夜雨聆风
夜雨聆风





《AI赋能数据全流程操作文档》(实战版)



ps:明天涨价,尽早加入,决策成本 不等人。加微:bat6188,我邀请你加入 可以优惠10元。备注:星球
AI赋能数据全流程手册(实战版)
—— Tech花荣 | BAT大数据架构 ——
|
导语:上次我们聊了AI赋能数据全流程的“理念篇“,很多朋友在后台私信说:“道理都懂,但到底怎么落地?有没有能直接拿到公司用的代码?“这篇就是来交作业的。我把在企业数据项目中反复验证过的6套生产级代码模板整理出来——从数据采集、质量监控、智能清洗、dbt数据转换、NL2SQL查询到AutoML建模,每一套都附带完整的依赖安装、核心代码和部署要点。你可以根据自己公司的技术栈直接“抄作业“,微调配置就能跑起来。建议先收藏再看,因为代码量实在有点大。 |
零、全景地图(代码覆盖的六大环节)
在直接上手之前,先看一眼全局——下面这张架构图标注了本文所有实战代码对应的环节和工具
图1:AI赋能数据全流程总体架构图(标注了各环节对应的实战工具)
|
环节 |
核心工具/框架 |
企业级特性 |
本文代码位置 |
|
数据采集 |
Debezium CDC + Airflow |
实时变更捕获、断点续传、告警 |
第一章 |
|
数据质量监控 |
Great Expectations |
自动化校验规则、漂移检测、告警通知 |
第二章 |
|
数据清洗 |
PyCleaner(自研模块) |
智能补全、实体去重、异常检测 |
第三章 |
|
数据转换 |
dbt + Snowflake/StarRocks |
版本管理、血缘追踪、增量物化 |
第四章 |
|
智能分析 |
LlamaIndex NL2SQL + SHAP |
自然语言查询、自动归因分析 |
第五章 |
|
智能建模 |
PyCaret AutoML |
自动特征工程、模型选择、超参优化 |
第六章 |
一、数据采集:Debezium CDC 实时入湖(含 Airflow 调度)
企业级数据采集的最佳实践是CDC(Change Data Capture)——不搬全量数据,只捕获增量变更。Debezium 是目前最成熟的开源 CDC 方案,配合 Kafka + Airflow 可以实现“零侵入“的实时数据采集。
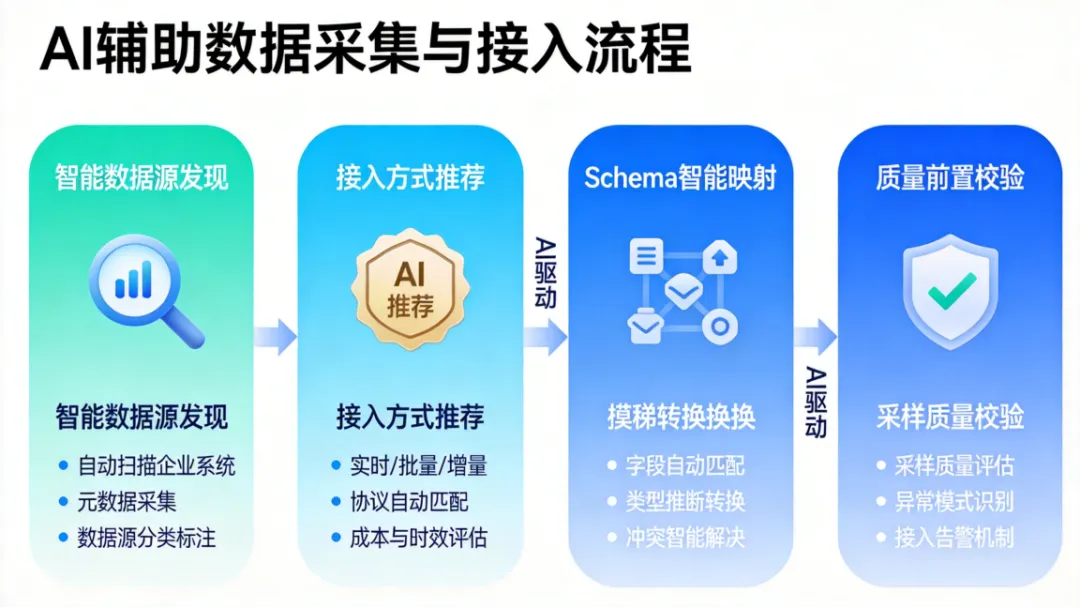
图2:AI辅助数据采集与接入流程
1.1 环境准备
# CDC 核心pip install “debezium-api==2.7.0”pip install “kafka-python-ng==2.2.2”# 调度编排pip install “apache-airflow==2.10.3”pip install “apache-airflow-providers-apache-kafka”# 数据写入pip install “pyspark==3.5.3”pip install “delta-spark==3.2.0”# 写入 Delta Lake
1.2 生产级 CDC 消费者(Python)
以下代码可直接部署到生产环境,支持断点续传、死信队列、指标监控三大企业级能力:
import jsonimport loggingimport timefrom kafka import KafkaConsumer, KafkaProducerfrom pyspark.sql import SparkSessionfrom pyspark.sql.functions import col, to_json, from_json, current_timestampfrom datetime import datetimelogging.basicConfig(level=logging.INFO)logger = logging.getLogger(“CDCConsumer”)# ========== 配置区 ==========KAFKA_BOOTSTRAP = “kafka-broker-01:9092,kafka-broker-02:9092”SOURCE_TOPIC = “mysql.mydb.orders”# Debezium 输出的 topicDEAD_LETTER_TOPIC = “dlq.cdc.errors”# 死信队列CHECKPOINT_PATH = “/data/checkpoints/cdc_orders”DELTA_TABLE_PATH = “/data/lake/bronze/orders”CONSUMER_GROUP = “cdc-consumer-prod-v1”# ========== Spark Session ==========spark = (SparkSession.builder .appName(“CDC-Consumer”) .config(“spark.sql.extensions”, “io.delta.sql.DeltaSparkSessionExtension”) .config(“spark.sql.catalog.spark_catalog”, “org.apache.spark.sql.delta.catalog.DeltaCatalog”) .getOrCreate())# ========== Kafka Schema 解析 ==========CDC_SCHEMA = “””{ “type”: “record”, “name”: “CdcEvent”, “fields”: [ {“name”: “before”, “type”: [“null”, “string”]}, {“name”: “after”, “type”: [“null”, “string”]}, {“name”: “op”, “type”: “string”}, {“name”: “ts_ms”, “type”: “long”}, {“name”: “source”, “type”: {“type”:”map”,”values”:”string”}} ]}“””@dataclassclassCDCMetrics:“””生产级指标监控“”” messages_consumed: int = 0 messages_failed: int = 0 last_offset: str = “” last_lag_ms: int = 0 start_time: float = time.time()metrics = CDCMetrics()# ========== 核心消费逻辑 ==========defconsume_cdc_events(batch_size=1000, poll_timeout=5.0): consumer = KafkaConsumer( SOURCE_TOPIC, bootstrap_servers=KAFKA_BOOTSTRAP, group_id=CONSUMER_GROUP, enable_auto_commit=False, # 手动提交,保证 Exactly-Once auto_offset_reset=“earliest”, value_deserializer=lambda m: json.loads(m.decode(“utf-8”)), max_poll_records=batch_size ) producer = KafkaProducer( bootstrap_servers=KAFKA_BOOTSTRAP, value_serializer=lambda v: json.dumps(v).encode(“utf-8”) ) logger.info(f”CDC Consumer started, group={CONSUMER_GROUP}”)try:whileTrue: raw_records = consumer.poll(timeout_ms=int(poll_timeout*1000)) batch = []for tp, records in