 夜雨聆风
夜雨聆风





Splunk 的 AI RCA 给了一个提醒:别再只做 AI 运维助手了
最近看完 Splunk / Cisco 在 AI RCA 方向的一批公开资料后,我最大的感受是:
Splunk 并不是在做一个更会聊天的运维助手。
它真正想做的,是把 AI 放进一条完整的故障处理链路里:告警触发、影响面分析、候选根因、证据呈现、历史相似事件、行动计划、外部工具调用。
这点对国内可观测性厂商很重要。
现在很多产品一提 AI RCA,第一反应还是做一个聊天框,让用户自己输入服务名、时间范围、告警信息、日志关键词,然后等模型总结一段话。
这个方向不是没价值,但很容易停在 Demo 阶段。
真正的一线排障场景里,用户不想从空白聊天框开始。他们想知道:
-
这个告警影响了谁? -
最可能的问题在哪里? -
证据是什么? -
有没有历史相似事故? -
下一步该查什么? -
哪些动作有风险,需要人确认?
Splunk 的产品路线,正好给了一个参考答案。
先说结论
Splunk 的 AI RCA 大致有三条线。
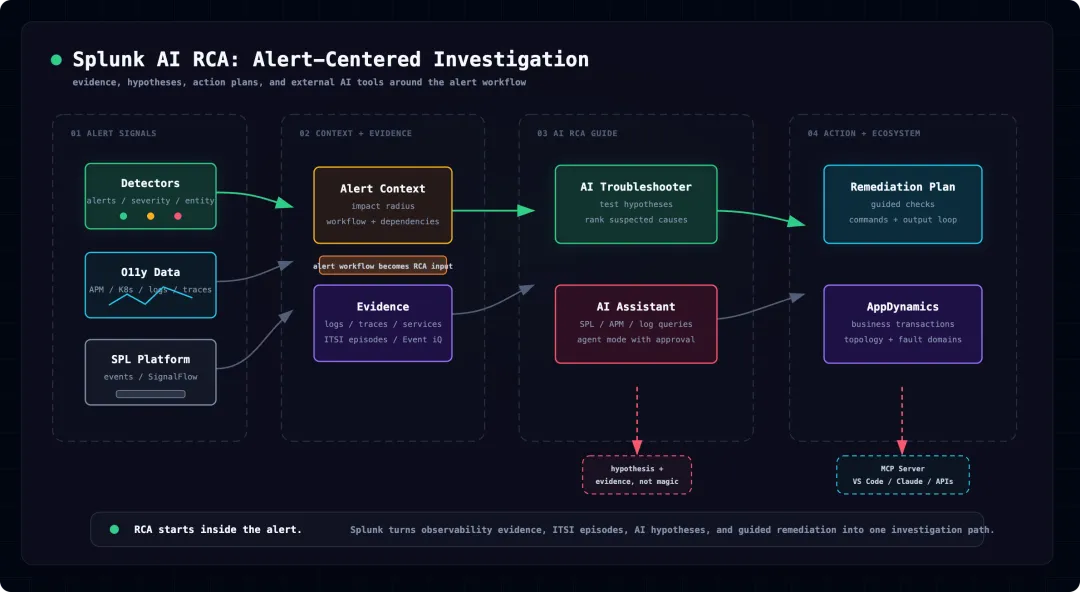
第一条线,是 Splunk Observability Cloud 里的 AI Troubleshooting Agent。它把 RCA 放进告警详情页,用户打开 alert 后,系统自动分析 APM、Kubernetes、日志、指标、trace、service dependency、workflow,给出影响面、候选根因、证据和 remediation plan。
第二条线,是 AI Assistant / Agent Mode / MCP Server。它把自然语言、SPL、SignalFlow、APM 查询、alert/incident 查询和外部 AI 工具连起来,让排障不只发生在 Splunk UI 里,也可以进入 IDE、AI coding assistant 和其他工作流。
第三条线,是 ITSI + AppDynamics 这些更传统但很扎实的 AIOps / APM 能力。ITSI 负责把告警风暴聚合成 episode,AppDynamics 负责业务交易、应用拓扑、异常检测和 suspected causes。
所以,Splunk 的重点不是“模型能不能直接说出根因”。
它的重点是:先把问题单元、上下文、证据链和行动路径组织好,再让 AI 介入。
1. RCA 的入口应该是告警页,不是聊天框
Splunk 当前最像 AI RCA 产品形态的能力,是 Observability Cloud 里的 AI Troubleshooting Agent。
它不是一个独立的 AI 页面,而是嵌在 alert workflow 里。用户打开告警后,可以看到几个核心区域:
-
Overview:告警摘要、触发规则、影响面、blast radius、primary root cause。 -
Root Cause Analysis:候选根因列表,以及每个候选原因的摘要和跳转链接。 -
Evidence:相关日志、exemplar traces、APM services 等证据。 -
Remediation plan:进一步检查和处理步骤。
这个入口设计很关键。
告警已经天然带着结构化上下文:service、detector、time range、severity、affected entity、labels。平台不应该让用户再手工复制这些信息到聊天框里。
更合理的做法是:用户从 Slack、邮件、ServiceNow 或 IM 通知里打开告警,系统自动完成第一轮机器调查。
国内很多 AI 运维助手最大的问题就在这里:它把本该由平台自动补齐的上下文,重新丢给用户输入。
这不是智能化,是换了一种方式让用户干活。
2. 好的 AI RCA 不急着宣布“根因已确定”
Splunk 和 AppDynamics 的文档里,反复使用的是 suspected root causes、hypotheses、evidence 这类表达。
这个措辞非常重要。
真实故障现场里,很多时候没有一个模型可以立刻给出绝对根因。更可信的产品表达应该是:
-
这是候选原因; -
它为什么可疑; -
支持证据有哪些; -
还需要验证什么; -
有没有反证或不确定性; -
下一步应该怎么查。
如果一个产品上来就说“根因已确定”,反而会让 SRE 警惕。
AI RCA 要建立信任,不是靠语气坚定,而是靠证据可追溯。
Splunk 的 Evidence tab 就是这个逻辑。它把 logs、traces、APM services 等证据放在单独区域,而不是只输出一段自然语言总结。
对国内产品来说,这里有一个很直接的启发:AI 结论旁边必须有证据面板。
至少应该展示:
-
关联指标; -
关联日志模式; -
关联 trace/span; -
相关实体; -
时间关系; -
影响范围; -
置信度或优先级; -
可继续验证的链接。
否则,AI RCA 就很容易变成“看起来很像那么回事”的报告生成器。
3. Remediation plan 比“自动修复”更现实
Splunk 的 remediation plan 没有一上来承诺“自动修复生产系统”。
它更像一个交互式 runbook:AI 给出 hypotheses、root causes、下一步检查、命令或代码块,用户可以复制执行,再把结果提交回来,系统根据结果决定下一步。
这个设计很现实。
