 夜雨聆风
夜雨聆风





漫说龙虾|第40集:知识库——让OpenClaw成为行业专家
【漫说龙虾】合集请看➡️:漫说龙虾系列

【摘要】
OpenClaw本身只是一个AI框架,它的知识来自通用大模型——但你可以把私有知识喂给它,让它成为你们公司、你们行业、你们业务的专属AI专家。本期小钳讲清楚RAG(检索增强生成)是什么、怎么把PDF/Word/飞书文档接入OpenClaw、以及如何配置才能让AI在回答时优先使用你的知识库而不是瞎编。
1. 小钳遇到了知识盲区
凡哥在做技术咨询时,发现OpenClaw回答客户问题时偶尔会”瞎编”——明明公司有相关规定,但AI不知道;明明这个产品是去年才发布的,AI却说不存在。
“小钳,你怎么连自己公司的事都不知道?”
小钳委屈地夹了夹大钳:”凡哥,我是通用AI,你公司的事我怎么可能知道?你得给我喂资料才行!”
“怎么喂?”
“这就要用到知识库了。把你们的文档、产品手册、公司规范全部接入OpenClaw,它就能像你们的专属顾问一样,用你们的知识来回答问题。”

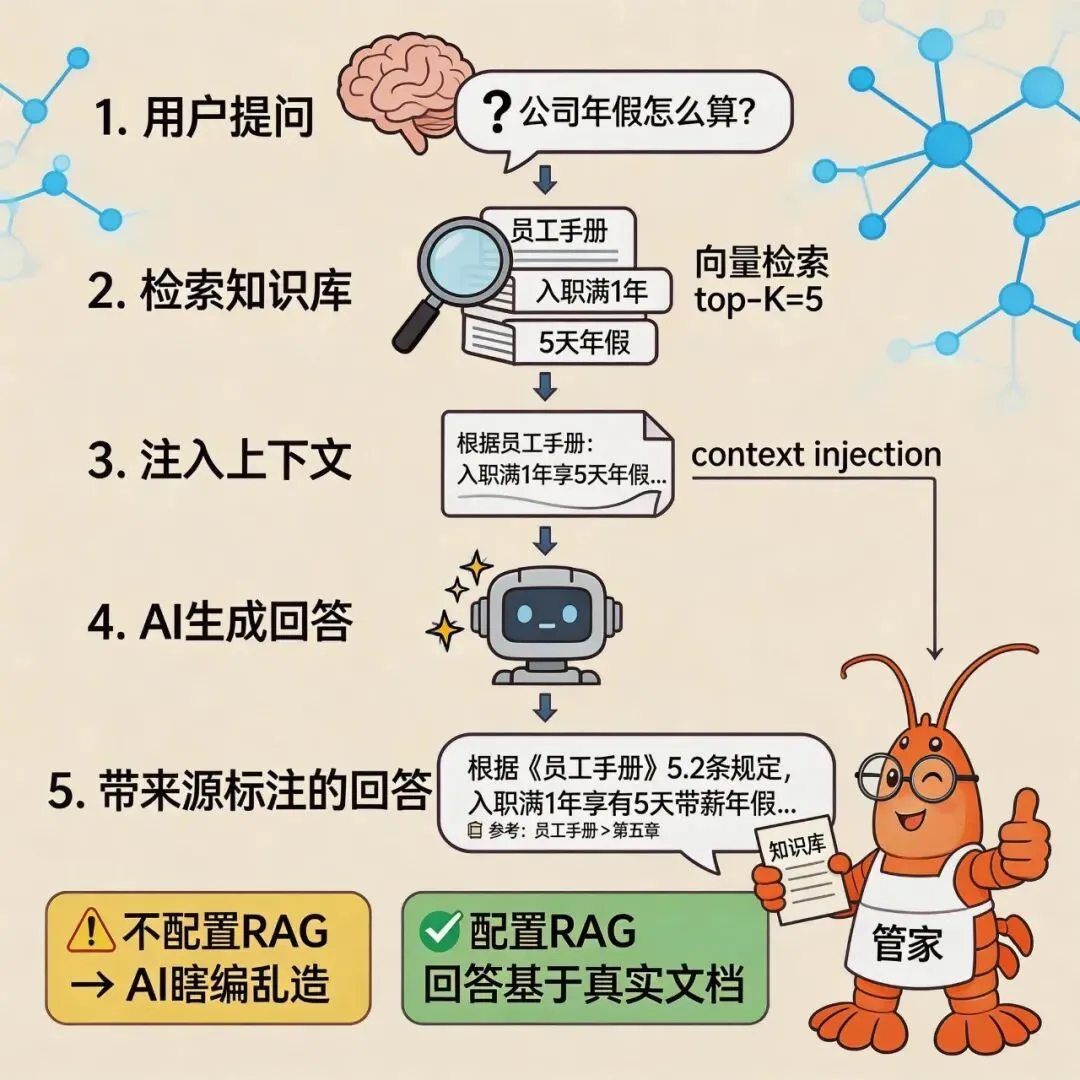
2. 什么是RAG?
在动手配置之前,先弄清楚原理。
RAG = Retrieval-Augmented Generation(检索增强生成)
普通AI回答问题靠的是训练时学到的知识;RAG则是:
-
1. 先从你的文档里检索相关信息 -
2. 把检索到的内容注入给AI作为上下文 -
3. AI在检索到的真实内容基础上生成回答
用户提问:「我们公司年假怎么算?」 ↓检索:「员工手册第5.2条:入职满1年享5天年假...」 ↓注入上下文:「根据公司员工手册:入职满1年享5天年假...」 ↓AI生成:「根据员工手册规定,入职满1年的员工享有5天带薪年假...」关键点:AI回答的内容来自你的真实文档,而不是瞎编。
3. 第一步:整理知识库文档
知识库的质量直接决定AI回答的质量。在接入之前,先整理好文档。
3.1 文档类型优先级
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.2 文档格式建议
RAG效果最好的文档格式:
-
• Markdown(.md) → 效果最好,结构清晰 -
• Word(.docx) → 需转换为md -
• PDF(.pdf) → 需提取文字 -
• 飞书文档 → 可直接接入 -
• 网页(URL) → 可直接抓取
3.3 文档目录结构
~/.openclaw/workspace/└── knowledge-base/ ├── company/ │ ├── policies.md ← 公司制度 │ ├── org-chart.md ← 组织架构 │ └── benefits.md ← 员工福利 ├── products/ │ ├── product-a.md ← 产品A手册 │ ├── product-b.md ← 产品B手册 │ └── faq.md ← 常见问题 ├── industry/ │ └── market-report.md ← 行业报告 └── processes/ └── onboarding.md ← 入职流程4. 第二步:配置向量数据库
文档要能被检索,需要先转换成”向量”存入向量数据库。这个过程叫Embedding(向量化)。
4.1 选择Embedding模型
OpenClaw支持多种Embedding模型:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4.2 配置Embedding
{ memory: { embedding: { provider: "openai", model: "text-embedding-3-small", apiKey: { source: "env", id: "OPENAI_API_KEY" } } }}4.3 配置向量数据库
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
{ memory: { vectorStore: { provider: "faiss", // FAISS是本地文件存储,不需要额外服务 indexPath: "~/.openclaw/workspace/knowledge-base/index" } }}5. 第三步:接入文档