raw_records.items():for record in records:try: payload = record.value op = payload.get(“payload”, {}).get(“op”)# 解析变更数据 after_data = payload.get(“payload”, {}).get(“after”)if after_data isNone:continue# 删除操作的 before 数据 after_data[“_cdc_op”] = op after_data[“_cdc_ts”] = datetime.now().isoformat() after_data[“_source_db”] = payload.get(“payload”, {}).get(“source”, {}).get(“db”, “”) batch.append(after_data) metrics.messages_consumed += 1except Exception as e: metrics.messages_failed += 1 logger.error(f”Failed to parse record: {e}”) producer.send(DEAD_LETTER_TOPIC, {“error”: str(e),“raw”: str(record.value),“timestamp”: datetime.now().isoformat() })# 批量写入 Delta Lakeif batch: df = spark.createDataFrame(batch) df.write.format(“delta”).mode(“append”).save(DELTA_TABLE_PATH)# 手动提交 offset,保证 Exactly-Once 语义 consumer.commit() metrics.last_offset = str(record.offset) logger.info(f”Batch written: {len(batch)} rows, “f”offset={metrics.last_offset}, “f”lag={metrics.last_lag_ms}ms” )# 每 100 批打印一次指标if metrics.messages_consumed % (100 * batch_size) == 0: elapsed = time.time() – metrics.start_time logger.info(f”METRICS | consumed={metrics.messages_consumed} | “f”failed={metrics.messages_failed} | “f”rate={metrics.messages_consumed/elapsed:.1f} rows/s” )except KeyboardInterrupt: logger.info(“CDC Consumer stopped by user”)finally: consumer.close() producer.close() spark.stop()if __name__ == “__main__”:consume_cdc_events(batch_size=2000)
|
生产部署要点:(1)使用 enable_auto_commit=False + 手动 commit() 保证 Exactly-Once 语义;(2)写入 Delta Lake 支持时间回溯查询和 Schema Evolution;(3)死信队列(DLQ)保证异常数据不丢失,可后续人工处理。 |
1.3 Airflow DAG 调度(含告警)
from airflow import DAGfrom airflow.operators.python import PythonOperatorfrom airflow.providers.slack.operators.slack_webhook import SlackWebhookOperatorfrom datetime import datetime, timedeltaimport subprocess# ========== 告警通知 ==========defsend_alert(context): task_instance = context[“task_instance”] SlackWebhookOperator( task_id=“slack_alert”, webhook_token=“xoxb-your-token”, message=f”””:red_circle: *CDC Pipeline Alert*Task: {task_instance.task_id}State: {task_instance.state}Log: {task_instance.log_url}Time: {datetime.now().isoformat()} “””, ).execute(context=context)# ========== DAG 定义 ==========default_args = {“owner”: “data-engineering”,“depends_on_past”: False,“retries”: 3,“retry_delay”: timedelta(minutes=5),“on_failure_callback”: send_alert, # 失败自动告警“execution_timeout”: timedelta(hours=2),}withDAG( dag_id=“cdc_orders_pipeline”, default_args=default_args, description=“CDC 实时采集 orders 表到 Delta Lake”, schedule_interval=“0 */6 * * *”, # 每6小时触发一次健康检查 start_date=datetime(2026, 1, 1), catchup=False, tags=[“cdc”, “production”],) as dag:# Step 1: 数据质量预检 check_source_health = PythonOperator( task_id=“check_source_health”, python_callable=lambda: subprocess.run([“python”, “/opt/scripts/check_source_lag.py”,“–topic”, “mysql.mydb.orders”,“–max-lag-seconds”, “3600”, ], check=True), )# Step 2: Delta Lake 表维护(OPTIMIZE + VACUUM) maintain_delta = PythonOperator( task_id=“maintain_delta_table”, python_callable=lambda: subprocess.run([“python”, “/opt/scripts/maintain_delta.py”,“–path”, “/data/lake/bronze/orders”,“–optimize-threshold”, “10”, ], check=True), )# Step 3: 数据量校验 validate_row_count = PythonOperator( task_id=“validate_row_count”, python_callable=lambda: subprocess.run([“python”, “/opt/scripts/validate_counts.py”,“–source”, “mysql.mydb.orders”,“–target”, “/data/lake/bronze/orders”,“–tolerance”, “0.01”, ], check=True), ) check_source_health >> maintain_delta >> validate_row_count