企业客户不是不想自动化,而是不愿意把生产变更直接交给一个黑盒模型。
更容易落地的路径是:
-
AI 先生成检查计划; -
只读查询可以自动执行; -
高成本查询需要确认; -
写操作和生产变更必须审批; -
所有动作都要有审计; -
最后沉淀成复盘和 runbook。
这比“AI 一键修复”慢一点,但更容易进入真实生产。
4. ITSI 的价值:先把告警风暴变成一个问题
Splunk ITSI 不是一个新概念,但在 AI RCA 里很关键。
RCA 不能直接面对告警风暴。几十条、几百条告警同时出现时,第一步不是问模型“根因是什么”,而是先定义:我们到底要分析哪个问题?
ITSI 的 episode 模型就是做这件事。
它把 notable events 通过规则和相似性聚合成 episode,并提供影响面、事件时间线、共同字段、相似历史、评论、指派、外部工单等能力。
这里有两个细节值得学。
第一个是 Events Timeline。它支持按 RCA 视角排序,帮助用户看“哪个事件最先从正常变成异常”。很多时候,最严重的告警不一定是最早的问题源头。
第二个是 Similar Episodes。它让用户查历史相似事故,看过去怎么解决。真正的排障高手不是每次从零推理,而是见过足够多相似问题。产品化的相似事故检索,就是把组织记忆放进一线响应流程。
这对国内厂商尤其重要。
很多 AI RCA 项目失败,并不是模型不够强,而是前面的事件聚合、字段治理、历史事故沉淀没有做好。
没有稳定的问题单元,AI 只能对一堆噪声做总结。
5. Event iQ 说明了一个现实:聚合规则也需要 AI
ITSI 里的 Event iQ 用机器学习分析历史事件,帮助识别哪些字段适合用于事件关联和 grouping policy。
这解决的是 AIOps 落地里非常现实的问题:聚合规则很难配。
传统做法往往要求用户自己判断:
-
哪些字段代表同一个问题; -
哪些字段不能聚合; -
时间窗口多长合适; -
哪些清除事件可以关闭 episode; -
哪些动作可以自动触发。
但在真实客户环境里,告警字段经常不规范,服务名、主机名、集群名、业务标签也不统一。让用户手工配好所有规则,难度很高。
Event iQ 的思路更务实:先从历史事件里找模式,推荐聚合字段和策略,再让用户确认。
这比直接让 AI 回答根因更基础,也更重要。
6. MCP Server 代表了另一个方向:可观测性平台要变成工具层
Splunk 还提供了 Splunk MCP Server,把 Observability Cloud 的能力暴露给外部 AI 工具。
它支持的工具包括 metrics / SignalFlow、APM service、service dependency、latency、errors、exemplar traces、alert / incident search 等。
这个方向值得提前关注。
未来故障定位不一定只发生在监控控制台里。它可能发生在:
-
IDE; -
AI coding assistant; -
企业微信/飞书/钉钉; -
工单系统; -
事故频道; -
私有化大模型门户。
如果可观测性平台只把 AI 做在自己的页面里,会限制使用场景。
更好的定位是:平台提供可靠的数据、上下文、查询能力和工具调用,成为 AI agent 的证据层和工具层。
这也是 MCP Server 对国内厂商最大的启发。
7. AppDynamics 提醒我们:别只盯着 Kubernetes
Cisco 收购 Splunk 后,AppDynamics 也是这条产品线里很重要的资产。
AppDynamics 的 RCA 更偏传统和混合应用,强调 Business Transaction、flow map、anomaly detection、Top Suspected Causes、fault domain isolation。
它的逻辑是:先看到业务交易性能变差,再沿着调用路径、服务、后端、基础设施往下定位,把 suspected cause 所在路径高亮出来。
这对国内市场很有参考价值。
很多大客户并不是纯 Kubernetes、纯微服务。传统 Java/.NET、三层应用、数据库、中间件、SAP、专线网络、混合云、数据中心环境仍然大量存在。
AI RCA 如果只围绕云原生标签设计,很容易忽略这些客户真正复杂的部分。
8. 对国内厂商的几个直接建议
第一,把 AI RCA 放进告警详情页。
告警页应该天然带出 Overview、候选根因、证据、影响面、历史相似事件和 Action plan。不要让用户从空白聊天框开始。
第二,少说“确定根因”,多说“候选原因 + 证据 + 下一步验证”。
这更符合真实故障现场,也更容易赢得 SRE 信任。
第三,把事件聚合做成 AI RCA 的前置能力。
先把告警去重、聚合、归并成 incident / episode / problem,再做 RCA。否则 AI 只能被告警风暴淹没。
第四,把日志、trace、指标的关联字段治理好。
trace id、service.name、env、cluster、namespace、pod、host、version、region 这些字段如果不统一,AI RCA 很难深入。
第五,把 runbook 做成交互式 remediation plan。
AI 不只是输出“建议检查 CPU”,而是给出步骤、查询、预期结果、分支判断和下一步动作。
第六,对高成本和高风险动作做权限、确认和审计。
日志扫描、复杂查询、脚本执行、生产变更,都不能让 AI 随便跑。
