 夜雨聆风
夜雨聆风





VoxCPM2:当AI学会“说人话”,语音合成进入无Tokenizer时代
一声“你好”,已经不再冰冷。当AI学会了呼吸、停顿、语调与情绪,语音的世界正在被改写成另一副模样——而这一次,方向盘握在开源的手里。
你还记得第一次听到Siri说话的场景吗?那是在2011年,那个机械而僵硬的声音勉强完成了信息传递的任务,却让人本能地意识到——这是一台机器。十几年过去了,语音合成技术经历了从拼接合成到参数合成,再到神经网络TTS的多次范式跃迁。而今天,一个名为VoxCPM2的模型,正在用另一种方式告诉我们:AI终于学会“说人话”了——它能呼吸、会停顿、有情绪,甚至能凭空“想”出一个从未存在过的声音。它的出现,让语音合成的天花板再一次被击穿。

现在,请系好安全带:我们要走进的,是一个语音合成不再依赖“分词器”的新世界。
语音合成为什么听起来像机器?
在揭开VoxCPM2的神秘面纱之前,我们得先搞清楚一个关键问题:为什么传统TTS生成的语音,总有一种挥之不去的“机器感”?
答案藏在一个叫做Tokenizer(分词器)的技术环节里。绝大多数主流TTS系统的工作流程是:先把语音切成离散的“音频token”——类似于把一幅油画拆成无数块拼图碎片;然后用语言模型学习这些碎片的排列规律;最后再像拼拼图一样把它们拼回声音。这个过程确实解决了传输和运算的难题,但在“切碎-重组”的过程中,换气声的微妙差异、鼻音的柔和共鸣、声带振动的微小颤音……这些真正让人声听起来“有人味”的细节,却被一刀切掉了。
这就好比你把一首肖邦的夜曲转录成MIDI数字音符——每个音高、时长都精准无误,但缺少了钢琴家指尖触键时的微妙力度变化,音乐的灵魂就消失了。VoxCPM2正是看到了这个根本性的瓶颈,决定换个思路:干脆不做“切碎”这一步。
扔掉Tokenizer,直接“画”出声音波形
2026年4月,OpenBMB团队正式发布了VoxCPM2——一个彻底抛弃了离散分词器的端到端语音合成模型。它的核心架构叫做扩散自回归架构,将LocEnc、TSLM、RALM与LocDiT等多项先进技术融为一体,不再把语音“切碎”成离散token,而是直接在连续的声学空间中生成语音表征。
用通俗的话讲:传统方法像数字油画——用有限的颜料色块拼贴出画面,虽可辨认但终究粗糙;VoxCPM2则像直接拿着调色板挥洒笔触,保留了声音中最细腻的动态和情感。
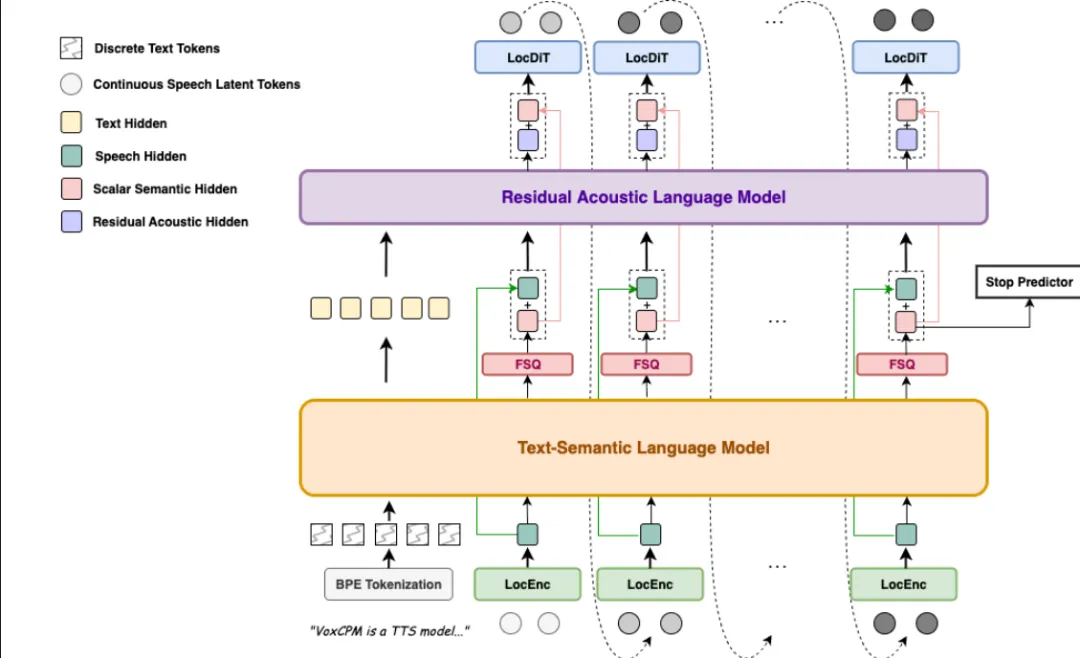
这套架构建立在MiniCPM-4骨干模型之上,通过分层语言建模和FSQ(快速采样量化)约束,实现了隐式的语义-声学解耦。简单来说,模型先理解文本的深层语义,再把理解转化为声学特征参数,最后用扩散解码器“画”出真实的声音波形。正因如此,VoxCPM2不仅知道一句话在说什么,还能自动推断出应该用什么样的语气、节奏和情绪来演绎它——就像一位经验丰富的配音演员,拿到剧本后立刻知道该怎么“读”。这种能力在学术上被称为上下文感知合成,是语音表达力从“可接受”跨越到“动人”的关键一步。
一个模型打包四项神技