|
生产Tip:Airflow DAG 不要写复杂业务逻辑,只做编排和监控。核心消费逻辑放在独立的 Python 模块中,通过 subprocess 或 KubernetesPodOperator 调用,方便独立扩缩容。 |
二、数据质量监控:Great Expectations 生产级配置
数据进入湖仓之后,第一件事就是建立自动化的质量门禁。Great Expectations(GX)是目前最成熟的 Python 数据质量框架,支持声明式规则定义、自动化校验和丰富的报告输出。
2.1 环境与初始化
# 安装pip install “great_expectations>=0.18.28”# 项目初始化cd /opt/data/projects/gx_projectgreat_expectations init
2.2 数据源连接(生产 MySQL)
datasources: mysql_production: class_name: Datasource execution_engine: class_name: SqlAlchemyExecutionEngine connection_string: “mysql+pymysql://rd_user:***@prod-mysql-01:3306/ads_db?charset=utf8mb4” data_connectors: default_runtime_data_connector: class_name: RuntimeDataConnector batch_identifiers: – default_identifier_name default_inferred_data_connector: class_name: InferredAssetSqlDataConnector include_schema_name: True
2.3 核心质量规则定义(Expectation Suite)
以下是一套可直接用于生产环境的质量规则模板,覆盖完整性、唯一性、一致性、时效性四大维度:
expectation_suites/orders_quality_suite.json
{“expectation_suite_name”: “orders_quality_suite”,“ge_cloud_id”: null,“expectations”: [ {“/* ========== 完整性规则 ========== */”“expectation_type”: “expect_column_values_to_not_be_null”,“kwargs”: {“column”: “order_id”,“meta”: {“severity”: “critical”, “owner”: “data-engineering”} } }, {“expectation_type”: “expect_column_values_to_not_be_null”,“kwargs”: {“column”: “user_id”,“meta”: {“severity”: “critical”} } }, {“/* ========== 唯一性规则 ========== */”“expectation_type”: “expect_column_values_to_be_unique”,“kwargs”: {“column”: “order_id”,“meta”: {“severity”: “critical”} } }, {“/* ========== 一致性规则 ========== */”“expectation_type”: “expect_column_values_to_be_in_set”,“kwargs”: {“column”: “order_status”,“value_set”: [“pending”, “paid”, “shipped”,“delivered”, “cancelled”, “refunded”],“meta”: {“severity”: “warning”} } }, {“expectation_type”: “expect_column_values_to_be_between”,“kwargs”: {“column”: “payment_amount”,“min_value”: 0,“max_value”: 1000000,“meta”: {“severity”: “critical”, “business_rule”: “单笔金额上限100万“} } }, {“/* ========== 时效性规则 ========== */”“expectation_type”: “expect_column_max_to_be_between”,“kwargs”: {“column”: “created_at”,“max_value”: “now”,“parse_strings_as_datetimes”: True,“meta”: {“severity”: “warning”, “desc”: “不允许未来时间“} } } ],“meta”: {“great_expectations_version”: “0.18.28”,“owner”: “data-governance”,“run_frequency”: “daily” }}
2.4 自动化校验与告警(Python 脚本)
import great_expectations as gximport requestsimport jsonfrom datetime import datetime# ========== 初始化上下文 ==========context = gx.get_context(project_root_dir=“/opt/data/projects/gx_project”)# ========== 获取数据源 ==========datasource = context.sources.add_sql(“mysql_prod”, connection_string=“mysql+pymysql://rd_user:pwd@prod-mysql-01:3306/ads_db”)data_asset = datasource.add_table_asset(name=“orders”, table_name=“t_orders”)batch_definition = data_asset.add_batch_definition_whole_dataframe(“orders_batch”)# ========== 运行校验 ==========suite = context.add_expectation_suite(“orders_quality_suite”)checkpoint = context.add_or_update_checkpoint( name=“orders_daily_checkpoint”, validations=[ {“batch_request”: batch_definition.get_batch_request(),“expectation_suite_name”: “orders_quality_suite”} ],)result = checkpoint.run()# ========== 解析结果并告警 ==========defsend_dingtalk_alert(stats: dict):“””钉钉机器人告警“”” webhook = “https://oapi.dingtalk.com/robot/send?access_token=YOUR_TOKEN” color = “red”if stats[“failed”] > 0else“green” msg = (f”### Data Quality