第七,让 AI 支持查询语言,而不是绕开查询语言。
PromQL、LogQL、SQL、TraceQL、自研 DSL 不会因为 AI 出现而消失。更现实的是让 AI 生成、解释、优化查询,并把用户带回原生查询页面。
第八,打通 IM、IDE、工单和事故频道。
工程师排障不一定愿意打开监控控制台。可观测性平台应该把能力开放出去。
最后
Splunk 的 AI RCA 路线最值得学的,不是某个单点功能。
它真正有价值的地方,是没有把 RCA 简化成“AI 问答”。
它把 AI 放在多个成熟对象上:
-
Observability Cloud 的 alert; -
ITSI 的 episode; -
AppDynamics 的 anomaly 和 business transaction; -
Splunk 平台的 search; -
MCP 的 tool; -
remediation plan 的 action。
这背后的判断是对的。
AI RCA 需要稳定的产品对象、结构化上下文和可追溯证据链。
对国内可观测性厂商来说,与其急着包装一个“AI 运维助手”,不如先把告警、事件、证据、历史事故、查询语言、权限审计和行动计划这条链路打通。
聊天框只是入口之一。
真正决定产品能不能落地的,是它能不能在故障发生时,帮一线人员少跳几个页面、少写几条查询、少猜几次方向,并且每一步都有证据。
可观测性 + AI 这套东西涉及的信息比较多,很多公司的人力主要投入在主营业务上,无暇他顾,如果您需要一个靠谱的乙方来帮您构建这套体系,欢迎联系我们做产品技术交流:https://flashcat.cloud/contact/
参考资料
-
Splunk Docs: AI troubleshooting agent and remediation plan in Splunk Observability Cloud https://help.splunk.com/en/splunk-observability-cloud/create-alerts-detectors-and-service-level-objectives/create-alerts-and-detectors/ai-troubleshooting-agent-and-remediation-plan -
Splunk Blog: Accelerate Resolution and Prevent Future Outages with Splunk Observability Cloud https://www.splunk.com/en_us/blog/observability/ai-troubleshooting-agent-in-splunk-observability-cloud -
Splunk Docs: Splunk AI Assistant in Observability Cloud https://help.splunk.com/en/splunk-observability-cloud/splunk-ai-assistant/ai-assistant-in-observability-cloud -
Splunk Docs: Prompt guide and library for AI Assistant in Observability Cloud https://help.splunk.com/en/splunk-observability-cloud/splunk-ai-assistant/prompt-guide-and-library-for-ai-assistant-in-observability-cloud -
Splunk Docs: Interact with your observability data using the Splunk MCP server https://help.splunk.com/en/splunk-observability-cloud/splunk-ai-assistant/interact-with-your-observability-data-using-the-splunk-mcp-server -
Splunk Docs: Related Content in Splunk Observability Cloud https://help.splunk.com/en/splunk-observability-cloud/data-tools/related-content -
Splunk Docs: View dependencies in the service map in Splunk APM https://help.splunk.com/en/splunk-observability-cloud/monitor-application-performance/manage-services-spans-and-traces-in-splunk-apm/view-dependencies-in-the-service-map -
Splunk Docs: Find the root cause of an error using Tag Spotlight https://help.splunk.com/en?resourceId=apm_apm-scenarios_troubleshoot-tag-spotlight -