5.1 手动导入文档
# 导入单个文档到知识库openclaw kb add \ --file "~/documents/product-manual.md" \ --category "products"# 批量导入整个目录openclaw kb add \ --dir "~/.openclaw/workspace/knowledge-base" \ --recursive5.2 接入PDF文档
PDF需要先提取文字再导入:
# 用Python提取PDF文字pip install pymupdfpython -c "import fitzdoc = fitz.open('product-manual.pdf')text = '\n'.join([page.get_text() for page in doc])with open('product-manual.md', 'w', encoding='utf-8') as f: f.write(text)print('PDF extracted, pages:', len(doc))"# 导入到知识库openclaw kb add --file "product-manual.md" --category "products"5.3 接入飞书文档
飞书文档是很多公司的知识沉淀中心:
## 飞书文档接入Skill## 触发条件用户说「同步飞书知识库」或定时触发## 操作步骤1. 调用飞书API获取文档列表2. 遍历指定文件夹下的文档3. 抓取每个文档的内容(支持云文档API)4. 转换为Markdown格式5. 批量导入到OpenClaw知识库## 配置需要先配置飞书开放平台应用权限:- docx: document.content:readonly- docx: document.meta:readonly5.4 定时增量更新
知识库需要定期更新,新增文档要同步:
{ "cron": { "weekly-kb-sync": { "schedule": "0 2 * * 0", "command": "openclaw kb sync --all" } }}6. 第四步:配置RAG检索
文档接入后,还需要配置检索规则,让AI在回答时优先用知识库。
6.1 配置检索参数
{ memory: { search: { // 检索时返回的最大文档数 topK: 5, // 检索相关性阈值(0-1,越高越严格) scoreThreshold: 0.7, // 是否混合搜索(向量+关键词) hybridSearch: true } }}6.2 配置RAG Skill
---name: rag-answerdescription: 基于知识库回答问题,优先使用私有文档---# RAG回答Skill## 触发条件用户提出任何问题。## 执行流程### 第一步:判断是否需要检索如果问题明显涉及私人/本地知识(公司、产品、业务流程),执行RAG。如果问题是通用知识(历史、常识、技术概念),直接回答。### 第二步:检索知识库检索词:{用户问题的关键词}范围:相关类别的文档返回:top 5 最相关的段落
### 第三步:判断检索质量- 如果检索结果相关性 > 0.8 → 基于检索结果回答- 如果检索结果相关性在 0.5-0.8 → 基于检索结果+补充知识回答- 如果检索结果相关性 < 0.5 → 坦诚告知知识库无相关信息,建议人工### 第四步:生成回答使用RAG Prompt模板:基于以下知识回答用户问题:{检索到的文档内容}
用户问题:{用户问题}回答要求:
-
• 只使用上述文档中的信息 -
• 如信息不足,坦诚说明 -
• 引用相关文档位置
### 第五步:标注信息来源回答末尾标注:📚 参考文档:• {文档名} – {相关章节}
## 回答格式示例根据《员工手册》第5.2条规定:入职满1年的员工享有5天带薪年假…
📚 参考文档:员工手册 > 第五章 假期管理
7. 第五步:知识库运营维护
知识库不是一次性建好就完事的,需要持续运营。
7.1 文档质量监控
定期检查知识库的准确性:
## 知识库质量检查Skill(每月执行)## 检查项目1. 文档数量和总量变化2. 最近更新的文档数量3. 检索命中率(知识库被用到的频率)4. 回答准确率(人工抽检)## 告警规则- 某类问题连续3次检索无结果 → 该领域文档可能缺失- 检索命中率 > 80% → 知识库使用率高- 文档总数月增长 < 5篇 → 知识库更新不及时7.2 知识库问答日志
记录每次RAG问答,方便后续改进:
## RAG问答日志格式```json{ "timestamp": "2026-04-14T10:30:00+08:00", "question": "公司年假怎么算?", "retrieved_docs": [ {"doc": "员工手册.md", "section": "第五章", "score": 0.92} ], "answer_source": "员工手册 第五章 5.2条", "user_feedback": "正确", "corrected": false}7.3 知识库优化循环
用户提问 → 检索 → 生成回答 → 用户反馈 ↑ ↓ ← 知识库更新 ← 分析反馈 ←根据用户反馈,不断补充缺失文档、修正错误表述、优化检索关键词。
8. 常见问题与解决
问题1:AI仍然在瞎编
原因:检索结果不相关,AI没有使用知识库内容。
排查:
# 查看最近一次检索的详情openclaw kb search "问题关键词" --verbose# 查看返回的相关性分数# 如果最高分 < 0.5,说明没有匹配到相关内容解决:
-
1. 检查知识库是否有相关文档 -
2. 降低 scoreThreshold(如从0.7降到0.5) -
3. 优化文档的关键词标注
问题2:检索太慢
原因:文档量太大,检索性能下降。
解决:
-
• 启用ANN(近似最近邻)索引加速 -
• 分段索引,按类别隔离 -
• 使用更快的Embedding模型
问题3:文档格式混乱
原因:PDF/Word文档排版复杂,提取后格式乱七八糟。
解决:
-
1. 尽量使用Markdown作为知识库格式 -
2. Word/HTML文档转换后手动清洗 -
3. 建立知识库编写规范(统一模板)
9. 知识库效果评估
用这几个指标衡量知识库的效果:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
【配置箱】知识库最小配置
{ memory: { embedding: { provider: "openai", model: "text-embedding-3-small", apiKey: { source: "env", id: "OPENAI_API_KEY" } }, vectorStore: { provider: "faiss", indexPath: "~/.openclaw/workspace/knowledge-base/index" }, search: { topK: 5, scoreThreshold: 0.6, hybridSearch: true } }, skills: { entries: { "rag-answer": { enabled: true } } }}对应的目录结构:
~/.openclaw/workspace/└── knowledge-base/ ├── index/ ← 向量索引目录 ├── company/ ← 公司文档 ├── products/ ← 产品文档 └── processes/ ← 流程文档【避坑提示】
坑1:把所有文档都塞进知识库知识库不是越多越好。文档质量参差不齐,差的文档会拉低检索质量。只放经过审核的、准确的、常用的文档。
坑2:不更新旧文档知识库里的文档过期了,AI还在用旧信息回答。务必建立文档更新机制,过期文档及时删除或更新。
坑3:完全依赖AI不核实AI偶尔还是会在检索结果不准确时瞎编。重要问题(如合规、财务、医疗)必须有人工复核流程,不能完全交给AI。
【认知升级】
知识库的本质是把组织的知识资产变成AI的生产力。
很多公司的知识散落在各种文档、飞书、邮件里,找起来费劲,用起来更费劲。把这些知识整理进OpenClaw的知识库,AI就能帮你检索、总结、回答——相当于给整个公司配了一个永远不会忘记、永远不会疲倦的超级助理。
但要注意,知识库不是万能药。它的效果取决于:文档质量 × 检索配置 × 持续运营。三者缺一不可。



欢迎加入交流群
一起赢在AI时代

后台加凡哥微信后入群