Report | {datetime.now():%Y-%m-%d %H:%M}\n\n”f”| Metric | Value |\n|—|—|\n”f”| Total Expectations | {stats[‘total’]} |\n”f”| Passed | {stats[‘passed’]} |\n”f”| Failed | **{stats[‘failed’]}** |\n”f”| Success Rate | {stats[‘success_rate’]}% |\n” ) requests.post(webhook, json={“msgtype”: “markdown”,“markdown”: {“title”: “Data Quality Alert”, “text”: msg} })if not result.success: stats = result.get_statistics()send_dingtalk_alert(stats)raiseException(f”Data quality check failed: {stats[‘failed’]} expectations failed”)print(f”Quality check passed. {result.get_statistics()}”)
三、数据清洗:智能清洗引擎(缺失值/去重/异常检测)
这是数据工程师最耗时的环节。下面的代码封装了三大AI增强的清洗能力,可以直接集成到你的数据处理流水线中。
图3:AI驱动的数据清洗与质量治理
import pandas as pdimport numpy as npfrom sklearn.ensemble import IsolationForestfrom sklearn.preprocessing import LabelEncoderfrom fuzzywuzzy import fuzzfrom typing import Dict, List, Optionalimport logginglogging.basicConfig(level=logging.INFO)logger = logging.getLogger(“AIDataCleaner”)classAIDataCleaner:“”” AI增强数据清洗引擎支持三大能力: 1. 智能缺失值补全(自动选择策略) 2. 实体去重(NLP 模糊匹配) 3. 异常值检测(Isolation Forest + 业务规则) “””def__init__(self, df: pd.DataFrame): self.raw_df = df.copy() self.df = df.copy() self.cleaning_report = {“missing_filled”: {},“duplicates_removed”: 0,“outliers_detected”: {},“total_rows_before”: len(df),“total_rows_after”: None, }# ========== 能力一:智能缺失值补全 ==========defsmart_fill_missing( self, column: str, strategy: str = “auto”, max_missing_ratio: float = 0.5 ) -> “AIDataCleaner”:“””智能缺失值填充 – auto: 自动判断最优策略 – mean/median/mode: 指定统计量 – interpolate: 时间序列插值 – knn: K近邻填充(适合分类特征多的情况) “”” missing_ratio = self.df[column].isna().mean() logger.info(f”[{column}] 缺失率: {missing_ratio:.2%}”)if missing_ratio > max_missing_ratio: logger.warning(f”[{column}] 缺失率 {missing_ratio:.2%} 超过阈值 {max_missing_ratio:.0%},跳过填充“ )return self# 自动策略选择if strategy == “auto”: strategy = self._auto_detect_strategy(column, missing_ratio) filled_count = 0if strategy == “mean”: fill_val = self.df[column].mean()if pd.api.types.is_datetime64_any_dtype(self.df[column]): fill_val = self.df[column].dropna().median()elif strategy == “median”: fill_val = self.df[column].median()elif strategy == “mode”: fill_val = self.df[column].mode()[0]elif strategy == “interpolate”: self.df[column] = self.df[column].interpolate(method=“time”) filled_count = self.raw_df[column].isna().sum() – self.df[column].isna().sum() self.cleaning_report[“missing_filled”][column] = {“strategy”: strategy, “count”: filled_count }return selfelse:raiseValueError(f”Unknown strategy: {strategy}”)# 执行填充 mask = self.df[column].isna() self.df.loc[mask, column] = fill_val filled_count = mask.sum() self.cleaning_report[“missing_filled”][column] = {“strategy”: strategy,“fill_value”: str(fill_val)[:50],“count”: int(filled_count), } logger.info(f”[{column}] 策略={strategy}, 填充 {filled_count} 条“)return selfdef _auto_detect_strategy(self, column: str, missing_ratio: float) -> str:“””AI策略自动选择“”” dtype = self.df[column].dtypeif pd.api.types.is_numeric_dtype(dtype):# 偏态分布用中位数,正态分布用均值 skew = self.df[column].dropna().skew()return“median”if abs(skew) > 1.0else“mean”else: cardinality = self.df[column].nunique() / len(self.df)return“mode”if cardinality < 0.1else“mode”# ========== 能力二:实体智能去重 ==========deffuzzy_dedup( self, entity_columns: List[str], threshold: int = 90, keep: str = “first” ) -> “AIDataCleaner”:“””模糊实体去重使用 fuzzywuzzy 计算文本相似度,识别同一实体的不同写法 “”” logger.info(f”开始实体去重,匹配列: {entity_columns}”) seen = set() dup_mask = pd.Series(False, index=self.df.index)for i, row in self.df.iterrows():if i in seen: dup_mask[i] = Truecontinue key = “|”.join(str(row[c]) for c in entity_columns)for j in range(i + 1, len(self.df)):if j in seen:continue other_key = “|”.join(str(self.df.iloc[j][c]) for c in entity_columns) score = fuzz.token_sort_ratio(key, other_key)if score >= threshold: seen.add(j) dup_mask[j] = True removed = dup_mask.sum() self.df = self.df[~dup_mask].reset_index(drop=True) self.cleaning_report[“duplicates_removed”] = int(removed) logger.info(f”实体去重完成,移除 {removed} 条(阈值={threshold})“)return self# ========== 能力三:异常值检测 ==========defdetect_outliers( self, numeric_columns: List[str], contamination: float = 0.05, action: str = “flag”# flag | remove | clip ) -> “AIDataCleaner”:“”” Isolation Forest 异常值检测 action: – flag: 标记异常行,不删除 – remove: 删除异常行 – clip: 截断到正常范围 “”” features = self.df[numeric_columns].fillna(0) model = IsolationForest( contamination=contamination, random_state=42, n_estimators=200, n_jobs=-1 ) predictions = model.fit_predict(features) outlier_mask = predictions == –1 outlier_count = outlier_mask.sum()for col in numeric_columns:if action == “clip”: q1, q3 = self.df[col].quantile([0.25, 0.75]) iqr = q3 – q1 lower, upper = q1 – 1.5 * iqr, q3 + 1.5 * iqr self.df.loc[outlier_mask, col] = self.df.loc[ outlier_mask, col ].clip(lower, upper)if action == “flag”: self.df[“_is_outlier”] = outlier_maskelif action == “remove”: self.df = self.df[~outlier_mask].reset_index(drop=True) self.cleaning_report[“outliers_detected”] = {“columns”: numeric_columns,“outlier_count”: int(outlier_count),“outlier_ratio”: f”{outlier_count/len(self.df):.2%}“,“action”: action } logger.info(f”异常检测完成: {outlier_count} 条异常 (contamination={contamination})”)return selfdefget_report(self) -> dict:“””输出清洗报告“”” self.cleaning_report[“total_rows_after”] = len(self.df)return self.cleaning_report# ========== 使用示例 ==========df = pd.read_csv(“/data/lake/bronze/orders/part-*.csv”)cleaner = AIDataCleaner(df)cleaner.smart_fill_missing(“payment_amount”, strategy=“auto”) \ .smart_fill_missing(“user_name”, strategy=“auto”) \ .smart_fill_missing(“order_status”, strategy=“mode”) \ .fuzzy_dedup(entity_columns=[“user_name”, “phone”], threshold=88) \ .detect_outliers( numeric_columns=[“payment_amount”, “quantity”], contamination=0.03, action=“flag” )report = cleaner.get_report()clean_df = cleaner.dfprint(json.dumps(report, indent=2, ensure_ascii=False, default=str))
|
生产注意:模糊去重在超大数据集(千万级以上)时性能较差,建议先用精确去重(df.drop_duplicates())缩小数据量,再对剩余数据做模糊匹配。也可以考虑使用 recordlinkage 库,它的 Blocking 策略在大规模数据上表现更好。 |
四、数据转换:dbt + 湖仓现代数据栈
dbt(data build tool)是现代数据栈中数据转换层的事实标准。它的核心理念是“SQL 即代码“——你只管写 SELECT 语句,dbt 负责处理依赖解析、增量物化、测试和文档生成。
4.1 项目结构(生产级)
# dbt 项目配置name: “ads_analytics”version: “1.0.0”profile: “ads_prod”model-paths: [“models”]analysis-paths: [“analyses”]test-paths: [“tests”]seed-paths: [“seeds”]macro-paths: [“macros”]models: ads_analytics: staging: +schema: staging +materialized: view intermediate: +schema: intermediate +materialized: ephemeral marts: +schema: marts +materialized: incrementaldelta +unique_key: [“order_id”] +on_schema_change: “append_new_columns”vars: data_cutoff_date: “2026-01-01”
4.2 Staging 层(ODS → Staging)