Splunk Docs: Use and manage Troubleshooting MetricSets https://help.splunk.com/en/splunk-observability-cloud/monitor-application-performance/analyze-services-with-span-tags-and-metricsets/learn-about-troubleshooting-metricsets/use-and-manage-troubleshooting-metricsets -
Splunk Docs: About Splunk AI Assistant https://help.splunk.com/en/splunk-enterprise/search/splunk-ai-assistant -
Splunk Docs: Agent Mode in Splunk AI Assistant https://help.splunk.com/en/splunk-enterprise/search/splunk-ai-assistant/2.0.0/use-splunk-ai-assistant/agent-mode-in-splunk-ai-assistant -
Splunk Docs: Overview of Event Analytics in ITSI https://help.splunk.com/en/splunk-it-service-intelligence/splunk-it-service-intelligence/detect-and-act-on-notable-events/4.20/overview/overview-of-event-analytics-in-itsi -
Splunk Docs: Investigate episodes in ITSI https://help.splunk.com/en/splunk-it-service-intelligence/splunk-it-service-intelligence/detect-and-act-on-notable-events/4.18/episode-review/investigate-episodes-in-itsi -
Splunk Docs: Automate event correlation with Event iQ in ITSI https://help.splunk.com/en/splunk-it-service-intelligence/splunk-it-service-intelligence/detect-and-act-on-notable-events/4.21/event-correlation/automate-event-correlation-with-event-iq-in-itsi -
Cisco Newsroom: Cisco Supercharges Observability with Agentic AI for Real-Time Business Insights https://newsroom.cisco.com/c/r/newsroom/en/us/a/y2025/m09/cisco-supercharges-observability-with-agentic-ai-for-real-time-business-insights.html -
Splunk Docs: What is Root Cause Analysis (RCA)? in AppDynamics https://help.splunk.com/en/appdynamics-saas/get-started/26.4.0/alert-and-respond/anomaly-detection/what-is-root-cause-analysis-rca -
Splunk Docs: Troubleshooting Anomalies in AppDynamics https://help.splunk.com/en/appdynamics-on-premises/virtual-appliance-self-hosted/25.7.0/anomaly-detection/troubleshooting-anomalies -
Splunk Product Page: Splunk AppDynamics https://www.splunk.com/en_us/products/splunk-appdynamics.html -
Splunk Blog: Cisco builds a unified observability experience between AppDynamics and Splunk https://www.splunk.com/en-us/blog/observability/cisco-builds-a-unified-observability-experience-between-appdynamics-and-splunk.html -
Splunk Blog: Introducing Log Observer Connect for AppDynamics https://www.splunk.com/en_us/blog/observability/log-observer-connect-for-appdynamics.html