如果VoxCPM2只有“扔掉Tokenizer”这一张王牌,那还不足以在2026年这个AI模型井喷的时代脱颖而出。真正让它在众多开源TTS项目中杀出重围的,是它在一个仅2B参数体量的模型里,实现了四项原本需要多个模型协同才能完成的核心能力。
能力一:30国语言+9种中国方言,无需切换语言标签
VoxCPM2当前版本支持30种语言的一键合成——包括但不限于阿拉伯语、缅甸语、中文、丹麦语、荷兰语、英语、芬兰语、法语、德语、希腊语、希伯来语、印地语、印尼语、意大利语、日语、高棉语、韩语、老挝语、马来语、挪威语、波兰语、葡萄牙语、俄语、西班牙语、斯瓦希里语、瑞典语、他加禄语、泰语、土耳其语、越南语。值得一提的是,VoxCPM2在东南亚主流8国语种上做了专门优化,覆盖越南语、泰语、印尼语、老挝语、缅甸语、柬埔寨语、菲律宾语、马来西亚语,为东南亚市场的出海应用提供了原生级的语音支持。
不仅国际范十足,VoxCPM2在中国方言上的覆盖同样引人注目:四川话、粤语、吴语、东北话、河南话、陕西话、山东话、天津话、闽南话,九大方言一应俱全。这意味着你完全可以让《哆啦A梦》中的角色开口说一口地道的四川话,全程零人类配音师参与。
最令人惊喜的是,VoxCPM2在生成多语言语音时无需任何语言标签——你只需要直接把目标语言的文本喂进去,模型会自动识别语种并用正确的语音特征合成,这项能力在目前的语音模型中尚属罕见。
能力二:音色设计——用文字“创造”不存在的声音
这是VoxCPM2最富有想象力的一项功能。什么叫音色设计?你不需要任何参考音频,只需要用自然语言描述你想要的音色:比如“一个低沉浑厚、略带沙哑的老者声音,语气缓慢而睿智”,VoxCPM2就能凭空创造出一个符合描述的全新声音。这项能力的突破性在于,它把语音合成从“复制已有声音”推进到了“无中生有”的创造力层面。
实战效果:一口气让VoxCPM2生成7个不同音色,然后让它们上演一场武侠大戏——每位大侠的声线各具特色,从冷峻刀客到风流书生,仅靠文字描述就完成了“选角”工作。对于有声书制作、游戏NPC配音、动画角色塑造等场景,这意味着不再受真人声优档期和成本的限制,创作自由度被完全打开。
能力三:可控克隆——不仅能“模仿”声音,还能“导演”情绪
VoxCPM2在声音克隆方面同样带来了重要突破。传统的语音克隆技术只能复制音色,生成的语音在情绪表达上往往是扁平的——你可以让AI用某个人的声音说话,但很难控制它是高兴、悲伤还是愤怒。
VoxCPM2的可控克隆功能做到了这两件事:首先,通过一段短至3到10秒的参考音频,即可精准捕捉说话者的音色、语速和语调风格;其次,额外加入风格引导,你可以指定目标情绪、语速、表达方式,让克隆后的声音带有特定情感色彩。更令人印象深刻的是它内置的场景感知能力——当你输入带有情感色彩的文字时,模型会根据上下文自主调整说话的语气。文字描写愤怒的场面,生成的语音不仅音量放大,连咬字力度和节奏都会同步收紧。
能力四:48kHz高保真——CD级别的“录音棚音质”
如果前三个能力都还停留在“说不说得像”的层面,那么48kHz高保真音频输出就是关于“听不听得爽”的根本体验。VoxCPM2通过AudioVAE V2实现了非对称编解码设计:输入端使用16kHz参考音频即可完成特征提取,而输出端则直接生成48kHz的录音棚级音频,内置超分辨率功能,无需外接任何升频器。