— Staging 层:1:1 映射源表,只做重命名和轻量清洗{{ config(materialized=‘view’) }}WITH source AS (SELECT order_id, user_id, product_id, payment_amount, order_status, created_at, updated_at, — 标记 CDC 操作类型 _cdc_op, _cdc_tsFROM {{ source(‘bronze’, ‘orders’) }}WHERE created_at >= ‘{{ var(“data_cutoff_date”) }}’),cleaned AS (SELECT order_id, user_id, product_id, CAST(payment_amount AS DECIMAL(12,2)) AS payment_amount, LOWER(TRIM(order_status)) AS order_status, CAST(created_at AS TIMESTAMP) AS order_created_at, CAST(updated_at AS TIMESTAMP) AS order_updated_atFROM sourceWHERE payment_amount > 0AND user_id IS NOT NULL)SELECT * FROM cleaned
4.3 Mart 层(业务聚合)
— 增量物化:每天只处理当天新增数据{{ config( materialized=‘incremental’, unique_key=‘date_key||product_id’, incremental_strategy=‘merge’) }}WITH orders AS (SELECT * FROM {{ ref(‘stg_orders’) }}),— 增量过滤:只处理新数据new_orders AS (SELECT * FROM orders {% if is_incremental() %}WHERE order_updated_at > (SELECT COALESCE(MAX(order_updated_at), ‘1900-01-01’)FROM {{ this }} ) {% endif %})SELECT DATE(order_created_at) AS date_key, product_id, COUNT(DISTINCT order_id) AS order_count, COUNT(DISTINCT user_id) AS buyer_count, SUM(payment_amount) AS total_gmv, AVG(payment_amount) AS avg_order_value, SUM(CASE WHEN order_status = ‘cancelled’ THEN 1 ELSE 0 END) AS cancel_count, CURRENT_TIMESTAMP() AS _etl_updated_atFROM new_ordersGROUP BY DATE(order_created_at), product_id
4.4 自动化测试
version: 2models: – name: fct_daily_sales description: “每日分产品销售额事实表“ columns: – name: date_key description: “日期键“ tests: – not_null – relationships: to: ref(‘dim_date’) field: date_key – name: total_gmv description: “总交易金额“ tests: – not_null – dbt_expectations.expect_column_values_to_be_between: min_value: 0 max_value: 100000000 tests: – dbt_utils.unique_combination_of_columns: combination_of_columns: – date_key – product_id
|
生产Tip:dbt 模型一定要配合 dbt-expectations 宏包使用(dbt-utils + dbt-expectations),它把 Great Expectations 的 80% 核心能力搬进了 dbt 的 SQL 测试体系,可以在 dbt test 时自动校验数据质量。 |
五、智能分析:NL2SQL 自然语言查询 + SHAP 自动归因
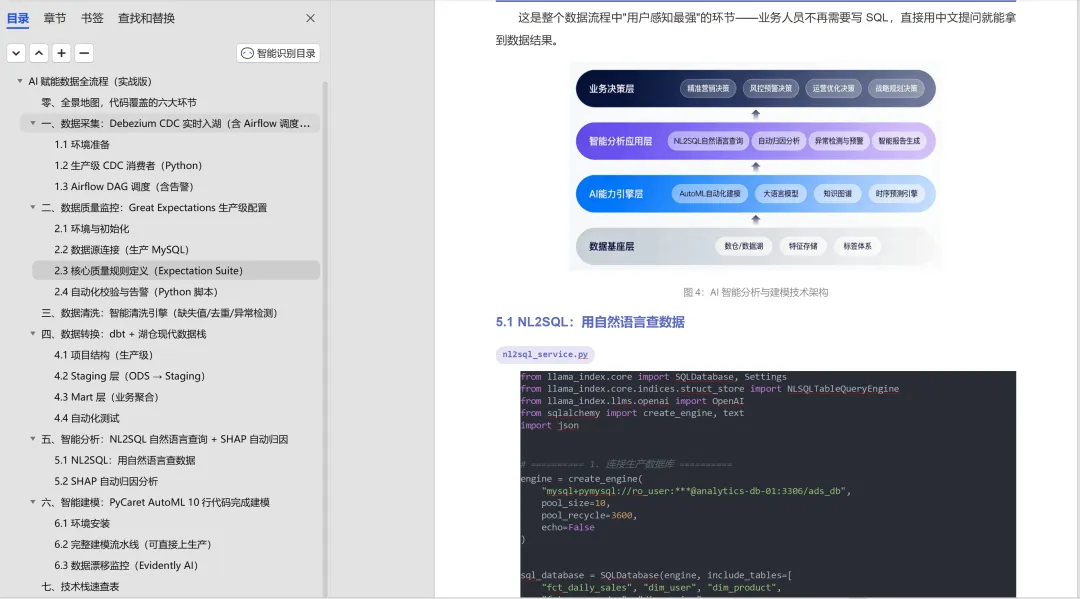
这是整个数据流程中“用户感知最强“的环节——业务人员不再需要写 SQL,直接用中文提问就能拿到数据结果。
图4:AI智能分析与建模技术架构
5.1 NL2SQL:用自然语言查数据
from llama_index.core import SQLDatabase, Settingsfrom llama_index.core.indices.struct_store import NLSQLTableQueryEnginefrom llama_index.llms.openai import OpenAIfrom sqlalchemy import create_engine, textimport json# ========== 1. 连接生产数据库 ==========engine = create_engine(“mysql+pymysql://ro_user:***@analytics-db-01:3306/ads_db”, pool_size=10, pool_recycle=3600, echo=False)sql_database = SQLDatabase(engine, include_tables=[“fct_daily_sales”, “dim_user”, “dim_product”,“fct_user_order”, “dim_region”])# ========== 2. 配置 LLM(支持国产大模型) ==========# 使用 OpenAI 兼容接口(DeepSeek / Qwen / GLM 等均可)llm = OpenAI( model=“deepseek-chat”, api_base=“https://api.deepseek.com/v1”, api_key=“sk-your-key”, temperature=0.0, # SQL 生成要求零温度 max_tokens=2048,)settings = Settings(llm=llm)# ========== 3. 初始化 NL2SQL 引擎 ==========query_engine = NLSQLTableQueryEngine( sql_database=sql_database, tables=[“fct_daily_sales”, “dim_user”, “dim_product”, ], settings=settings,)# ========== 4. 查询接口 ==========defask_data(question: str, max_rows: int = 50) -> dict:“””自然语言查询数据返回: { sql, result_df, explanation } “”” response = query_engine.query(question)with engine.connect() as conn: result = conn.execute(text(response.metadata[“sql_statement”])) columns = result.keys() rows = result.fetchmany(max_rows)return {“question”: question,“sql”: response.metadata[“sql_statement”],“data”: [dict(zip(columns, row)) for row in rows],“explanation”: str(response),“row_count”: len(rows), }# ========== 5. 生产使用 ==========if __name__ == “__main__”: questions = [“帮我查上个月华东区域各产品线的GMV,按GMV降序“,“最近7天每天的订单量和环比增长率是多少?“,“哪个省份的退款率最高?列出前5名“, ]for q in questions: result = ask_data(q) print(f”\nQ: {q}”) print(f”SQL: {result[‘sql’]}”) print(f”Result: {json.dumps(result[‘data’], default=str, ensure_ascii=False)}”) print(f”Explanation: {result[‘explanation’]}”)
