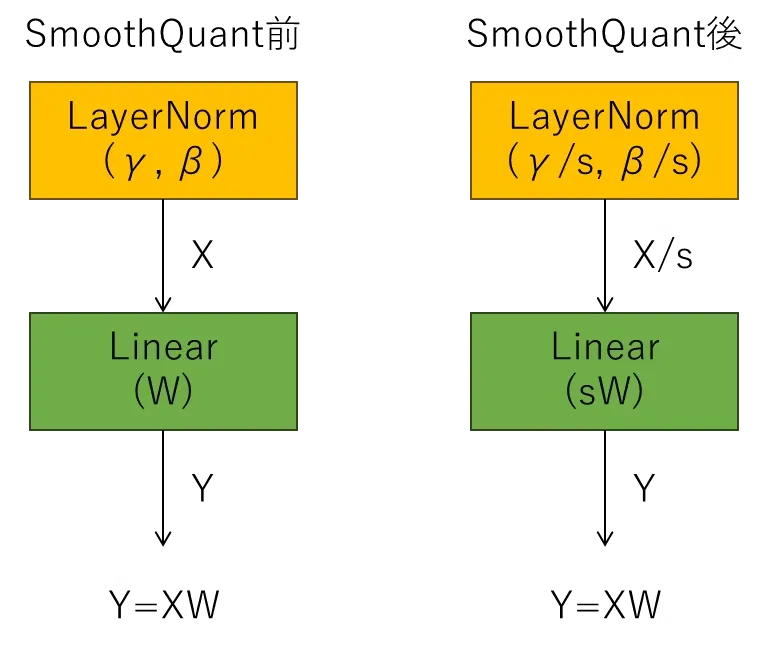
SmoothQuantRmsNorm
class SmoothQuantRmsNorm(Module): def __init__(self, normalized_shape, eps=1e-06, elementwise_affine=True, dtype=None, quant_mode=QuantMode(0), bias=False): super().__init__() if isinstance(normalized_shape, int): normalized_shape = (normalized_shape, ) if not quant_mode.has_act_and_weight_quant(): raise ValueError( "SmoothQuant Rms norm has to have some quantization mode set") self.normalized_shape = tuple(normalized_shape) self.elementwise_affine = elementwise_affine if self.elementwise_affine: self.weight = Parameter(shape=self.normalized_shape, dtype=dtype) else: self.register_parameter('weight', None) if bias: self.bias = Parameter(shape=self.normalized_shape, dtype=dtype) else: self.register_parameter('bias', None) self.eps = eps self.quant_mode = quant_mode if self.quant_mode.has_act_and_weight_quant(): self.scale_to_int = Parameter(shape=(1, ), dtype=dtype) else: self.register_parameter('scale_to_int', None) def forward(self, x): weight = None if self.weight is None else self.weight.value bias = None if self.bias is None else self.bias.value scale = None if self.scale_to_int is None else self.scale_to_int.value return smooth_quant_rms_norm( x, self.normalized_shape, weight, bias, scale, self.eps, dynamic_act_scaling=self.quant_mode.has_per_token_dynamic_scaling())def smooth_quant_rms_norm(input: Tensor, normalized_shape: Union[int, Tuple[int]], weight: Optional[Tensor] = None, bias: Optional[Tensor] = None, scale: Optional[Tensor] = None, eps: float = 1e-05, dynamic_act_scaling: bool = False) -> Tensor: if not default_net().plugin_config.rmsnorm_quantization_plugin: raise TypeError("Smooth Quant Rms Norm is only supported with plugin") else: plg_creator = trt.get_plugin_registry().get_plugin_creator( 'RmsnormQuantization', '1', TRT_LLM_PLUGIN_NAMESPACE) assert plg_creator is not None eps = trt.PluginField("eps", np.array(eps, dtype=np.float32), trt.PluginFieldType.FLOAT32) dyn_act_scaling = trt.PluginField( "dyn_act_scaling", np.array([int(dynamic_act_scaling)], np.int32), trt.PluginFieldType.INT32) p_dtype = default_net().plugin_config.rmsnorm_quantization_plugin pf_type = trt.PluginField( "type_id", np.array([int(str_dtype_to_trt(p_dtype))], np.int32), trt.PluginFieldType.INT32) pfc = trt.PluginFieldCollection([eps, dyn_act_scaling, pf_type]) rmsnorm_plug = plg_creator.create_plugin("rmsnorm_quantized", pfc) normalized_shape = [normalized_shape] if isinstance( normalized_shape, int) else normalized_shape if weight is None: weight = constant( np.ones(normalized_shape, dtype=str_dtype_to_np(p_dtype))) if bias is None: bias = constant( np.zeros(normalized_shape, dtype=str_dtype_to_np(p_dtype))) plug_inputs = [ input.trt_tensor, weight.trt_tensor, bias.trt_tensor, scale.trt_tensor ] layer = default_trtnet().add_plugin_v2(plug_inputs, rmsnorm_plug) layer.get_output(0).set_dynamic_range(-127, 127) if not dynamic_act_scaling: return _create_tensor(layer.get_output(0), layer) return _create_tensor(layer.get_output(0), layer), _create_tensor(layer.get_output(1), layer)WeightOnlyQuantColumnLinear
class WeightOnlyQuantLinear(Module): def __init__(self, in_features, out_features, bias=True, dtype=None, tp_group=None, tp_size=1, gather_output=True, quant_mode=QuantMode.use_weight_only()): super().