从16kHz到48kHz这个跨越意味着什么?16kHz的电话音质频率上限大约为8kHz,而48kHz则能完整保留人耳可闻的20kHz全频段。这意味着齿音的气流感、乐器泛音的辉光、混响空间感的微妙余韵,这些在传统TTS中极易丢失的高频细节,在VoxCPM2的声场中都被完好无损地保留下来。
轻量化奇迹:8GB显存就能跑
强悍的性能通常意味着高昂的硬件门槛,但VoxCPM2打破了这一惯性。虽然拥有2B参数,它经过精心架构优化后,仅需8GB显存的中端消费级显卡即可流畅运行,这意味着你完全不需要租用昂贵的云端GPU服务器——一张NVIDIA RTX 3060或4060级别的显卡,就足以在本地搭建起一套私人专属的AI配音工作室。
在性能方面,VoxCPM2同样没有妥协。在NVIDIA RTX 4090上,实时因子仅约0.3;如果配合Nano-vLLM或vLLM-Omni进行推理加速优化,RTF更可以降至0.13——这意味着生成1秒音频仅需约130毫秒,完全满足流式实时对话的需求。高并发、低延迟的流式服务也不再是商用闭源模型的专利。
更重要的是,VoxCPM2采用Apache-2.0协议开放全部模型权重和代码,对商用完全友好。无论是初创团队想用AI语音赋能产品,还是独立开发者想构建语音交互应用,甚至是大企业寻求TTS能力内部私有化部署,VoxCPM2都提供了从0到1的全套免费工具。
探索VoxCPM2的典型落地场景
从功能特性到实际价值的转化,离不开具体场景的支撑。以下是VoxCPM2正在打开的几个高价值应用方向:
-
有声内容创作:你只需把小说文本输入VoxCPM2,结合音色设计功能为每个角色赋予独特声音,一本有声书的初版音频就能在很短时间内生成。而且VoxCPM2在长文本生成上经过专门优化,大幅减少了音频伪影,确保整段音频的聆听体验连贯自然。
-
游戏与虚拟角色配音:在游戏开发中,NPC配音长期以来是既耗费人力又占用经费的环节。VoxCPM2让开发者可以通过文字描述批量设计上百个NPC的音色,并在剧情对话中灵活调整情感走向。
-
跨语言出海与国际化本地化:一条中文广告片,无需另请外籍声优,VoxCPM2可以直接用原声说话者的音色生成泰语、越南语、印尼语等多语种版本。跨语言克隆能力意味着你可以用自己的声音流利说出阿拉伯语或日语。
-
智能语音助手与车载交互:VoxCPM2的低延迟流式推理(RTF≈0.13)使其非常适合部署在车载算力有限的环境中,实现个性化、及时性的语音响应——你的车载助手不再是一个千篇一律的机械女声,它可以是你熟悉和亲近的任何一种声音。
参考链接与体验入口
– 🌐 官方网站:https://voxcpm.com/zh/
– 🐙 GitHub开源仓库:https://github.com/OpenBMB/VoxCPM
– 🤗HuggingFace:https://huggingface.co/openbmb/VoxCPM2
– 🎮 在线Demo体验:https://voxcpm.modelbest.cn/