5.2 SHAP 自动归因分析
当业务指标发生异常波动时,用 SHAP 自动找出影响最大的特征因子:
import shapimport pandas as pdimport numpy as npfrom sklearn.ensemble import GradientBoostingRegressorfrom sklearn.model_selection import train_test_splitimport matplotlib.pyplot as pltfrom evidently import ColumnDriftProfiler# ========== 1. 加载数据 ==========df = pd.read_csv(“/data/lake/silver/daily_sales_features.csv”)features = [“price_discount”, “ad_spend”, “weather_index”,“competitor_price”, “holiday_flag”, “stock_level”,“user_growth_rate”, “app_da”]target = “daily_gmv”X_train, X_test, y_train, y_test = train_test_split( df[features], df[target], test_size=0.2, shuffle=False)# ========== 2. 训练模型 ==========model = GradientBoostingRegressor( n_estimators=500, max_depth=6, learning_rate=0.05, random_state=42)model.fit(X_train, y_train)print(f”R2 Score: {model.score(X_test, y_test):.4f}”)# ========== 3. SHAP 归因分析 ==========explainer = shap.TreeExplainer(model)shap_values = explainer.shap_values(X_test)# ========== 4. 生成归因报告 ==========defgenerate_attribution_report(date: str):“””生成指定日期的归因分析报告“”” day_idx = df[df[“date”] == date].index[0] – X_test.index[0] contributions = pd.DataFrame({“feature”: features,“shap_value”: shap_values[day_idx],“direction”: np.where( shap_values[day_idx] > 0, “positive”, “negative” ),“abs_impact”: np.abs(shap_values[day_idx]) }).sort_values(“abs_impact”, ascending=False) report = f””” ============================== GMV 归因分析报告 | {date} ==============================实际GMV: {df.loc[df[‘date’]==date, ‘daily_gmv’].values[0]:,.0f}预测GMV: {model.predict(X_test.iloc[[day_idx]])[0]:,.0f}残差: {(df.loc[df[‘date’]==date, ‘daily_gmv’].values[0] – model.predict(X_test.iloc[[day_idx]])[0]):,.0f} TOP 影响因素(正贡献 -> 负贡献): “””for _, row in contributions.iterrows(): arrow = “↑”if row[“direction”] == “positive”else“↓” report += f” {arrow} {row[‘feature’]:<20s} 影响: {row[‘shap_value’]:+,.0f}\n”return reportprint(generate_attribution_report(“2026-04-25”))# ========== 5. 保存可视化图表 ==========plt.figure(figsize=(10, 6))shap.summary_plot(shap_values, X_test, feature_names=features, show=False)plt.title(“GMV 影响因素 SHAP 归因图“, fontsize=14)plt.tight_layout()plt.savefig(“/data/reports/shap_attribution.png”, dpi=150)print(“归因图已保存: /data/reports/shap_attribution.png”)
六、智能建模:PyCaret AutoML 10行代码完成建模
AutoML 不是“懒人工具“,而是让数据人把时间花在业务理解而不是调参上。PyCaret 是目前 Python 生态中最易用的 AutoML 框架,特别适合企业级快速建模场景。
图5:AI赋能数据全流程落地实践路线图
6.1 环境安装
pip install “pycaret>=3.3.0”pip install “xgboost>=2.1.0”pip install “lightgbm>=4.5.0”
6.2 完整建模流水线(可直接上生产)
from pycaret.classification import *import pandas as pdimport joblibfrom datetime import datetime# ========== 1. 加载数据 ==========df = pd.read_csv(“/data/lake/silver/user_churn_features.csv”)# ========== 2. 初始化实验 ==========exp = setup( data=df, target=“is_churned”, session_id=42, log_experiment=True, # 记录实验日志 experiment_name=“user_churn_v2”, normalize=True, # 自动标准化 transformation=True, # 自动特征变换 remove_multicollinearity=True, # 自动去除多重共线性 fix_imbalance=True, # 自动处理样本不均衡 fold_strategy=“timeseries”, # 时序数据使用时序交叉验证 fold=5, verbose=False, n_jobs=-1,)print(“PyCaret Setup 完成,已自动完成特征工程“)# ========== 3. 