__init__() if quant_mode.is_int8_weight_only(): self.weight_only_quant_mode = 1 quant_type_size_in_bits = 8 elif quant_mode.is_int4_weight_only(): self.weight_only_quant_mode = 2 quant_type_size_in_bits = 4 self.in_features = in_features self.out_features = out_features // tp_size # we use a fake tensor with data_type = float self.weight = Parameter(shape=(self.in_features, int(self.out_features * quant_type_size_in_bits / 32)), dtype="float32") scale_shape = (self.out_features, ) self.per_channel_scale = Parameter(shape=scale_shape, dtype=dtype) self.tp_size = tp_size self.tp_group = tp_group self.gather_output = gather_output if bias: self.bias = Parameter(shape=(self.out_features, ), dtype=dtype) else: self.register_parameter('bias', None) def forward(self, x): x = weight_only_quant_matmul(x, self.weight.value, self.per_channel_scale.value, self.weight_only_quant_mode) if self.bias is not None: x = x + self.bias.value if self.gather_output and self.tp_size > 1 and self.tp_group is not None: # 1. [dim0, local_dim] -> [dim0 * tp_size, local_dim] x = allgather(x, self.tp_group) # 2. [dim0 * tp_size, local_dim] -> [dim0, local_dim * tp_size] # 2.1 split split_size = shape(x, dim=0) / self.tp_size ndim = x.ndim() starts = [constant(int32_array([0])) for _ in range(ndim)] sizes = [shape(x, dim=d) for d in range(ndim)] sizes[0] = split_size sections = [] for i in range(self.tp_size): starts[0] = split_size * i sections.append(slice(x, concat(starts), concat(sizes))) # 2.2 concat x = concat(sections, dim=1) return xWeightOnlyQuantColumnLinear = WeightOnlyQuantLineardef weight_only_quant_matmul(input: Tensor, weights: Tensor, scales: Tensor, weightTypeId: int) -> Tensor: if not default_net().plugin_config.weight_only_quant_matmul_plugin: raise TypeError( "Weight Only Qunat MatMul is only supported with plugin") else: plg_creator = trt.get_plugin_registry().get_plugin_creator( 'WeightOnlyQuantMatmul', '1', TRT_LLM_PLUGIN_NAMESPACE) assert plg_creator is not None weight_type_id = trt.PluginField("weight_type_id", np.array(weightTypeId, dtype=np.int32), trt.PluginFieldType.INT32) p_dtype = default_net().plugin_config.weight_only_quant_matmul_plugin pf_type = trt.PluginField( "type_id", np.array([int(str_dtype_to_trt(p_dtype))], np.int32), trt.PluginFieldType.INT32) pfc = trt.PluginFieldCollection([pf_type, weight_type_id]) matmul_plug = plg_creator.create_plugin("woq_matmul", pfc) plug_inputs = [input.trt_tensor, weights.trt_tensor, scales.trt_tensor] layer = default_trtnet().add_plugin_v2(plug_inputs, matmul_plug) return _create_tensor(layer.get_output(0), layer)WeightOnlyQuantRowLinear
class WeightOnlyQuantRowLinear(Module): def __init__(self, in_features, out_features, bias=True, dtype=None, tp_group=None, tp_size=1, quant_mode=QuantMode.use_weight_only()): super().__init__() if quant_mode.is_int8_weight_only(): self.weight_only_quant_mode = 1 elif quant_mode.is_int4_weight_only(): self.weight_only_quant_mode = 2 self.in_features = in_features // tp_size self.out_features = out_features #we use a fake tensor with data_type = float self.weight = Parameter(shape=(self.in_features, int(self.out_features / 4 / self.weight_only_quant_mode)), dtype="float32") self.per_channel_scale = Parameter(shape=(self.out_features, ), dtype=dtype) if bias: self.bias = Parameter(shape=(self.out_features, ), dtype=dtype) else: self.register_parameter('bias', None) self.tp_group = tp_group self.tp_size = tp_size def forward(self, x, workspace=None): x = weight_only_quant_matmul(x, self.weight.value, self.per_channel_scale.value, self.weight_only_quant_mode) if self.tp_size > 1 and self.tp_group is not None: x = allreduce(x, self.tp_group, workspace) if self.bias is not None: x = x + self.bias.value return xWeightOnlyGroupwiseQuantColumnLinear