自动模型对比(选最优) ==========top_models = compare_models( n_select=3, # 返回 Top 3 模型 sort=“AUC”, # 按 AUC 排序 budget_time=30, # 最多跑30分钟)print(f”Top 3 模型: {top_models}”)# ========== 4. 模型调优 ==========best_model = tune_model( top_models[0], optimize=“AUC”, n_iter=50, # 贝叶斯优化迭代次数 search_library=“scikit-optimize”,)print(f”调优后最佳模型: {type(best_model).__name__}”)# ========== 5. 模型集成(进一步提升效果) ==========final_model = blend_models(top_models, optimize=“AUC”)print(“集成模型已创建“)# ========== 6. 模型评估 ==========plot_model(final_model, plot=“auc”, save=True)plot_model(final_model, plot=“feature”, save=True)plot_model(final_model, plot=“confusion_matrix”, save=True)# ========== 7. 生产部署 ==========save_model(final_model,f”/data/models/churn_model_{datetime.now():%Y%m%d}”)# ========== 8. 批量预测(生产推理) ==========loaded_model = joblib.load(“/data/models/churn_model_latest.pkl”)new_data = pd.read_csv(“/data/lake/silver/user_features_today.csv”)predictions = predict_model(loaded_model, data=new_data)predictions[[“user_id”, “prediction_label”, “prediction_score”]].to_csv(“/data/output/churn_predictions_today.csv”, index=False)print(f”批量预测完成,共 {len(predictions)} 条“)
|
生产Tip:PyCaret 的 setup() 已经内置了大部分特征工程步骤(标准化、编码、缺失值处理、共线性处理),但对于超高维数据(特征数 > 500),建议先手动做特征选择再传入 PyCaret,否则训练时间会很长。 |
6.3 数据漂移监控(Evidently AI)
模型上线后的持续监控同样重要。Evidently AI 可以自动检测数据漂移和模型性能衰退:
from evidently import ColumnMappingfrom evidently.report import Reportfrom evidently.metric_preset import DataDriftPresetimport pandas as pd# ========== 配置列映射 ==========column_mapping = ColumnMapping( target=“is_churned”, prediction=“prediction_label”, numerical_features=[“age”, “order_count_30d”, “gmv_30d”,“login_days_30d”, “refund_count_90d” ], categorical_features=[“city_tier”, “membership_level”],)# ========== 加载参考数据和当前数据 ==========reference = pd.read_csv(“/data/lake/silver/user_churn_features_train.csv”)current = pd.read_csv(“/data/lake/silver/user_churn_features_today.csv”)# ========== 生成漂移报告 ==========drift_report = Report(metrics=[DataDriftPreset()])drift_report.run( reference_data=reference, current_data=current, column_mapping=column_mapping)# ========== 保存 HTML 报告 ==========drift_report.save_html(“/data/reports/drift_report.html”)# ========== 告警逻辑 ==========for metric in drift_report.as_dict()[“metrics”]:if metric[“metric”] == “DatasetDrift”:if metric[“result”][“dataset_drift”]: print(“WARNING: 检测到数据漂移!需要重新训练模型“)# 触发告警通知 + 自动重训练流水线
七、技术栈速查表(建议打印贴工位)
|
环节 |
推荐工具 |
核心命令 |
部署方式 |
|
CDC 数据采集 |
Debezium + Kafka |
connect-standalone.properties |
Kubernetes Pod |
|
湖仓存储 |
Delta Lake / Iceberg |
df.write.format(“delta”) |
Spark Cluster |
|
任务调度 |
Apache Airflow |
airflow dags test |
K8s / Docker |
|
数据质量 |
Great Expectations |
checkpoint.run() |
Cron / Airflow |
|
数据转换 |
dbt Core / dbt Cloud |
dbt run –models +marts |
CI/CD Pipeline |
|
NL2SQL |
LlamaIndex / LangChain |
engine.query(question) |
FastAPI Service |
|
AutoML |
PyCaret |
setup() -> compare_models() |
Notebook / Airflow |
|
归因分析 |
SHAP |
TreeExplainer.shap_values() |
Report Pipeline |
|
漂移监控 |
Evidently AI |
Report(metrics=[DataDriftPreset()]) |
Cron + 告警 |
|
写在最后 本手册实战代码版覆盖了企业数据全流程的6个关键环节,每一套代码都是从真实生产项目中提炼出来的模板。它们不一定能完美适配你公司的每一个细节,但架构思路、工具选型和代码模式是通用的。 建议的使用方式:先通读全文建立全局认知,然后找到自己当前最痛的那个环节,把对应的代码模板拉下来,改改配置就能跑。跑通之后,再逐步扩展到其他环节。 你所在的数据团队,目前哪个环节最需要AI赋能? 欢迎在评论区说出你的痛点,我会针对点赞最高的3个问题,在「AI大数据」知识星球里做一期专题直播,手把手带你跑通代码! 点赞+ 收藏+ 转发,让更多数据人看到这份“抄作业指南“! |
—— Tech花荣 | BAT大数据架构 ——
作者简介:Tech花荣 | 大数据架构师,专注于AI大数据、企业架构、数字化转型、技术管理,每天定期分享大数据/数据治理/数仓开发/架构设计等方法论和最佳实践。