class WeightOnlyGroupwiseQuantLinear(Module): def __init__(self, in_features, out_features, group_size=128, pre_quant_scale=False, zero=False, bias=False, dtype=None, tp_group=None, tp_size=1, gather_output=True): super().__init__() # Flags for indicating whether the corresponding inputs are applied in quant_algo BIAS = 1 ZERO = 2 PRE_QUANT_SCALE = 4 self.quant_algo = pre_quant_scale * PRE_QUANT_SCALE + zero * ZERO + bias * BIAS self.group_size = group_size self.in_features = in_features self.out_features = out_features // tp_size self.qweight = Parameter(shape=(self.in_features, self.out_features // 8), dtype="float32") scale_shape = (self.in_features // group_size, self.out_features) self.scale = Parameter(shape=scale_shape, dtype=dtype) if pre_quant_scale: self.pre_quant_scale = Parameter(shape=(1, self.in_features), dtype=dtype) else: self.register_parameter('pre_quant_scale', None) if zero: self.zero = Parameter(shape=scale_shape, dtype=dtype) else: self.register_parameter('zero', None) if bias: self.bias = Parameter(shape=(self.out_features, ), dtype=dtype) else: self.register_parameter('bias', None) self.tp_size = tp_size self.tp_group = tp_group self.gather_output = gather_output def forward(self, x): pre_quant_scale = self.pre_quant_scale.value if self.pre_quant_scale else None zero = self.zero.value if self.zero else None bias = self.bias.value if self.bias else None x = weight_only_groupwise_quant_matmul(x, pre_quant_scale, self.qweight.value, self.scale.value, zero, bias, self.quant_algo, self.group_size) if self.gather_output and self.tp_size > 1 and self.tp_group is not None: # 1. [dim0, local_dim] -> [dim0 * tp_size, local_dim] x = allgather(x, self.tp_group) # 2. [dim0 * tp_size, local_dim] -> [dim0, local_dim * tp_size] # 2.1 split split_size = shape(x, dim=0) / self.tp_size ndim = x.ndim() starts = [constant(int32_array([0])) for _ in range(ndim)] sizes = [shape(x, dim=d) for d in range(ndim)] sizes[0] = split_size sections = [] for i in range(self.tp_size): starts[0] = split_size * i sections.append(slice(x, concat(starts), concat(sizes))) # 2.2 concat x = concat(sections, dim=1) return xWeightOnlyGroupwiseQuantColumnLinear = WeightOnlyGroupwiseQuantLineardef weight_only_groupwise_quant_matmul(input: Tensor, pre_quant_scale: Tensor, weights: Tensor, scales: Tensor, zeros: Tensor, biases: Tensor, quant_algo: int, group_size: int) -> Tensor: if not default_net( ).plugin_config.weight_only_groupwise_quant_matmul_plugin: raise TypeError( "Weight Only Groupwise Quant MatMul is only supported with plugin") else: plg_creator = trt.get_plugin_registry().get_plugin_creator( 'WeightOnlyGroupwiseQuantMatmul', '1', TRT_LLM_PLUGIN_NAMESPACE) assert plg_creator is not None quant_algo_ = trt.PluginField("quant_algo", np.array(quant_algo, dtype=np.int32), trt.PluginFieldType.INT32) group_size_ = trt.PluginField("group_size", np.array(group_size, dtype=np.int32), trt.PluginFieldType.INT32) p_dtype = default_net( ).plugin_config.weight_only_groupwise_quant_matmul_plugin pf_type_ = trt.PluginField( "type_id", np.array([int(str_dtype_to_trt(p_dtype))], np.int32), trt.PluginFieldType.INT32) pfc = trt.PluginFieldCollection([pf_type_, quant_algo_, group_size_]) matmul_plug = plg_creator.create_plugin("woq_groupwise_matmul", pfc) # quant_algo = pre_quant_scale * 4 + zero * 2 + bias plug_inputs = [input.trt_tensor] # Flags for indicating whether the corresponding inputs are applied in quant_algo # quant_algo = pre_quant_scale * PRE_QUANT_SCALE + zero * ZERO + bias * BIAS # Here pre_quant_scale, zero and bias are boolean type BIAS = 1 ZERO = 2 PRE_QUANT_SCALE = 4 if quant_algo & PRE_QUANT_SCALE: plug_inputs += [pre_quant_scale.trt_tensor] plug_inputs += [weights.trt_tensor, scales.trt_tensor] if quant_algo & ZERO: plug_inputs += [zeros.trt_tensor] if quant_algo & BIAS: plug_inputs += [biases.trt_tensor] layer = default_trtnet().add_plugin_v2(plug_inputs, matmul_plug) return _create_tensor(layer.get_output(0), layer)WeightOnlyGroupwiseQuantRowLinear
class WeightOnlyGroupwiseQuantRowLinear(Module): def __init__(self, in_features, out_features, group_size=128, pre_quant_scale=False, zero=False, bias=False, dtype=None, tp_group=None, tp_size=1): super().__init__() # Flags for indicating whether the corresponding inputs are applied in quant_algo BIAS = 1 ZERO = 2 PRE_QUANT_SCALE = 4 self.quant_algo = pre_quant_scale * PRE_QUANT_SCALE + zero * ZERO + bias * BIAS self.group_size = group_size self.in_features = in_features // tp_size self.out_features = out_features self.qweight = Parameter(shape=(self.in_features, self.out_features // 8), dtype="float32") scale_shape = (self.in_features // group_size, self.out_features) self.scale = Parameter(shape=scale_shape, dtype=dtype) if pre_quant_scale: self.pre_quant_scale = Parameter(shape=(1, self.in_features), dtype=dtype) else: self.register_parameter('pre_quant_scale', None) if zero: self.zero = Parameter(shape=scale_shape, dtype=dtype) else: self.register_parameter('zero', None) if bias: self.bias = Parameter(shape=(self.out_features, ), dtype=dtype) else: self.register_parameter('bias', None) self.tp_size = tp_size self.tp_group = tp_group def forward(self, x, workspace=None): pre_quant_scale = self.pre_quant_scale.value if self.pre_quant_scale else None zero = self.zero.value if self.zero else None bias = self.bias.value if self.bias else None x = weight_only_groupwise_quant_matmul(x, pre_quant_scale, self.qweight.value, self.scale.value, zero, bias, self.quant_algo, self.group_size) if self.tp_size > 1 and self.tp_group is not None: x = allreduce(x, self.tp_group, workspace) return xSmoothQuantMLP
class SmoothQuantMLP(Module): def __init__(self, hidden_size, ffn_hidden_size, hidden_act, bias=True, dtype=None, tp_group=None, tp_size=1, quant_mode=QuantMode(0)): super().__init__() if hidden_act not in ACT2FN: raise ValueError( 'unsupported activation function: {}'.format(hidden_act)) self.fc = SmoothQuantColumnLinear(hidden_size, ffn_hidden_size, bias=bias, dtype=dtype, tp_group=tp_group, tp_size=tp_size, gather_output=False, quant_mode=quant_mode) self.proj = SmoothQuantRowLinear(ffn_hidden_size, hidden_size, bias=bias, dtype=dtype, tp_group=tp_group, tp_size=tp_size, quant_mode=quant_mode) self.hidden_act = hidden_act self.quant_mode = quant_mode if self.quant_mode.has_act_static_scaling(): self.quantization_scaling_factor = Parameter(shape=(1, ), dtype='float32') else: self.register_parameter('quantization_scaling_factor', None) def forward(self, hidden_states, workspace=None): inter = self.fc(hidden_states) inter = ACT2FN[self.hidden_act](inter) inter = inter / self.proj.smoother.value if self.quant_mode.has_act_and_weight_quant(): if self.quant_mode.has_act_static_scaling(): # Avoid quantiztion layers as it breaks int8 plugins inter = quantize_tensor(inter, self.quantization_scaling_factor.value) else: # Quantize per token outputs tuple: # quantized tensor and scaling factors per token inter = quantize_per_token(inter) output = self.proj(inter, workspace) return outputdef quantize_tensor(x, scale): if not default_net().plugin_config.quantize_tensor_plugin: scaled = x * scale rounded = round(scaled) clipped = clip(rounded, -128, 127) quantized = cast(clipped, 'int8') else: plg_creator = trt.get_plugin_registry().get_plugin_creator( 'QuantizeTensor', '1', TRT_LLM_PLUGIN_NAMESPACE) assert plg_creator is not None pfc = trt.PluginFieldCollection([]) quantize_plug = plg_creator.create_plugin("quantize_tensor_plugin", pfc) plug_inputs = [x.trt_tensor, scale.trt_tensor] layer = default_trtnet().add_plugin_v2(plug_inputs, quantize_plug) layer.get_output(0).set_dynamic_range(-127, 127) quantized = _create_tensor(layer.get_output(0), layer) quantized.trt_tensor.dtype = str_dtype_to_trt("int8") return quantized参考文献
-
• https://github.com/NVIDIA/TensorRT-LLM/blob/v0.5.0/tensorrt_llm/quantization/mode.py -
• https://github.com/NVIDIA/TensorRT-LLM/blob/v0.5.0/tensorrt_llm/quantization/layers.py -
• https://qiita.com/kyad/items/894bea24fdd0ed79318b